



«ö(d©Īng)╬ęéā╝▄įO(sh©©)ę╗éĆŽĄĮy(t©»ng)Ą─Ģr║“═©│ŻąĶę¬┐╝æ]ĄĮ╚ń║╬┼cŲõ╦¹ŽĄĮy(t©»ng)Į╗╗źŻ¼╦∙ęį╬ęéā╩ūŽ╚ąĶę¬ų¬Ą└Ė„ĘNŽĄĮy(t©»ng)ų«ķg╩Ū╚ń║╬Į╗╗źĄ─Ż¼╩╣ė├║╬ĘN╝╝ąg(sh©┤)īŹ(sh©¬)¼F(xi©żn)ĪŻ
1.▓╗═¼ŽĄĮy(t©»ng)▓╗═¼šZčįų«ķgĄ─Į╗╗ź
¼F(xi©żn)į┌╬ęéā│ŻęŖĄ─▓╗═¼ŽĄĮy(t©»ng)▓╗═¼šZčįų«ķgĄ─Į╗╗ź╩╣ė├WebServiceŻ¼HttpšłŪ¾ĪŻWebServiceŻ¼╝┤“WebĘ■äš(w©┤)”Ż¼║åīæ×ķWSĪŻÅ─ūų├µ╔Ž└ĒĮŌŻ¼╦³ŲõīŹ(sh©¬)Š═╩Ū“╗∙ė┌WebĄ─Ę■äš(w©┤)”ĪŻČ°Ę■äš(w©┤)ģs╩ŪļpĘĮĄ─Ż¼ėąĘ■äš(w©┤)ąĶŪ¾ĘĮŻ¼Š═ėąĘ■äš(w©┤)╠ß╣®ĘĮĪŻĘ■äš(w©┤)╠ß╣®ĘĮī”═Ō░l(f©Ī)▓╝Ę■äš(w©┤)Ż¼Ę■äš(w©┤)ąĶŪ¾ĘĮš{(di©żo)ė├Ę■äš(w©┤)╠ß╣®ĘĮ╦∙░l(f©Ī)▓╝Ą─Ę■äš(w©┤)ĪŻ╚ń╣¹šfĄ├į┘īŻśI(y©©)ę╗³c(di©Żn)Ż¼WSŲõīŹ(sh©¬)Š═╩ŪĮ©┴óį┌HTTPģf(xi©”)ūh╔ŽīŹ(sh©¬)¼F(xi©żn)«Éśŗ(g©░u)ŽĄĮy(t©»ng)═©ėŹĄ─╣żŠ▀ĪŻø]ÕeŻĪWSšf░ū┴╦▀Ć╩Ū╗∙ė┌HTTPģf(xi©”)ūhĄ─Ż¼ę▓Š═╩ŪšfŻ¼öĄ(sh©┤)ō■(j©┤)╩Ū═©▀^HTTP▀M(j©¼n)ąąé„▌ö?sh©┤)─ĪŻūŅįń╬ęéā╩Ūė├CXFķ_░l(f©Ī)SOAPĘ■äš(w©┤)īŹ(sh©¬)¼F(xi©żn)WSŻ¼║¾├µ╬ęéā╩Ūė├RESTĘ■äš(w©┤)īŹ(sh©¬)¼F(xi©żn)WS(▀@éĆ─┐Ū░╩╣ė├▒╚▌^ČÓŻ¼ę▓ūŅ╬ęė├Ą├ūŅČÓĄ─▀@ę╗ĘN)ĪŻ╗∙ė┌CXFę▓┐╔ęįķ_░l(f©Ī)RESTĘ■äš(w©┤)Ż¼▓╗▀^╬ęéāę╗░Ńų▒Įė╩╣ė├springMVC╗“š▀Ųõ╦¹MVC┐“╝▄īŹ(sh©¬)¼F(xi©żn)RESTĘ■äš(w©┤)ĪŻ
Ą½╩Ūį┌║▄ČÓ╚╦Ą─ėĪŽ¾ųąWeb serviceĄ─įÆę╗░ŃųĖ╩«üĒ─ĻŪ░IBMų„ī¦(d©Żo)Ą─╗∙ė┌XMLĄ─Ė„ĘNĮ╗╗ź╝╝ąg(sh©┤)Ż¼¼F(xi©żn)į┌│²┴╦ę╗ą®╣½╦Šį┌ė├ų«═Ōė├Ą├╚╦ę▓║▄╔┘┴╦ĪŻÅV┴xĄ─įÆWebserviceŠ═╩ŪWebĘ■äš(w©┤)┴╦Ż¼ę╗ŪąĮįĘ■äš(w©┤)ĪŻ
2.▓╗═¼ŽĄĮy(t©»ng)ŽÓ═¼šZčįų«ķgĄ─Į╗╗ź
│ŻęŖĄ─▓╗═¼ŽĄĮy(t©»ng)ŽÓ═¼šZčįų«ķgĄ─Į╗╗źė├RPC(▀h(yu©Żn)│╠▀^│╠š{(di©żo)ė├)Ż¼╗“š▀RMI(▀h(yu©Żn)│╠ĘĮĘ©š{(di©żo)ė├)īŹ(sh©¬)¼F(xi©żn)Ż¼▓╗ė├ī”═Ō▓┐╠ß╣®Ę■äš(w©┤)Ż¼«ö(d©Īng)╚╗╔Ž├µšfĄ─ę▓┐╔ęį╩╣ė├į┌ŽÓ═¼šZčįų«ķgĄ─Į╗╗źŻ¼ų╗╩Ū╬ę│Żė├Ą─╩ŪRPCĪŻ
3.å╬éĆ«a(ch©Żn)ŲĘĄ─╝▄śŗ(g©░u)č▌▀M(j©¼n)
ę╗░Ń╬ęéāų╗╩Ūę╗éĆ«a(ch©Żn)ŲĘĄ─ŪķørŽ┬Ą─╝▄śŗ(g©░u)č▌▀M(j©¼n)Üv│╠Ż¼╚ń╣¹ąĶę¬ī”═Ō╠ß╣®webServiceŻ¼═©│Ż╩╣ė├RESTĘ■äš(w©┤)īŹ(sh©¬)¼F(xi©żn)ĪŻ
ęįŽ┬ę╗Č╬ā╚(n©©i)╚▌üĒį┤ė┌ų¬║§
1.Ęų▓╝╩Į╝▄śŗ(g©░u)Ą─č▌▀M(j©¼n)ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-│§╩╝ļAČ╬╝▄śŗ(g©░u)
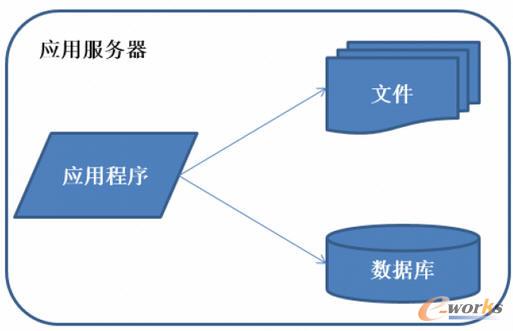
łD1 Ęų▓╝╩Į╝▄śŗ(g©░u)Ą─č▌▀M(j©¼n)ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-│§╩╝ļAČ╬╝▄śŗ(g©░u)
│§╩╝ļAČ╬Ą─ąĪą═ŽĄĮy(t©»ng)æ¬(y©®ng)ė├│╠ą“ĪóöĄ(sh©┤)ō■(j©┤)ÄņĪó╬─╝■Ą╚╦∙ėąĄ─┘Yį┤Č╝į┌ę╗┼_Ę■äš(w©┤)Ų„╔Ž═©╦ūĘQ×ķLAMP╠žš„Ż║æ¬(y©®ng)ė├│╠ą“ĪóöĄ(sh©┤)ō■(j©┤)ÄņĪó╬─╝■Ą╚╦∙ėąĄ─┘Yį┤Č╝į┌ę╗┼_Ę■äš(w©┤)Ų„╔ŽĪŻ
├Ķ╩÷Ż║═©│ŻĘ■äš(w©┤)Ų„▓┘ū„ŽĄĮy(t©»ng)╩╣ė├linuxŻ¼æ¬(y©®ng)ė├│╠ą“╩╣ė├PHPķ_░l(f©Ī)Ż¼╚╗║¾▓┐╩į┌Apache╔ŽŻ¼öĄ(sh©┤)ō■(j©┤)Äņ╩╣ė├MysqlŻ¼ģR╝»Ė„ĘN├Ō┘M(f©©i)ķ_į┤▄ø╝■ęį╝░ę╗┼_┴«ārĘ■äš(w©┤)Ų„Š═┐╔ęįķ_╩╝ŽĄĮy(t©»ng)Ą─░l(f©Ī)š╣ų«┬Ę┴╦ĪŻ
2.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-æ¬(y©®ng)ė├Ę■äš(w©┤)║═öĄ(sh©┤)ō■(j©┤)Ę■äš(w©┤)Ęųļx
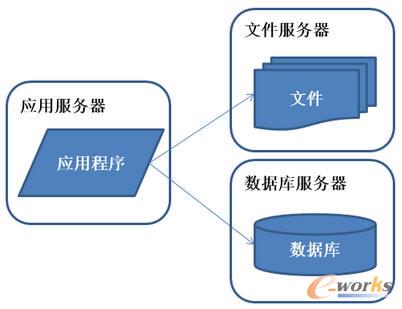
łD2 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-æ¬(y©®ng)ė├Ę■äš(w©┤)║═öĄ(sh©┤)ō■(j©┤)Ę■äš(w©┤)Ęųļx
║├Š░▓╗ķLŻ¼░l(f©Ī)¼F(xi©żn)ļSų°ŽĄĮy(t©»ng)įLå¢┴┐Ą─į┘Č╚į÷╝ėŻ¼webserverÖC(j©®)Ų„Ą─ē║┴”į┌Ė▀ĘÕŲ┌Ģ■╔Ž╔²ĄĮ▒╚▌^Ė▀Ż¼▀@éĆĢr║“ķ_╩╝┐╝æ]į÷╝ėę╗┼_webserver╠žš„Ż║æ¬(y©®ng)ė├│╠ą“ĪóöĄ(sh©┤)ō■(j©┤)ÄņĪó╬─╝■Ęųäe▓┐╩į┌¬Ü(d©▓)┴óĄ─┘Yį┤╔ŽĪŻ
├Ķ╩÷Ż║öĄ(sh©┤)ō■(j©┤)┴┐į÷╝ėŻ¼å╬┼_Ę■äš(w©┤)Ų„ąį─▄╝░┤µā”┐šķg▓╗ūŃŻ¼ąĶę¬īóæ¬(y©®ng)ė├║═öĄ(sh©┤)ō■(j©┤)ĘųļxŻ¼▓ó░l(f©Ī)╠Ä└Ē─▄┴”║═öĄ(sh©┤)ō■(j©┤)┤µā”┐šķgĄ├ĄĮ┴╦║▄┤¾Ė─╔ŲĪŻ
3.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-╩╣ė├ŠÅ┤µĖ─╔Ųąį─▄
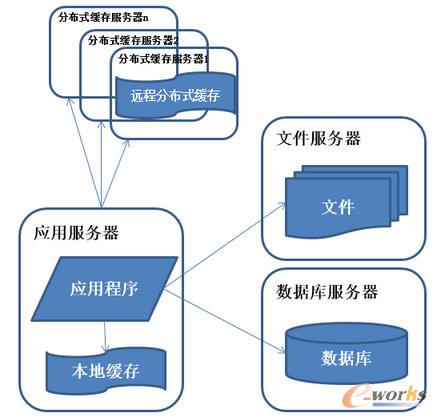
łD3 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-╩╣ė├ŠÅ┤µĖ─╔Ųąį─▄
╠žš„Ż║öĄ(sh©┤)ō■(j©┤)ÄņųąįLå¢▌^╝»ųąĄ─ę╗ąĪ▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)┤µā”į┌ŠÅ┤µĘ■äš(w©┤)Ų„ųąŻ¼£p╔┘öĄ(sh©┤)ō■(j©┤)ÄņĄ─įLå¢┤╬öĄ(sh©┤)Ż¼ĮĄĄ═öĄ(sh©┤)ō■(j©┤)ÄņĄ─įLå¢ē║┴”ĪŻ├Ķ╩÷Ż║ŽĄĮy(t©»ng)įLå¢╠ž³c(di©Żn)ū±čŁČ■░╦Č©┬╔Ż¼╝┤80%Ą─śI(y©©)äš(w©┤)įLå¢╝»ųąį┌20%Ą─öĄ(sh©┤)ō■(j©┤)╔ŽĪŻŠÅ┤µĘų×ķ▒ŠĄžŠÅ┤µ║═▀h(yu©Żn)│╠Ęų▓╝╩ĮŠÅ┤µŻ¼▒ŠĄžŠÅ┤µįLå¢╦┘Č╚Ė³┐ņĄ½ŠÅ┤µöĄ(sh©┤)ō■(j©┤)┴┐ėąŽ▐Ż¼═¼Ģr┤µį┌┼cæ¬(y©®ng)ė├│╠ą“ĀÄė├ā╚(n©©i)┤µĄ─ŪķørĪŻ
4.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-╩╣ė├æ¬(y©®ng)ė├Ę■äš(w©┤)Ų„╝»╚║
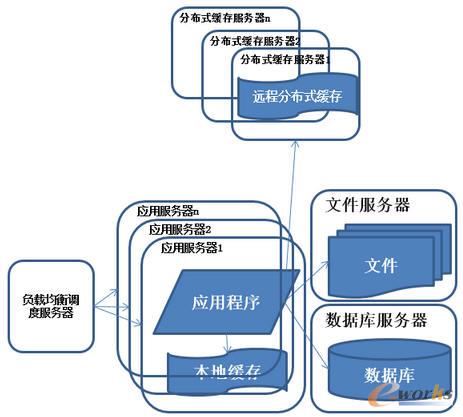
łD4 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-╩╣ė├æ¬(y©®ng)ė├Ę■äš(w©┤)Ų„╝»╚║
į┌ū÷═ĻĘųÄņĘų▒Ē▀@ą®╣żū„║¾Ż¼öĄ(sh©┤)ō■(j©┤)Äņ╔ŽĄ─ē║┴”ęčĮø(j©®ng)ĮĄĄĮ▒╚▌^Ą═┴╦Ż¼ėųķ_╩╝▀^ų°├┐╠ņ┐┤ų°įLå¢┴┐▒®į÷Ą─ąęĖŻ╔·╗Ņ┴╦Ż¼═╗╚╗ėąę╗╠ņŻ¼░l(f©Ī)¼F(xi©żn)ŽĄĮy(t©»ng)Ą─įLå¢ėųķ_╩╝ėąūā┬²Ą─┌ģä▌┴╦Ż¼▀@éĆĢr║“╩ūŽ╚▓ķ┐┤öĄ(sh©┤)ō■(j©┤)ÄņŻ¼ē║┴”ę╗Ūąš²│ŻŻ¼ų«║¾▓ķ┐┤webserverŻ¼░l(f©Ī)¼F(xi©żn)apacheūĶ╚¹┴╦║▄ČÓĄ─šłŪ¾Ż¼Č°æ¬(y©®ng)ė├Ę■äš(w©┤)Ų„ī”├┐éĆšłŪ¾ę▓╩Ū▒╚▌^┐ņĄ─Ż¼┐┤üĒ╩ŪšłŪ¾öĄ(sh©┤)╠½Ė▀ī¦(d©Żo)ų┬ąĶę¬┼┼ĻĀ(du©¼)Ą╚┤²Ż¼Ēææ¬(y©®ng)╦┘Č╚ūā┬²╠žš„Ż║ČÓ┼_Ę■äš(w©┤)Ų„═©▀^žō(f©┤)▌dŠ∙║Ō═¼ĢrŽ“═Ō▓┐╠ß╣®Ę■äš(w©┤)Ż¼ĮŌøQå╬┼_Ę■äš(w©┤)Ų„╠Ä└Ē─▄┴”║═┤µā”┐šķg╔ŽŽ▐Ą─å¢Ņ}ĪŻ
├Ķ╩÷Ż║╩╣ė├╝»╚║╩ŪŽĄĮy(t©»ng)ĮŌøQĖ▀▓ó░l(f©Ī)Īó║Ż┴┐öĄ(sh©┤)ō■(j©┤)å¢Ņ}Ą─│Żė├╩ųČ╬ĪŻ═©▀^Ž“╝»╚║ųąūĘ╝ė┘Yį┤Ż¼╠ß╔²ŽĄĮy(t©»ng)Ą─▓ó░l(f©Ī)╠Ä└Ē─▄┴”Ż¼╩╣Ą├Ę■äš(w©┤)Ų„Ą─žō(f©┤)▌dē║┴”▓╗į┘│╔×ķš¹éĆŽĄĮy(t©»ng)Ą─Ų┐ŅiĪŻ
5.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-öĄ(sh©┤)ō■(j©┤)ÄņūxīæĘųļx
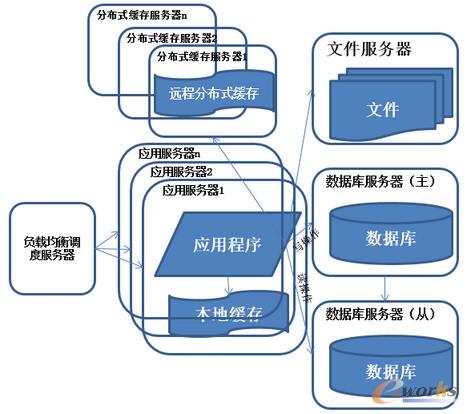
łD5 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-öĄ(sh©┤)ō■(j©┤)ÄņūxīæĘųļx
ŽĒ╩▄┴╦ę╗Č╬ĢrķgĄ─ŽĄĮy(t©»ng)įLå¢┴┐Ė▀╦┘į÷ķLĄ─ąęĖŻ║¾Ż¼░l(f©Ī)¼F(xi©żn)ŽĄĮy(t©»ng)ėųķ_╩╝ūā┬²┴╦Ż¼▀@┤╬ėų╩Ū╩▓├┤ĀŅør─žŻ¼Įø(j©®ng)▀^▓ķšęŻ¼░l(f©Ī)¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)Äņīæ╚ļĪóĖ³ą┬Ą─▀@ą®▓┘ū„Ą─▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)Äņ▀BĮėĄ─┘Yį┤ĖéĀÄĘŪ│Ż╝ż┴ęŻ¼ī¦(d©Żo)ų┬┴╦ŽĄĮy(t©»ng)ūā┬²╠žš„Ż║ČÓ┼_Ę■äš(w©┤)Ų„═©▀^žō(f©┤)▌dŠ∙║Ō═¼ĢrŽ“═Ō▓┐╠ß╣®Ę■äš(w©┤)Ż¼ĮŌøQå╬┼_Ę■äš(w©┤)Ų„╠Ä└Ē─▄┴”║═┤µā”┐šķg╔ŽŽ▐Ą─å¢Ņ}ĪŻ
├Ķ╩÷Ż║╩╣ė├╝»╚║╩ŪŽĄĮy(t©»ng)ĮŌøQĖ▀▓ó░l(f©Ī)Īó║Ż┴┐öĄ(sh©┤)ō■(j©┤)å¢Ņ}Ą─│Żė├╩ųČ╬ĪŻ═©▀^Ž“╝»╚║ųąūĘ╝ė┘Yį┤Ż¼╩╣Ą├Ę■äš(w©┤)Ų„Ą─žō(f©┤)▌dē║┴”▓╗į┌│╔×ķš¹éĆŽĄĮy(t©»ng)Ą─Ų┐ŅiĪŻ
6.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ę┤Ž“┤·└Ē║═CDN╝ė╦┘
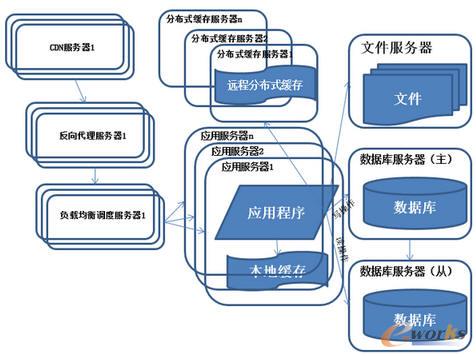
łD6 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ę┤Ž“┤·└Ē║═CDN╝ė╦┘
╠žš„Ż║▓╔ė├CDN║═Ę┤Ž“┤·└Ē╝ė┐ņŽĄĮy(t©»ng)Ą─įLå¢╦┘Č╚ĪŻ├Ķ╩÷Ż║×ķ┴╦æ¬(y©®ng)ĖČÅ═(f©┤)ļsĄ─ŠW(w©Żng)Įj(lu©░)Łh(hu©ón)Š│║═▓╗═¼Ąžģ^(q©▒)ė├æ¶Ą─įLå¢Ż¼═©▀^CDN║═Ę┤Ž“┤·└Ē╝ė┐ņė├æ¶įLå¢Ą─╦┘Č╚Ż¼═¼Ģr£p▌p║¾Č╦Ę■äš(w©┤)Ų„Ą─žō(f©┤)▌dē║┴”ĪŻCDN┼cĘ┤Ž“┤·└ĒĄ─╗∙▒ŠįŁ└ĒČ╝╩ŪŠÅ┤µĪŻ
7.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ
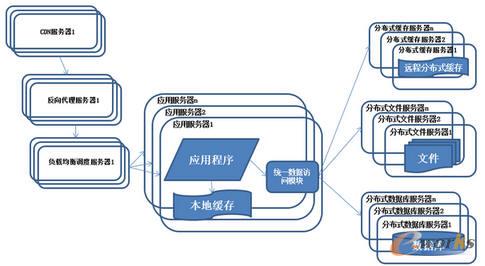
łD7 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ
ļSų°ŽĄĮy(t©»ng)Ą─▓╗öÓ▀\(y©┤n)ąąöĄ(sh©┤)ō■(j©┤)┴┐ķ_╩╝┤¾Ę∙Č╚į÷ķLŻ¼▀@éĆĢr║“░l(f©Ī)¼F(xi©żn)ĘųÄņ║¾▓ķįā?n©©i)į╚╗Ģ■ėąą®┬²Ż¼ė┌╩Ū░┤ššĘųÄņĄ─╦╝Žļķ_╩╝ū÷Ęų▒ĒĄ─╣żū„╠žš„Ż║öĄ(sh©┤)ō■(j©┤)Äņ▓╔ė├Ęų·▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŻ¼╬─╝■ŽĄĮy(t©»ng)▓╔ė├Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)ĪŻ
├Ķ╩÷Ż║╚╬║╬ÅŖ(qi©óng)┤¾Ą─å╬ę╗Ę■äš(w©┤)Ų„Č╝ØMūŃ▓╗┴╦┤¾ą═ŽĄĮy(t©»ng)│ų└m(x©┤)į÷ķLĄ─śI(y©©)äš(w©┤)ąĶŪ¾Ż¼öĄ(sh©┤)ō■(j©┤)ÄņūxīæĘųļxļSų°śI(y©©)äš(w©┤)Ą─░l(f©Ī)š╣ūŅĮKę▓īó¤oĘ©ØMūŃąĶŪ¾Ż¼ąĶę¬╩╣ė├Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╝░Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)üĒų¦ō╬ĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩ŪŽĄĮy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ▓ĘųĄ─ūŅ║¾ĘĮĘ©Ż¼ų╗ėąį┌å╬▒ĒöĄ(sh©┤)ō■(j©┤)ęÄ(gu©®)─ŻĘŪ│Ż²ŗ┤¾Ą─Ģr║“▓┼╩╣ė├Ż¼Ė³│Żė├Ą─öĄ(sh©┤)ō■(j©┤)Äņ▓Ęų╩ųČ╬╩ŪśI(y©©)äš(w©┤)ĘųÄņŻ¼īó▓╗═¼Ą─śI(y©©)äš(w©┤)öĄ(sh©┤)ō■(j©┤)Äņ▓┐╩į┌▓╗═¼Ą─╬’└ĒĘ■äš(w©┤)Ų„╔ŽĪŻ
8.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-╩╣ė├NoSQL║═╦č╦„ę²Ūµ
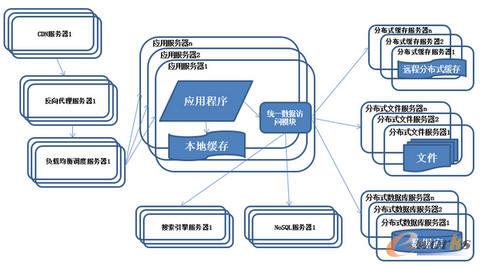
łD8 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ
╠žš„Ż║ŽĄĮy(t©»ng)ę²╚ļNoSQLöĄ(sh©┤)ō■(j©┤)Äņ╝░╦č╦„ę²ŪµĪŻ├Ķ╩÷Ż║ļSų°śI(y©©)äš(w©┤)įĮüĒįĮÅ═(f©┤)ļsŻ¼ī”öĄ(sh©┤)ō■(j©┤)┤µā”║═Öz╦„Ą─ąĶŪ¾ę▓įĮüĒįĮÅ═(f©┤)ļsŻ¼ŽĄĮy(t©»ng)ąĶę¬▓╔ė├ę╗ą®ĘŪĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ╚ńNoSQL║═Ęų?j©½n)?sh©┤)ō■(j©┤)Äņ▓ķįā╝╝ąg(sh©┤)╚ń╦č╦„ę²ŪµĪŻæ¬(y©®ng)ė├Ę■äš(w©┤)Ų„═©▀^Įy(t©»ng)ę╗öĄ(sh©┤)ō■(j©┤)įLå¢─ŻēKįLå¢Ė„ĘNöĄ(sh©┤)ō■(j©┤)Ż¼£p▌pæ¬(y©®ng)ė├│╠ą“╣▄└ĒųTČÓöĄ(sh©┤)ō■(j©┤)į┤Ą─┬ķ¤®ĪŻ
9.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-śI(y©©)äš(w©┤)▓Ęų
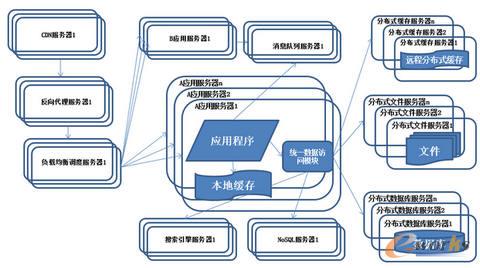
łD9 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-śI(y©©)äš(w©┤)▓Ęų
╠žš„Ż║ŽĄĮy(t©»ng)╔Ž░┤ššśI(y©©)äš(w©┤)▀M(j©¼n)ąą▓ĘųĖ─įņŻ¼æ¬(y©®ng)ė├Ę■äš(w©┤)Ų„░┤ššśI(y©©)äš(w©┤)ģ^(q©▒)Ęų▀M(j©¼n)ąąĘųäe▓┐╩ĪŻ├Ķ╩÷Ż║×ķ┴╦æ¬(y©®ng)ī”╚šęµÅ═(f©┤)ļsĄ─śI(y©©)äš(w©┤)ł÷Š░Ż¼═©│Ż╩╣ė├ĘųČ°ų╬ų«Ą─╩ųČ╬īóš¹éĆŽĄĮy(t©»ng)śI(y©©)äš(w©┤)Ęų│╔▓╗═¼Ą─«a(ch©Żn)ŲĘŠĆŻ¼æ¬(y©®ng)ė├ų«ķg═©▀^│¼µ£ĮėĮ©┴óĻP(gu©Īn)ŽĄŻ¼ę▓┐╔ęį═©▀^Ž¹ŽóĻĀ(du©¼)┴ą▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų░l(f©Ī)Ż¼«ö(d©Īng)╚╗Ė³ČÓĄ─▀Ć╩Ū═©▀^įLå¢═¼ę╗éĆöĄ(sh©┤)ō■(j©┤)┤µā”ŽĄĮy(t©»ng)üĒśŗ(g©░u)│╔ę╗éĆĻP(gu©Īn)┬ō(li©ón)Ą─═Ļš¹ŽĄĮy(t©»ng)ĪŻ┐vŽ“▓ĘųŻ║īóę╗éĆ┤¾æ¬(y©®ng)ė├▓Ęų×ķČÓéĆąĪæ¬(y©®ng)ė├Ż¼╚ń╣¹ą┬śI(y©©)äš(w©┤)▌^×ķ¬Ü(d©▓)┴óŻ¼─Ū├┤Š═ų▒ĮėīóŲõįO(sh©©)ėŗ▓┐╩×ķę╗éƬÜ(d©▓)┴óĄ─Webæ¬(y©®ng)ė├ŽĄĮy(t©»ng)┐vŽ“▓ĘųŽÓī”▌^×ķ║åå╬Ż¼═©▀^╩ß└ĒśI(y©©)äš(w©┤)Ż¼īó▌^╔┘ŽÓĻP(gu©Īn)Ą─śI(y©©)äš(w©┤)äāļx╝┤┐╔ĪŻÖMŽ“▓ĘųŻ║īóÅ═(f©┤)ė├Ą─śI(y©©)äš(w©┤)▓Ęų│÷üĒŻ¼¬Ü(d©▓)┴ó▓┐╩×ķĘų▓╝╩ĮĘ■äš(w©┤)Ż¼ą┬į÷śI(y©©)äš(w©┤)ų╗ąĶ꬚{(di©żo)ė├▀@ą®Ęų▓╝╩ĮĘ■äš(w©┤)ÖMŽ“▓ĘųąĶę¬ūRäe┐╔Å═(f©┤)ė├Ą─śI(y©©)äš(w©┤)Ż¼įO(sh©©)ėŗĘ■äš(w©┤)Įė┐┌Ż¼ęÄ(gu©®)ĘČĘ■äš(w©┤)ę└┘ćĻP(gu©Īn)ŽĄĪŻ
10.ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ęų▓╝╩ĮĘ■äš(w©┤)
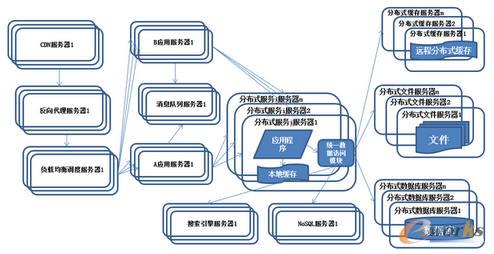
łD10 ŽĄĮy(t©»ng)╝▄śŗ(g©░u)č▌╗»Üv│╠-Ęų▓╝╩ĮĘ■äš(w©┤)
╠žš„Ż║╣½╣▓Ą─æ¬(y©®ng)ė├─ŻēK▒╗╠ß╚Ī│÷üĒŻ¼▓┐╩į┌Ęų▓╝╩ĮĘ■äš(w©┤)Ų„╔Ž╣®æ¬(y©®ng)ė├Ę■äš(w©┤)Ų„š{(di©żo)ė├ĪŻ├Ķ╩÷Ż║ļSų°śI(y©©)äš(w©┤)įĮ▓įĮąĪŻ¼æ¬(y©®ng)ė├ŽĄĮy(t©»ng)š¹¾wÅ═(f©┤)ļs│╠Č╚│╩ųĖöĄ(sh©┤)╝ē╔Ž╔²Ż¼ė╔ė┌╦∙ėąæ¬(y©®ng)ė├ę¬║═╦∙ėąöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)▀BĮėŻ¼ūŅĮKī¦(d©Żo)ų┬öĄ(sh©┤)ō■(j©┤)Äņ▀BĮė┘Yį┤▓╗ūŃŻ¼Š▄Į^Ę■äš(w©┤)ĪŻ
QŻ║Ęų▓╝╩ĮĘ■äš(w©┤)æ¬(y©®ng)ė├Ģ■├µ┼R──ą®å¢Ņ}Ż┐
(1)«ö(d©Īng)Ę■äš(w©┤)įĮüĒįĮČÓĢrŻ¼Ę■äš(w©┤)URL┼õų├╣▄└ĒūāĄ├ĘŪ│Ż└¦ļyŻ¼F(xi©żn)5ė▓╝■žō(f©┤)▌dŠ∙║ŌŲ„Ą─å╬³c(di©Żn)ē║┴”ę▓įĮüĒįĮ┤¾ĪŻ
(2)«ö(d©Īng)▀M(j©¼n)ę╗▓Į░l(f©Ī)š╣Ż¼Ę■äš(w©┤)ķgę└┘ćĻP(gu©Īn)ŽĄūāĄ├Õe█ÖÅ═(f©┤)ļsŻ¼╔§ų┴Ęų▓╗ŪÕ──éĆæ¬(y©®ng)ė├ę¬į┌──éĆæ¬(y©®ng)ė├ų«Ū░åóäėŻ¼╝▄śŗ(g©░u)ĤČ╝▓╗─▄═Ļš¹Ą─├Ķ╩÷æ¬(y©®ng)ė├Ą─╝▄śŗ(g©░u)ĻP(gu©Īn)ŽĄĪŻ
(3)Įėų°Ż¼Ę■äš(w©┤)Ą─š{(di©żo)ė├┴┐įĮüĒįĮ┤¾Ż¼Ę■äš(w©┤)Ą─╚▌┴┐å¢Ņ}Š═▒®┬Č│÷üĒŻ¼▀@éĆĘ■äš(w©┤)ąĶę¬ČÓ╔┘ÖC(j©®)Ų„ų¦ō╬Ż┐╩▓├┤Ģr║“įō╝ėÖC(j©®)Ų„Ż┐
(4)Ę■äš(w©┤)ČÓ┴╦Ż¼£Ž═©│╔▒Šę▓ķ_╩╝╔Ž╔²Ż¼š{(di©żo)─│éĆĘ■äš(w©┤)╩¦öĪįōšęšlŻ┐Ę■äš(w©┤)Ą─ģóöĄ(sh©┤)Č╝ėą╩▓├┤╝sČ©Ż┐
(5)ę╗éĆĘ■äš(w©┤)ėąČÓéĆśI(y©©)äš(w©┤)Ž¹┘M(f©©i)š▀Ż¼╚ń║╬┤_▒ŻĘ■äš(w©┤)┘|(zh©¼)┴┐Ż┐
(6)ļSų°Ę■äš(w©┤)Ą─▓╗═Ż╔²╝ēŻ¼┐éėąą®ęŌŽļ▓╗ĄĮĄ─╩┬░l(f©Ī)╔·Ż¼▒╚╚ńcacheīæÕe┴╦ī¦(d©Żo)ų┬ā╚(n©©i)┤µęń│÷Ż¼╣╩šŽ▓╗┐╔▒▄├ŌŻ¼├┐┤╬║╦ą─Ę■äš(w©┤)ę╗ÆņŻ¼ė░Ēæę╗┤¾Ų¼Ż¼╚╦ą─╗┼╗┼Ż¼╚ń║╬┐žųŲ╣╩šŽĄ─ė░Ēæ├µŻ┐Ę■äš(w©┤)╩Ūʱ┐╔ęį╣”─▄ĮĄ╝ēŻ┐╗“š▀┘Yį┤┴ė╗»Ż┐
▀@éĆ║├Ž±╩ŪĪČ┤¾ą═ŠW(w©Żng)šŠ╝╝ąg(sh©┤)╝▄śŗ(g©░u)║╦ą─įŁ└Ē┼c░Ė└²Ęų╬÷ĪĘķ_Ų¬Ą─ā╚(n©©i)╚▌Ż¼▓╗▀^ū„š▀┐éĮY(ji©”)Ą├▓╗ÕeŻ¼╬ęŠ═▐D(zhu©Żn)▌dę╗Ž┬░╔ĪŻ
4.«a(ch©Żn)ŲĘŠĆĄ─╝▄śŗ(g©░u)
▀Ćėąę╗ĘNŠ═╩Ū╔Ž├µę▓ėą╠ߥĮĄ─śI(y©©)äš(w©┤)▓ĘųĪŻ¼F(xi©żn)į┌╬ęéāąĶę¬ū÷ę╗éĆ«a(ch©Żn)ŲĘŠĆŻ¼╬ęéāų╗ąĶę¬ę╗éĆöĄ(sh©┤)ō■(j©┤)īėŻ¼ę╗éĆ═©ė├śI(y©©)äš(w©┤)▀ē▌ŗīėŻ¼Ū░├µ▀ĆėąĖ„ĘNæ¬(y©®ng)ė├║═Įń├µīėŻ¼▓╗ąĶę¬ī”═Ō▓┐ŽĄĮy(t©»ng)(═Ō▓┐╣½╦ŠĄ─ŽĄĮy(t©»ng))╠ß╣®Ę■äš(w©┤)Ą─ŪķøręįŪ░╬ęéāę╗░ŃĢ■▀xō±ė├EJBĄ╚üĒśŗ(g©░u)Į©Ęų▓╝╩Įæ¬(y©®ng)ė├Ż¼Ą½╩Ū¼F(xi©żn)į┌╬ęéā┐╔ęį╩╣ė├dobboĪóthriftĪóavroĪóhessian▀@ŅÉRPC┐“╝▄üĒśŗ(g©░u)Į©Ęų▓╝╩Įæ¬(y©®ng)ė├īŹ(sh©¬)¼F(xi©żn)▓╗═¼æ¬(y©®ng)ė├║═öĄ(sh©┤)ō■(j©┤)üĒį┤Ą─Į╗╗źĪŻ▀@ĘNĮY(ji©”)śŗ(g©░u)─Ż╩ĮŽ┬╬ęéāąĶę¬ī”Ųõ╦¹╣½╦Š╠ß╣®Ę■äš(w©┤)Ż¼┐╔ęįīŻķTīæę╗éĆæ¬(y©®ng)ė├ī”═Ō▓┐ŽĄĮy(t©»ng)╠ß╣®restĘ■äš(w©┤)ĪŻę╗░Ń┤¾ČÓöĄ(sh©┤)╗ź┬ō(li©ón)ŠW(w©Żng)Ę■äš(w©┤)▒│║¾Č╝ę¬įLå¢╩«ÄūéĆ╔§ų┴Äū░┘éĆā╚(n©©i)▓┐Ę■äš(w©┤)Ż¼╦³éāų«ķgĄ─═©ą┼ĘĮ╩Įę╗░ŃČ╝╩ŪRPCŻ║Š═Ž±įLå¢ę╗éĆ▀h(yu©Żn)│╠ĘĮĘ©─ŪśėŻ¼▌ö╚ļ?y©▓n)óö?sh©┤)║¾Ą╚┤²ĘĄ╗žĮY(ji©”)╣¹ĪŻ▀@ī”ė┌śŗ(g©░u)Į©Å═(f©┤)ļsŽĄĮy(t©»ng)╩ŪūŅ╚▌ęū└ĒĮŌĄ─ĘĮ╩ĮĪŻ
╚ńŽ┬łDĄ──Żą═Ż¼╬─╝■ŽĄĮy(t©»ng)Ż¼ŠÅ┤µ─Ūą®ø]ėą«ŗ│÷üĒŻ¼┤¾╝ę└ĒĮŌŠ═ąąĪŻ
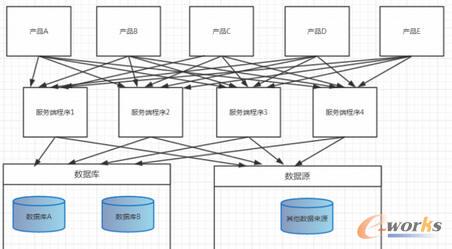
łD11 «a(ch©Żn)ŲĘŠĆĄ─╝▄śŗ(g©░u)
ĮY(ji©”)šZŻ║·▓╗╣▄──ĘN╝▄śŗ(g©░u)╬ęéāČ╝ąĶę¬ū÷║├─ŻēK╗»(▒M┴┐ū÷ĄĮ─ŻēKÅ═(f©┤)ė├)ĪŻ
·▓╗ę¬×ķ┴╦╝▄śŗ(g©░u)Č°╝▄śŗ(g©░u)ī¦(d©Żo)ų┬▀^Č╚įO(sh©©)ėŗĪŻ
·▓╗╣▄║╬ĘN╝▄śŗ(g©░u)Č╝╩Ū×ķ┴╦Ė³║├ØMūŃśI(y©©)äš(w©┤)ąĶŪ¾Ż¼╝▄śŗ(g©░u)æ¬(y©®ng)įōĖ·ļSśI(y©©)äš(w©┤)Ą─░l(f©Ī)š╣Č°░l(f©Ī)š╣ĪŻ
·«ö(d©Īng)Ū░Ą─╝▄śŗ(g©░u)╚ń╣¹┐╔ęįØMūŃ«ö(d©Īng)Ū░Ą─śI(y©©)äš(w©┤)░l(f©Ī)š╣Ż¼Š═┐╔ęį┐╝æ]Ž┬ę╗▓ĮĄ─öU(ku©░)š╣┴╦Ż¼▓╗ė├ę╗Ž┬ūė┐╝æ]3▓Į4▓Į╔§ų┴Ė³ČÓĪŻ
ęį╔Ž╚ń╣¹ėąš`Ż¼▀Ć═¹┤¾╝ę▓╗┴▀┘nĮ╠ŻĪ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.guhuozai8.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║Javaæ¬(y©®ng)ė├╝▄śŗ(g©░u)Ą─č▌╗»ų«┬Ę
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.guhuozai8.cn/html/support/11121519270.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")














