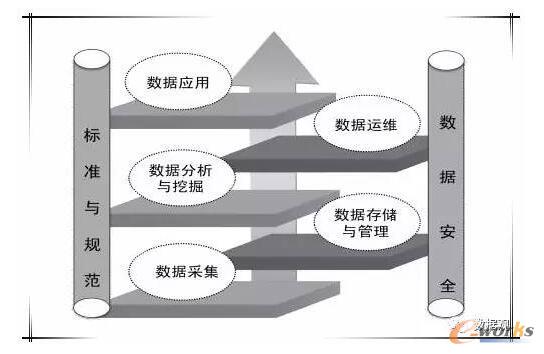
Ū░čį
╬ęĮoųąąĪą═▀\ŠSłFĻĀĄ─Č©┴x╩Ūš¹éĆłFĻĀ╚╦öĄŻ©╦∙ėą▀\ŠS╣ż│╠Ĥ + ▀\ŠSķ_░l╣ż│╠ĤŻ®×ķ 20 ╚╦ęįŽ┬Ż¼ę╗░Ń▀@śėĄ─łFĻĀŻ¼─▄×ķūįäė╗»═Č╚ļĄ─┘Yį┤ę▓įSŠ═ 1Īó2 éĆķ_░l╚╦åTĪŻ
BAT Ą╚┤¾╣½╦ŠĄ─ DevOps ŲĮ┼_╣”─▄║Ł╔wĄ─ĘČć·ĘŪ│Ż╚½├µČ°ŪęĖ„ĘNĖ▀┤¾╔ŽŻ¼▀@├┤²ŗ┤¾Ą─¾wŽĄī”ė┌ųąąĪą═▀\ŠSłFĻĀŻ¼ę¬┐┐╩ųŅ^ĒöČÓ 2 ├¹▀\ŠSķ_░l╣ż│╠ĤüĒīŹ¼F┬õĄžŠ═Ń┬┴╦Ż¼▓╗ų¬įōÅ─║╬╚ļ╩ųĪŻ╦∙ęį═∙═∙┤¾▓┐ĘųųąąĪą═▀\ŠSłFĻĀę¬├┤é„Įy╚╦╚Ō▀\ŠS║┌┬Ęū▀ĄĮĄūŻ¼ę¬├┤ųĖ═¹╣½╦Šę¦č└╔Ž DevOps ╔╠śIĘ■äšĪŻ
╚╗Č°Ż¼āH┐┐┘Å┘I╔╠śIĘ■äšę▓╬┤▒ž─▄═Ļ╚½ĮŌøQå¢Ņ}Ż¼ų„ę¬įŁę“ėąŻ║
1 . Üv╩ĘĒŚ─┐│╔▒Š┐╝æ]Ż║╔╠śIŲĮ┼_▓╗ų¦│ųéĆąį╗»Ż¼Üv╩ĘĒŚ─┐╬┤▒ž─▄ų▒Įėī”Įė╔╠śIŲĮ┼_Ż¼ąĶę¬═©▀^▀\ŠS┼cśIäšé╚Š∙ųžśŗęį▀mæ¬╔╠śIŲĮ┼_Ż¼ī”Įė│╔▒Š╔§ų┴Ė▀ė┌ūįĮ©ŲĮ┼_Ż¼Ūęę¬Ė▀╦┘▀\ąąĄ─śIäšé╚═ŻŽ┬┼õ║Žę▓▓ó▓╗┐┐ūVŻ╗
2 . ╔╠śIÖC├▄öĄō■Ą─┐╝æ]Ż║╔╠śIŲĮ┼_Ģ■┤µā”▀\ŠS / ▓┐ĘųśI䚎ÓĻPöĄō■Ż¼▀@ī”ė┌░▓╚½ę¬Ū¾▌^Ė▀Ą─ąąśIüĒšfŻ¼ūįĮ©ŲĮ┼_Ą─┐╔┐žČ╚Ė³Ė▀Ż╗
╚╗Č°Ż¼ųąąĪą═╣½╦ŠĄ─ūįĮ©ŲĮ┼_┤¾ČÓČ╝╦Ń╩ŪųžÅ═įņ▌åūėŻ¼ļm╚╗Ė„╝ęśIäšŪķørĖ„«ÉŻ¼Ą½ę▓ėą┐╔ęį│ķŽ¾│╔┐╔Å═ė├Ą─╝▄śŗ¾wŽĄŻ¼▀@ę▓╩Ū╔╠śIūįäė╗»ŲĮ┼_Ą─ārųĄ╦∙į┌Ż¼╚ń╣¹łFĻĀ╩Ū 10 ╚╦ęįŽ┬Ūęø]īŻ┬Üķ_░l╚╦åTį┘ŪęśIäš╝╝ągÜv╩Ęé∙äš▓╗ųžĄ─ŪķørŽ┬Ż¼▀xō±╔╠śIĘ■äšę▓▓╗╩¦×ķ├„ųŪų«┼eĪŻ
╬ęéāĮø│Ż┐┤ĄĮĖ„ĘN┤¾ÅSĄ─ūįäė╗»ŲĮ┼_ę╗░Ń░³║¼Ūę▓╗Ž▐ė┌ęįŽ┬ā╚╚▌Ż║CMDBĪó┼õų├ųąą─Īó╣▄┐žŲĮ┼_ĪóöĄō■ŲĮ┼_ĪóCI/CDĪóū„śIŲĮ┼_Īó╚▌Ų„╣▄└ĒĪóöU╚▌┐s╚▌Īó▌oų·▀\ĀIĪó▒O┐žųąą─ Ą╚Ą╚Ż¼Ė„ĘNĖ▀┤¾╔Žį~ģRūī╚╦─┐▓╗ŽŠĮėĪŻ
ė╔ė┌ųąąĪą═łFĻĀĄ─ė├╚╦│╔▒Š▒žĒÜ┐žųŲĄ├śOŲõŠ½┤_Ż¼ę╗░Ń▓╗Ģ■ėą╠½ČÓ╚╦┴”┘Yį┤═Č╚ļĄĮūįäė╗»ŲĮ┼_Ą─ķ_░lŻ¼╦∙ęį▒žĒÜšę│÷ūŅ║╦ą─╣”─▄Ż¼ęį▀_ĄĮ┐ņ╦┘┬õĄž═Č╚ļ╔·«aŁh╣Ø╩╣ė├×ķ─┐Ą─ĪŻ╬ęéā▓╗┐╔─▄ī”╔Ž╩÷╣”─▄³c├µ├µŠŃĄĮŻ¼▀@śėų╗Ģ■ūīūį╝║¤oÅ─Ž┬╩ųĪŻ
ŲõīŹūŅ║╦ą─Ą─╣”─▄─ŻēKų╗ėąā╔éĆŻ║CMDBŻ©┼õų├ŲĮ┼_Ż®║═ū„śIŲĮ┼_ĪŻ╬ęéāū„×ķųąąĪą═Ą─▀\ŠSłFĻĀŻ¼ŲõīŹ─▄░č▀@ā╔▓┐Ęų═Ļ│╔╝┤┐╔ØMūŃ 80% Ą─śIäšąĶŪ¾Ż¼į┌┤╦╗∙ĄA╔ŽŻ¼į┘Ė∙ō■ūį╔ĒśIäšąĶŪ¾į┘┐╝æ]ķ_░lŲõ╦¹Ė▀╝ēöUš╣╣”─▄╚ń CI/CDĪóöĄō■Ęų╬÷ĪóśIäš▒O┐žĪó▌oų·▀\ĀIĄ╚ĪŻ
ĒŚ─┐▒│Š░
ąĶŪ¾“īäėī¦Ž“Ż¼┤¾╝ęę▓▓╗Ģ■ę“×ķ╔ŽŠĆę╗éĆąĪĒŚ─┐Š═šą╚╦ū÷ūįäė╗»ŲĮ┼_Ż¼į┌╩▓├┤ŪķørŽ┬╬ęéā▓┼ąĶę¬ū÷ūįäė╗»ŲĮ┼_─žŻ┐
╚ź─ĻŻ¼ļSų°╩ųė╬ĒŚ─┐Ą─░lš╣Ż¼╣½╦ŠśIäšąĶŪ¾╠Äė┌ę╗éĆ’w╦┘į÷ķLĄ─ļAČ╬Ż¼į┌Č╠Ģrķgā╚ęčĮø░lš╣ĄĮīóĮ³öĄ╩«éĆĒŚ─┐Ż©║¼Ė„ĘNŪ■Ą└ĪóŲĮ┼_ĪóĘųģ^Ż®Ż¼śIäšą╬æBĖ„«ÉŻ¼░³└©Ēōė╬Īó╩ųė╬Ī󚊳cĪóapp Ą╚Ż¼▀@śė▒ŖČÓĄ─ĒŚ─┐▀\ŠS╣▄└Ē│╔▒ŠĘŪ│ŻĖ▀Ż¼é„ĮyĄ─▀\ŠS╣▄└ĒĘĮ╩Į║▄ļyĖ▀ą¦┬╩ĪóĖ▀┘|┴┐Ąž╣▄└Ē║═░č┐ž╚ń┤╦ČÓĄ─«aŲĘ║═ĒŚ─┐ĪŻ
ļSų°╠ōöM╗»ĪóįŲĪó╬óĘ■䚥╚╝╝ągĄ─░lš╣Ż¼į┘╝ė╔Žėą▒ŖČÓĄ─įŲĘ■äš╠ß╣®╔╠Ż©░ó└’įŲĪó“vėŹįŲĪóUCloud Ą╚Ż®Ż¼æ¬ė├│╠ą“Ą─Ąūīė▀\ąąŁhŠ│ė·░lČÓśė╗»Ż¼Ė„ĘN▀\ŠSī”Ž¾Č╝ąĶę¬═©▀^ę╗éĆŲĮ┼_▀MąąĮyę╗Ą─▓┘ū„║═╣▄└ĒĪŻ
×ķ┴╦æ¬ī”ęį╔Žå¢Ņ}▓óĖ▀┘|┴┐═Ļ│╔▀\ŠS▒ŻšŽĘ■䚯¼╬ęéā▒žĒÜū÷ĄĮŻ║
- ═©▀^ŲĮ┼_Įyę╗╣▄└Ē╦∙ėą▀\ŠSī”Ž¾Ż¼ī”ĒŚ─┐ĮMĪóī”▀\ŠS▓┐ķTĄ─╦∙ėą▓┘ū„Č╝│╠ą“╣╠╗»Ż╗
- īŹ¼F╦∙ėąĒŚ─┐Ą─│ų└m╝»│╔Īóūįäė╗»▓┐╩ĪóĒŚ─┐ĮMūįų·▓┘ū„ęį╠ß╔²░l▓╝ą¦┬╩║═ĮĄĄ═╣╩šŽ┬╩Ż╗
- ėąę╗éĆ═Ļ╔ŲĄ─┼õų├ųąą─×ķ╦∙ėą▀\ŠSūįäė╗»Ą─ĄūīėöĄō■║═┼õų├╗∙ĄAŻ¼“īäė╦∙ėą▀\ŠS─_▒ŠĪó╣żŠ▀ĪóĮM╝■š²│Ż▀\ąąŻ╗
╚ń║╬▀_│╔─┐ś╦
├„┤_┴╦─┐ś╦ų«║¾Ż¼─ŃĢ■░l¼F▀@╚²éĆ─┐ś╦š²║├ī”æ¬╚²éĆ▀\ŠSągšZŻ║ś╦£╩╗»Īó┴„│╠ęÄĘČ╗»║═ CMDBĪŻ
- ś╦£╩╗»Ż║Å─ų„ÖC├¹ĪóIPĪó▓┘ū„ŽĄĮyĪó╬─╝■─┐õøĪó─_▒ŠĄ╚ę╗ŽĄ┴ą▀\ŠSī”Ž¾Č╝ųŲČ©ś╦£╩ęÄĘČŻ¼śIäš▓┐ķT║═▀\ŠS▓┐ķTČ╝ū±╩ž═¼ę╗╠ūś╦£╩Ż¼╗∙ė┌▀@╠ūś╦£╩╚źĮ©įOĮyę╗Ą─ŲĮ┼_ĪŻ
- ┴„│╠ęÄĘČ╗»Ż║ų„ę¬╩Ū╔µ╝░ │╠ą“╬─╝■┤“░³Īóķ_░l£yįćŠĆ╔ŽŁhŠ│╣▄└ĒĪó░l▓╝┴„│╠ Ą╚ČÓ▓┐ķTģfū„Ą─ęÄĘČŻ¼▒žĒÜ┬õīŹĄĮ│╠ą“╣╠╗»╗“š▀╬─Ön╣╠╗»Ż¼┤“įņ Dev ║═ Ops ų«ķgĄ─ś╦£╩Į╗ĖČŁhŠ│ĪŻ
- CMDBŻ║▀@╩Ūę╗Ūą▀\ŠSūįäė╗»¾wŽĄĮ©įOĄ─╗∙╩»Ż¼Ųõ╦³╚ń┼õų├╣▄└ĒĪóū„śIł╠ąąĪó┘Y«a╣▄└ĒĄ╚ąĶę¬╗∙ė┌ CMDB ▓┼─▄ą╬│╔¾wŽĄŻ¼śŗĮ©═Ļ╔ŲĄ─▀\ŠSī”Ž¾╔·├³ų▄Ų┌║═▓┘ū„ķ]ŁhĪŻ
ś╦£╩╗»
ś╦£╩╗»░³║¼Ą─ĘČ«ĀĘŪ│ŻČÓŻ¼Å─ūŅ║åå╬Ą─▓┘ū„ŽĄĮy░µ▒ŠĪóų„ÖC├¹ĪóIP Č╬ĪóŽĄĮyÄż╠¢├▄┤aĄĮ▄ø╝■░▓čbĄ──┐õøĪóģóöĄĪó┼õų├╬─╝■Ą╚Ą╚Ż¼ę▓įS▓╗═¼Ą─╣½╦ŠėąŲõ╠žėą┴ĢæT║═Üv╩Ę▀z┴¶Ż¼╦∙ęį▀@éĆø]ėąę╗éĆ╚½śIĮńĄ─Įyę╗─Ż╩ĮĪŻ
¼Fį┌ų╗ąĶę¬░č┘F╦ŠĄ─┴ĢæTė├╬─ÖnĄ─ą╬╩Į╣╠╗»Ž┬üĒŻ¼į┘ÅžĄūÖz▓ķ╔·«aŁhŠ│Ą─Ūķør╩ŪʱØMūŃęÄĘČ╦∙╩÷Ż¼▓╗ØMūŃät░┤ęÄĘČ▓┘ū„ĪŻ
ī”ė┌Üv╩Ę▓╗╩Ū╠½ėŲŠ├Ą─ĒŚ─┐ꬹ▐š²▓╗Ģ■╠½└¦ļyŻ¼╚ń╣¹▀B▀@³cČ╝Žė┬ķ¤®Ą─įÆŻ¼ę▓▓╗ė├šä╩▓├┤▀\ŠSūįäė╗»┴╦ĪŻ
║åå╬«ŗéĆ╦╝ŠSī¦łDŻ¼ś╦£╩╗»Ą─ĘČ«Āų„ę¬░³║¼Ą½▓╗Ž▐ė┌ęįŽ┬ā╚╚▌Ż║
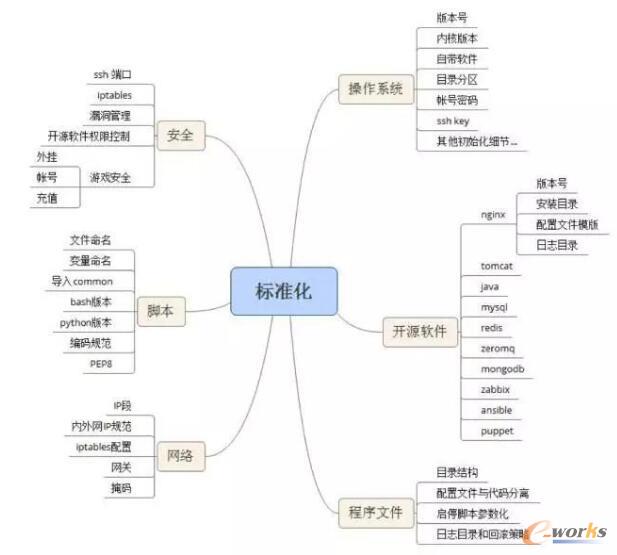
┴„│╠ęÄĘČ╗»
┴„│╠ęÄĘČ╗»╩Ūį┌Į©┴ó┴╦ś╦£╩╗»ų«║¾Ż¼×ķ┴╦ęÄĘČ▀\ŠSā╚▓┐ęį╝░┼c═Ō▓┐ķT║Žū„Ą─ę╗ŽĄ┴ąÅ═ļs╩┬╝■Ą─╝Ü╣Øū÷Ę©Ż¼▒╚╚ńę¬░l▓╝ą┬░µ▒ŠĪó╔ŽŠĆą┬ĒŚ─┐ĪóśIäšöU╚▌┐s╚▌Ą╚ĪŻ
▀@ę╗▓┐Ęų▓╗╠½╚▌ęūš╣ķ_Ż¼ę“×ķ▓╗═¼╣½╦Šėąūį╝║Ą─ū÷Ę©║═┴ĢæTŻ¼¤ošō╩Ūį§śėū÷Ż¼šłė├╬─ÖnęÄĘČ║═╝s╩°Ė„▓┐ķT╚╦åTĄ─ąą×ķŻ¼▀@śė▓┼─▄ĘĮ▒Ń│╠ą“╗»║═ūįäė╗»Ż¼▓╗╚╗│╠ą“Š═ę¬īæČÓ║▄ČÓ if-else šZŠõ╗“š▀ąĶę¬┼õų├╗»üĒ╝µ╚▌Ė„ĘN▓╗ęÄĘČŪķørŻ¼═Įį÷ķ_░l╚╦┴”Ž¹║─ĪŻ
CMDB
▓╗ė├┘ś╩÷Ż¼CMDB Ą─įOėŗ┐ŽČ©╩Ū▀\ŠSūįäė╗»Į©įOĄ─ųžųąų«ųžŻ¼įOėŗ║├Ą─įÆŻ¼▀\ŠSŲĮ┼_Ą─ķ_░l┐╔ęįėą╩┬░ļ╣”▒ČĄ─ą¦╣¹ĪŻ
CMDBŻ©Configuration Management DatabaseŻ®┼õų├╣▄└ĒöĄō■ÄņŻ¼╩Ūėøõø╦∙ėą▀\ŠSī”Ž¾ą┼ŽóĄ─öĄō■ÄņŻ¼╦∙ėą▀\ŠS┴„│╠ąĶę¬╗∙ė┌ CMDB Ą─öĄō■▀Mąą▓┘ū„Ż¼ą╬│╔▓┘ū„ķ]ŁhŻ¼▓┘ū„Ą─ĮY╣¹Ģ■Ę┤üĄĮ CMDB ųąĪŻ
┤╦ŽĄĮy╠ß╣®┴╦ę╗š¹╠ūĮė┐┌Įń├µ┼cŲõ╦³╚╬║╬ąĶꬹ┼ŽóĄ─ŽĄĮy▀Mąąī”ĮėŻ¼▀@ę▓╩ŪįOėŗ│§ųįŻ¼īóą┼ŽóÅ─ę╗éĆĮyę╗Ą─Īóś╦£╩Ą─į┤Ņ^▌ö│÷ĮoĖ„┤╣ų▒╗“╦«ŲĮśIäš╣”─▄ŽĄĮyŻ¼Č°▀\ŠSąĶę¬ū÷Ą─Š═╩ŪŠSūo CMDB ▒Š╔Ē╗∙ĄAöĄō■Ą─═Ļš¹ąįĪó£╩┤_ąįŻ¼CMDB ┼cĖ„┴„│╠ŽĄĮyĪó┤╣ų▒╣”─▄ŽĄĮyĮY║Žų«║¾īŹ¼Fą┼ŽóöĄō■ę╗╠ÄūāĖ³Ż¼╠Ä╠Ä═¼▓ĮĪŻ
ę╗éĆÖCŲ„Ž┬╝▄Ą─▓┘ū„Ż║
é„ĮyĘĮ╩ĮŻ║═©▀^ SSH ĄŪõøĄĮįōÖCŲ„Ż¼ĻPķ]╦∙ėąśIäš│╠ą“Ż¼ĻPÖCŻ¼į┌┐žųŲ┴ą▒Ēäh│²įō IPŻ¼Ž┬╝▄Ż¼ĄŪõø┘Yį┤╣▄└ĒŽĄĮyäh│²įōÖCŲ„ą┼ŽóĪŻ
ūįäė╗»ĘĮ╩ĮŻ║į┌ CMDB ųąŠÄ▌ŗŲõĀŅæBŻ¼ŽĄĮyūįäėš{ė├Ąūīė╣żŠ▀ĻPķ]Ę■äšĪóĻPÖCŻ¼▓óūįäėīóÖCŲ„ą┼Žóį┌ CMDB ųąĖ³ą┬ĀŅæB
ģ^äeŻ║é„ĮyĘĮ╩ĮĖ„éĆ▓Į¾EČ╝╩ŪĘŪįŁūėąįŻ¼├┐ę╗▓ĮČ╝┐╔─▄ėąÕe┬®Ą─å¢Ņ}Ż¼╚ń═³ėøäh│²┐žųŲ┴ą▒Ē IP ╗“š▀═³ėøĖ³ą┬┘Yį┤╣▄└ĒŽĄĮyą┼ŽóŻ¼▀\ŠS┴„│╠¤oĘ©▀_ĄĮ▓┘ū„ķ]ŁhĪŻČ°šµš²Ą─ūįäė╗»ĘĮ╩Į╩Ūæ¬įōąĶę¬▀_ĄĮ▓┘ū„ķ]ŁhŻ¼¤oąĶ╚╦╣żĖ╔ŅAĪŻ
╚ń║╬įOėŗ
CMDB Ą─įOėŗėąę╗éĆūŅ┤¾Ą─š`ģ^╩ŪŽļĮ©┴óę╗éĆ┤¾Č°╚½Ą─ī┘ąį▒ĒŻ¼║▐▓╗Ą├Žļ░č╚½▓┐▀\ŠSī”Ž¾Ą─╚½▓┐ī┘ąįČ╝šę│÷üĒŻ¼▒╚╚ńŻ║
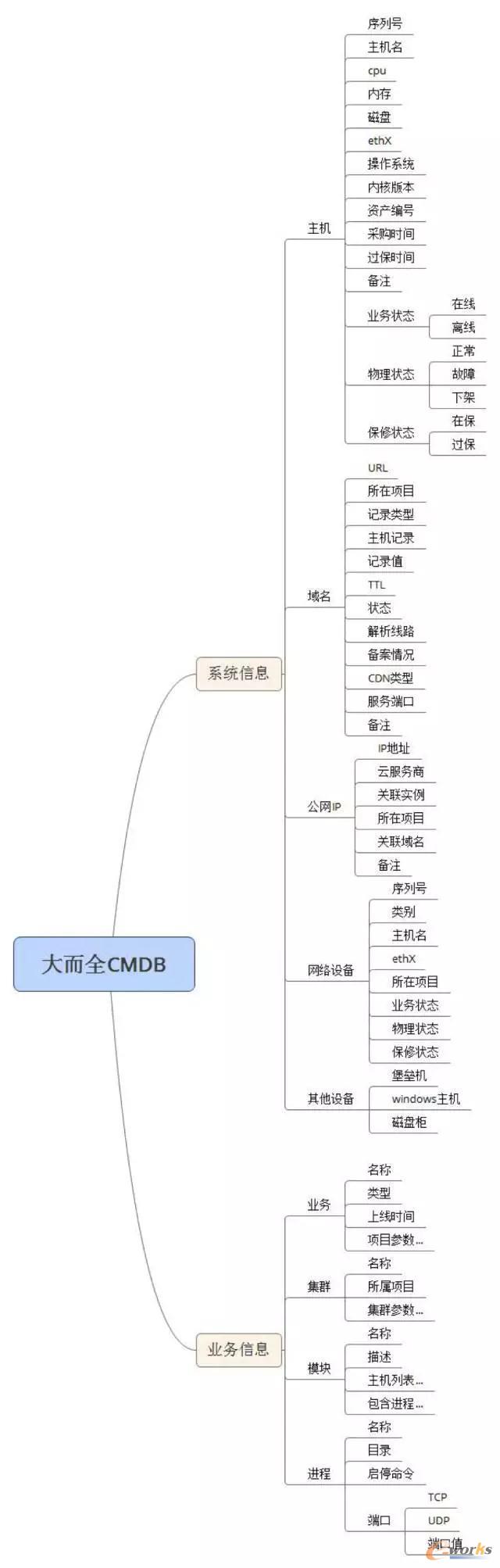
Å─┴Ń╔óĄ─▀\ŠSī”Ž¾üĒŲ┤£É CMDB ╗∙▒ŠČ╝╩Ū│į┴”▓╗ėæ║├Ą─Ż¼ę“×ķ▀@śėĄ─įOėŗĘĮ╩ĮĖ∙▒Šø]ėąÅ─śIäš│÷░lĪŻ
Č°šµš²─▄ĮŌøQśIäšå¢Ņ}Ą─ CMDB ▒žĒÜ╗žĄĮśIäš╔Ž├µüĒŻ¼Å─║╦ą─Ą─╚²īėĻPŽĄķ_╩╝ĮMĮ© CMDBŻ¼▀@╚²īėĖ┼─ŅÅ─┤¾ĄĮąĪĘųäe╩ŪŻ║śIäšĪó╝»╚║Īó─ŻēKŻ©ė╬æ“ąąśIągšZę╗░ŃĮąĒŚ─┐ĪóĘųģ^ĪóĘ■䚯®
įOėŗ╦╝┬Ęæ¬įō╩Ū▀@śėĄ─Ż¼╬ę╦∙▀\ŠSę╗éĆśI䚯¼╦³ėą──ą®╝»╚║Ż┐╝»╚║Ž┬ėą──ą®─ŻēKŻ┐─ŻēKŽ┬ėą──ą®ÖCŲ„Ż┐ÖCŲ„ėą──ą®ī┘ąįŻ┐Ė„ĘNī┘ąįų«ķgėą╩▓├┤ĻP┬ōĻPŽĄŻ┐
═©▀^▀@śėĄ─╦╝ŠSĘĮ╩Į┬²┬²░čšµš²Ą─ CMDB ĮM┐ŚŲüĒ……
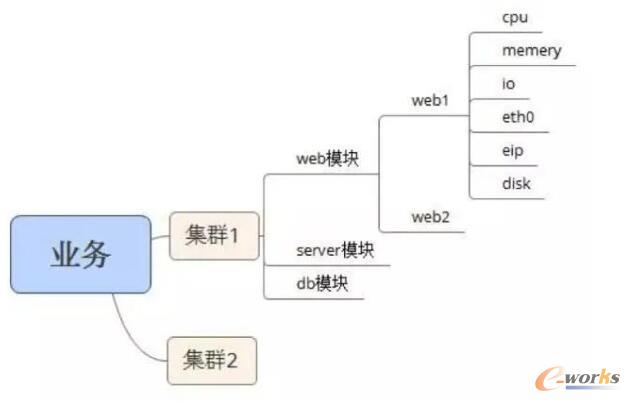
«ö╚╗Ż¼▀\ŠSī”Ž¾▀h▓╗ų╣─Ū├┤╔┘Ż¼▀ĆąĶę¬┤¾╝ęĖ∙ō■ūį╝ęśIäšČÓČÓ═┌Š“Ż¼▀@éĆ▀^│╠▒╚▌^ŲDą┴Ż¼Ą½▓╗ąĶę¬ę╗▓ĮĄĮ╬╗Ż¼Ž╚┤_Č©║├║╦ą─ī”Ž¾Ż¼į┘┬²┬²═Ļ╔Ųča│õŲõ╦¹ī”Ž¾ĪŻ
┼õų├ĒŚī┘ąį
╬ęéā░č CMDB Ą──│éĆī”Ž¾ĘQ×ķ┼õų├ĒŚŻ¼ę╗éĆĄõą═Ą─┼õų├ĒŚ╚ńę╗┼_ų„ÖCĪóę╗éĆė“├¹Īóę╗éĆ IP ĪŻ
┼eéĆ└²ūėŻ¼ę╗┼_ų„ÖCŻ¼Ųõī┘ąį½@╚ĪĄ─╚²ĘNĘĮ╩ĮŻ║
- agent ½@Ą├Ż║╚ń cpuĪómemeryĪódiskĪóethX ų«ŅÉĄ─ė▓╝■ą┼ŽóŻ¼ę╗░Ńė├ python psutil ─ŻēK┐╔ęį½@╚Ī┤¾▓┐Ęų╦∙ąĶꬥ─ī┘ąįŻ╗
- įŲĘ■äš╔╠ apiŻ║ėą▓┐Ęųī┘ąį▓╗─▄═©▀^ agent ½@Ą├Ą─╚ń EIPĪóRegionĪóZone Ą╚Ż¼╚ń╣¹▓╗╩Ūė├įŲų„ÖCĄ─Š═▓╗ąĶę¬▀@ę╗▓┐ĘųŻ╗
- ╩ų╣żŠSūoŻ║ėąą®ī┘ąį▓╗─▄ūįäė½@╚ĪŻ¼ų╗─▄═©▀^╚╦╣żõø╚ļŻ¼▓╗▀^▀@ŅÉī┘ąį▀Ć╩Ū▒M┴┐įĮ╔┘įĮ║├Ż╗
ė╔³cĄĮ├µ┐╔ęį┐┤│÷Ż¼┼õų├ĒŚĄ─ī┘ąįŅÉäe╗∙▒Š┐╔ęįĘų│╔╚²ŅÉŻ║
╚╦╣żõø╚ļ Ż║ ūįäė╗»ŽĄĮy╦∙ąĶĄ─śIäš – ╝»╚║ – ─ŻēKĻPŽĄŻ¼├┐┼_ų„ÖC▀\ąą╩▓├┤Ę■䚥╚Ą╚ĪŻ
═ŌŽĄĮy APIŻ║ ąĶę¬═©▀^įŲĘ■äš╔╠ APIĪóZabbix APIĪóK8s APIĪóŲõ╦¹śI䚎ĄĮy API Ą╚═ŠÅĮĪŻ
ūį░l¼FŻ║ ÖCŲ„ā╚▓┐½@Ą├Ż¼╚ń python psutilĪópuppet factĪóansible setup Ą╚═ŠÅĮĪŻ
┴╦ĮŌī┘ąįŅÉäe┐╔ęįÄ═ų·╬ęéāĖ³║├Ė³┐ņĄž═Ļ╔Ų┼õų├ĒŚĄ─Ė„ĘNī┘ąįūįäė½@╚ĪÖCųŲŻ¼▒M┴┐▒▄├Ō╚╦╣żĖ╔ŅAĪŻ
į┘┴─┴─ų„ÖCŻ¼ų„ÖC╩Ūę╗éĆ│ą╔ŽåóŽ┬Ą─║╦ą─ī”Ž¾Ż¼į┌╦³╔Ē╔Žėą║▄ČÓī┘ąįĢ■▒╗Ė„ĘN╣”─▄╦∙╩╣ė├Ż¼╦∙ęį╬ęéāꬎ╚└ĒŪÕ╦³║═Ųõ╦¹ī”Ž¾Ą─ĻP┬ōĻPŽĄĪŻ
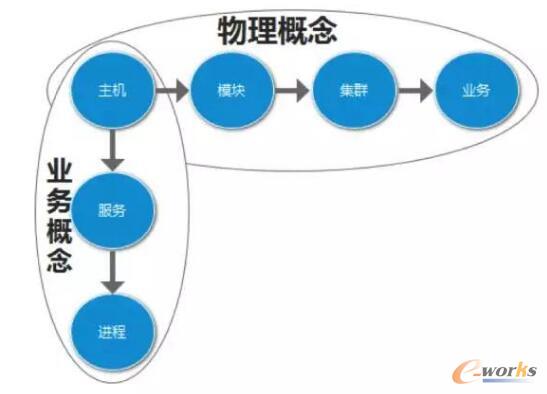
▀@└’Ą─śIäš – ╝»╚║ – ─ŻēK – ų„ÖCī┘ė┌╬’└ĒĖ┼─ŅŻ¼╩ŪÖCŲ„╦∙į┌Ą─╬’└Ēīė┤╬ĻPŽĄŻ¼ę“×ķÖCŲ„▒ž╚╗░ķļSų°ÖCĘ┐ĪóŠWĮjĪó╣Ō└wų«ŅÉĄ─ė▓╝■Ė┼─ŅŻ¼ļm╚╗šf╩Ū╬’└Ēīė┤╬Ż¼Ą½╩Ū─Ńė├įŲĘ■䚥─įÆŻ¼Š═▓╗┤µį┌ų„ÖC▀@éĆīŹ¾wĪŻ
Č°Ę■äš╩ŪÖCŲ„Ą─ę╗éĆśIäšī┘ąįŻ¼ę╗éĆÖCŲ„┐╔ęįī”æ¬ČÓéĆĘ■䚯¼ū„×ķĘ■䚥─Ž┬ę╗╝ēäe╩Ū▀M│╠Ż¼▒╚╚ńę╗éĆ web Ę■äšĢ■ėą nginxĪótomcat Ą╚╚¶Ė╔éĆ▀M│╠Ż¼Č©┴xę╗éĆĘ■äšätąĶę¬┼cų«ĻP┬ōĄ─▀M│╠Ż¼▀M│╠Ą─ų„ę¬ī┘ąįĢ■ėą▀M│╠├¹ĘQĪóŲ═Ż├³┴ŅĪóš╝ė├Č╦┐┌Ą╚ĪŻ
ū„śIŲĮ┼_
Č©┴x
ū„śI╩Ūę╗ŽĄ┴ą▀\ŠS▓┘ū„Ą─│ķŽ¾Č©┴xŻ¼╚╬║╬ę╗éĆ▀\ŠS▓┘ū„Č╝┐╔ęįĘųĮŌ│╔ę╗▓Įę╗▓ĮĄ─▓┘ū„▓Į¾E║═▓┘ū„ī”Ž¾Ż¼▓╗šō╩Ū░l▓╝ūāĖ³▀Ć╩ŪĖµŠ»╠Ä└ĒŻ¼Č╝╩Ū┐╔ęįĘų▓Į¾EĄ─ĪŻ
├³┴ŅŻ║ ę╗éĆ┐╔ęį¬Ü┴óĄ─▓┘ū„Ż¼ūŅ║åå╬Ą─╚ńĻPĘ■Īóķ_Ę■Īół╠ąą xx ─_▒ŠĄ╚Ż╗
╬─╝■Ęų░lŻ║ ░čųĖČ©Ą─╬─╝■Ęų░lĄĮ─┐ś╦ÖCŲ„Ą──┐ś╦┬ĘÅĮŻ╗
ū„śIŻ║ ę╗ŽĄ┴ą├³┴ŅĪó╬─╝■Ęų░lĄ─ėąą“ĮM║ŽŻ¼ū„śIĄ─▓Į¾E┐╔ęįė╔ “├³┴Ņ”Īó“╬─╝■Ęų░l” ęį╝░ “ł╠ąąī”Ž¾” ĮM│╔Ż╗
┼eę╗éĆŽÓī”Å═ļsĄ─▓┘ū„▀^│╠Ż¼╚ńĖ³ą┬┤·┤a▓óųžåóĘ■䚯║
1 . ī” webŻ║ĻPķ] tomcat (/home/tomcat/bin/shutdown.sh)
2 . ī” serverŻ║ĻPķ]śIäšų„▀M│╠ (/home/server/bin/stop.sh)
3 . ī” webŻ║Ęų░lą┬Ą─šŠ³c╬─╝■ (scp xxx yyy)
4 . ī” serverŻ║Ęų░lĘ■äšČ╦╬─╝■ (scp xxx yyy)
5 . ī” webŻ║åóäė tomcat (/home/tomcat/bin/startup.sh)
6 . ī” serverŻ║åóäėśIäšų„▀M│╠ (/home/server/bin/start.sh)
┐╔ęį┐┤│÷Ż¼┴„│╠░³║¼┴╦ę╗ŽĄ┴ą “ī”Ž¾”-“▓┘ū„” Ą─ėąą“Ą─├³┴Ņęį╝░╬─╝■Ęų░lĄ─╝»║ŽĪŻ“ī”Ž¾”┐╔ęį╩Ūę╗éĆĮMĪóę╗éĆ╗“š▀ČÓéĆ IPŻ¼į┌ł╠ąą├³┴ŅĢr║“┐╔ęįį┌ŽĄĮyĄ─Ēō├µäėæBųĖČ©─┐ś╦ī”Ž¾ĪŻ
ū„śIČ©┴xĢrėąĖ„ĘNį÷ähĖ─▓ķ▓┘ū„Ż¼├┐éĆł╠ąą▀^Ą─ū„śIąĶę¬ėøõøł╠ąą╚╦Īół╠ąąĢrķgĪóĮY╩°ĢrķgĪóĘĄ╗žųĄĄ╚ą┼ŽóĪŻ
ł╠ąąĒśą“
ū„śIąĶę¬░┤Ēśą“ł╠ąąŻ¼«öę╗éĆ▓Į¾E│╔╣”║¾▓┼─▄ł╠ąąŽ┬ę╗éĆ▓Į¾EŻ¼╚ń╣¹ł╠ąą╩¦öĪąĶę¬═Żų╣▀\ąąū„śIŻ¼▓ó▒Ż┴¶ł╠ąąĄ─Ė„ĘN╚šųŠĪŻ
▒╚╚ńę╗éĆū„śIČ©┴x╚ńŽ┬Ż║
ī” web ĮMŻ©3 ┼_ÖCŲ„Ż®Ż║ł╠ąą stop tomcatŻ╗
ī” server ĮMŻ©4 ┼_ÖCŲ„Ż®Ż║ł╠ąą stop serverŻ╗
ī” app ĮMŻ©2 ┼_ÖCŲ„Ż®Ż║ł╠ąą stop appŻ╗
ł╠ąą╝Ü╣Ø╩ŪĄ┌ę╗▓Įī” web ĮMĄ─ 3 ┼_ÖCŲ„═¼Ģr░lŲ stop tomcat ├³┴ŅŻ¼Ą╚┤² 3 ┼_ÖCŲ„╚½▓┐ĘĄ╗žĮY╣¹║¾Ż¼╚ń╣¹ĮY╣¹ĘĄ╗ž 0 ▒Ē╩Š├³┴Ņł╠ąą│╔╣”Ż¼▀@Ģr║“▓┼└^└m▀MąąĄ┌Č■▓Įī” server ĮMĄ─┴„│╠ĪŻ╚ń╣¹Ą┌ę╗▓ĮĘĄ╗žĮY╣¹▓╗×ķ 0Ż¼ät╠ß╩Š┴„│╠ł╠ąą╩¦öĪŻ¼╠ß╩ŠąĶę¬╚╦╣żÖz▓ķŻ¼ĮKų╣║¾├µĄ─┴„│╠ĪŻ
ų„ę¬ī”Ž¾
Ž┬├µ┐╔ęį┤¾ų┬«ŗéĆłD╣┤└š│÷ū„śIŲĮ┼_Ą─ų„ę¬ī”Ž¾
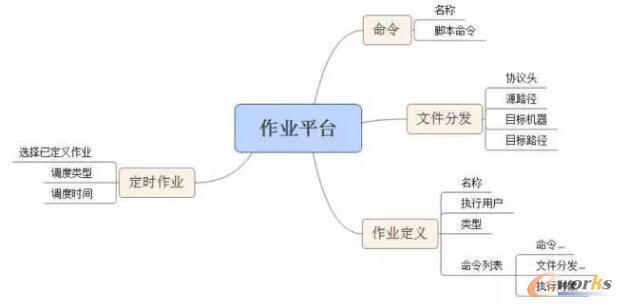
ū„śI▀@éĆĖ┼─ŅĄ─╠ß│÷Ż¼╝┤┐╔ęįīó▀\ŠS╣żū„Ą─Ė„ĘN“ūāĖ³”Īó“░l▓╝”Īó“╣╩šŽ╠Ä└Ē”Ą╚┴Ń╦ķ▓┘ū„ĘųĮŌ│╔ę╗éĆéĆ┐╔Å═ė├Īó┐╔öUš╣Īó┐╔ł╠ąąĄ─¬Ü┴ó▓┘ū„├³┴ŅŻ¼─Ū├┤ūŅĮKŲĮ┼_╗»Ą─ūįäėš{Č╚īó│╔×ķ┐╔─▄ĪŻ
ķ_░lĄ─Ģr║“ŲõĮń├µ║═▓┘ū„ĘĮ╩Į┐╔ęįģó┐╝╦{÷LĄ─ū„śIŲĮ┼_Ż©httpŻ║//bk.tencent.com/document/bkprod/000119.html Ż®Ż¼╬ę╦∙Įėė|▀^Ą─ÄūéĆūįäė╗»ŲĮ┼_Ż©░³└©╔╠śIĄ─║═ŠWęūā╚▓┐Ą─Ż®Č╝╩Ūæ¬ė├┴╦ŅÉ╦ŲĄ─įOėŗĘĮ╩Į Ż¼▀@╦Ń╩Ūę╗éĆĮø▀^▒ŖČÓ▀\ŠSłFĻĀ┐╝“ץ─ūŅ╝čīŹ█`Ż¼╚ń╣¹ø]ėą╩▓├┤╠ž╩ŌśIäšąĶŪ¾Ż¼╗∙▒Š┐╔ęį░┤▀@ĘN─Ż╩Įåóäėęį╠ßĖ▀ķ_░lą¦┬╩ĪŻ
╚╗Č°Ż¼├┐╝ę╣½╦ŠĄ─Š▀¾wśIäšą╬æBøQČ©┴╦▒ž╚╗Ģ■ėą▓Ņ«É╗»Ą─ąĶŪ¾Ż¼ļSęŌ┴ą┼eÄūéĆ░╔ĪŻ
- ū„śIÖÓŽ▐ŽĄĮyŻ¼▓╗═¼ĮŪ╔½ė├æ¶┐╔▓┘ū„▓╗═¼╝ēäeĄ─ū„śIŻ╗
- ū„śI▀\ąąŪ░┤_šJŻ¼▒╚╚ń─│£yįć═¼╩┬åóäėū„śIŻ¼ąĶę¬ī”æ¬ų„│╠╗“š▀ų„▓▀äØ┤_šJ▓┼åóäėŻ╗
- Ą╚┤²┤_šJ│¼ĢrĢrķgŻ¼▒╚╚ńĄ╚┤² 30 ĘųńŖŻ¼╬┤┤_šJät╚ĪŽ¹åóäėŻ╗
- ū„śI«É│ŻĘĄ╗žätł¾Š»Ó]╝■═©ų¬ĄĮ▀\ŠSĮMęį╝░ī”æ¬ĒŚ─┐ĮM═¼╩┬Ż╗
- ╗ęČ╚ł╠ąąŻ¼░┤ū„śIĄ─įOų├Ż¼Ž╚į┌£yįćĘ■▀\ąąŻ¼į┘ĄĮš²╩ĮĘ■Ż╗
- ū„śI┼õų├┐╦┬ĪŻ¼┐ņ╦┘┤ŅĮ©ą┬Ą─ĒŚ─┐Ą─ū„śI┼õų├Ż╗
▓Ņ«É╗»ąĶŪ¾Ą─ķ_░l┐╔ęįį┌║¾Ų┌┬²┬²Ą³┤·Ė─▀MĪŻ
ū„śIł╠ąąŪķørĘų╬÷
╣Ø╝s╚╦┴”ŅA╣└
ę“×ķū„śIŲĮ┼_╩Ūę╗éĆūī▀\ŠSČ©ųŲĖ„ĘNŠĆ╔Ž▓┘ū„Ż¼ĘŌčb╚╬ęŌ─▄═©▀^─_▒Š═Ļ│╔Ą─╣”─▄Ż¼┐╔ęį╣®ūį╝║╗“š▀ĒŚ─┐ĮMūįų·╩╣ė├Ż¼▒M┐╔─▄ū÷ĄĮ▀\ŠS¤o╚╦ųĄ╩žŻ¼▀\ŠS╠ß╣®ĮŌøQĘĮ░ĖŻ¼─Ū├┤ŲõūŅ┤¾ū„ė├Š═╩Ū×ķ▀\ŠS▓┐ķT╣Ø╝s╚╦┴”Ż¼Č┼Į^ųžÅ═ä┌äėĪŻ
ū„śIł╠ąąū„×ķūįäė╗»ŲĮ┼_Ą─║╦ą─╣”─▄Ż¼▒žĒÜ═┌Š“Ųõ└¹ė├ą¦┬╩Ż¼▒╚╚ńĖ∙ō■ł╠ąą╚šųŠĮyėŗ├┐╠ņĪó├┐ų▄Īó├┐į┬ł╠ąą┤╬öĄŻ¼ł╠ąą┐é║─ĢrĄ╚öĄō■Ż¼ęį╣└╦Ń│÷ŲĮ┼_×ķ▀\ŠS╚╦åT╣Ø╩ĪČÓ╔┘╚╦┴”ĪŻ
╩╣ė├ŲĮ┼_Ū░Ż║
ĒŚ─┐═¼╩┬Ę┼Ž┬╩ųŅ^╣żū„ ->═©▀^Ó]╝■╗“š▀ IM ═©ų¬▀\ŠS═¼╩┬ł╠ąą─│ĒŚ▓┘ū„ ->▀\ŠS═¼╩┬Ę┼Ž┬╩ųŅ^╣żū„Ż¼ūxÓ]╝■╗“ IMŻ¼└ĒĮŌĒŚ─┐═¼╩┬Ą─▓┘ū„ā╚╚▌ ->ł╠ąą▓┘ū„ ->═©▀^Ó]╝■╗“š▀ IM Ę┤üĒŚ─┐═¼╩┬ ->▀\ŠS═¼╩┬ĘĄ╗žįŁüĒ╣żū„ ->ĒŚ─┐═¼╩┬Ę┼Ž┬╣żū„ūxÓ]╝■╗“ IM į┘ĘĄ╗žįŁ╣żū„
╩╣ė├ŲĮ┼_║¾Ż║
ĒŚ─┐═¼╩┬▓┘ū„ŲĮ┼_ų▒Įėł╠ąą─│ĒŚ▓┘ū„Ą├ĄĮĘ┤ü
▀@éĆ▀^│╠ī”ė┌ĒŚ─┐═¼╩┬║═▀\ŠS═¼╩┬ļpĘĮ┐é╣▓ų┴╔┘─▄╣Ø╝s╚╦┴” 15 ĘųńŖŻ¼£p╔┘┴╦║▄ČÓ£Ž═©Īó└ĒĮŌĪóĘ┤üĄ─Ģrķg│╔▒ŠĪŻ
ī”ė┌▒╚▌^│ŻęÄĄ─Ųš═©▓┘ū„ät¤oąĶ▀\ŠS═¼╩┬Ė╔ŅAŻ¼│²ĘŪł╠ąą«É│Ż▓┼ąĶę¬▀\ŠS╚╦åTĮķ╚ļĪŻ
╬ęéā═©▀^ĮyėŗĄ├ų¬ŲĮ┼_├┐į┬ł╠ąąū„śIĄ─┐é┤╬öĄ×ķ NŻ¼├┐┤╬ŅAėŗ╣Ø╝s╚╦┴”┘Yį┤ 15 ĘųńŖŻ©0.25 ąĪĢrŻ®Ż¼ät├┐į┬┐é╣Ø╝s╚╦┴”×ķ 0.25Ż¬N ąĪĢrŻ¼╝┘įO N ×ķ 1000Ż¼ät├┐į┬╣Ø╝s▀\ŠS▓┐ķT 250 éĆąĪĢrĄ─╚╦┴”┘Yį┤ĪŻ
ę╗éĆ▀\ŠS╚╦åTę╗╠ņę▓Š═╣żū„ 8 ąĪĢrŻ©▓╗╝ė░ÓĄ─įÆ~Ż®Ż¼ę╗éĆį┬×ķ 21*8=168 ąĪĢrŻ¼─Ū├┤╣Ø╝s 250 ąĪĢrät╝sĄ╚ė┌ 1.5 éĆ▀\ŠS╚╦åTĄ─į┬╣żĢrĪŻ
ė╔┤╦┐╔ęŖ«öū„śIŲĮ┼_Ą─ł╠ąą┤╬öĄįĮ┤¾įĮ─▄ą╬│╔ęÄ─Ż╗»Ż¼ī”╚╦┴”┘Yį┤Ą─╣Ø╩Īą¦╣¹įĮėą└¹Ż¼╝┘įO«ö N = 10000 Ą─Ģr║“Ż¼ŽÓ«öė┌╣Ø╝s┴╦Į³ 15 éĆ▀\ŠS╚╦åTĄ─į┬╣żĢrŻ¼ą¦╣¹▀Ć╩ŪŽÓ«ö┐╔ė^Ą─ĪŻ
ŲĮ┼_Ą─ł╠ąąöĄō■┐╔ęį└¹ė├ echarts ū÷ł¾▒ĒŻ¼ūī▀\ŠS═¼╩┬īŹĢr▓ķ┐┤Üv╩Ęł╠ąą┤╬öĄ║═ŅAėŗ╣Ø╝s╚╦┴”ĪŻ
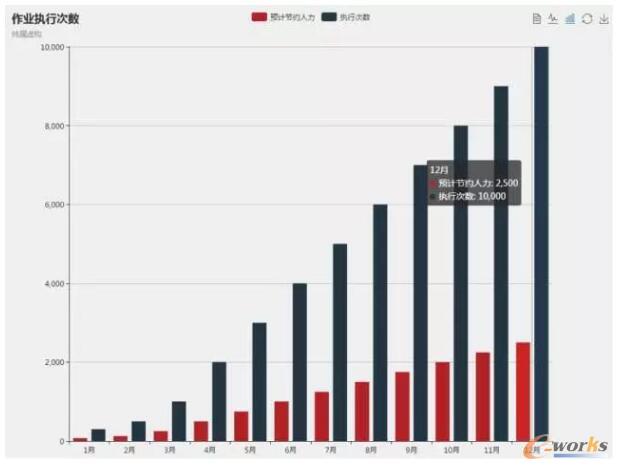
łD▒ĒĮŌ╬÷Ż║X ▌S╩ŪĢrķgŻ¼ęį├┐éĆį┬ū„×ķę╗éĆĢrķgģ^ķgŻ¼Įyėŗįōį┬ę╗╣▓ł╠ąą┴╦ČÓ╔┘éĆū„śIĪŻY ▌SĄ─╩Ūū„śIĄ─ł╠ąą┐é┤╬öĄŻ©╦{╔½▌SŻ¼å╬╬╗┤╬Ż®Ż¼╚╗║¾╝┘įO├┐éĆū„śI╝s╣Ø╝s╚╦┴” 15 ĘųńŖŻ¼ūŅĮKėŗ╦Ń│÷├┐į┬╣Ø╝s╚╦┴”┐éĢrķgŻ©╝t╔½▌SŻ¼å╬╬╗ąĪĢrŻ®ĪŻ
ū„śI«É│ŻĘų╬÷
ū„śIŲĮ┼_┐╔ęįūī▀\ŠS╚╦åTĮŌĘ┼┴╦║▄ČÓä┌äė┴”Ż¼Ą½╩Ū╬ęéāę▓▓╗┐╔─▄▒ŻūC├┐éĆū„śIČ╝─▄š²│Ż▀\ąąŻ¼╚¶į┌ł╠ąą«É│ŻĄ─ŪķørŽ┬Ż¼╬ęéā┐╔ęį×ķ«É│ŻĄ─įŁę“┤“╔Žś╦║ׯ¼┤“ś╦║×┐╔ęįĖ∙ō■Õeš`▌ö│÷ĻPµIūųŲź┼õūįäėĘųŅÉ╗“š▀╚╦╣żÜwŅÉŻ¼╚╗║¾ĮyėŗĖ„ĘN«É│ŻŪķørĄ─▒╚└²Ż¼į┘ųž³cĘų╬÷▓ó╠Ä└Ē«É│Ż▒╚└²Ė▀Ą─ŪķørĪŻ
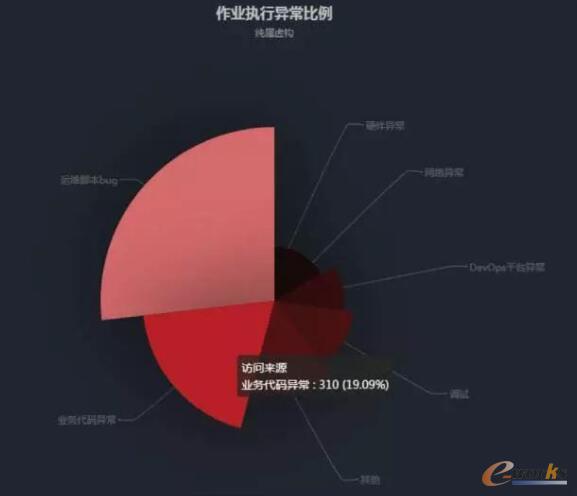
łD▒ĒĮŌ╬÷Ż║ ė╔╔ŽłD┐╔ęį┐┤│÷▀@╩ŪĖ„ĘN«É│ŻĄ─öĄ┴┐Ęų▓╝ŪķørŻ¼«É│ŻĄ─ĘųŅÉ╩ŪąĶę¬▀\ŠSŅAŽ╚Č©┴x▓óŪęėąūŃē“Ą─ģ^ĘųČ╚ĪŻ╚╗║¾Ė∙ō■ū„śIį┌ę╗éĆĢrķgģ^ķgā╚Įyėŗ│÷Ė„ĘN«É│ŻĄ─▒╚└²Ż¼į┘└¹ė├’×ĀŅłD┐╔ęįĘĮ▒ŃšęĄĮ▒╚└²ūŅĖ▀Ą─╚¶Ė╔ĒŚŻ¼╚ń╔ŽłD╩ŪĪŠ▀\ŠS─_▒Š bugĪ┐║═ĪŠśIäš┤·┤a«É│ŻĪ┐▒╚└²ūŅĖ▀Ż¼į┘ų°ųžĘų╬÷ĮŌøQ▀@ŅÉ«É│ŻĄ─įŁę“üĒĮĄĄ═▀\ŠS▓┘ū„╣╩šŽ┬╩ĪŻ
┐éĮY
▀\ŠSūįäė╗»ŲĮ┼_Ą─Į©įO▒Š┘|╩Ū▀\ŠSłFĻĀĘ■äš╗»─▄┴”Ą─ūā¼F▀^│╠Ż¼╦³ūī╬ęéāÅ─┤¾┴┐ųžÅ═¤oęÄ┬╔Ą─╚╦╚Ō▓┘ū„ųąĮŌĘ┼│÷üĒŻ¼īŻūóė┌▀\ŠSĘ■äš┘|┴┐Ą─╠ß╔²ĪŻė╔ė┌╬─š┬Ų¬Ę∙╦∙Ž▐Ż¼╬┤─▄║═┤¾╝ę╚½├µĮķĮBš¹éĆūįäė╗»ŲĮ┼_Ą─įOėŗ╦╝┬ĘŻ¼░┤ŽĄĮyĄ─║╦ą─│╠Č╚üĒäØĘųŻ¼ūŅ║╦ą─Ą─╩Ū CMDB ║═ū„śIŲĮ┼_Ż¼«ö═Ļ│╔▀@ā╔▓┐Ęųų«║¾Ż¼┤╬║╦ą─Ą─ CI/CDĪóöĄō■ŲĮ┼_Īó▒O┐žŲĮ┼_ę▓┐╔ęį═Č╚ļķ_░lŻ¼║¾├µĄ─▀\ĀI▌oų·Īó╣╩šŽūįė·ĪóųŪ─▄öU╚▌┐s╚▌╔§ų┴ AiOps Ą╚ę▓ąĶę¬ DevOps łFĻĀ└^└m╠Į╦„ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ųąąĪą═▀\ŠSłFĻĀ╚ń║╬įOėŗ▀\ŠSūįäė╗»ŲĮ┼_
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/11121521486.html