



“ąį─▄”▀@éĆį~┐╔ęįšf░ķļSų°š¹éĆITąąśIĄ─░lš╣Ż¼├┐┤╬ą┬Ą─╝╝ąg│÷¼FŻ¼Å─ė▓╝■ĄĮ▄ø╝■┤¾ČÓöĄŪķørŽ┬Č╝ć·└@ų°ąį─▄╠ß╔²Č°š╣ķ_ĪŻ“─”Ā¢Č©└Ē”ųĖ│÷CPUĄ─╠Ä└Ē╦┘Č╚├┐18éĆį┬Ģ■ĘŁę╗Ę¼Ż¼Ą½╩Ū▀M╚ļ21╩└╝oĄ─Ą┌Č■éĆ╩«─ĻüĒŻ¼╦Ų║§╦³Ą─╦┘Č╚┬²┴╦Ž┬üĒĪŻĄ½╩ŪITąąśIĄ─Ė„éĆąąśIŅIī¦š▀éāŻ¼▀Ć╩Ū▓╗öÓį┌ėŗ╦ŃÖCĄ─ąį─▄īżŪ¾═╗ŲŲŻ¼└^└m╠¶æ╬’└ĒśOŽ▐ĪŻ╝Ü┐┤┤µā”ąąśIŻ¼├┐┐Ņą┬Ą─┤µā”«aŲĘĄ─═Ų│÷Ż¼ę▓ć·└@ų°╚ń║╬Ė³┐ņĪóĖ³║├Ą─Ę■äšŪ░Č╦Ę■äšŲ„Ą─I/OšłŪ¾×ķųąą─ĪŻ▒Š╬─Å─I/OŻ©BlockŻ®Ą─┴„Ž“ĮķĮBŻ¼įćłDĮŌūxš¹éĆI/O┴„┼c┤µā”ąį─▄ų«ķgĄ─ą®įS┬ōŽĄĪŻ▒Š╬─ū„×ķę╗Ų¬┤µā”╗∙ĄAĄ─ĮķĮB╬─š┬Ż¼Ä═ų·ūxš▀┴╦ĮŌ┐┤╦Ų║åå╬Ą─öĄō■ūxīæųąĄ─Ė³ČÓ╝Ü╣ØĪŻ
ĪĪĪĪ┤µā”I/O┴„┼c┤µā”ąį─▄Ż║
ĪĪĪĪ┤µā”I/OŻ©║¾╬─║åĘQI/OŻ®Ą─╠Ä└Ē▀^│╠Š═╩Ūėŗ╦ŃÖCį┌┤µā”Ų„╔Žūx╚ĪöĄō■║═īæ╚ļöĄō■Ą─▀^│╠ĪŻ▀@ĘN┤µā”Ų„┐╔ęį╩ŪĘŪ│ųŠ├ąį┤µā”Ż©RAMŻ®Ż¼ę▓┐╔ęį╩ŪŅÉ╦Ųė▓▒PĄ─│ųŠ├ąį┤µā”ĪŻę╗éĆ═Ļš¹Ą─I/O┐╔ęį└ĒĮŌ×ķę╗éĆöĄō■å╬į¬═Ļ│╔Å─░lŲČ╦ĄĮĮė╩šČ╦Ą─ļpŽ“Ą─▀^│╠ĪŻį┌Ų¾śI╝ēĄ─┤µā”ŁhŠ│ųąŻ¼į┌▀@éĆ▀^│╠Ģ■Įø▀^ČÓéĆ╣سcŻ¼Č°├┐éĆ╣سcųąČ╝Ģ■╩╣ė├▓╗═¼Ą─öĄō■é„▌öģfūhĪŻę╗éĆ═Ļš¹Ą─I/Oį┌├┐éĆ▓╗═¼╣سcķgĄ─é„▌öŻ¼┐╔─▄Ģ■▒╗▓Ęų│╔ČÓéĆI/OŻ¼╚╗║¾Å─ę╗éĆ╣سcé„▌öĄĮ┴Ē═Ōę╗éĆ╣سcŻ¼ūŅ║¾į┘ĮøÜvŽÓ═¼Ą─▀^│╠ĘĄ╗žį┤Č╦ĪŻ
ĪĪĪĪŽ┬łDč▌╩Š┴╦ę╗éĆ╬─╝■į┌Įø▀^š¹éĆI/O┬ĘÅĮųą├┐éĆ╣سc╦∙▀MąąĄ─ūā╗»Ż©ęįEMC Symmetrix┤µā”Ļć┴ą×ķ└²Ż®Ż║
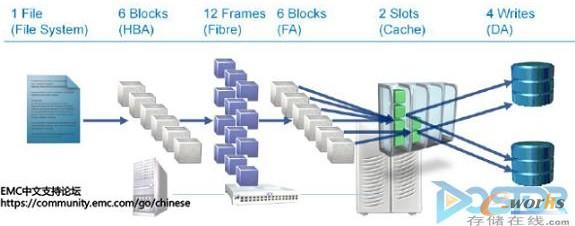
łD1 ╬─╝■į┌Įø▀^š¹éĆI/O┬ĘÅĮųą├┐éĆ╣سc╦∙▀MąąĄ─ūā╗»
ĪĪĪĪš¹éĆI/O┴„ĮøÜvę╗Ž┬ÄūéĆ╣سcŻ║
ĪĪĪĪFile System – ╬─╝■ŽĄĮyĢ■Ė∙ō■╬─╝■┼cBlockĄ─ė│╔õĻPŽĄŻ¼═©▀^File System Managerīó╬─╝■äØĘų×ķČÓéĆBlockŻ¼šłŪ¾░l╦═ĮoHBAĪŻ
ĪĪĪĪHBA – HBAł╠ąąī”▀@ę╗ŽĄ┴ąĄ─Ė³ąĪĄ─╣żū„å╬į¬▀Mąą▓┘ū„Ż¼īó▀@▓┐ĘųI/O▐DōQ×ķFibre ChannelģfūhŻ¼░³čb│╔▓╗│¼▀^2KBĄ─Frameé„▌öĄĮŽ┬ę╗éĆ▀BĮė╣سcFC SwitchĪŻ
ĪĪĪĪFC Switch – FC SwitchĢ■═©▀^FC FabricŠWĮjīó▀@ą®Frame░l╦═ĄĮ┤µā”ŽĄĮyĄ─Ū░Č╦┐┌Ż©Front AdapterŻ®ĪŻ
ĪĪĪĪStorage FA – ┤µā”Ū░Č╦┐┌Ģ■īó▀@ą®FC Ą─Frameųžą┬ĘŌčb│╔║═HBA│§╩╝░l╦═I/Oę╗ų┬Ż¼╚╗║¾FAĢ■īóöĄō■é„▌öĄĮĻć┴ąŠÅ┤µŻ©Storage Array CacheŻ®
ĪĪĪĪStorage Array Cache – Ļć┴ąŠÅ┤µ╠Ä└ĒI/O═©│Żėąā╔ĘNŪķørŻ║1.ų▒ĮėĘĄ╗žöĄō■ęčĮøīæ╚ļĄ─ėŹ╠¢ĮoHBAŻ¼▀@ĘNĮąū„╗žīæŻ¼ę▓╩Ū┤¾ČÓöĄ┤µā”Ļć┴ą╠Ä└ĒĄ─ĘĮ╩ĮĪŻ2. öĄō■īæ╚ļŠÅ┤µ╚╗║¾į┘╦óą┬ĄĮ╬’└Ē┤┼▒PŻ¼Įąū÷īæ═ĖĪŻI/O┤µĘ┼į┌ŠÅ┤µųąęį║¾Ż¼Į╗ė╔║¾Č╦┐žųŲŲ„Ż©Disk AdapterŻ®└^└m╠Ä└ĒŻ¼═Ļ│╔║¾į┘ĘĄ╗žöĄō■ęčĮøīæ╚ļĄ─ėŹ╠¢ĮoHBAĪŻ
ĪĪĪĪDisk Adapter – ╔Ž╩÷ā╔ĘNĘĮ╩ĮŻ¼ūŅ║¾Č╝Ģ■īóI/OūŅ║¾īæ╚ļĄĮ╬’└Ē┤┼▒PųąĪŻ▀@éĆ▀^│╠ė╔║¾Č╦Disk Adapter┐žųŲŻ¼Ė∙ō■║¾Č╦╬’└Ē┤┼▒PĄ─RAID╝ēäeĄ─▓╗═¼Ż¼ę╗éĆI/OĢ■ūā│╔ā╔éĆ╗“š▀ČÓéĆīŹļHĄ─I/OĪŻ
ĪĪĪĪĖ∙ō■╔Ž╩÷Ą─I/O┴„Ž“Ą─üĒ┐┤Ż¼ę╗éĆ═Ļš¹Ą─I/Oé„▌öŻ¼Įø▀^Ą─Ģ■Ž¹║─ĢrķgĄ─╣سc┐╔ęįĖ┼└©×ķęįŽ┬ÄūéĆŻ║
ĪĪĪĪCPU – RAMŻ¼ ═Ļ│╔ų„ÖC╬─╝■ŽĄĮyĄĮHBAĄ─▓┘ū„ĪŻ
ĪĪĪĪHBA – FAŻ¼═Ļ│╔į┌╣Ō└wŠWĮjųąĄ─é„▌ö▀^│╠ĪŻ
ĪĪĪĪFA – CacheŻ¼┤µā”Ū░Č╦┐©īóöĄō■īæ╚ļĄĮŠÅ┤µĄ─ĢrķgĪŻ
ĪĪĪĪDA – DriveŻ¼┤µā”║¾Č╦┐©īóöĄō■Å─ŠÅ┤µīæ╚ļĄĮ╬’└Ē┤┼▒PĄ─ĢrķgĪŻ
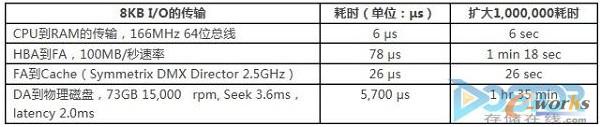
ĪĪĪĪŽ┬├µĄ─▒ĒųąĖ∙ō■▓╗═¼ļAČ╬Ą─öĄō■įLå¢Ģrķgū÷┴╦ę╗éĆ▒╚▌^Ż¼ę╗éĆ8KBĄ─I/O═Ļ│╔š¹éĆI/O┴„Ž“Ą─┤¾Ė┼║─ĢrĪŻŻ©▒ĒųąĄ─║─ĢrĖ∙ō■├┐├ļĄ─é„▌ööĄō■š¹│²½@Ą├Ż¼└²╚ńHBAĄĮFAĄ─╦┘Č╚ėą102,400KB/├ļ│²ęį8KBĄ├ĄĮ78 μsŻ®ĪŻĖ∙ō■▒ĒųąĄ─öĄō■’@Č°ęūęŖŻ¼I/OÅ─ų„ÖCĄ─╬─╝■ŽĄĮyķ_╩╝é„▌öĄĮ┤µā”Ļć┴ąĄ─ŠÅ┤µį┌š¹éĆ▀@éĆI/Oš╝▒╚║▄ąĪŻ¼ė╔ė┌ÖCąĄė▓▒PĄ─Ž▐ųŲŻ¼ūŅ┤¾Ą─║─Ģr▀Ć╩Ūį┌DAĄĮ╬’└Ē┤┼▒PĄ─ĢrķgĪŻ╚ń╣¹╩╣ė├ķW┤µ▒PŻ¼─Ū▀@éĆöĄō■Ģ■┤¾Ę∙┐sąĪŻ¼Ą½╩Ū┼cŲõ╦¹ÄūéĆ╣سcĄ─é„▌öĢrķgŽÓ▒╚Ż¼š╝▒╚▀Ć╩Ū▒╚▌^┤¾Ą─ĪŻ
▒Ē1 ▓╗═¼ļAČ╬Ą─öĄō■įLå¢Ģrķg▒╚▌^
ĪĪĪĪ┐╔ęį┐┤ĄĮŻ¼┤µā”Ļć┴ąĄ─ŠÅ┤µį┌š¹éĆI/O┴„ųą╦∙ŲĄĮĄ─ū„ė├╩Ūų┴ĻPųžę¬ĪŻŠÅ┤µĄ─╠Ä└Ēą¦┬╩┼c┤¾ąĪŻ¼ų▒Įėė░ĒæĄĮI/O╠Ä└ĒĄ─╦┘Č╚ĪŻČ°╚╗Ż¼į┌īŹļHĄ─ŁhŠ│ųąŻ¼╝┤╩╣┤µā”Ļć┴ąĄ─ŠÅ┤µ╣żū„Ą├«öŻ¼ų„ÖCĄ─I/Oę▓▓╗Ģ■▀_ĄĮ100 μsę▓Š═╩Ū0.1msĄ─╦«ŲĮŻ¼═©│Żį┌1-3msū¾ėęŻ¼Š═Ģ■šJ×ķI/O╠Ä└Ē╠Äė┌▒╚▌^Ė▀ąį─▄Ą──Ż╩ĮĪŻįŁę“Š═╩Ūę“×ķ┴Ē═Ōā╔éĆę“╦ž“öĄō■Ņ^╠Ä└Ē”║═“▓ó░l”ĪŻ
ĪĪĪĪ 1.“öĄō■Ņ^╠Ä└Ē“ė╔ė┌I/O┴„ųą├┐éĆI/OĄ─öĄō■ĮM│╔▓ó▓╗╩Ūų╗░³║¼öĄō■Ż¼╚ńŽ┬łD╦∙╩ŠŻ¼ę╗éĆI/O│²┴╦öĄō■ęį═Ō▀Ć░³║¼┴╦NegotiationŻ¼Acknowledgementė├üĒžōž¤į┌I/O┴„ųąĄ─├┐éĆ╣سcé„▌ö║═▀Mąą╣▄└ĒĄ─ĪŻŲõųą░³║¼║═TCP/IPę╗śėĄ─“Handshaking“ą┼Žóęį╝░┴„┐žųŲĄ─ą┼ŽóŻ¼▒╚╚ń│§╩╝╗»é„▌öŻ¼ĮY╩°═©ėŹĄ╚Ą╚ĪŻHeaderųąätĢ■Č©┴xę╗ą®└²╚ńCRCąŻ“ץ─ą┼ŽóŻ¼▒ŻūCöĄō■Ą─ę╗ų┬ąįĪŻ╦∙ėą▀@ą®öĄō■Ą─╠Ä└ĒČ╝Ģ■║─┘Mę╗Č©Ą─╠Ä└Ē┘Yį┤Ż¼į÷╝ėI/O┴„Ą─║─ĢrĪŻ

łD2 öĄō■Ņ^╠Ä└Ē
ĪĪĪĪ2.“▓ó░l“ĪŻė╔ė┌I/O┴„š¹éĆ▀^│╠ųą▓╗┐╔─▄ų╗═¼Ģr╠Ä└Ēę╗éĆI/OŻ¼╦∙ėąĄ─I/Oį┌HBAŻ¼FCŻ¼FA║═DA╠Ä└ĒĄ─▀^│╠ųąČ╝╩Ūęč┤¾┴┐▓ó░lĄ─ŪķørŽ┬▀MąąĪŻČ°ų„ꬥ─║─Ģr╚ĪøQė┌I/OĻĀ┴ąĄ─Ą╚┤²Ż¼ļm╚╗┤µā”Ļć┴ąĢ■į┌▓ó░l╔Ž▀Mąąā×╗»ĪŻ═¼ę╗éĆ╠Ä└ĒSliceĄ─╠Ä└Ē▀Ć╩ŪĢ■ę╗ĻĀ┴ąą╬╩Į▀MąąĪŻ╚ńŽ┬łD╦∙╩ŠŻ¼«ö┤µā”═¼Ģr├µī”ČÓéĆI/OĄ─╠Ä└ĒĄ─ŪķørŻ¼┐éĢ■ėą─│éĆI/OĢ■į┌š¹éĆ┴„Ą─ūŅ║¾│÷üĒŻ¼Č°į÷╝ėI/OĄ─║─ĢrĪŻ╦∙ęįšfŻ¼į┌I/O┴„Ą─├┐éĆ╣سc│÷¼FŲ┐ŅiŻ¼╗“š▀Č╠░ÕĄ─Ģr║“ĪŻI/OĄ─║─ĢrŠ═Ģ■į÷╝ėĪŻ
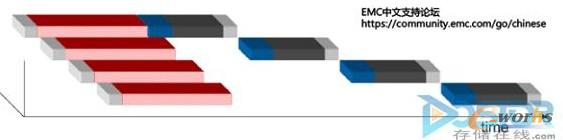
łD3 ┤µā”═¼Ģr├µī”ČÓéĆI/OĄ─╠Ä└ĒĄ─Ūķør
ĪĪĪĪŠC╔Ž╦∙╩÷Ż¼I/O┴„┼c┤µā”ąį─▄Ą─ĻPŽĄ┐╔ęį┐éĮY×ķęįŽ┬Äū³cŻ║
ĪĪĪĪ═Ļ│╔ę╗éĆI/O┴„ų„ę¬ĮøÜv▀^Ą─╣سcėąHBAŻ¼FCŠWĮjŻ¼┤µā”Ū░Č╦┐┌FAŻ¼┤µā”ŠÅ┤µĪó┤µā”║¾Č╦┐┌Ż¼╬’└Ē┤┼▒PĪŻČ°║▄éĆ▀^│╠ųąūŅ║─ĢrĄ─╩Ū╬’└Ē┤┼▒PĪŻ
ĪĪĪĪ┤µā”Ļć┴ąĄ─ŠÅ┤µĄ─┤¾ąĪ║═╠Ä└ĒĘĮ╩Įų▒Įėė░ĒæĄĮI/O┴„Ą─ąį─▄Ż¼ę▓╩ŪČ©┴xę╗éĆ┤µā”Ļć┴ąā×┴ėĄ─ųžę¬ųĖś╦ų«ę╗ĪŻ
ĪĪĪĪI/OĄ─╠Ä└Ē╦┘Č╚═©│ŻĢ■▀hļx└ĒšōųĄŻ¼įŁę“ČÓéĆ▓ó░l┴┐▌^┤¾Č°įņ│╔Ą─ĻĀ┴ąčė▀tĪŻ
ĪĪĪĪā×╗»I/OĄ─ĘĮ╩Į┐╔ęįÅ─ČÓéĆ╣سc╚ļ╩ųŻ¼Č°ūŅ’@ų°Ą─ą¦╣¹╩Ū╠ß╔²╬’└Ē┤┼▒PĄ─╦┘Č╚ĪŻę“×ķ┤µā”Ļć┴ąĢ■░č▒M┐╔─▄ČÓĄ─öĄō■Ę┼╚ļŠÅ┤µŻ¼Č°«öŠÅ┤µė├ØMęį║¾Ą─öĄō■Į╗ōQät═Ļ╚½╚ĪøQė┌╬’└Ē┤┼▒PĄ─╦┘Č╚ĪŻ
ĪĪĪĪ▀m«ö▀xė├║Ž▀mĄ─RAID╝ēäeŻ¼ę“×ķ▓╗═¼Ą─RAID╝ēäeĄ─ūxīæ▒╚└²┤¾▓╗ŽÓ═¼Ż¼┐╔─▄╩╣Ą├╬’└Ē┤┼▒P╠Ä└Ē║─ĢrÄū▒Čį÷╝ėĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║£\╬÷I/O╠Ä└Ē▀^│╠┼c┤µā”ąį─▄Ą─ĻPŽĄ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/11121511282.html






















