



į┌2016Hadoop╝╝ąg(sh©┤)ĘÕĢ■(hu©¼)Ą─ų„Ņ}č▌ųv╔ŽŻ¼ąŪŁh(hu©ón)┐Ų╝╝äō(chu©żng)╩╝╚╦īOį¬║Ų╔Ņ╚ļ£\│÷Ą─ĻU╩÷┴╦Hadoop╩Ū╚ń║╬═Ųäė(d©░ng)öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)▀M(j©¼n)ąą╔Ņ┐╠ūāĖ’ĪŻ
ę╗ĪóöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)▀M(j©¼n)╚ļæ(zh©żn)┬į▐D(zhu©Żn)š█³c(di©Żn)
Į±─Ļ┤¾Ģ■(hu©¼)Ą─ų„Ņ}╩ŪHadoop╩«─ĻĪŻ2006─Ļč┼╗óĄ╚łF(tu©ón)ĻĀ(du©¼)ķ_╩╝čą░l(f©Ī)Hadoop╝╝ąg(sh©┤)ų┴Į±ęčš¹š¹╩«─ĻĪŻį┌┤╦ų«ķg╝╝ąg(sh©┤)░l(f©Ī)š╣čĖ╦┘Ż¼Hadoop╔ŽĄ─╔·æB(t©żi)ŽĄĮy(t©»ng)ųØuöU(ku©░)┤¾ĪŻĖ„éĆ(g©©)ąąśI(y©©)Ą─ė├æ¶ųØuķ_╩╝╗∙ė┌▀@ę╗ą┬Ą─╝╝ąg(sh©┤)üĒķ_░l(f©Ī)╚½ą┬Ą─æ¬(y©®ng)ė├Ż¼╔§ų┴īóįŁŽ╚Ą─æ¬(y©®ng)ė├Ž“Hadoopų«╔Ž▀M(j©¼n)ąą▀węŲĪŻ╬┤üĒŻ¼HadoopĢ■(hu©¼)│╔×ķŲ¾śI(y©©)öĄ(sh©┤)ō■(j©┤)ųąą─Ą─║╦ą─ĪŻĮø(j©®ng)▀^▀@10─ĻĄ─░l(f©Ī)š╣Ż¼Į±─Ļķ_╩╝▀M(j©¼n)╚ļę╗éĆ(g©©)æ(zh©żn)┬į▐D(zhu©Żn)š█³c(di©Żn)(strategic inflection point)ĪŻ▀@ęŌ╬Čų°ą┬Ą─╝╝ąg(sh©┤)ķ_╩╝ųØu╚Ī┤·║═│¼įĮ└ŽĄ─╝╝ąg(sh©┤)Ż¼▓óį┌Ė„éĆ(g©©)ąąśI(y©©)čĖ╦┘░l(f©Ī)š╣ĪŻ╬┤üĒĄ─╚¶Ė╔─Ļų«ā╚(n©©i)Ż¼╚Ī┤·▀^│╠Ģ■(hu©¼)▓╗öÓ╝ė╦┘ĪŻąŪŁh(hu©ón)Į³3─ĻĄ─░l(f©Ī)š╣Ż¼Įø(j©®ng)▀^│ų└m(x©┤)Ą─čą░l(f©Ī)Īó═Č╚ļęį╝░┤¾┴┐Ą─░Ė└²Ęe└█Ż¼▀_(d©ó)ĄĮą┬Ą─Ė▀Č╚ĪŻ╚ź─Ļ12į┬Ę▌GartnerĘų╬÷Ĥ░čąŪŁh(hu©ón)┐Ų╝╝(Transwarp)┴ą×ķ┴╦ć°ļHų„┴„Ą─Hadoop░l(f©Ī)ąą░µÅS╔╠ų«ę╗Ż¼Ųõ╦¹Äū╝ę░³└©ClouderaĪóHortonworksĪóMapRĪŻ┴Ē═Ō▀Ćėąā╔╝ę╣½╦ŠĘųäe╩ŪIBM║═PivotalŻ¼╦¹éā▓╔ė├Open data PlatformĪŻ╚½Ū“╣▓ėą6╝ę╣½╦Š╔Ž░±Ż¼ąŪŁh(hu©ón)ę▓║▄śsąę─▄│╔×ķŲõųąę╗╝ęĪŻ

łD1 Hadoop╩«─Ļ
Į±─Ļ2į┬Ę▌Gartner░l(f©Ī)▓╝Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ─¦┴”Ž¾Ž▐«ö(d©Īng)ųąŻ¼ąŪŁh(hu©ón)┐Ų╝╝ę▓▒╗Ę┼╚ļ┴╦▀h(yu©Żn)ęŖš▀(Visionaries)Ž¾Ž▐«ö(d©Īng)ųąĪŻ▀@éĆ(g©©)Ž¾Ž▐└’╗∙▒Š╔ŽČ╝╩Ū▓╔ė├Hadoop╝╝ąg(sh©┤)Ą─äō(chu©żng)śI(y©©)╣½╦ŠĪŻ▀@ą®╣½╦Š▓╔ė├╚½ą┬Ą─╝╝ąg(sh©┤)Ż¼ųØu╠µ┤·é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņüĒśŗ(g©░u)įņą┬Ą─öĄ(sh©┤)ō■(j©┤)ŲĮ┼_(t©ói)ĪŻ┴Ē═Ōļm╚╗─┐Ū░ŅI(l©½ng)ī¦(d©Żo)š▀Ž¾Ž▐(Leaders)╚į╩Ū┤¾ÅS╔╠Ż¼╚ńOracleĪóTeradataĄ╚Ż¼Ą½╩ŪĮø(j©®ng)▀^▀@10─ĻĄ─Įø(j©®ng)“×(y©żn)╝╝ąg(sh©┤)Ą─Ęe└█Ż¼ųØu▀_(d©ó)ĄĮæ(zh©żn)┬į▐D(zhu©Żn)š█³c(di©Żn)Ż¼╝╝ąg(sh©┤)Ą─╚Ī┤·▀^│╠├„’@╝ė╦┘ĪŻ╚ń╣¹ĻP(gu©Īn)ūó▀@ą®ŅI(l©½ng)ī¦(d©Żo)š▀╣½╦Š╣╔Ų▒į┌▀^╚źę╗─ĻĄ─ār(ji©ż)Ė±ūā╗»Ż¼Š═Ģ■(hu©¼)░l(f©Ī)¼F(xi©żn)╩ął÷(ch©Żng)ŅA(y©┤)Ų┌į┌2016ų┴2017─Ļ╝╝ąg(sh©┤)Ģ■(hu©¼)░l(f©Ī)╔·ĘŪ│Ż┤¾Ą─ūā╗»ĪŻį┌Ų¾śI(y©©)┐═æ¶ųąŻ¼╩╣ė├ą┬╝╝ąg(sh©┤)Ą─▓ĮĘźĢ■(hu©¼)├„’@╝ė╦┘ĪŻ
Č■Īóųą├└Hadoopæ¬(y©®ng)ė├Įy(t©»ng)ėŗ(j©¼)ī”(du©¼)▒╚
Į±╠ņ╬ęč▌ųvĄ─Ņ}─┐╩ŪĮķĮBHadoop╩Ū╚ń║╬═Ųäė(d©░ng)öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)▀M(j©¼n)ąą╔Ņ┐╠ūāĖ’Ą─ĪŻ▀@└’ėąę╗ĮMĮy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)Ż║
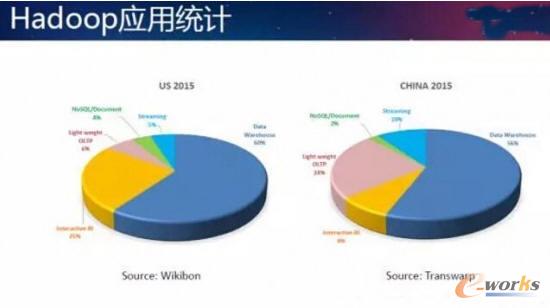
łD2 Hadoopæ¬(y©®ng)ė├Įy(t©»ng)ėŗ(j©¼)
ū¾▀ģĄ─öĄ(sh©┤)ō■(j©┤)╩ŪWikibonĄ─Ęų╬÷Ĥū÷Ą─├└ć°╩ął÷(ch©Żng)ųąHadoopą┬╝╝ąg(sh©┤)Ą─æ¬(y©®ng)ė├ł÷(ch©Żng)Š░Įy(t©»ng)ėŗ(j©¼)ĪŻ╦¹▓╔įL┴╦╔ŽŪ¦├¹HadoopĄ─ė├æ¶Ż¼▀@Ųõųąėą60%Ą─ė├æ¶╩╣ė├Hadoop╝╝ąg(sh©┤)üĒū÷öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼ėą25%Ą─ė├æ¶╩Ū░┤ššĮ╗╗ź╩ĮBIĄ─Ż¼į┌Hadoopų«╔Žė├ł¾(b©żo)▒Ē╣żŠ▀Īó┐╔ęĢ╗»╣żŠ▀üĒū÷Į╗╗ź╩ĮĘų╬÷öĄ(sh©┤)ō■(j©┤)ł¾(b©żo)▒ĒĪŻ═¼Ģr(sh©¬)ėą6%Ą─ė├æ¶╩Ūį┌ė├HBaseĪóCassandraüĒū÷OLAPĄ─║åå╬▌p┴┐╝ē(j©¬)Key-Value▓ķįāĪŻėą4%ė├æ¶╩╣ė├MongoDBĪóCouchbase╬─Ön╩ĮöĄ(sh©┤)ō■(j©┤)Äņ▀M(j©¼n)ąą╬─Ön┤µā”(ch©│)Ż¼▀Ćėą5%Ą─ė├æ¶╩╣ė├┴„╠Ä└ĒüĒū÷īŹ(sh©¬)Ģr(sh©¬)öĄ(sh©┤)ō■(j©┤)čą┼ąŻ¼ė╔┤╦śŗ(g©░u)│╔ę╗éĆ(g©©)═Ļš¹Ą─100%Ą─æ¬(y©®ng)ė├ĘųŅÉĪŻ«ö(d©Īng)╚╗▀Ćėą┐╔─▄ėąę╗ą®Ųõ╦¹Ą─æ¬(y©®ng)ė├┬®Ą¶┴╦Ż¼Ą½▀@ÄūéĆ(g©©)╩Ūų„ꬥ─æ¬(y©®ng)ė├«a(ch©Żn)ŲĘĪŻ
į┌ųąć°╩ął÷(ch©Żng)Ż¼Ė∙ō■(j©┤)╬ęéāĄ─śė▒ŠųąÄū░┘├¹Ų¾śI(y©©)ė├æ¶▀M(j©¼n)ąąĮy(t©»ng)ėŗ(j©¼)Ż¼ĮY(ji©”)╣¹Ė·├└ć°╔į╬óėą³c(di©Żn)▓Ņ«ÉĪŻĘų╬÷ĮY(ji©”)╣¹’@╩ŠŻ¼ėą56%Ą─┐═æ¶╩Ūū÷öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─Ż¼░³└©ODSĪóETLĪóöĄ(sh©┤)ō■(j©┤)ŪÕŽ┤Ą╚Ż¼╚ńį┌╬ęéāĄ─┐═æ¶ųąŻ¼ė├ė┌╚Ī┤·ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ╠ß╣®═Ļš¹Ą─öĄ(sh©┤)ō■(j©┤)é}Äņų¦│ųŻ¼üĒĮ©śŗ(g©░u)Ė„ĘNų„Ņ}─Żą═ĪŻ▀@éĆ(g©©)▒╚└²╩Ū▒╚▌^ĮėĮ³├└ć°ė├æ¶Ą─ĪŻĄ½╩Ū╬ęéāų╗ėą8%Ą─ė├æ¶į┌ū÷Į╗╗ź╩ĮBIĪŻūįų„BI▀@ę╗ēKį┌ć°ā╚(n©©i)ę▓ķ_╩╝┼dŲĪŻūóęŌĄĮ║═├└ć°╩ął÷(ch©Żng)ŽÓ▒╚Ż¼’@ų°▓╗ę╗śėĄ─ĄžĘĮį┌ė┌╬ęéāėą24%Ą─┐═æ¶╩Ūė├üĒū÷▌p┴┐╝ē(j©¬)▓ķįāĄ─Ż¼▀@éĆ(g©©)░┘Ęų▒╚ųĖĄ─╩Ū┐═æ¶öĄ(sh©┤)┴┐š╝▒╚Č°▓╗╩Ū┐═æ¶╝»╚║ęÄ(gu©®)─Ż(śŗ(g©░u)│╔Ą─╝»╚║╣Ø(ji©”)³c(di©Żn)öĄ(sh©┤)┴┐)ĪŻ▀@éĆ(g©©)▒╚▌^ėą╚żĄ─¼F(xi©żn)Ž¾šf├„Ż¼īŹ(sh©¬)ļH╔Žį┌ųąć°Ż¼æ¬(y©®ng)ė├▒╚▌^║åå╬Ż¼ę“?y©żn)ķ┐═æ¶Ą─ö?sh©┤)ō■(j©┤)┴┐ĘŪ│ŻŠ▐┤¾Ż¼▓┼Ģ■(hu©¼)╩╣ė├ą┬╝╝ąg(sh©┤)ĮŌøQå¢Ņ}ĪŻīŹ(sh©¬)ļH╔Žųąć°┐═æ¶Ą─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼Ė·├└ć°═¼ŅÉą═┐═æ¶Ą─öĄ(sh©┤)ō■(j©┤)┴┐ŽÓ▒╚╩Ūę¬┤¾ę╗éĆ(g©©)öĄ(sh©┤)┴┐╝ē(j©¬)(10▒Č)Ą─Ż¼║åå╬Ą─▓ķįāī”(du©¼)ųąć°Ą─┐═æ¶üĒšf╩ŪėąŠ▐┤¾Ą─└¦ļyĄ─ĪŻ╦∙ęį╬ęéā┐╔ęį┐┤ĄĮėą24%Ą─┐═æ¶į┌ė├Hyperbase(HBase)ĮM╝■▀M(j©¼n)ąą║åå╬▓ķįāĪŻ▀Ćėą2%Ą─┐═æ¶╩Ūė├╬ęéāĄ─«a(ch©Żn)ŲĘüĒ▀M(j©¼n)ąą╬─ÖnĄ─╦č╦„║═łDÖz╦„ĪŻ┴Ē═Ō▀ĆėąéĆ(g©©)║▄┤¾Ą─▓╗═¼╩Ūėą10%Ą─ė├æ¶╩Ūė├┴„╠Ä└ĒĄ─ĪŻÅ─łDųąŠ═┐╔ęį░l(f©Ī)¼F(xi©żn)Ż¼╬ęéāć°╝ęĄ─╣żśI(y©©)4.0ųŲįņśI(y©©)é„ĖąŲ„Ą─ŠW(w©Żng)Įj(lu©░)Į©įO(sh©©)╦┘Č╚╩Ū┐ņė┌├└ć°Ą─ĪŻ╬ęéāĄ─ė├æ¶╚║ųą▒╚└²├„’@Š═│¼▀^┴╦├└ć°Ą─╩ął÷(ch©Żng)▒╚└²ĪŻ
╚²Īóé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}Äņ├µ┼RĄ─╦─┤¾╠¶æ(zh©żn)
īŹ(sh©¬)ļH╔Ž┤¾╝ę┐╔ęį┐┤ĄĮŻ¼Hadoop╝╝ąg(sh©┤)į┌▀^╚źę╗Č╬Ģr(sh©¬)ķgų«ā╚(n©©i)Ż¼ų┴╔┘į┌2015─ĻųØuķ_╩╝═∙öĄ(sh©┤)ō■(j©┤)é}ÄņĘĮŽ“▐D(zhu©Żn)ūāĪŻ«ö(d©Īng)╚╗Ż¼Hadoopį┌įń─Ļäéķ_╩╝äō(chu©żng)Į©Ą─Ģr(sh©¬)║“Ż¼ų„ę¬ę▓╩Ūū„×ķöĄ(sh©┤)ō■(j©┤)é}ÄņĄ─Ż¼╦∙ęį¼F(xi©żn)į┌įĮüĒįĮČÓĄ─ąąśI(y©©)ę▓ķ_╩╝ė├Hadoop╝╝ąg(sh©┤)ū÷öĄ(sh©┤)ō■(j©┤)é}ÄņĪŻ─Ū├┤╩▓├┤╩ŪöĄ(sh©┤)ō■(j©┤)é}ÄņŻ┐GartnerĄ─ĮŌßī╩ŪŻ║öĄ(sh©┤)ō■(j©┤)é}Äņ▓╗āH╩Ūę╗éĆ(g©©)å╬ę╗Ą─öĄ(sh©┤)ō■(j©┤)ÄņŻ¼╦³╩Ūę╗š¹╠ūĄ─öĄ(sh©┤)ō■(j©┤)╣▄└ĒŽĄĮy(t©»ng)Ż¼░³║¼║▄ČÓĄ─▌oų·╣żŠ▀Īóę╗ą®įO(sh©©)ėŗ(j©¼)└Ē─Ņ║═╣▄└ĒĘĮĘ©ĪŻé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)Ż¼Įø(j©®ng)▀^┐ņ20─Ļ╗“š▀Ė³ķLĢr(sh©¬)ķgĄ─░l(f©Ī)š╣Ż¼ęčĮø(j©®ng)├µ┼R┴╦ę╗ą®Ų┐ŅiĪŻ
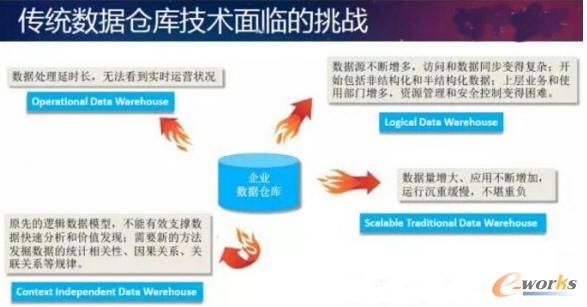
łD3 é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)├µ┼RĄ─╠¶æ(zh©żn)
Ą┌ę╗éĆ(g©©)å¢Ņ}Ż¼╬ęéā┐┤ĄĮļSų°öĄ(sh©┤)ō■(j©┤)┴┐į÷┤¾Ż¼░³└©Å═(f©┤)ļs│╠ą“æ¬(y©®ng)ė├Ą─į÷ČÓŻ¼é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}ÄņįĮüĒįĮ▓╗┐░ųžžō(f©┤)ĪŻ╬ęéāėąę╗éĆ(g©©)┐═æ¶į┌öĄ(sh©┤)ō■(j©┤)é}ÄņĮ©┴ó┴╦5000éĆ(g©©)Įy(t©»ng)ėŗ(j©¼)ł¾(b©żo)▒Ēæ¬(y©®ng)ė├ĪŻ╬ęéāę▓ėą┐═æ¶╩╣ė├ų°öĄ(sh©┤)ō■(j©┤)┴┐Į³20éĆ(g©©)PBĄ─╔╠śI(y©©)ŽĄĮy(t©»ng)ĪŻī”(du©¼)ė┌┤¾▓┐ĘųĄ─Ų¾śI(y©©)ė├æ¶Ż¼öĄ(sh©┤)ō■(j©┤)┴┐ę╗░Ńį┌Äū╩«éĆ(g©©)TB╗“š▀Äū░┘éĆ(g©©)TBū¾ėęĪŻ▀@├┤┤¾Ą─öĄ(sh©┤)ō■(j©┤)┴┐ī”(du©¼)é„Įy(t©»ng)Ą─é}ÄņŽĄĮy(t©»ng)üĒšf╩ŪĘŪ│Ż┤¾Ą─žō(f©┤)ō·(d©Īn)ĪŻå╬ę╗Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ¤oĘ©╠Ä└Ē▀@├┤┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ż¼╦∙ęįį┌▀@ę╗ēKąĶꬹ┬Ą─╝╝ąg(sh©┤)Ż¼╠žäe╩Ū└¹ė├Ęų▓╝╩Įėŗ(j©¼)╦ŃüĒ╚Ī┤·įŁ▒Šå╬ę╗Ą─ėŗ(j©¼)╦ŃĘĮ╩ĮüĒ▀M(j©¼n)ąąÖMŽ“öU(ku©░)š╣ĪŻ╬ęéāšJ(r©©n)×ķHadoop╝╝ąg(sh©┤)─▄│╔╣”Ą─ūŅĖ∙▒ŠĄ─įŁę“╩Ū╦³╩ŪÅ─å╬ÖC(j©®)Ą─╝»ųą╩Į▀\(y©┤n)╦Ńūā│╔┴╦Ęų▓╝╩Įėŗ(j©¼)╦ŃŻ¼▀@╩Ū╦³ūŅ┤¾Ą─ėŗ(j©¼)╦Ń─Ż╩ĮĄ─č▌ūāĪŻ░č╝»ųąėŗ(j©¼)╦Ńūā│╔Ęų▓╝ėŗ(j©¼)╦Ń╩Ūę╗éĆ(g©©)▒ž╚╗┌ģä▌(sh©¼)Ż¼▀@╩Ū┼÷ĄĮĄ─Ą┌ę╗éĆ(g©©)└¦ļyŻ¼ę╗╩ŪąĶę¬ę╗ą®ą┬ą═Ą─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)▀M(j©¼n)ąąąį─▄Ą─╝ė╦┘Ż¼üĒ╠Ä└Ē▀@ĘNÄū░┘TB╗“š▀╔ŽPBĄ─öĄ(sh©┤)ō■(j©┤)┴┐ĪŻČ■╩ŪļSų°öĄ(sh©┤)ō■(j©┤)į┤Ą─▓╗öÓį÷ČÓŻ¼įLå¢öĄ(sh©┤)ō■(j©┤)Ą─ĘĮ╩ĮūāĄ├ĘŪ│ŻÅ═(f©┤)ļsĪŻ╬ęéā║▄ČÓ┐═æ¶ėąÄū░┘éĆ(g©©)Äņ▒ĒŻ¼ėąÄūŪ¦╔Ž╚fÅł▒ĒŻ¼▀@śėÅ═(f©┤)ļsĄ─öĄ(sh©┤)ō■(j©┤)─Żą══©│Ż║▄ļy░č╦∙ėąöĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)ĄĮę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ«ö(d©Īng)ųąŻ¼ų╗─▄Ęų?j©½n)éĄĮ║▄ČÓéĆ(g©©)Äņ«ö(d©Īng)ųąĪŻī”(du©¼)öĄ(sh©┤)ō■(j©┤)Ą─╩╣ė├š▀ĦüĒ┴╦║▄┤¾Ą─└¦ļyŻ¼ę“?y©żn)ķ╦¹éāąĶę¬░čČÓĘNöĄ(sh©┤)ō■(j©┤)╚½▓┐┤µā”(ch©│)ŲüĒĪŻ▀@éĆ(g©©)╩ŪĄ┌ę╗éĆ(g©©)┤¾Ą─└¦ļyĪŻ
Ą┌Č■éĆ(g©©)å¢Ņ}╩ŪöĄ(sh©┤)ō■(j©┤)Ą─ŅÉą═░l(f©Ī)╔·ūā╗»Ż¼▀^╚ź╩ŪęįĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)×ķų„Ż¼80%╩ŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ĪŻ¼F(xi©żn)į┌ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ųØuį÷ČÓŻ¼▀@éĆ(g©©)ųĄķ_╩╝Ę┤▀^üĒŻ¼80%╩ŪĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)║═░ļĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ĪŻĄ½╩ŪÅ─ār(ji©ż)ųĄČ╚üĒųvŻ¼80%Ą─ār(ji©ż)ųĄ├▄Č╚╚į╚╗╩ŪüĒūįė┌ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ĪŻČ°ī”(du©¼)ė┌Ų¾śI(y©©)üĒųvŻ¼ąĶę¬▀@ą®ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ż¼▀M(j©¼n)ąą┤µā”(ch©│)Ęų╬÷ĪŻ┴Ē═Ōį┌öĄ(sh©┤)ō■(j©┤)į┤ūāČÓęį║¾Ż¼ė├æ¶║═śI(y©©)äš(w©┤)▓┐ķTę▓ūāČÓĪŻ▀@ą®▓┐ķTų«ķg╚ń║╬▀M(j©¼n)ąą┘Yį┤ėąą¦╣▄└Ē║═Ė¶ļxŻ¼ūā│╔ę╗éĆ(g©©)ĘŪ│Żć└(y©ón)ųžĄ─å¢Ņ}ĪŻ└²╚ń▀^╚źėąą®Ńyąą┐═æ¶╩Ū▓╔ė├ąąš■╠Ä┴P┤ļ╩®Ż¼╚ń╣¹ėą╚╦īæę╗ŚlSQLŻ¼░čöĄ(sh©┤)ō■(j©┤)é}Äņ┘Yį┤║─▒MŻ¼ī¦(d©Żo)ų┬Ųõ╦¹╚╦▓╗─▄╩╣ė├Ż¼─Ū├┤▀@éĆ(g©©)╚╦Į±─ĻĄ─¬ä(ji©Żng)äŅ(l©¼)Š═ø]ėą┴╦ĪŻ▓╔ė├▀@ĘNĘĮ╩Į╩Ūø]ėąą¦╣¹Ą─Ż¼ę“?y©żn)ķė├æ¶Ė∙▒ŠŠ═▓╗ų¬Ą└╦¹īæĄ─▀@éĆ(g©©)SQLŻ¼Ģ■(hu©¼)▓╗Ģ■(hu©¼)░čöĄ(sh©┤)ō■(j©┤)é}Äņ┼▄ÆņĄ¶ĪŻ┴Ē═Ōū÷įLå¢┐žųŲę▓╩Ū║▄═┤┐ÓĄ─Ż¼×ķ┴╦╩╣▓╗═¼Ą─Ęųų¦ÖC(j©®)śŗ(g©░u)ų╗─▄įLå¢ūį╝║Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ąĶę¬?ji©Żng)?chu©żng)Į©ęĢłDĪŻ╚ń╣¹ė├æ¶ėą1000Åł▒ĒŻ¼═¼Ģr(sh©¬)▀ĆėąÄū╩«éĆ(g©©)Ęųų¦ÖC(j©®)śŗ(g©░u)Ż¼─Ū├┤Š├ąĶę¬?ji©Żng)?chu©żng)Į©╔Ž╚féĆ(g©©)ęĢłDŻ¼▀@ī”(du©¼)öĄ(sh©┤)ō■(j©┤)Ą─ęĢłD╣▄└ĒĢ■(hu©¼)ĦüĒŠ▐┤¾Ą─╠¶æ(zh©żn)ĪŻ╦∙ęįį┌Äū─ĻŪ░Ż¼Ęų╬÷ÖC(j©®)śŗ(g©░u)Š═╠ß│÷ę¬Į©▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}ÄņĪŻ▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}ÄņŠ═╩Ūį┌▀^╚źÄū─Ļ«ö(d©Īng)ųąę╗ų▒▒╗öĄ(sh©┤)ō■(j©┤)é}ÄņŅI(l©½ng)ī¦(d©Żo)š▀Ę┤Å═(f©┤)ÅŖ(qi©óng)š{(di©żo)Ż¼╬ęéāąĶę¬╚źĮ©ę╗éĆ(g©©)▀ē▌ŗ╔Ž┤¾Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼╦¹ĄūŽ┬┐╔ęį░³└©ČÓéĆ(g©©)öĄ(sh©┤)ō■(j©┤)į┤—-═©▀^database federation(öĄ(sh©┤)ō■(j©┤)┬ō(li©ón)░Ņ)╣”─▄Ż¼═¼Ģr(sh©¬)╦³┐╔ęį┐ńČÓĘNöĄ(sh©┤)ō■(j©┤)į┤Ż¼┐╔ęį░čĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)║═ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Įy(t©»ng)ę╗╠Ä└ĒĪŻMichael Stonebrakerį┌Ū░Č╬Ģr(sh©¬)ķgųv▀^Ż¼╬┤üĒ▓╗╣▄╩Ūé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)▀Ć╩Ū┤¾öĄ(sh©┤)ō■(j©┤)╝╝ąg(sh©┤)Ż¼┤¾╝ęČ╝Ģ■(hu©¼)Įy(t©»ng)ę╗ĄĮ╩╣ė├SQLĮė┐┌Ż¼░³└©ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)┼cĘŪÖC(j©®)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ż¼ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ę▓Ģ■(hu©¼)▒╗ĮY(ji©”)śŗ(g©░u)╗»║¾▀M(j©¼n)ąą╠Ä└ĒĪŻ╦∙ęį▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}Äņ▀mæ¬(y©®ng)ė┌▀@ĘNūā╗»Ż¼═©▀^Įy(t©»ng)ę╗Įė┐┌Įy(t©»ng)ę╗ĘĮ╩ĮįLå¢öĄ(sh©┤)ō■(j©┤)į┤Ż¼═Ļ│╔┐ńĖ„ĘNöĄ(sh©┤)ō■(j©┤)į┤Ą─įLå¢Ż¼═¼Ģr(sh©¬)ę▓Ģ■(hu©¼)Į©įņę╗éĆ(g©©)ėąČÓūŌæ¶╣▄└ĒĪó┘Yį┤╣▄┐žĄ─Łh(hu©ón)Š│Ż¼─▄ē“▒╗║▄ČÓ▓┐ķTĪóė├æ¶▀M(j©¼n)ąą╩╣ė├ĪŻ▀@Å─└Ēšō╔ŽüĒųv╩Ūģ^(q©▒)äeė┌é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─æ¬(y©®ng)ė├ł÷(ch©Żng)Š░ĪŻ
Ą┌╚²éĆ(g©©)╠¶æ(zh©żn)╩ŪöĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─čėĢr(sh©¬)╠½ķLĪŻ▀^╚źš¹éĆ(g©©)öĄ(sh©┤)ō■(j©┤)╝▄śŗ(g©░u)Ū░├µ╩ŪOLTPŽĄĮy(t©»ng)Ż¼ųąķg╩ŪODSŻ¼║¾├µ╩ŪöĄ(sh©┤)ō■(j©┤)é}ÄņīėŻ¼į┘═∙║¾╩ŪöĄ(sh©┤)ō■(j©┤)╝»╩ąĪŻ─Ū├┤į┌öĄ(sh©┤)ō■(j©┤)é}Äņ▀@ę╗īėŻ¼öĄ(sh©┤)ō■(j©┤)╩ŪT+1Ą─Ż¼ęŌ╬Čų°Ą┌Č■╠ņ▓┼įLå¢Ū░ę╗╠ņĄ─öĄ(sh©┤)ō■(j©┤)ĪŻĄ½╩Ū║▄ČÓąąśI(y©©)ąĶę¬Ė³īŹ(sh©¬)Ģr(sh©¬)Ą─öĄ(sh©┤)ō■(j©┤)Ż¼×ķ┴╦┴╦ĮŌ«ö(d©Īng)Ū░Ą─╔·«a(ch©Żn)▀\(y©┤n)ĀIĀŅørŻ¼╦³éāąĶę¬╗∙ė┌T+0Īó£╩(zh©│n)īŹ(sh©¬)Ģr(sh©¬)Ą─Ż¼╔§ų┴╩ŪīŹ(sh©¬)Ģr(sh©¬)Ą─ÄūĘųńŖÄū├ļńŖų«ā╚(n©©i)Ą─öĄ(sh©┤)ō■(j©┤)ĪŻ▀@ĘNąĶŪ¾Š═č▌ūā│╔Ą┌╚²ĘNöĄ(sh©┤)ō■(j©┤)é}Äņ▀\(y©┤n)ĀI─Ż╩Į——Operational Data WarehouseĪŻ▀@ĘNśI(y©©)äš(w©┤)─Ż╩ĮĄ─įO(sh©©)ėŗ(j©¼)│§ųį╩ŪŽŻ═¹░čöĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)Ģr(sh©¬)╗“£╩(zh©│n)īŹ(sh©¬)Ģr(sh©¬)Ą─ī¦(d©Żo)╚ļĄĮöĄ(sh©┤)ō■(j©┤)é}Äņ«ö(d©Īng)ųąŻ¼─▄ē“?q©▒)”ī?sh©¬)Ģr(sh©¬)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą┐ņ╦┘Ą─Ęų╬÷║══┌Š“ĪŻé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ū├┐╠ņ═Ē╔ŽöĄ(sh©┤)ō■(j©┤)ī¦(d©Żo)╚ļŻ¼╗©7-8éĆ(g©©)ąĪĢr(sh©¬)▀M(j©¼n)ąą┼·╠Ä└Ēėŗ(j©¼)╦ŃŻ¼Ą┌Č■╠ņ▓┼─▄┐┤ĄĮł¾(b©żo)▒ĒĪŻ╦∙ęįé„Įy(t©»ng)╝╝ąg(sh©┤)├µ┼Rę╗éĆ(g©©)Ųš▒ķĄ─å¢Ņ}Ż║▓╗─▄īŹ(sh©¬)¼F(xi©żn)īŹ(sh©¬)Ģr(sh©¬)╠Ä└ĒĪŻ
Ą┌╦─éĆ(g©©)╠¶æ(zh©żn)╩ŪįŁŽ╚Ą─▀ē▌ŗöĄ(sh©┤)ō■(j©┤)─Żą═▓╗─▄ėąą¦ų¦ō╬öĄ(sh©┤)ō■(j©┤)┐ņ╦┘Ęų╬÷║═ār(ji©ż)ųĄ░l(f©Ī)¼F(xi©żn)ĪŻ▀^╚ź┤¾╝ęū÷Įy(t©»ng)ėŗ(j©¼)╩Ūī”(du©¼)öĄ(sh©┤)ō■(j©┤)ū÷ę╗ą®│ŻęŖĄ─Š█║Žęį╝░▀BĮėĻP(gu©Īn)┬ō(li©ón)▓┘ū„ĪŻū±čŁĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ──Ż╩ĮŻ¼ėą║▄ČÓ─Żą═║═Ė„ĘNĘČ╩ĮŻ¼Ž±║▄ČÓÅS╔╠į┌ŽÓĻP(gu©Īn)ąąśI(y©©)įO(sh©©)ėŗ(j©¼)┴╦╩«┤¾ų„Ņ}─Żą═Īó░╦┤¾ų„Ņ}─Żą═Ż¼ųąķgöĄ(sh©┤)ō■(j©┤)Ą─ĻP(gu©Īn)┬ō(li©ón)│╠Č╚╩ŪĘŪ│ŻĖ▀Ą─ĪŻę╗éĆ(g©©)ėąÄūŪ¦éĆ(g©©)öĄ(sh©┤)ō■(j©┤)į┤▒ĒĄ─śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)Ż¼ųąķgīėąĶę¬ė├╔Ž╚fÅłöĄ(sh©┤)ō■(j©┤)▒ĒüĒØMūŃ╦³Ą──Żą═ĪŻ▀@śėę╗éĆ(g©©)Å═(f©┤)ļsĄ──Żą═╦∙ĦüĒĄ─▒ūČ╦Š═╩ŪöĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)ę╗Ą®░l(f©Ī)╔·ūā╗»╗“š▀į÷╝ėĢr(sh©¬)Ż¼─Żą═Š═▓╗┐░ųžžō(f©┤)ĪŻŅA(y©┤)Ž╚įO(sh©©)Č©Ą──Żą═ø]Ę©▀mæ¬(y©®ng)śI(y©©)äš(w©┤)Ą─┐ņ╦┘ūā╗»Ż¼╦∙ęį╬ęéāĮø(j©®ng)│Ż─▄┐┤ĄĮŃyąą╗©Äū─ĻĢr(sh©¬)ķgĮ©┴óę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼Ę┤Å═(f©┤)═Č╚ļŻ¼├┐─Ļį┌Ė─įņ╦³ĪŻĮ³Ų┌┴╦ĮŌĄĮę╗╝ęŃyąą┐Ų╝╝▓┐ķTŻ¼Ū░║¾10─Ļ═Č╚ļ╩«Äūā|üĒĮ©öĄ(sh©┤)ō■(j©┤)é}ÄņĪŻČ°Į±╠ņę╗ĘĮ├µ┤¾┴┐öĄ(sh©┤)ō■(j©┤)į┌«a(ch©Żn)╔·Ż¼═¼Ģr(sh©¬)ą┬Ą─öĄ(sh©┤)ō■(j©┤)ę▓į┌į÷╝ėŻ¼ėąą®üĒūįā╚(n©©i)▓┐Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ėąą®üĒūįą┬Ą─═Ō▓┐öĄ(sh©┤)ō■(j©┤)ĪŻöĄ(sh©┤)ō■(j©┤)╠Ä└ĒĘĮĘ©Ą─┤_ĄĮ┴╦æ¬(y©®ng)įōūāĖ’Ą─Ģr(sh©¬)║“ĪŻ═©▀^└¹ė├ą┬Ą─ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─Įy(t©»ng)ėŗ(j©¼)ĘĮĘ©Ż¼▓╗āHū÷é„Įy(t©»ng)SQLĄ─Įy(t©»ng)ėŗ(j©¼)Ż¼▀ĆŽŻ═¹─▄ē“Å─öĄ(sh©┤)ō■(j©┤)ĻP(gu©Īn)┬ō(li©ón)╔Ž├µ░l(f©Ī)¼F(xi©żn)ęÄ(gu©®)┬╔ĪóĻP(gu©Īn)┬ō(li©ón)─Ż╩ĮĪóĢr(sh©¬)ą“╔ŽĄ─╠žš„ĪŻ═©▀^ī”(du©¼)╦³▀M(j©¼n)ąąę╗ą®ŅA(y©┤)£y(c©©)Ęų╬÷Ż¼─▄ē“░l(f©Ī)¼F(xi©żn)Įy(t©»ng)ėŗ(j©¼)īW(xu©”)ęŌ┴x╔ŽĄ─ę“╣¹ĻP(gu©Īn)ŽĄĪŻ▀@Š═ūāĄ├ī”(du©¼)Ų¾śI(y©©)Ė³╝ėųžę¬ĪŻ▀@ę╗ēK╩ŪĄ┌╦─ĘNöĄ(sh©┤)ō■(j©┤)é}Äņą┬Ą─įO(sh©©)ėŗ(j©¼)─Ż╩ĮŻ¼Įącontext independent data warehouseŻ¼ę▓Š═╩ŪšfÆüŚē▀@ą®▀ē▌ŗĻP(gu©Īn)┬ō(li©ón)─Żą═Ż¼į┌▓╗ų¬Ą└▀@ą®─Żą═Ą─ŪķørŽ┬Ż¼ę▓─▄═©▀^ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─ĘĮĘ©šęĄĮöĄ(sh©┤)ō■(j©┤)ų«ķgĄ─ĻP(gu©Īn)┬ō(li©ón)ĻP(gu©Īn)ŽĄŻ¼─▄ē“šęĄĮ╦¹éāų«ķgĮy(t©»ng)ėŗ(j©¼)īW(xu©”)Ą─ę“╣¹ĻP(gu©Īn)ŽĄĪŻ
╦─Īó╚½ą┬Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņįO(sh©©)ėŗ(j©¼)─Ż╩Į
▀@╦─éĆ(g©©)æ¬(y©®ng)ė├─Ż╩ĮŻ¼▀@╦─éĆ(g©©)└¦Š│ę²│÷┴╦ą┬Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─įO(sh©©)ėŗ(j©¼)─Ż╩ĮĪŻęŌ╬Čų°▀@╦─ĘNæ¬(y©®ng)ė├─Ż╩ĮąĶę¬╚½ą┬Ą─╝╝ąg(sh©┤)ų¦ō╬Ż¼▀@ę▓╩Ū╬ęéā┐┤ĄĮą┬Ą─╝╝ąg(sh©┤)Ż¼╠žäe╩ŪHadoop«a(ch©Żn)╔·ęį║¾Ż¼č▄╔·│÷üĒą┬Ą─╝╝ąg(sh©┤)č▌▀M(j©¼n)ų▓Įį┌ØMūŃ▀@ą®ąĶŪ¾ĪŻ
¼F(xi©żn)į┌ųvĄ┌ę╗éĆ(g©©)Ż¼é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}Äņ×ķ┴╦æ¬(y©®ng)ī”(du©¼)öĄ(sh©┤)ō■(j©┤)┴┐Ą─į÷╝ėŻ¼ąĶę¬▓╔ė├ą┬Ą─ĘĮ╩ĮĪŻ╬ęéā┐┤ĄĮėŗ(j©¼)╦Ń─Ż╩Įį┌▀^╚źĄ─╩«Äū─Ļ└’░l(f©Ī)╔·┴╦ĘŪ│Ż├„’@Ą─ūā╗»Ż¼Å─å╬ÖC(j©®)ķ_╩╝Ż¼╩ūŽ╚╩ŪĄ┌ę╗▓Įėŗ(j©¼)╦Ń▓óąą╗»ĪŻėŗ(j©¼)╦Ń▓óąą╗»Š═╩Ū╬ęéāĘQ×ķ▓óąąöĄ(sh©┤)ō■(j©┤)Äņ——öĄ(sh©┤)ō■(j©┤)Äņę²Ūµ▓óąą╗»Ż¼Ą½╩Ūī”(du©¼)┤µā”(ch©│)¤oĘ©ėąą¦öU(ku©░)š╣Ż¼╦∙ęįŠ═č▌ūā│÷┴╦Ą┌Č■┤·ėŗ(j©¼)╦Ń║═┤µā”(ch©│)Ą─Ęų▓╝╩Į╗»Ż¼«a(ch©Żn)╔·┴╦Ą┌Č■┤·Ęų▓╝╩Į╝╝ąg(sh©┤)Ż¼┤¾ęÄ(gu©®)─Ż▓óąąöĄ(sh©┤)ō■(j©┤)ÄņŠ═╩ŪMPPöĄ(sh©┤)ō■(j©┤)ÄņŻ¼▀@éĆ(g©©)öĄ(sh©┤)ō■(j©┤)ÄņĮŌøQ┴╦ę╗▓┐Ęųå¢Ņ}——ÄūéĆ(g©©)TB╝ē(j©¬)äeĄ─öĄ(sh©┤)ō■(j©┤)Ą─Ė▀╦┘╠Ä└Ēå¢Ņ}ĪŻĄ½╩Ūį┌öĄ(sh©┤)┴┐į÷╝ėĄ─Ģr(sh©¬)║“Ż¼ėųė÷ĄĮę╗éĆ(g©©)Ų┐ŅiŻ¼╦³ąĶę¬ę╗éĆ(g©©)ą┬ę╗┤·Ą─╝╝ąg(sh©┤)ĪŻą┬ę╗┤·Ą─ėŗ(j©¼)╦Ń─Ż╩Į░l(f©Ī)╔·┴╦ūā╗»Ż¼▀@éĆ(g©©)╩ŪGoogleį┌2003Īó2004─Ļųą░l(f©Ī)▓╝Ą─ā╔Ų¬šō╬─ųąŻ¼ĮŌßī┴╦MapReduceĄ─ėŗ(j©¼)╦Ń─Ż╩ĮĪŻ┤¾╝ę░l(f©Ī)¼F(xi©żn)Ż¼Įø(j©®ng)▀^▀@├┤ČÓ─Ļ░l(f©Ī)š╣Ż¼MapReduceėŗ(j©¼)╦Ń─Ż╩Į╚į╚╗╩ŪūŅ╝čĄ─Ęų▓╝╩Įėŗ(j©¼)╦Ń─Ż╩ĮŻ¼╦³░čėŗ(j©¼)╦Ń║═┤µā”(ch©│)ėąą¦ĄžĮY(ji©”)║Ž┴╦ŲüĒŻ¼╦³╚į╚╗╩Ū¼F(xi©żn)į┌ūŅŠ▀ėąöU(ku©░)š╣ąįĪóūŅŠ▀╚▌Õe(cu©░)ąįŻ¼¼F(xi©żn)į┌ļSų°╬ęéāąŪŁh(hu©ón)ą┬Ą─╝╝ąg(sh©┤)īŹ(sh©¬)¼F(xi©żn)Ż¼╦³╔§ų┴╩Ūąį─▄ūŅ║├Ą─ėŗ(j©¼)╦Ń─Ż╩ĮĪŻ▀@śėę╗éĆ(g©©)č▌ūā╩╣Ą├ą┬Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)─▄ē“╠Ä└ĒÅ─ÄūéĆ(g©©)TBĄĮÄū╩«éĆ(g©©)PBĄ─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼─▄ē“ŠĆąįöU(ku©░)š╣Ż¼Č°Ūęį┌├┐éĆ(g©©)öĄ(sh©┤)┴┐╝ē(j©¬)╔ŽČ╝┐╔ęį▒╚é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╝╝ąg(sh©┤)┐ņ╚¶Ė╔▒Č╔§ų┴ę╗éĆ(g©©)öĄ(sh©┤)┴┐╝ē(j©¬)(10▒Č)ĪŻ▀@└’ėąę╗ĮMöĄ(sh©┤)ō■(j©┤)Ż¼╩Ū╬ęéā?c©©)┌┤║╣?ji©”)Ū░£y(c©©)įćĄ─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)╣¹Ż¼Į±╠ņĄ─č▌ųvę▓╩Ū×ķ┴╦ĮķĮB╬ęéā?c©©)┌TPC-DSś╦(bi©Īo)£╩(zh©│n)£y(c©©)įć╝»╔ŽĄ─ūŅą┬▀M(j©¼n)š╣ĪŻ╚ź─ĻĄ─Ģr(sh©¬)║“╬ęéāęčĮø(j©®ng)ū÷ĄĮ┴╦╗∙ė┌TPC-DS benchmarkÅ─1TBĄĮ100TBČ╝─▄ėąą¦Ąž╠Ä└ĒŻ¼Č°Ūę╠Ä└ĒĄ─ąį─▄╩ŪŻ¼╬ęéāė├29┼_(t©ói)ÖC(j©®)Ų„Ż¼─▄ē“į┌40éĆ(g©©)ąĪĢr(sh©¬)ā╚(n©©i)═Ļ│╔100TB┐é╣▓99éĆ(g©©)ł¾(b©żo)▒Ē╠Ä└ĒĪŻ╬ęéā£y(c©©)įć╩╣ė├Ą─╩ŪŲš═©Ą─ā╔┬ĘĄ─Ę■äš(w©┤)Ų„Ż¼CPU▀Ć╩Ū▒╚▌^╚§Ą─Ż¼Į±╠ņ─▄ē“į┌TPC-DS benchmark╔Ž┼▄▀^100TBĄ─öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼æ¬(y©®ng)įō╩ŪŪ³ųĖ┐╔öĄ(sh©┤)Ą─ĪŻ┤¾╝ę┐╔ęį░l(f©Ī)¼F(xi©żn)ą┬Ą─╝╝ąg(sh©┤)Ż¼į┌╠Ä└Ē100TB╔Ž╩Ūø]ėąē║┴”Ą─ĪŻ
Ą┌ę╗éĆ(g©©)å¢Ņ}╬ęéā┐╔ęį═©▀^Ęų▓╝╩Įėŗ(j©¼)╦ŃüĒĮŌøQŻ¼Ą┌Č■éĆ(g©©)╩Ū═©▀^öĄ(sh©┤)ō■(j©┤)┬ō(li©ón)░Ņ╝╝ąg(sh©┤)╠Ä└ĒČÓöĄ(sh©┤)ō■(j©┤)į┤ęį╝░ĮŌøQČÓūŌæ¶Ą─å¢Ņ}Ż¼▀@éĆ(g©©)╩ŪGartnerĘų╬÷Ĥį┌Äū─Ļų«Ū░╠ß│÷üĒĄ─Ż¼Įą▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}ÄņĪŻ▀ē▌ŗdata warehouse─▄ē“▒╚▌^ėąą¦ĄžĮŌøQ▀@éĆ(g©©)å¢Ņ}ĪŻĘų╬÷ĤšJ(r©©n)×ķŻ¼▀ē▌ŗöĄ(sh©┤)é}æ¬(y©®ng)įōėą╚²éĆ(g©©)▓┐ĘųĪŻĄ┌ę╗éĆ(g©©)▓┐Ęų╩Ūųąą─Ą─RepositoryŻ¼╦∙ėąöĄ(sh©┤)ō■(j©┤)╚½▓┐╝»ųąĘ┼į┌▀@éĆ(g©©)╔Ž├µĪŻĄ┌Č■éĆ(g©©)╩ŪąĶę¬ėąę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ╠ōöM╗»Ż¼╗“š▀ĮąöĄ(sh©┤)ō■(j©┤)Äņ┬ō(li©ón)░Ņ╝╝ąg(sh©┤)Ż¼─▄ē“░čČÓĘNöĄ(sh©┤)ō■(j©┤)į┤╚┌║ŽŲüĒŻ¼Å─æ¬(y©®ng)ė├ĮŪČ╚üĒ┐┤╩╣ė├Ė³╝ėĘĮ▒ŃĪŻĄ┌╚²éĆ(g©©)╩Ūį┌▀ē▌ŗöĄ(sh©┤)é}ų«╔ŽŻ¼ūŅ║╦ą─Ą─Š═╩ŪĘų▓╝╩Įėŗ(j©¼)╦ŃĪŻ═¼Ģr(sh©¬)Ųõųąėąā╔éĆ(g©©)╠žąį╩ŪąĶę¬ØMūŃĄ─Ż¼ę╗éĆ(g©©)Š═╩Ū─▄▓╗─▄░┤ąĶī”(du©¼)öĄ(sh©┤)ō■(j©┤)é}Äņ▀M(j©¼n)ąąöU(ku©░)ÅłĪó─▄▓╗─▄īŹ(sh©¬)¼F(xi©żn)ČÓéĆ(g©©)ė├æ¶╣▓ŽĒę╗éĆ(g©©)ŲĮ┼_(t©ói)ĪŻ▀@éĆ(g©©)╩Ū▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}Äņ▒žĒÜę¬ĮŌøQĄ─å¢Ņ}ĪŻĄ┌Č■éĆ(g©©)╩Ūī”(du©¼)ė┌į¬öĄ(sh©┤)ō■(j©┤)Ą─╣▄└ĒĪóī”(du©¼)öĄ(sh©┤)ō■(j©┤)┘|(zh©¼)┴┐╣▄└ĒĄ─ėąą¦ĘĮĘ©Īóī”(du©¼)öĄ(sh©┤)ō■(j©┤)įLå¢ę¬ėąīÅėŗ(j©¼)Ż¼▀@ę▓╩Ū▀ē▌ŗöĄ(sh©┤)ō■(j©┤)Äņ║╦ą─įO(sh©©)ėŗ(j©¼)Ą─įŁätĪŻ«ö(d©Īng)╚╗╬ęéā▀@└’ĮķĮBĄ─ā╔éĆ(g©©)╝╝ąg(sh©┤)Ż¼╩ŪąŪŁh(hu©ón)ė├üĒų¦ō╬▀ē▌ŗöĄ(sh©┤)ō■(j©┤)ÄņĮ©įO(sh©©)Ą─ĪŻ╬ęéā?c©©)┌SQLīėę▓ų¦│ųé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņĄ─öĄ(sh©┤)ō■(j©┤)┬ō(li©ón)░ŅĄ─Ė┼─ŅŻ¼┐╔ęįų¦│ųDBlinkĄ─šZĘ©ĪŻ╬ęéā░č▀@éĆ(g©©)ėŗ(j©¼)╦ŃĘų╔óķ_Ż¼äØĄĮČÓéĆ(g©©)öĄ(sh©┤)ō■(j©┤)į┤╔Ž├µĪŻ▀@└’ėąā╔ĘNīŹ(sh©¬)¼F(xi©żn)ĘĮ╩ĮŻ¼ę╗ĘN╩Ūé„Įy(t©»ng)ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņĄ─ĘĮ╩ĮŻ¼░čHadoopū„×ķ┴Ē═Ōéõė├Ą─ėŗ(j©¼)╦Ńę²ŪµĪŻ
┴Ē═Ōę╗ĘNŻ¼ąŪŁh(hu©ón)╩ŪĮ©įņSQLĘŁūgīėŻ¼░čį┤öĄ(sh©┤)ō■(j©┤)Ę┼ĄĮHadoop╔ŽĄ─ł╠(zh©¬)ąąėŗ(j©¼)äØ└’Ż¼Ą½╩Ū╚ń╣¹öĄ(sh©┤)ō■(j©┤)į┌ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ╔ŽŻ¼╬ęéāĢ■(hu©¼)░čSQLĮoĄĮĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņł╠(zh©¬)ąąŻ¼ł╠(zh©¬)ąąĄ─Ģr(sh©¬)║“?q©▒)ŹļH╔Žėŗ(j©¼)╦Ń╚į╚╗╩ŪĘų▓╝╩ĮĄ─Ż¼╚į╚╗į┌Hadoop╔Ž▀M(j©¼n)ąą▀\(y©┤n)╦ŃŻ¼ų╗▓╗▀^öĄ(sh©┤)ō■(j©┤)į┤į┌ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ└’ĪŻ▀@└’├µėąā╔éĆ(g©©)ā×(y©Łu)╗»╝╝ąg(sh©┤)Ż¼ę╗éĆ(g©©)ā×(y©Łu)╗»╩Ū░čöĄ(sh©┤)ō■(j©┤)│ķ╚ĪĄĮČÓéĆ(g©©)╣Ø(ji©”)³c(di©Żn)╔Ž▀M(j©¼n)ąąĘų▓╝╩Įėŗ(j©¼)╦ŃŻ¼═¼Ģr(sh©¬)░čSQLųąĄ─ę╗ą®▀^×VŚl╝■Ž┬═Ų(pushdown)ĄĮĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņĪŻ▀@ĘNĘĮ╩ĮĄ─ūā╗»Š═╩ŪĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņęį╝░é„Įy(t©»ng)╔Ž¼F(xi©żn)į┌╠Äė┌ŅI(l©½ng)ī¦(d©Żo)š▀Ž¾Ž▐Ą─ÅS╔╠īŹ(sh©¬)ļH╔ŽŽŻ═¹╩Ūęį╦¹éāĄ─öĄ(sh©┤)ō■(j©┤)Äņ×ķų„Ż¼Č°╬ęéā╩ŪŽŻ═¹ęįHadoop×ķų„Ż¼üĒśŗ(g©░u)įņ▀@śėę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)┬ō(li©ón)░ŅĄ─īŹ(sh©¬)¼F(xi©żn)ĘĮ░ĖĪŻĮ±╠ņ┐┤üĒŻ¼▀@ĘN╝╝ąg(sh©┤)╩ŪūŅ╝čĄ─Ż¼ę“?y©żn)ķ╬ęéāĄ─ė?j©¼)╦Ń╩Ū╚½▓┐Ęų▓╝╩Į╗»Ą─Ż¼╦∙ęį╬ęéāĄ─ąį─▄▒╚╦¹éāĖ³ėąā×(y©Łu)ä▌(sh©¼)ĪŻĄ┌Č■éĆ(g©©)Ż¼×ķ┴╦śŗ(g©░u)įņ▀ē▌ŗöĄ(sh©┤)é}ę²╚ļ┴╦╬óĘ■äš(w©┤)Ą─Ė┼─ŅŻ¼─Ū╬óĘ■äš(w©┤)Ą─īŹ(sh©¬)¼F(xi©żn)╩Ūė├╚▌Ų„üĒīŹ(sh©¬)¼F(xi©żn)Ą─ĪŻ╬ęéāėąéĆ(g©©)«a(ch©Żn)ŲĘŻ¼ę▓ėąŽÓæ¬(y©®ng)Ą─č▌ųv╩ŪĮķĮBą┬Ą─«a(ch©Żn)ŲĘTOS(Transwarp Operating System)Ż¼▀@éĆ(g©©)«a(ch©Żn)ŲĘ╩Ū╗∙ė┌Docker║═kubernetesüĒśŗ(g©░u)įņÅŚąįĄ─╗∙ė┌╚▌Ų„╗»Ą─ėŗ(j©¼)╦ŃŁh(hu©ón)Š│ĪŻį┌▀@ų«╔Ž╬ęéā░čé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─æ¬(y©®ng)ė├Ż¼╝┤äé▓┼╬ęéāųvĄ─╔ŽŪ¦éĆ(g©©)æ¬(y©®ng)ė├Ż¼╚½▓┐╚▌Ų„╗»Ż¼Ę┼į┌╬ęéāĄ─æ¬(y©®ng)ė├╔╠ĄĻ«ö(d©Īng)ųąĪŻæ¬(y©®ng)ė├╔╠ĄĻ└’├µĄ─├┐ę╗ĒŚ(xi©żng)æ¬(y©®ng)ė├Č╝╩Ūś╦(bi©Īo)£╩(zh©│n)Ą─Ę■äš(w©┤)Ż¼▀@ą®Ę■äš(w©┤)į┌īŹ(sh©¬)└²╗»Ą─Ģr(sh©¬)║“┐╔─▄Ģ■(hu©¼)ė╔Äū░┘éĆ(g©©)╔ŽŪ¦éĆ(g©©)╚▌Ų„ĮM│╔ĪŻ─Ū├┤╬ęéāĢ■(hu©¼)░č▀@éĆ(g©©)æ¬(y©®ng)ė├┤“░³│╔ę╗éĆ(g©©)Ę■äš(w©┤)Ż¼ū„×ķš¹¾w▀M(j©¼n)ąąš{(di©żo)Č╚ĪŻ═©▀^▀@ĘNĘĮ╩ĮŻ¼╬ęéā┐╔ęįėąą¦ĄžīŹ(sh©¬)¼F(xi©żn)░čöĄ(sh©┤)ō■(j©┤)Äņ▒Š╔ĒĄ─Ę■äš(w©┤)«ö(d©Īng)│╔ŲĮ┼_(t©ói)Ę■äš(w©┤)Ż¼─▄ē“ę╗╝■ę╗╝■▓┐╩Ż¼─▄ē“▀M(j©¼n)ąąņ`╗ŅĄž?c©ói)U(ku©░)ÅłŻ¼═¼Ģr(sh©¬)╬ęéāę▓┐╔ęį░č╔Žīėæ¬(y©®ng)ė├Ž±╠O╣¹Ą─apple store░▓čbæ¬(y©®ng)ė├ę╗śėŻ¼į┌╬ęéāĄ─æ¬(y©®ng)ė├╔╠ĄĻųą┐ņ╦┘Ąž▓┐╩ĪŻ═¼Ģr(sh©¬)Ż¼▓╗═¼æ¬(y©®ng)ė├ų«ķg┐╔ęį═©▀^╚▌Ų„╝╝ąg(sh©┤)▀M(j©¼n)ąąėąą¦Ą─Ė¶ļxĪŻ
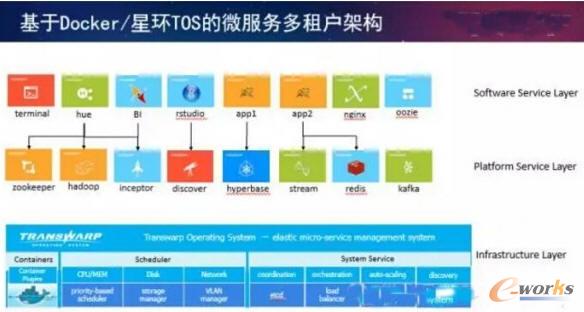
łD4 ╗∙ė┌Docker/ąŪŁh(hu©ón)TOSĄ─╬óĘ■äš(w©┤)ČÓūŌæ¶╝▄śŗ(g©░u)
Ą┌╚²ĘNŠ═╩ŪīŹ(sh©¬)¼F(xi©żn)īŹ(sh©¬)Ģr(sh©¬)öĄ(sh©┤)ō■(j©┤)é}ÄņĪŻ╬ęéāąĶę¬ėąę╗ĘNą┬Ą─ĘĮĘ©░čöĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)Ģr(sh©¬)ī¦(d©Żo)╚ļĄĮöĄ(sh©┤)é}«ö(d©Īng)ųąŻ¼ę╗ĘNĘĮĘ©╩Ū░čé„Įy(t©»ng)Ą─OLTPöĄ(sh©┤)ō■(j©┤)Äņ═©▀^ETL│ķ╚ļĄĮę╗éĆ(g©©)operational database«ö(d©Īng)ųąĪŻ▀^╚źŻ¼▀@Š═╩ŪĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)ÄņŻ¼¼F(xi©żn)į┌Ż¼║▄ČÓ╚╦╩Ūė├HBase╗“CassandraüĒīŹ(sh©¬)¼F(xi©żn)ĪŻĄ½╩Ūėąę╗éĆ(g©©)Ųš▒ķĄ─å¢Ņ}Š═╩ŪöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)╚ļ▀@éĆ(g©©)operational databaseęį║¾Ż¼┤¾╝ęąĶę¬ī”(du©¼)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąÅ═(f©┤)ļsĄ─Ęų╬÷Ż¼ę“?y©żn)ķö?sh©┤)ō■(j©┤)é}Äņ╩Ūė├üĒū÷Ęų╬÷Ą─ĪŻöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─Å═(f©┤)ļs│╠Č╚┐╔─▄╩Ūį┌╔Ž├µ┼▄Äū╩«╚fąąSQLĮy(t©»ng)ėŗ(j©¼)ĪŻ═¼Ģr(sh©¬)Ż¼╦³Ą─ę╗éĆ(g©©)Å═(f©┤)ļsĘų╬÷┐╔─▄Š═ėą╔Ž╚fąąŻ¼ąĶę¬┐ņ╦┘Ąž═Ļ│╔ĪŻ▀@śėĄ─ę╗éĆ(g©©)ę¬Ū¾īŹ(sh©¬)ļH╔Ž╩Ū║▄ļyØMūŃĄ─Ż¼ę“?y©żn)ķ╦³Ą─╠ž³c(di©Żn)╩Ūę¬ī”(du©¼)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąīŹ(sh©¬)Ģr(sh©¬)Ą─īæ╚ļŻ¼═¼Ģr(sh©¬)ę▓ę¬ī”(du©¼)╦³▀M(j©¼n)ąąÅ═(f©┤)ļsĄ─Ęų╬÷Ż¼─┐Ū░ø]ėąę╗ĒŚ(xi©żng)öĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)─▄ē“═¼Ģr(sh©¬)ØMūŃ▀@ā╔éĆ(g©©)ąĶŪ¾ĪŻ«ö(d©Īng)╚╗ėąĄ─ÅS╔╠╠¢(h©żo)ĘQ╝╚─▄ų¦│ųOLTPėų─▄ų¦│ųOLAPĪŻėąę╗éĆ(g©©)ą┬Ą─ŅÉäeĮąHybrid Transactional &AnalyticalDatabaseŻ¼▀@ĘNöĄ(sh©┤)ō■(j©┤)Äņę▓ėąŽÓĻP(gu©Īn)Ęų╬÷ł¾(b©żo)ĖµŻ¼Ą½─┐Ū░║├Ž±ø]ėą╝╝ąg(sh©┤)─▄▒╚▌^│╔╩ņĄžüĒĮŌøQ▀@éĆ(g©©)å¢Ņ}ĪŻ─Ū╬ęéā?c©©)┌ī?sh©¬)¼F(xi©żn)įōįO(sh©©)ėŗ(j©¼)─Ż╩ĮĄ─Ģr(sh©¬)║“Ż¼Ąūīė▓╔ė├Ą─╝╝ąg(sh©┤)ŲõīŹ(sh©¬)Š═╩Ū╗∙ė┌HadoopŻ¼╬ęéā╩Ūį┌HDFS╔Žśŗ(g©░u)įņūį╝║Ą─Ęų▓╝öĄ(sh©┤)ō■(j©┤)ÄņŻ¼┤µā”(ch©│)Ė±╩ĮĖ─▀M(j©¼n)┴╦ORCĄ─┤µā”(ch©│)Ė±╩ĮŻ¼┐╔ęįų¦│ųį÷äh▓ķĖ─Ż¼ę▓┐╔ęįų¦│ųĘų▓╝╩Į╩┬äš(w©┤)╠Ä└ĒĪŻ╬ęéāŪ░├µķ_░l(f©Ī)┴╦ę╗éĆ(g©©)ETLĄ─╣żŠ▀Ż¼┐╔ęį░čöĄ(sh©┤)ō■(j©┤)ÄņĄ─╚šųŠ▀M(j©¼n)ąąųžĘ┼Ż¼ų▒Įė▓Õ╚ļĄĮORC╩┬äš(w©┤)▒Ē└’├µ╚źĪŻ▀@╩Ūę╗éĆ(g©©)£╩(zh©│n)īŹ(sh©¬)Ģr(sh©¬)Ą─▓┘ū„Ż¼═©│Ż╩ŪÄūĘųńŖā╚(n©©i)─▄═Ļ│╔Å─Į╗ęūą═öĄ(sh©┤)ō■(j©┤)ÄņīŹ(sh©¬)Ģr(sh©¬)═¼▓ĮĄĮHadoop«ö(d©Īng)ųąŻ¼╚╗║¾į┌▀@éĆ(g©©)╔Ž├µĄ─ū÷Å═(f©┤)ļsĻP(gu©Īn)ŽĄŻ¼▀@éĆ(g©©)Ęų╬÷╩ŪĘŪ│ŻĖ▀ą¦Ą─ĪŻ▀@╩Ūę╗ĘNīŹ(sh©¬)¼F(xi©żn)ĘĮ╩ĮŻ¼Ą½╩Ū╦¹Ą─čėĢr(sh©¬)▀Ć▓╗ē“┐ņŻ¼ę“?y©żn)ķ╦³╩ŪĘųńŖ╝?j©¬)äeĄ─Ż¼▒╚╚ń╩ŪśI(y©©)äš(w©┤)öĄ(sh©┤)ō■(j©┤)ÄņŻ¼╚ńDB2ĮĶų·IBM Datastage░č▓┘ū„╚šųŠĘ┼│÷üĒų«║¾Ż¼į┘ĮŌūx▀@éĆ(g©©)╚šųŠŻ¼īæĄĮé}Äņųą╚źĪŻ
Ą½╩Ū▀Ćėąę╗ą®┐═涎Ż═¹╩ŪĖ³īŹ(sh©¬)Ģr(sh©¬)Ą─Ż¼╦¹ŽŻ═¹į┌Äū├ļńŖų«ā╚(n©©i)─▄ē“═Ļ│╔ėŗ(j©¼)╦ŃŻ¼▀@éĆ(g©©)Ģr(sh©¬)║“╬ęéā▓╔ė├Ą┌Č■ĘNĘĮĘ©╩Ū░čöĄ(sh©┤)ō■(j©┤)┼cÅ═(f©┤)ļsėŗ(j©¼)╦ŃŪ░═ŲĄĮ┴„╠Ä└Ē┐“╝▄ųą╚źĪŻŪ░ų├Ą─Į╗ęūŽĄĮy(t©»ng)═©│Ż╩Ū▓╔ė├▀@ĘNĘĮ╩ĮŻ¼Į±╠ņėą║▄ČÓĮ╚┌ÖC(j©®)śŗ(g©░u)Ą─æ¬(y©®ng)ė├Ż¼╠žäe╩ŪŠW(w©Żng)ŃyŻ¼Ž±╗ź┬ō(li©ón)ŠW(w©Żng)Į╚┌Ż¼╚½▓┐Ą─Į╗ęūėåå╬Č╝į┌Ž¹ŽóĻĀ(du©¼)┴ąųąŻ¼╚ńRabbitMQĪóKafkaŻ¼▀@éĆ(g©©)Ģr(sh©¬)║“╬ęéā╠ņ╔·Ą─ā×(y©Łu)ä▌(sh©¼)Ż¼Š═╩Ū┐╔ęįų▒ĮėÅ─Į╗ęūĻĀ(du©¼)┴ąųą░čöĄ(sh©┤)ō■(j©┤)╚Ī│÷üĒŻ¼į┌┴„╔Ž▀M(j©¼n)ąą▀\(y©┤n)╦ŃĪŻ┴„╔ŽĄ─ėŗ(j©¼)╦ŃīŹ(sh©¬)ļH╔Žę▓╩Ūį┌öĄ(sh©┤)ō■(j©┤)é}ÄņųąĄ─ę╗éĆ(g©©)Å═(f©┤)ļsĄ─▀\(y©┤n)╦ŃŻ¼ę▓ėą┤¾┴┐┤µā”(ch©│)▀^│╠║═SQLŻ¼▀@ĘĮ├µąŪŁh(hu©ón)ū÷┴╦┤¾┴┐Ą─╣żū„Ż¼╬ęéā─▄ē“į┌┴„╔Ž▀M(j©¼n)ąąÅ═(f©┤)ļsĄ─SQL▀\(y©┤n)╦ŃŻ¼ų¦│ųś╦(bi©Īo)£╩(zh©│n)SQL2003║═┤µā”(ch©│)▀^│╠Ż¼░³└©DB2║═Oracle┤µā”(ch©│)▀^│╠Ż¼ę▓Š═ęŌ╬Čų°─Ń┐╔ęį░čįŁüĒį┌║¾Č╦Ą─Å═(f©┤)ļsĄ─SQL▀\(y©┤n)╦ŃŪ░ų├ĄĮ┴„╔Ž├µüĒū÷Ż¼└²╚ńĢr(sh©¬)ķg┤░┐┌ųąĄ─öĄ(sh©┤)ō■(j©┤)śŗ(g©░u)│╔ę╗Åł▒ĒŻ¼▀@Åł▒ĒĖ·Ųš═©▒Ē▓╗ę╗śėĄ─ĄžĘĮ╩ŪŻ¼╦³╩Ūę╗ų▒╠Äė┌ūā╗»┴„äė(d©░ng)«ö(d©Īng)ųąĪŻ▀@ĘNĘĮ╩Į▀m║Žī”(du©¼)ėŗ(j©¼)╦ŃčėĢr(sh©¬)ę¬Ū¾║▄Ė▀Ą─Ż¼╬ęéāėąę╗éĆ(g©©)┐═æ¶ę¬į┌ę╗├ļńŖų«ā╚(n©©i)ī”(du©¼)╩ął÷(ch©Żng)ąąŪķ▀M(j©¼n)ąą▀\(y©┤n)╦ŃŻ¼╦¹ėą160éĆ(g©©)Å═(f©┤)ļs─Żą═Ż¼ėąą®Å═(f©┤)ļs─Żą═ŲõīŹ(sh©¬)╩Ūė├┤µā”(ch©│)▀^│╠üĒīæĄ├Ų½╬óĘųĘĮ│╠Ą─śŗ(g©░u)│╔ĪŻ▀@Š═ęŌ╬Čų°╬ęéāąĶę¬į┌┴„╔Ž├µū÷Å═(f©┤)ļsėŗ(j©¼)╦ŃŻ¼╚╗║¾čėĢr(sh©¬)ę¬į┌Äū├ļńŖā╚(n©©i)═Ļ│╔Ż¼ą┬ą═Ą─Ė▀ŅlĮ╗ęūĄ─ł÷(ch©Żng)║ŽŠ═ĘŪ│ŻąĶę¬▀@ĘN─Ż╩ĮĪŻ
Ą┌╦─ĘNöĄ(sh©┤)ō■(j©┤)é}ÄņįO(sh©©)ėŗ(j©¼)─Ż╩ĮųĖĄ─╩ŪŻ¼Įącontext independent Data warehouseŻ¼ę╗ĘN╔ŽŽ┬╬─¤oĻP(gu©Īn)Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņįO(sh©©)ėŗ(j©¼)╝▄śŗ(g©░u)ĪŻ▀@éĆ(g©©)╝▄śŗ(g©░u)═©│ŻąĶę¬═Ļ│╔ÄūĒŚ(xi©żng)ųžę¬Ą─╣żū„ĪŻ╩ūŽ╚Š═╩ŪšfŻ¼▀@éĆ(g©©)öĄ(sh©┤)ō■(j©┤)é}Äņæ¬(y©®ng)įō─▄ē“ų¦│ųĻP(gu©Īn)┬ō(li©ón)Ęų╬÷Ż¼ī”(du©¼)ė┌öĄ(sh©┤)ō■(j©┤)║═▒ĒŻ¼─▄ē“═©▀^ŽÓĻP(gu©Īn)ąįšęĄĮ╦³éāų«ķgĄ─ĻP(gu©Īn)┬ō(li©ón)ĻP(gu©Īn)ŽĄŻ¼═¼Ģr(sh©¬)ę▓─▄░l(f©Ī)¼F(xi©żn)ę╗ą®Įy(t©»ng)ėŗ(j©¼)īW(xu©”)╔ŽĄ─ę“╣¹ĻP(gu©Īn)ŽĄĪŻ▀@ę╗ēK╬ęéā╩ŪĮĶų·RšZčįüĒīŹ(sh©¬)¼F(xi©żn)Ą─ĪŻų╗▓╗▀^╬ęéā░čRšZčįĄ─║▄ČÓ╦ŃĘ©Ęų▓╝╩Į╗»┴╦Ż¼Ą½╩Ūī”(du©¼)ė├æ¶üĒųvŻ¼¾w“×(y©żn)╩ŪĖ·RšZčįę╗─Żę╗śėĄ─ĪŻ╚ń╣¹ė├æ¶ėą╩ņŽżRšZčįĄ─īŻ╝ęŻ¼┐╔ęį║▄┐ņ╔Ž╩ųŻ¼─▄ē“ė├RšZčįüĒū÷Å═(f©┤)ļsĄ─ĻP(gu©Īn)┬ō(li©ón)Ęų╬÷║═ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĪŻŲõīŹ(sh©¬)▀@ę╗ēKŻ¼ę▓Š═ęŌ╬Čų°╩Ū▓╗ąĶę¬Å═(f©┤)ļs─Żą═─Ż╩ĮŻ¼ī”(du©¼)öĄ(sh©┤)ō■(j©┤)╠žš„│ķ╚Īęį║¾Š═┐╔ęį▀M(j©¼n)ąąÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ż¼ę▓▓╗ąĶę¬╠½ČÓĄ─īŻ╝ęüĒÄ═─ŃįO(sh©©)ėŗ(j©¼)ęÄ(gu©®)ätŻ¼╦³╩Ū═©▀^ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĘĮĘ©ūįäė(d©░ng)Ä═─Ńča(b©│)│õĄ─ĪŻ▀@╩ŪĄ┌ę╗┤¾╣”─▄Ż¼Ą┌Č■╩ŪŠW(w©Żng)Įj(lu©░)Ęų╬÷ĪółDĘų╬÷Ą──▄┴”ĪŻ¼F(xi©żn)į┌╠žäe╩Ū╔ńĮ╗ŠW(w©Żng)Įj(lu©░)Ęų╬÷Īó═©ėŹŠW(w©Żng)Įj(lu©░)Ęų╬÷Ż¼ėų▒╚╚ńŃyąą┘YĮ▐D(zhu©Żn)┘~µ£Īóō·(d©Īn)▒ŻĻP(gu©Īn)ŽĄĪóŲ¾śI(y©©)═Č┘YĻP(gu©Īn)ŽĄŻ¼Č╝ę¬ė├łDĄ─╝╝ąg(sh©┤)üĒīŹ(sh©¬)¼F(xi©żn)ĪŻłD╝╝ąg(sh©┤)Š═ÅVĘ║Ąž▀\(y©┤n)ė├ĄĮĮ╚┌ÖC(j©®)śŗ(g©░u)Ą─Ę┤Ų█įp«ö(d©Īng)ųąĪŻį┌▀@śėę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)é}ÄņųąŻ¼łDĄ─Ęų╬÷─▄┴”ę▓╩Ūę╗éĆ(g©©)ųžę¬Ą─ĻP(gu©Īn)µI─▄┴”ĪŻĄ┌╚²ēK╩ŪąĶę¬╬─▒ŠĄ─Ęų╬÷═┌Š“─▄┴”Ż¼ę▓ąĶę¬╬─▒ŠųŲū„─▄┴”ĪŻĄ┌╦─éĆ(g©©)Š═╩Ū╬ęéāŽŻ═¹─▄▐Śē▀^╚źįO(sh©©)ėŗ(j©¼)Å═(f©┤)ļsĄ─▀ē▌ŗ─Żą═Ż¼ėąÄū╚fÅłųąķg▒ĒŻ¼▀@ĘN─Żą═┤·ār(ji©ż)ĘŪ│ŻĖ▀Ż¼Č°Ūę╣╠Č©Ž┬üĒŠ═║▄ļyūā╗»ĪŻ╬ęéāŽŻ═¹─▄ūįė╔Ąž▀M(j©¼n)ąą╠Į╦„Ż¼╬ęéāŽŻ═¹─▄ėąę╗éĆ(g©©)ūįų„Ą─╣żŠ▀ī”(du©¼)╦³▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)═┌Š“Ęų╬÷Ż¼▀@ę╗ēKę▓ąĶę¬╣żŠ▀╔ŽĄ─ų¦ō╬ĪŻ╦∙ęį╬ęéāĮ±╠ņį┌īŹ(sh©¬)¼F(xi©żn)▀@ĘNöĄ(sh©┤)ō■(j©┤)é}Äņ╝▄śŗ(g©░u)Ą─Ģr(sh©¬)║“Ż¼ŠC║Ž╩╣ė├┴╦╬ęéāĄ─Į^┤¾▓┐ĘųĮM╝■Ż¼╬ęéā╩╣ė├┴╦InceptorĘų╬÷ą═öĄ(sh©┤)ō■(j©┤)ÄņŻ¼ī”(du©¼)öĄ(sh©┤)ō■(j©┤)╠žš„▀M(j©¼n)ąąŪÕŽ┤Ż¼╔§ų┴SQL─▄ų▒Įėė├łDĄ─╦ŃĘ©▀M(j©¼n)ąąĘų╬÷ĪŻ═¼Ģr(sh©¬)Ż¼╬ęéā?c©©)┌Hyperbase╔Ž▀Ć─▄ų¦│ų╬─Ön╦č╦„Īó╬─▒Š╦č╦„Ż¼ę▓ų¦│ų┤¾ęÄ(gu©®)─ŻłDĄ─▓ó░l(f©Ī)▓ķįāŻ¼╬ęéāī”(du©¼)═Ō╠ß╣®DataFrameĄ─│ķŽ¾Ż¼Š═╩ŪRšZčįĄ─DataFrameĄ─│ķŽ¾Ż¼║═RšZčįĄ─įŁ╩╝DataFrame╩Ūę╗śėĄ─Ż¼┐╔ęįė├RĄ─╦ŃĘ©╚źįLå¢▀@ą®DataFrameŻ¼═¼Ģr(sh©¬)╬ęéāę▓╠ß╣®Äū╩«ĘNĘų▓╝╩ĮÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╦ŃĘ©Ż¼ūīė├æ¶üĒū÷┤¾ęÄ(gu©®)─ŻĄ─ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĪŻųąķgč▌ūā│÷ÄūĘNæ¬(y©®ng)ė├─Ż╩ĮŻ¼ėą’L(f©źng)ļU(xi©Żn)Ęų╬÷ĪóėąŠ½£╩(zh©│n)ĀIõNĄ─Ż¼ę▓ėąĘ┤Ų█įpĪó╬─▒ŠĘų╬÷ĪŻ«ö(d©Īng)╚╗╬ęéāę▓ŠC║Ž┴╦é„Įy(t©»ng)Ą─RĄ─å╬ÖC(j©®)╦ŃĘ©░³Ż¼ę▓╠ß╣®é„Įy(t©»ng)Ą─RĄ─¾w“×(y©żn)ĪŻ
▀@ą®╝╝ąg(sh©┤)ĮM╝■śŗ(g©░u)Į©│÷ę╗éĆ(g©©)═Ļš¹Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņĪŻ╚ń╣¹░č▀@ą®öĄ(sh©┤)ō■(j©┤)é}Äņ╚½▓┐Ę┼į┌ę╗Åł╝ł╔ŽĄ─įÆŻ¼─Ū╬ęéāŠ═─▄┐┤ĄĮš¹éĆ(g©©)╝▄śŗ(g©░u)Ą─ĄūīėŲõīŹ(sh©¬)╩Ūė├TOSīŹ(sh©¬)¼F(xi©żn)┘Yį┤╣▄└ĒČÓūŌæ¶Ą──▄┴”Ż¼ė├╚▌Ų„üĒĖ¶ļxŻ¼ųąķgīė╩Ūę╗éĆ(g©©)▀ē▌ŗöĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼░čĮY(ji©”)śŗ(g©░u)╗»ęį╝░ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)╚½▓┐Ę┼ĄĮ▀@éĆ(g©©)▀ē▌ŗīė«ö(d©Īng)ųąŻ¼═¼Ģr(sh©¬)╔Žīė╩ŪĮĶų·TOSäō(chu©żng)Į©▀ē▌ŗ╝»╚║üĒśŗ(g©░u)Į©╚ńūįė╔╠Į╦„Ą─æ¬(y©®ng)ė├Ż¼ę▓┐╔ęįė├üĒśŗ(g©░u)Į©é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}ÄņĪóśŗ(g©░u)įņöĄ(sh©┤)ō■(j©┤)╝»╩ąĪóśŗ(g©░u)įņīŹ(sh©¬)Ģr(sh©¬)öĄ(sh©┤)ō■(j©┤)é}ÄņĪŻš¹¾wüĒšfŠ═╩Ū┐╔ęįė├╚½ą┬Ą─╝╝ąg(sh©┤)üĒ┤“įņę╗éĆ(g©©)ą┬Ą─Ų¾śI(y©©)öĄ(sh©┤)ō■(j©┤)ŲĮ┼_(t©ói)Ż¼▀@ę▓╩Ū×ķ╩▓├┤╬ęéā▒╗Gartner▀x×ķöĄ(sh©┤)ō■(j©┤)é}Äņųąį┌▀h(yu©Żn)ęŖŽ¾Ž▐ųą╩ŪūŅėę▀ģĄ─ÅS╔╠Ż¼╩Ūę“?y©żn)ķ╬ęéāĄ─╝╝ąg(sh©┤)į┌ų¦│ų▀@╦─ŅÉą┬Ą─öĄ(sh©┤)ō■(j©┤)é}Äņųą╩ŪūŅŅI(l©½ng)Ž╚Ą─Č°Ūę╩ŪūŅ═ĻéõĄ─ÅS╔╠ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.guhuozai8.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║Hadoop╚ń║╬═Ųäė(d©░ng)¼F(xi©żn)┤·öĄ(sh©┤)ō■(j©┤)é}Äņ╝╝ąg(sh©┤)Ą─ūāĖ’
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.guhuozai8.cn/html/news/10515519209.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")














