



┤¾öĄō■Ą─å¢Ņ}
╗“įS╦∙ėąūxš▀Č╝├„░ū▀@ę╗³cŻ║öĄō■š²į┌’w╦┘į÷ķLŻ¼╚¶╩Ū─▄ē“ėąą¦└¹ė├Ą─įÆŻ¼╬ęéā─▄Å─▀@ą®öĄō■ųąšęĄĮĘŪ│ŻėąārųĄĄ─ęŖĮŌŻ╗é„Įy╝╝ągėą║▄ČÓČ╝╩Ūį┌40─ĻŪ░įOėŗĄ─Ż¼▒╚╚ńRDBMSsŻ¼▓╗ūŃęįäōįņ“┤¾öĄō■”│┤ū„╦∙ą¹ĘQĄ─╔╠śIārųĄĪŻį┌┤¾öĄō■╝╝ągĄ─╩╣ė├╔ŽŻ¼│ŻęŖĄ─░Ė└²╩Ū“┐═æ¶å╬ę╗ęĢłD”Ż╗īóĻPė┌┐═æ¶╦∙ų¬Ą└Ą─ę╗Ūąā╚╚▌Ę┼į┌ę╗ŲŻ¼ęį▒ŃūŅ┤¾╗»Ę■äš╠ß╣®┼cūį╔Ē╩š╚ļŻ¼▒╚╚ń┤_Č©Š▀¾wąĶę¬▓╔ė├╩▓├┤┤┘õNĘĮ╩ĮŻ¼ėų╩Ūį┌╩▓├┤Ģr║“Īó═©▀^╩▓├┤Ū■Ą└üĒ░l╦═ĪŻ
▒M╣▄┤¾öĄō■Ą─å¢Ņ}į┌ė┌Ż¼ūī╬ęéāīó▀@ĘNØō┴”ūā×ķ¼FīŹŻ¼Ė▀Ą╚╝ēĄ─ĻPµI╣”─▄ų┴╔┘░³└©Ž┬├µ▀@ą®─▄┴”Ż║
║Ž▓óą┼Žó╣┬Š«Īó═Ōį┌ę“╦ž┼cöĄō■┴„Ż╗
·┐žųŲöĄō■įLå¢Ż╗
·Ė∙ō■ąĶę¬▐D╗»öĄō■Ż╗
·š¹║ŽöĄō■Ż╗
·×ķöĄō■Ęų╬÷╠ß╣®╣żŠ▀Ż╗
·░l▓╝öĄō■ł¾ĖµŻ╗
·īóęŖĮŌ¾w¼Fį┌▀\ĀI▀^│╠ųąŻ╗
·ūŅąĪ╗»╣żū„═Ļ│╔Ą─┐éōĒėą│╔▒Š┼cĒææ¬ĢrķgĪŻ
ė├öĄō■║■ū„×ķ┤░Ė
║▄ČÓ╣½╦Šš²į┌ė^═¹ę╗éĆ▒╗─│ą®╚╦ĘQ×ķöĄō■║■Ą─╝▄śŗŻ¼▀@éĆöĄō■ŲĮ┼_į┌║Ž▓óą┼Žó╣┬Š«öĄō■┴„ęį╝░į┌å╬¬ÜĄ─▀ē▌ŗ╬╗ų├ųął╠ąąöĄō■│ųŠ├╗»ĘĮ├µŠ▀ėąņ`╗ŅąįŻ¼─▄ē“Å─Ų¾śIūį╔Ēęį╝░Ą┌╚²ĘĮĄ─öĄō■ųą═┌Š“│÷ęŖĮŌĪŻīóHadoopŻ©░³└©Sparkį┌ā╚Ż®ė├ė┌öĄō■║■ęč│╔┤¾ä▌╦∙┌ģŻ¼įŁę“║▄ČÓŻ║╩╣ė├┐éōĒėą│╔▒Š▌^Ą═Ą─Ųš═©ė▓╝■Š═─▄▀MąąöUš╣Ż¼į╩įSė├ūxĢr─Ż╩ĮŻ©schema-on-readŻ®╩š╚Ī┤¾┴┐öĄō■Ż¼ų¦│ųķ_į┤Ż¼░³└©ė├SQL║═Ųš═©šZčįśŗĮ©Ęų▓╝╩Į╠Ä└ĒīėĪŻ┤╦═ŌŻ¼Ž±č┼╗ó║═╣╚ĖĶ▀@śėĄ─webscale╣½╦ŠČ╝╩ŪįńŲ┌ś╦ŚUŻ¼ĮĶė├▀@ĘN╝▄śŗį┌ĮŌøQŠWšŠ╦„ę²ŽÓĻPĄ─å¢Ņ}Ģr½@Ą├┴╦Š▐┤¾Ą─│╔╣”ĪŻ
HadoopųąĄ─öĄō■│ųŠ├╗»▀xĒŚ
▀@śėę╗üĒŻ¼Å─▀@└’ķ_╩╝įu╣└öĄō■║■ĮŌøQĘĮ░ĖĄ─Ū░Š░╦Ų║§║▄║Ž└ĒĪŻę╗Ą®ķ_╩╝Å─Ė³╔ŅĄ─īė┤╬└ĒĮŌHadoopĄ─ā╚║ŁŻ¼─ŃŠ═Ģ■░l¼F└’├µ╦∙░³║¼Ą─ĒŚ─┐šµĄ─╩Ū░³┴_╚fŽ¾Ż¼║Ł╔w┴╦öĄō■╠Ä└ĒĄ─ĘĮĘĮ├µ├µĪŻė├Hadoopį┌öĄō■║■ųą╠Į£y┤µā”Ą─öĄō■ĢrŻ¼ėąā╔éĆų„ę¬▀xĒŚŻ║HDFS║═HBaseĪŻ╩╣ė├HDFSĢrŻ¼┐╔ęįūįąąøQČ©╚ń║╬į┌ų╗╠Ē╝ė╬─╝■ųąī”öĄō■▀MąąŠÄ┤aŻ¼░³└©JSONĪóCSVĪóAvroĄ╚Ą╚Ż¼ę“×ķHDFSų╗╩Ūę╗éĆ╬─╝■ŽĄĮyŻ¼ŠÄ┤aĘĮ╩Į╚½ė╔─ŃøQČ©ĪŻŽÓĘ┤Ż¼HBase╩Ūę╗éĆöĄō■ÄņŻ¼Ųõ╠žėąĄ─öĄō■ŠÄ┤aĘĮ╩Į┐╔ęįīóėøõøīæ╚ļĄ─╦┘Č╚ūŅā×╗»Ż¼į┌═©▀^ų„µI▓ķįāĢrł╠ąąų╗ūxĄ─╦┘Č╚ŽÓī”ę▓║▄┐ņĪŻ
▀@ę▓╩Ūė├HadoopĄ─öĄō■║■ų«„╚┴”╦∙į┌Ż¼╦³─▄īŹ¼FšµīŹŪķørŽ┬Ą─ąĶŪ¾ĪŻę“┤╦Ż¼╬ęéāŠ═─▄╩╣ė├HadoopüĒł╠ąą╔Ž├µ┴ą│÷Ą─Ė▀īė┤╬ąĶŪ¾┴╦ĪŻį┌Ž±Spark║═Hive▀@śėĄ─Hadoop╔·æBŽĄĮyųąŻ¼╚įąĶė├ĄĮĘų▓╝╩Į╠Ä└ĒīėŻ¼Ą½▓╗ąĶHDFS╗“HBase┴╦Ż¼ę“┤╦─Ń┐╔ęįÅ─Ęų▓╝╩Į╠Ä└Ēīėųą▀xō±│ųŠ├╗»īė├µĪŻų«Ū░Ą─▓®╬─ųąėąŽÓĻP░Ė└²Ż¼├Ķ╩÷┴╦╩╣ė├Sparkį┌MongoDBųąūxīæöĄō■ĪŻ▀Ćėąę╗Ų¬▓®╬─ę▓║▄ŅÉ╦ŲŻ¼ūC├„┴╦MongoDBų╗╩Ūūx╚ĪöĄō■Ą─┴Ēę╗éĆHive▒ĒĖ±ĪŻ
╦„ę²╚į┼f║▄ųžę¬
┤¾ČÓ╩ņŽżRDBMSsĄ─╝╝ąg╚╦åT░l¼FŻ¼Å─▒Ē▀_▓ķįā─▄┴”ĄĮČ■╝ē╦„ę²Ż¼į┘ĄĮ╝ė╦┘▓ķįā╚½Č╝ārųĄŠ▐┤¾Ż©╝┤▒Ń─Ż╩Į╣╠Č©Īó┐éōĒėą│╔▒ŠĖ▀ęį╝░RDBMSsĄ─┐╔öUš╣ąįėąŽ▐Ż¼▀@ą®╩╣Ą├╦³║▄ļy▒╗ė├ū„öĄō■║■Ż®ĪŻ╚ń╣¹╬ęéāį┌öĄō■Äņ│ųŠ├╗»ųąų╗ė├ĄĮHDFS║═HBaseŻ¼Š═¤oĘ©īŹ¼F╬ęéāŲ┌┤²Ą─öĄō■Äņ┼RĢr╦„ę²┴╦Ż¼╠žäe╩Ūė÷ĄĮŽ┬├µÄūéĆŽ▐ųŲĢrŻ║
┼RĢrŪąŲ¼Ż║▓╗═©▀^Č■╝ē╦„ę²Ż¼╬ęéā╚ń║╬ī”▓╗ų╣ę╗éĆų„µIś╦ūR│÷Ą─öĄō■ŪąŲ¼▀Mąąėąą¦ĄžĘų╬÷─žŻ¼└²╚ńī”╬ęéāĄ─ūŅ╝č┐═涗—─Ūą®Ž¹┘MĮŅ~│¼▀^XĄ─┐═æ¶▀MąąĘų╬÷Ż┐ė╔ė┌öĄō■╠½▀^Š▐┤¾Ż¼Žļę¬═©▀^Æ▀├Ķšę│÷ūŅ╝č┐═æ¶Č╝Ģ■┴Ņ╣żū„┐©ūĪĪŻ
Ą═čė▀tł¾ĖµŻ║╚ń╣¹ø]ėąņ`╗ŅĄ─╦„ę²ĘĮ╩ĮŻ¼╬ęéā╚ń║╬į┌┤╬├ļ╝ēĢrķgā╚Ēææ¬┐═æ¶Ą─ąĶŪ¾Ż¼×ķ╦¹éā╠ß╣®ėąārųĄĄ─öĄō■ł¾Ėµ─žŻ┐į┘┤╬Ż¼╬ęéāų╗─▄╩╣ė├Ž¹┘Mš▀Ą─┘~æ¶╠¢╗“š▀Ųõ╦¹ų„µIüĒ▀Mąą┐ņ╦┘ł¾ĖµŻ¼Č°▓╗╩Ū═©▀^Ž¹┘Mš▀Ą─ąš├¹ĪóļŖįÆ╠¢┤aĪóÓ]ŠÄĪó╗©┘MĄ╚Ą╚ĪŻ╠žäe╠ߥĮŻ║MongoDBäéäé×ķ╗∙ė┌SQLĄ─ł¾Ėµ╣żŠ▀░l▓╝┴╦BI ConnectorĪŻ
▀\ĀI╗»Ż║═¼śėĄžŻ¼╬ęéā╚ń║╬īóėąārųĄĄ─ęŖĮŌę²╚ļæ¬ė├▀\ĀIųąŻ¼Å─Č°į┌ūŅ┤¾╗»ė░Ēæ╣½╦Š║═Ž¹┘Mš▀Ą─═¼ĢrīóöĄō■ūā¼FŻ┐ŽļŽ¾ę╗Ž┬┐═Ę■īŻåTŻ©CSRŻ®Ėµų¬Ž¹┘Mš▀Ż¼ę“×ķöĄō■║■āHų¦│ų▀@éĆų„µIŻ¼╦¹▒žĒÜ╠ß╣®┘~╠¢▓┼─▄▓ķįā╦∙ėąĄ─ą┼ŽóŻ╗╗“š▀▓ķįāąĶę¬10ĘųńŖĢrķgĪŻ
«ö╚╗Ż¼Ųõųąėąą®å¢Ņ}┐╔ęį═©▀^ūā═©ĘĮĘ©ĮŌøQŻ¼▓╗▀^Ģ■ī¦ų┬┐éōĒėą│╔▒ŠĖ³Ė▀Īóķ_░l╗“▀\ĀI╣żū„Ė³ČÓĪóčė▀tę▓Ė³Ė▀ĪŻ└²╚ńŻ¼╩╣ė├╦č╦„ę²Ūµ╗“š▀īŹ¾w╗»ęĢłDČ°▓╗╩Ū═©▀^ų„µIüĒ▓ķįāŻ╗▓╗▀^╔į║¾▀ĆąĶĘĄ╗žĄĮöĄō■ÄņŻ¼į┌ėą═Ļš¹ėøõøĄ─öĄō■Äņųąī”ų„▒Ē▀Mąąį┘┤╬▓ķįāŻ¼ęį½@Ą├╦∙ąĶĄ─═Ļš¹ą┼ŽóĪŻ│²┴╦čė▀tĘŁ▒Čų«═ŌŻ¼▀ĆąĶę¬║─┘MŅ~═ŌĄ─╣▄└ĒĪóķ_░l╣żū„Ż¼ęį╝░å╬¬Ü╦č╦„ę²ŪµąĶꬥ─╗∙ĄAįO╩®Ż¼▀ĆėąīŹ¾w╗»ęĢłD╦∙ąĶĄ─ŠSūoŻ¼╝ė╔ŽīóöĄō■īæ╚ļĄĮŲõ╦¹ĄžĘĮįņ│╔Ą─ę╗ų┬ąįå¢Ņ}ĪŻ▒Ż│ų╬ęéāĄ─įOėŗįŁätŻ¼ų╗ė├╬ęéāė├æTĄ─Ųš═©ņ`╗Ņ╦„ę²▓╗╩Ū║▄║├├┤Ż┐
MongoDB╩Ūę╗éĆėąą¦öĄō■║■Ą─ųžę¬▓┐Ęų
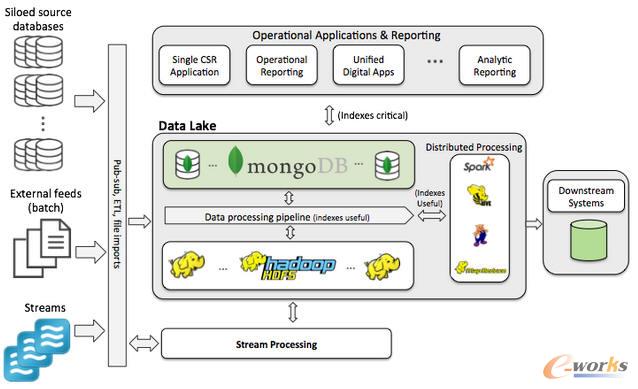
łD ┤¾öĄō■╝▄śŗ
╬ęéāķ_╩╝ėæšōŻ¼╠Į╦„å╬ė├Hadoop╩Ūʱ─▄ØMūŃöĄō■║■Ą─ąĶŪ¾Ż¼▓ó░l¼F┴╦ų┴╔┘3éĆå¢Ņ}ĪŻ╬ęéā─▄ʱį┌╝▄śŗųą┴Ē╝ėę╗īė│ųŠ├╗»īė├µüĒĮŌøQ▀@ą®å¢Ņ}Ż¼═¼Ģr▒Ż│ųįOėŗįŁät——╩╣ė├Ą═┐éōĒėą│╔▒ŠĄ─Ųš═©ė▓╝■Īóķ_į┤─Ż╩ĮĪóūxĢr─Ż╩Į▀ĆėąHadoopĘų▓╝╩ĮöĄō■īė——┼cų«Ū░ę╗ų┬─žŻ┐
╬ę▀xō±▒Š╬─Ą─ų„Ņ}╩Ūę“×ķŻ¼MongoDBŠ═╩Ūį┌Hadoop-onlyöĄō■║■ųąŻ¼ča╬╗ūŅā׹ѥ─öĄō■ÄņĪŻ╚ń╣¹╩╣ė├┴Ēę╗éĆķ_į┤NoSQLöĄō■ÄņŻ¼Š═Ģ■░l¼FŲõųąÄū║§▓╗║¼Č■╝ē╦„ę²Ż©╩╣ė├Č■╝ē╦„ę²Ģ■ī¦ų┬¤oĘ©═¼▓ĮöĄō■Ż®Ż¼ę▓ø]ėąĘųĮM║═Š█║Ž╣”─▄ĪŻ─Ń┐╔ęį╩╣ė├Ųõųąę╗ą®öĄō■ÄņīóöĄō■īæ╚ļöĄō■║■Ż¼▓╗▀^╚ń╣¹│÷ė┌╔╠śIąĶŪ¾Žļę¬ęįņ`╗ŅĄ─ĘĮ╩Į╩╣ė├Č■╝ē╦„ę²ūx╚ĪĄ─įÆŻ¼╩Ūū÷▓╗ĄĮĄ─ĪŻ╚ń╣¹Žļę¬į┌öĄō■║■ųą╩╣ė├ķ_į┤RDBMSŻ¼╬ęéāęčĮøšf▀^Ż¼╦³éā╣╠Č©Ą──Ż╩ĮĪó░║┘FĄ─┤╣ų▒öUš╣─Żą═Č╝▀`▒│┴╦╬ęéāįOėŗöĄō■║■Ą─įŁätĪŻ
ę“┤╦Ż¼═Ų╦]╩╣ė├Ž┬├µĄ─╝▄śŗüĒśŗĮ©öĄō■║■ĪŻ
MongoDBī”öĄō■║■ĘŪ│Żųžę¬
▀@éĆ╝▄śŗīóMongoDBū„×ķ│ųŠ├╗»īė├µ╝ė╚ļ╚╬║╬ąĶę¬▒Ē▀_▓ķįāĄ─öĄō■╝»ųąŻ¼š²┼c─ŃąĶę¬╦„ę²Ą─╚²éĆįŁę“Ż©╔Ž├µ┴ą┼e┴╦Ż®ŽÓĻPĪŻė╔ė┌ąĶŪ¾öĄō■üĒūįŽ¹┘Mš▀Ż¼¤ošō╩ŪʱīóöĄō■░l▓╝ĄĮHDFS║═/╗“MongoDBųąŻ¼╬ę═Ų╦]ė├governance functionüĒ┤_Č©ĪŻ¤ošō┤µā”ĄĮHDFS╗“š▀MongoDB╔ŽŻ¼Š═┐╔ęį▀\ąąĘų▓╝╩Į╠Ä└Ē╚╬䚯¼▒╚╚ńHive║═SparkĪŻ▓╗▀^╚ń╣¹öĄō■į┌MongoDB╔ŽŻ¼ę“×ķ║Y▀xś╦£╩Ž┬Ę┼ĄĮöĄō■ÄņųąŻ¼▓╗Ž±į┌HDFSųą─ŪśėÆ▀├Ķ╬─╝■Ż¼─ŃŠ═─▄į┌öĄō■┼RĢrŪąŲ¼╔Ž▀\ąąėąą¦Ęų╬÷┴╦ĪŻ┼c┤╦ŽÓ╦ŲŻ¼MongoDBųąĄ─öĄō■ę▓┐╔ė├ė┌īŹĢrĪóĄ═čė▀tł¾ĖµŻ¼▓ó×ķśŗĮ©Ą─æ¬ė├╦∙ė├ĄĮĄ─╦∙ėąŽĄĮy╠ß╣®▀\ĀIöĄō■ŲĮ┼_Ę■äšĪŻ
╚ńĮ±ę╗ą®╣½╦Šų╗╩ŪīóöĄō■Å═ųŲĄĮHadoopųą▀Mąą▐DōQŻ¼╚╗║¾į┘Å═ųŲĄĮŲõ╦¹ĄžĘĮŻ¼ė├ė┌═Ļ│╔ėąārųĄĄ─╣żū„ĪŻ×ķ╩▓├┤▓╗ų▒Įė└¹ė├öĄō■║■Ż¼░lō]ūŅ┤¾ārųĄ─žŻ┐╩╣ė├MongoDB┐╔ęįīóārųĄČÓ┤╬ĘŁ▒ČĪŻ
ĮYšō
ė^▓ņķLŲ┌┼cČ╠Ų┌ąĶŪ¾Ż¼┤_▒Ż▀@ą®ąĶŪ¾┐╔ęį═©▀^║╦ą─HadoopĘų▓╝ųąĄ─ūŅ╝č╣żŠ▀Ż¼ęį╝░MongoDB▀@śėĄ─╔·æBŁhŠ│īŹ¼FŻ¼öĄō■║■ī”─ŃČ°čįŠ═╩ŪėąārųĄŪęČ°┐╔ąąĄ─ĪŻę╗ą®Ų¾śIį┌╩╣ė├öĄō■║■ĢrŻ¼ų╗╗©┘Mę╗─ĻĢrķgŪÕŽ┤╦∙ėąöĄō■Ż¼╚╗║¾īóŲõīæ╚ļHDFSŻ¼ŽŻ═¹į┌╬┤üĒ─▄ė├▀@ą®öĄō■½@╚ĪārųĄĪŻĮY╣¹ģs╩¦═¹Ąž░l¼F▀@ą®öĄō■║┴¤oārųĄŻ¼╩┬īŹ╔Žį┌öĄō■┼cŽ¹┘Mš▀ų«ķg▀Ć┤µį┌┴Ēę╗ĘNbatch layerīė├µĪŻ
═©▀^īóHadoop┼cMongoDB║Ž▓óŻ¼öĄō■Äņ┐╔ęį┤_▒Ż│╔╣”Ż¼▓ó╩Ūę╗éĆ▒Ż│ų▌^Ą═Ą─┐éōĒėą│╔▒ŠŻ¼ūŅ┐ņĒææ¬╦∙ėąė├æ¶Ż©öĄō■┐ŲīW╝ęĪóĘų╬÷ĤĪó╔╠śIė├æ¶ĪóŽ¹┘Mš▀ūį╔ĒŻ®Ą─ņ`╗ŅöĄō■ŲĮ┼_ĪŻėą┴╦öĄō■║■Ż¼╣½╦Š║═åT╣żŠ═─▄ė├╦³üĒ½@╚Ī¬Ü╠žĄ─ęŖĮŌŻ¼┼c┐═æ¶▀Mąąėąą¦£Ž═©Ż¼īóöĄō■ūā¼F▓óæä┘ĖéĀÄī”╩ųĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║┤¾öĄō■╝▄śŗĄ─╬┤üĒ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/news/10515519182.html





















