



1Ū░čį
ļSų°ųŪ─▄ęŲäėĮKČ╦Ą─Ųš╝░┼cæ¬(y©®ng)ė├Ż¼ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)æ¬(y©®ng)ė├╩ął÷ęčĮø(j©®ng)│╔×ķę╗éĆ╚šęµĘ▒śsĄ─╔·æB(t©żi)ŽĄĮy(t©»ng)Ż¼▓╔ė├įŲėŗ╦Ń╝╝ąg(sh©┤)īŹ¼F(xi©żn)ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)æ¬(y©®ng)ė├│╔×ķų„┴„Ż¼╝┤═©▀^ęŲäėŠW(w©Żng)Įj(lu©░)ęį░┤ąĶĪóęūöUš╣Ą─ĘĮ╩ĮŻ¼½@Ą├╦∙ąĶ╗∙ĄA(ch©│)įO(sh©©)╩®ĪóŲĮ┼_Īó▄ø╝■Ż©╗“æ¬(y©®ng)ė├Ż®Ą╚Ą─ę╗ĘNIT┘Yį┤╗“Ż©ą┼ŽóŻ®Ę■äš(w©┤)Ą─Į╗ĖČ┼c╩╣ė├─Ż╩ĮĪŻ2009─Ļųąć°Ė„┤¾▀\ĀI╔╠½@Ą├3G┼ŲššŻ¼ś╦ųŠų°ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)į┌ųąć°Ą─░l(f©Ī)š╣▀M╚ļ┴╦┐ņ▄ćĄ└ĪŻ╬ęć°═Č╚ļ┴╦╚fā|ęÄ(gu©®)─ŻĄ─3GŠW(w©Żng)Įj(lu©░)╚¶ę¬│╔╣”Ż¼ę▓▒žĒÜę└┘ćė┌ŅÉ═¼╠O╣¹AppStore▀@śėĄ─ęŲäėįŲėŗ╦ŃĄ─│╔╣”ĪŻ└¹ė├ęŲäėįŲėŗ╦ŃĄ─Ė„ĘNęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)Ę■äš(w©┤)š²ųØu╔Ņ╚ļĄĮ╚╦éāĄ─╔·╗ŅųąŻ¼Č°╚╦éāī”ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)Ė„ŅÉĘ■äš(w©┤)Ą─┤¾┴┐╩╣ė├ėųīóĘ┤▀^üĒ▀Mę╗▓Į═ŲäėĪ░ęŲäėįŲėŗ╦ŃĪ▒╩ął÷┼c╝╝ąg(sh©┤)Ą─░l(f©Ī)š╣ĪŻ
ęŲäėĮKČ╦ęčĮø(j©®ng)ė╔įŁüĒå╬ę╗Ą─═©įÆ╣”─▄Ž“šZę¶ĪóöĄ(sh©┤)ō■(j©┤)ĪółDŽ±ŠC║ŽĘĮŽ“č▌ūāŻ¼╩ųÖCš²Įo╚╦éāĦüĒįĮüĒįĮžSĖ╗Ą─æ¬(y©®ng)ė├ĪŻ▀M╚ļ3GĢr┤·ęį║¾Ż¼ęŲäė═©ą┼ŠW(w©Żng)Įj(lu©░)Ą─öĄ(sh©┤)ō■(j©┤)é„▌ö╦┘Č╚’@ų°╠ßĖ▀Ż¼╩ŪGSMĄ─200▒ČĪóGPRSĄ─13▒Čų«ČÓĪŻĮY(ji©”)║Ž═©ą┼ŠW(w©Żng)Įj(lu©░)╚ń┤╦Ė’├³╗»Ą─╝╝ąg(sh©┤)═╗ŲŲŻ¼ųŪ─▄╩ųÖC║═Ė▀╦┘Ą─ ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)Įė╚ļĄ─ĮY(ji©”)║ŽŻ¼š²▓╗öÓĖ─ūāų°╚╦éāĄ─╔·╗ŅŻ¼Å─Č°┐╔ļSĢrļSĄžŽĒ╩▄╗ź┬ō(li©ón)ŠW(w©Żng)ĦüĒĄ─┐ņśĘĪŻüĒūįųąć°╗ź┬ō(li©ón)ŠW(w©Żng)ą┼Žóųąą─Ą─öĄ(sh©┤)ō■(j©┤)Ż¼Įžų┴2010─ĻĄūŻ¼ųąć°ėą3.03ā|ė├æ¶╩╣ė├╩ųÖC╔ŽŠW(w©Żng)Ż¼▌^╚ź─Ļį÷╝ė┴╦2.3ā|Ż¼╩ųÖC╔ŽŠW(w©Żng)ė├æ¶╚ń┤╦Ė▀╦┘Ą─į÷ķLŻ¼Įo▀\ĀI╔╠ĦüĒ┴╦žS║±╗žł¾Ż¼═¼Ģrę▓░ķļSų°ę╗ą®ć└ųžĄ─å¢Ņ}Ż║ė├æ¶╩ųÖC┴„┴┐Ą─═╗ŲŲąįį÷ķLĮo▀\ĀI╔╠Ą─▀\ĀIų¦ō╬ŽĄĮy(t©»ng)ĦüĒ┴╦ć└Š■Ą─╠¶æ(zh©żn)Ż¼ė├æ¶Ą─╩ųÖC╔ŽŠW(w©Żng)«a(ch©Żn)╔·┴╦┤¾┴┐Ą─╔ŽŠW(w©Żng)╚šųŠŻ¼Ė∙ō■(j©┤)─│▀\ĀI╔╠─│╩Ī╣½╦ŠöĄ(sh©┤)ō■(j©┤)’@╩ŠŻ¼├┐╠ņė├üĒėøõøė├æ¶╔ŽŠW(w©Żng)ąą×ķĄ─öĄ(sh©┤)ō■(j©┤)▀_ĄĮ┴╦1TŻ╗Č°ļSų°ė├涎¹┘MęŌūRĄ─▓╗öÓį÷ÅŖŻ¼ė├æ¶ī”ūį╝║╔ŽŠW(w©Żng)Ą─┴„┴┐ę▓įĮüĒįĮĻP(gu©Īn)ą─Ż¼╦¹éāĻP(gu©Īn)ą─ūį╝║┴„┴┐Ą─╩╣ė├ŪķørĪó╦∙╩╣ė├Ą─┴„┴┐├„╝ÜŻ¼Š═Ž±ī”šZę¶║═Č╠ą┼ę╗śėŻ¼ąĶę¬├„├„░ū░ūĄ─Ž¹┘MŻ¼├µī”▀@ą®║Ż┴┐öĄ(sh©┤)ō■(j©┤)▓ķįāŻ¼é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)ÄņęčĮø(j©®ng)║▄ļyų¦ō╬¼F(xi©żn)ėąĄ─æ¬(y©®ng)ė├ĪŻ▒Š╬─īóęįė├æ¶╔ŽŠW(w©Żng)ėøõø▓ķįāŽĄĮy(t©»ng)×ķ└²üĒųv╩÷Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņį┌▀\ĀI╔╠BSSųąĄ─æ¬(y©®ng)ė├ĪŻ
2Ęų▓╝╩Į╔ŽŠW(w©Żng)ėøõø▓ķįāŽĄĮy(t©»ng)Ą─ĻP(gu©Īn)µI╝╝ąg(sh©┤)
╦∙ų^Ęų▓╝╩ĮŻ¼į┌▀@└’Ż¼║▄¬M┴xĄ─ųĖ┤·ęįGoogleĄ─╚²±{±R▄ćGFSŻ¼Map/ReduceŻ¼BigTable×ķ┐“╝▄║╦ą─Ą─Ęų▓╝╩Į┤µā”║═ėŗ╦ŃŽĄĮy(t©»ng)ĪŻHadoop╩Ūę╗éĆ╗∙ė┌JavaīŹ¼F(xi©żn)Ą─Īóķ_į┤Ą─ĪóĘų▓╝╩Į┤µā”║═ėŗ╦ŃĄ─ĒŚ─┐ĪŻū„×ķ▀@éĆŅI(l©½ng)ė“ūŅĖ╗╩ó├¹Ą─ķ_į┤ĒŚ─┐ų«ę╗Ż¼╦³Ą─╩╣ė├š▀ę▓╩Ū┤¾┼Ų╚ńįŲŻ¼░³└©YahooŻ¼AmazonŻ¼F(xi©żn)acebookĄ╚ĪŻHadoop▒Š╔ĒŻ¼īŹ¼F(xi©żn)Ą─╩ŪĘų▓╝╩ĮĄ─╬─╝■ŽĄĮy(t©»ng)HDFSŻ¼║═Ęų▓╝╩ĮĄ─ėŗ╦ŃŻ©Map/ReduceŻ®┐“╝▄ĪŻ┤╦═ŌŻ¼Hadoop░³║¼ę╗ŽĄ┴ąöUš╣ĒŚ─┐Ż¼░³└©┴╦Ęų▓╝╩Į╬─╝■öĄ(sh©┤)ō■(j©┤)ÄņHBaseŻ©╦∙ī”æ¬(y©®ng)GoogleĄ─BigTableŻ®ĪóĘų▓╝╩Įģf(xi©”)═¼Ę■äš(w©┤)ZooKeeperŻ©ī”æ¬(y©®ng)GoogleĄ─ChubbyŻ®Ż¼Ą╚Ą╚ĪŻ
2.1Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)
Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼į┌š¹éĆĘų▓╝╩ĮŽĄĮy(t©»ng)¾wŽĄųą╠Äė┌ūŅĄ═īėūŅ╗∙ĄA(ch©│)Ą─Ąž╬╗ĪŻŅÖ├¹╦╝┴xŻ¼Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Š═╩ŪĘų▓╝╩Į+╬─╝■ŽĄĮy(t©»ng)ĪŻ╦³░³║¼▀@ā╔éĆĘĮ├µĄ─ā╚(n©©i)║ŁŻ¼Å─╬─╝■ŽĄĮy(t©»ng)┐═æ¶╩╣ė├Ą─ĮŪČ╚üĒ┐┤Ż¼╦³Š═╩Ūę╗éĆś╦£╩Ą─╬─╝■ŽĄĮy(t©»ng)Ż¼╠ß╣®┴╦ę╗ŽĄ┴ąAPIŻ¼ė╔┤╦▀Mąą╬─╝■╗“─┐õøĄ─äō(chu©żng)Į©ĪóęŲäėĪóäh│²ęį╝░ī”╬─╝■Ą─ūxīæĄ╚▓┘ū„ĪŻÅ─ā╚(n©©i)▓┐īŹ¼F(xi©żn)üĒ┐┤Ż¼Ęų▓╝╩ĮĄ─ŽĄĮy(t©»ng)ät▓╗į┘║═Ųš═©╬─╝■ŽĄĮy(t©»ng)ę╗śėÅ═(f©┤)ļs╣▄└Ē▒ŠĄž┤┼▒PŻ¼╦³Ą─╬─╝■ā╚(n©©i)╚▌║═─┐õøĮY(ji©”)śŗ(g©░u)Č╝▓╗╩Ū┤µā”į┌▒ŠĄž┤┼▒P╔ŽŻ¼Č°╩Ū═©▀^ŠW(w©Żng)Įj(lu©░)é„▌ö?sh©┤)Į▀hČ╦ŽĄĮy(t©»ng)╔ŽĪŻ▓óŪęŻ¼═¼ę╗éĆ╬─╝■┤µā”▓╗ų╗╩Ūį┌ę╗┼_ÖCŲ„╔ŽŻ¼Č°╩Ūį┌ę╗┤žÖCŲ„╔ŽĘų▓╝╩Į┤µā”Ż¼ģf(xi©”)═¼╠ß╣®Ę■äš(w©┤)Ż¼š²╦∙ų^Ęų▓╝╩ĮĪŻ
ę“┤╦Ż¼┐╝┴┐ę╗éĆĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─īŹ¼F(xi©żn)Ż¼ŲõīŹ▓╗Ę┴┐╔ęįÅ─▀@ā╔ĘĮ├µüĒĘųäeŲ╩╬÷Ż¼Č°║¾║ŽČ■×ķę╗ĪŻ╩ūŽ╚Ż¼┐┤╦³╚ń║╬╚źīŹ¼F(xi©żn)╬─╝■ŽĄĮy(t©»ng)╦∙ąĶĄ─╗∙▒Šį÷ĪóähĪóĖ─Īó▓ķĄ─╣”─▄Ż╗╚╗║¾Ż¼┐┤╦³╚ń║╬┐╝æ]Ęų▓╝╩ĮŽĄĮy(t©»ng)Ą─╠ž³cŻ¼╠ß╣®Ė³║├Ą─╚▌ÕeąįĪóžō▌dŲĮ║ŌĄ╚ĪŻ▀@Č■š▀║ŽČ■×ķę╗Ż¼Š═├„░ū┴╦ę╗éĆĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)š¹¾wĄ─īŹ¼F(xi©żn)─Ż╩ĮĪŻ
2.2Ęų▓╝╩Įėŗ╦Ń
Ęų▓╝╩Įėŗ╦ŃŻ¼═¼śė╩Ūę╗éĆīÆĘ║Ą─Ė┼─ŅŻ¼į┌▀@└’Ż¼╦³¬M┴xĄ─ųĖ┤·░┤GoogleMap/Reduce┐“╝▄╦∙įO(sh©©)ėŗĄ─Ęų▓╝╩Į┐“╝▄ĪŻĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼║▄┤¾│╠Č╚╔ŽŻ¼╩Ū×ķĖ„ĘNĘų▓╝╩Įėŗ╦ŃąĶŪ¾╦∙Ę■äš(w©┤)Ą─ĪŻŲõīŹĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Š═╩Ū╝ė┴╦Ęų▓╝╩ĮĄ─╬─╝■ŽĄĮy(t©»ng)Ż¼ŅÉ╦ŲĄ─Č©┴x═ŲÅVĄĮĘų▓╝╩Įėŗ╦Ń╔ŽŻ¼╬ęéā┐╔ęįīóŲõęĢ×ķį÷╝ė┴╦Ęų▓╝╩Įų¦│ųĄ─ėŗ╦Ń║»öĄ(sh©┤)ĪŻMap/Reduce┐“╝▄Įė╩▄Ė„ĘNĖ±╩ĮĄ─µIųĄī”╬─╝■ū„×ķ▌ö╚ļ/ūx╚Īėŗ╦Ń║¾Ż¼ūŅĮK╔·│╔ūįČ©┴xĖ±╩ĮĄ─▌ö│÷╬─╝■ĪŻČ°Å─Ęų▓╝╩ĮĄ─ĮŪČ╚╔Ž┐┤Ż¼Ęų▓╝╩Įėŗ╦ŃĄ─▌ö╚ļ╬─╝■═∙═∙ęÄ(gu©®)─ŻŠ▐┤¾Ż¼ŪęĘų▓╝į┌ČÓéĆÖCŲ„╔ŽŻ¼å╬ÖCėŗ╦Ń═Ļ╚½▓╗┐╔ų¦ō╬Ū깦┬╩Ą═Ž┬Ż¼ę“┤╦Map/Reduce┐“╝▄ąĶę¬╠ß╣®ę╗╠ūÖCųŲŻ¼īó┤╦ėŗ╦ŃöUš╣ĄĮ¤oŽ▐ęÄ(gu©®)─ŻĄ─ÖCŲ„╝»╚║╔Ž▀MąąĪŻMapReduceīóÅ═(f©┤)ļs▀\ąąė┌┤¾ęÄ(gu©®)─Ż╝»╚║╔ŽĄ─▓óąąėŗ╦Ń▀^│╠Ż¼Ė▀Č╚Ąž│ķŽ¾ĄĮ┴╦ā╔éĆ║»öĄ(sh©┤)Ż║Map║═ReduceŻ¼▀@╩Ūę╗éĆ┴Ņ╚╦¾@ėĀĄ─║åå╬ģsėų═■┴”Š▐┤¾Ą──Żą═ĪŻ▀m║Žė├MapReduceüĒ╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)╝»Ż©╗“╚╬äš(w©┤)Ż®ėąę╗éĆ╗∙▒Šę¬Ū¾Ż║┤²╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)╝»┐╔ęįĘųĮŌ│╔įSČÓąĪĄ─öĄ(sh©┤)ō■(j©┤)╝»Ż¼Č°Ūę├┐ę╗éĆąĪöĄ(sh©┤)ō■(j©┤)╝»Č╝┐╔ęį═Ļ╚½▓󹹥ž▀Mąą╠Ä└ĒĪŻ
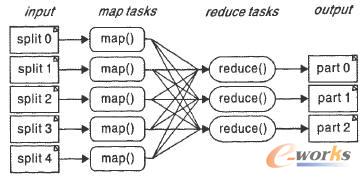
łD1 MapReduceėŗ╦Ń┴„│╠
łD1šf├„┴╦ė├MapReduceüĒ╠Ä└Ē┤¾öĄ(sh©┤)ō■(j©┤)╝»Ą─▀^│╠Ż¼▀@éĆMapReduceĄ─ėŗ╦Ń▀^│╠║åČ°čįų«Ż¼Š═╩Ūīó┤¾öĄ(sh©┤)ō■(j©┤)╝»ĘųĮŌ×ķ│╔░┘╔ŽŪ¦Ą─ąĪöĄ(sh©┤)ō■(j©┤)╝»Ż¼├┐éĆŻ©╗“╚¶Ė╔éĆŻ®öĄ(sh©┤)ō■(j©┤)╝»Ęųäeė╔╝»╚║ųąĄ─ę╗éĆĮY(ji©”)³cŻ©ę╗░ŃŠ═╩Ūę╗┼_Ųš═©Ą─ėŗ╦ŃÖCŻ®▀Mąą╠Ä└Ē▓ó╔·│╔ųąķgĮY(ji©”)╣¹Ż¼╚╗║¾▀@ą®ųąķgĮY(ji©”)╣¹ėųė╔┤¾┴┐Ą─ĮY(ji©”)³c▀Mąą║Ž▓óŻ¼ą╬│╔ūŅĮKĮY(ji©”)╣¹ĪŻ
ėŗ╦Ń─Żą═Ą─║╦ą─╩ŪMap║═Reduceā╔éĆ║»öĄ(sh©┤)Ż¼▀@ā╔éĆ║»öĄ(sh©┤)ė╔ė├涞ōž¤īŹ¼F(xi©żn)Ż¼╣”─▄╩Ū░┤ę╗Č©Ą─ė│╔õęÄ(gu©®)ätīó▌ö╚ļĄ─
ęįę╗éĆėŗ╦Ń╬─▒Š╬─╝■ųą├┐éĆå╬į~│÷¼F(xi©żn)Ą─┤╬öĄ(sh©┤)Ą─│╠ą“×ķ└²Ż¼
╗∙ė┌MapReduceėŗ╦Ń─Żą═ŠÄīæĘų▓╝╩Į▓óąą│╠ą“ĘŪ│Ż║åå╬Ż¼│╠ą“åTĄ─ų„ꬊÄ┤a╣żū„Š═╩ŪīŹ¼F(xi©żn)Map║═Reduce║»öĄ(sh©┤)Ż¼Ųõ╦³Ą─▓󹹊Ä│╠ųąĄ─ĘNĘNÅ═(f©┤)ļså¢Ņ}Ż¼╚ńĘų▓╝╩Į┤µā”Īó╣żū„š{(di©żo)Č╚Īóžō▌dŲĮ║ŌĪó╚▌Õe╠Ä└ĒĪóŠW(w©Żng)Įj(lu©░)═©ą┼Ą╚Ż¼Š∙ė╔MapReduce┐“╝▄žōž¤╠Ä└ĒŻ¼│╠ą“åT═Ļ╚½▓╗ė├▓┘ą─ĪŻ

▒Ē1
2.3Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ
é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņęčĮø(j©®ng)ųØu▒╗Ų¾śI(y©©)æ¬(y©®ng)ė├Ż¼į┌æ¬(y©®ng)ė├Ą─▀^│╠«öųąė÷ĄĮ┴╦║▄ČÓå¢Ņ}Ż╗Č°Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŠ▀éõĄ─Ė▀┐╔ė├ĪóĖ▀öUš╣Ą╚╠ž³cŻ¼ätĮŌøQ┴╦é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ¤oĘ©ĮŌøQĄ─å¢Ņ}ĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ▀@ĘNĖ▀┐╔ė├ĪóĖ▀öUš╣╠žąįīóĢ■ą╬│╔ę╗ĘN╝╝ąg(sh©┤)┌ģä▌ĪŻ
é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņŻ¼▒╚╚ńĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņį┌ĮŌøQå¢Ņ}Ą─Ģrė÷ĄĮ┴╦Ų┐ŅiŻ¼┤¾┴┐įLå¢ė├æ¶į┌įLå¢┴┐ĘĮ├µė÷ĄĮ┴╦ą┬Ą─╠¶æ(zh©żn)Ż╗šµš²╬┤üĒĄ─öĄ(sh©┤)ō■(j©┤)Äņ╩Ūę╗éĆĘų▓╝╩ĮĮŌøQĘĮ░ĖŻ¼╦³ŅÉ╦Ųė┌NoSqlĮŌøQĘĮ░ĖĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĮŌøQĘĮ░ĖŠ▀éõā╔éĆ╠ž³cŻ║Ą┌ę╗Ż¼Š▀ėąÅŚąį┐╔öUš╣ąįŻ╗Ą┌Č■Ż¼å╬³c▓╗┐╔┐┐ĪóĄ½š¹éĆ╝»╚║╩Ū┐╔┐┐ĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩Ū╬┤üĒöĄ(sh©┤)ō■(j©┤)Äņ╗“š▀╗ź┬ō(li©ón)ŠW(w©Żng)æ¬(y©®ng)ė├▒╚▌^ŪÓ▓AĄ─öĄ(sh©┤)ō■(j©┤)ÄņĪŻ
▀@ĘNĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņš²į┌ą╬│╔ę╗ĘN┌ģä▌ĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ║═é„Įy(t©»ng)Ą─ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņėąę╗Č©Ą─ģ^(q©▒)äeŻ¼ā╔š▀╗∙ė┌▓╗═¼Ą─└ĒšōĪŻĄ┌ę╗Ż¼é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)ÄņėąĘŪ│ŻÅŖĄ─╩┬äš(w©┤)─▄┴”Ż¼ę“Ųõę╗ų┬ąįĖ▀Ż¼ī¦ų┬╦³Ą─öUš╣ąįĘŪ│ŻÅ═(f©┤)ļsŻ╗Ą┌Č■Ż¼ī”ė┌╗ź┬ō(li©ón)ŠW(w©Żng)Ų¾śI(y©©)üĒųvŻ¼ŲõĖ³ČÓĻP(gu©Īn)ūóĄ─▓╗╩Ūę╗ų┬ąįŻ¼Ųõų╗ąĶę¬į┌ūŅĮK▀_ĄĮöĄ(sh©┤)ō■(j©┤)ę╗ų┬Š═┐╔ęį┴╦ĪŻ▀@śėŻ¼į┌é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņĮŌøQ▓╗┴╦Ų¾śI(y©©)æ¬(y©®ng)ė├Ą─å¢Ņ}ĢrŻ¼Š═Ģ■│÷¼F(xi©żn)Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĮŌøQĘĮ░ĖĪŻĘų▓╝╩ĮĄ─öĄ(sh©┤)ō■(j©┤)ÄņĮŌøQĘĮ░Ė▓ó▓╗┤·▒Ēé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņĄ─ĮKĮY(ji©”)Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņėąūį╝║Ą─æ¬(y©®ng)ė├ŅI(l©½ng)ė“Ż¼Ą½é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)Äņę▓╚įėąūį╔ĒĄ─ė├╬õų«ĄžĪŻ╬┤üĒŻ¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ║═é„Įy(t©»ng)Ą─ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņæ¬(y©®ng)įō╩Ū╗źŽÓÅøčaĪó╗źŽÓĮY(ji©”)║ŽĄ─ĪŻ
3Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņį┌╔ŽŠW(w©Żng)ėøõø▓ķįāĘĮ├µĄ─ā×(y©Łu)ä▌Ęų╬÷
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╩Ūį┌╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─╗∙ĄA(ch©│)╔Ž░l(f©Ī)š╣üĒĄ─Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)įO(sh©©)ėŗĢr╗∙ė┌ė▓╝■Õeš`╩Ū│ŻæB(t©żi)Ż¼Č°▓╗╩Ū╗∙ė┌«É│ŻĪó║åå╬Ą─ę╗ų┬ąį─Żą═Īó┤¾ęÄ(gu©®)─ŻöĄ(sh©┤)ō■(j©┤)╝»Īó«Éśŗ(g©░u)▄øė▓╝■ŲĮ┼_ķgĄ─┐╔ęŲų▓ąįĪóęŲäėėŗ╦Ń▒╚ęŲäėöĄ(sh©┤)ō■(j©┤)Ė³äØ╦ŃĄ╚įO(sh©©)ėŗ└Ē─ŅŻ¼ę“┤╦Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņÅ─šQ╔·ų«╚šŲŻ¼Š═ĘŪ│Ż▀m║Ž▓ķįāŅÉæ¬(y©®ng)ė├ĪŻ▒╚▌^Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)┼c╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ż¼┐╔ęį░l(f©Ī)¼F(xi©żn)Ęų▓╝╩ŪöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Š▀ėąŽ┬┴ąā×(y©Łu)³cŻ║
Ż©1Ż®Ė³▀m║ŽĘų▓╝╩ĮĄ─╣▄└Ē┼c┐žųŲĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─ĮY(ji©”)śŗ(g©░u)Ė³▀m║ŽŠ▀ėąĄž└ĒĘų▓╝╠žąįĄ─ĮM┐Ś╗“ÖCśŗ(g©░u)╩╣ė├Ż¼į╩įSĘų▓╝į┌▓╗═¼ģ^(q©▒)ė“Īó▓╗═¼╝ēäeĄ─Ė„éĆ▓┐ķTī”Ųõūį╔ĒĄ─öĄ(sh©┤)ō■(j©┤)īŹąąŠų▓┐┐žųŲĪŻ└²╚ńŻ║īŹ¼F(xi©żn)╚½ŠųöĄ(sh©┤)ō■(j©┤)į┌▒ŠĄžõø╚ļĪó▓ķįāĪóŠSūoŻ¼▀@Ģrė╔ė┌ėŗ╦ŃÖC┘Yį┤┐┐Į³ė├æ¶Ż¼┐╔ęįĮĄĄ══©ą┼┤·ārŻ¼╠ßĖ▀Ēææ¬(y©®ng)╦┘Č╚Ż¼Č°╔µ╝░Ųõ╦¹ł÷ĄžöĄ(sh©┤)ō■(j©┤)ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)ų╗╩Ū╔┘┴┐Ą─Ż¼Å─Č°┐╔ęį┤¾┤¾£p╔┘ŠW(w©Żng)Įj(lu©░)╔ŽĄ─ą┼Žóé„▌ö┴┐Ż╗═¼ĢrŻ¼Šų▓┐öĄ(sh©┤)ō■(j©┤)Ą─░▓╚½ąįę▓┐╔ęįū÷Ą├Ė³║├ĪŻ
Ż©2Ż®Š▀ėąņ`╗ŅĄ─¾wŽĄĮY(ji©”)śŗ(g©░u)ĪŻ╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ÅŖš{(di©żo)Ą─╩Ū╝»ųą╩Į┐žųŲŻ¼╬’└ĒöĄ(sh©┤)ō■(j©┤)Äņ╩Ū┤µĘ┼į┌ę╗éĆł÷Ąž╔ŽĄ─Ż¼ė╔ę╗éĆDBMS╝»ųą╣▄└ĒĪŻČÓéĆė├æ¶ų╗┐╔ęį═©▀^Į³│╠╗“▀h│╠ĮKČ╦į┌ČÓė├æ¶▓┘ū„ŽĄĮy(t©»ng)ų¦│ųŽ┬▀\ąąįōDBMSüĒ╣▓ŽĒ╝»ųąöĄ(sh©┤)ō■(j©┤)ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)ĪŻČ°Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─ł÷ĄžŠų▓┐DBMSĄ─ūįų╬ąįŻ¼╩╣Ą├┤¾▓┐ĘųĄ─Šų▓┐╩┬äš(w©┤)╣▄└Ē║═┐žųŲČ╝─▄Š═ĄžĮŌøQŻ¼ų╗ėąį┌╔µ╝░Ųõ╦¹ł÷ĄžĄ─öĄ(sh©┤)ō■(j©┤)Ģr▓┼ąĶę¬═©▀^ŠW(w©Żng)Įj(lu©░)ū„×ķ╚½Šų╩┬äš(w©┤)üĒ╣▄└ĒĪŻĘų▓╝╩ĮDBMS┐╔ęįįO(sh©©)ėŗ│╔Š▀ėą▓╗═¼│╠Č╚Ą─ūįų╬ąįŻ¼Å─Š▀ėą│õĘųĄ─ł÷Ąžūįų╬ĄĮÄū║§╩Ū═Ļ╚½╝»ųą╩ĮĄ─┐žųŲĪŻ
Ż©3Ż®ŽĄĮy(t©»ng)Įø(j©®ng)Ø·Ż¼┐╔┐┐ąįĖ▀Ż¼┐╔ė├ąį║├ĪŻ┼cę╗éĆ┤¾ą═ėŗ╦ŃÖCų¦│ųę╗éĆ┤¾ą═Ą─╝»ųąöĄ(sh©┤)ō■(j©┤)Äņį┘╝ėę╗ą®▀M│╠║═▀h│╠ĮKČ╦ŽÓ▒╚Ż¼ė╔│¼╝ē╬óą═ėŗ╦ŃÖC╗“│¼╝ēąĪą═ėŗ╦ŃÖCų¦│ųĄ─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)═∙═∙Š▀ėąĖ³Ė▀Ą─ąįār▒╚║═īŹ╩®ņ`╗ŅąįĪŻĘų▓╝╩ĮŽĄĮy(t©»ng)▒╚╝»ųą╩ĮŽĄĮy(t©»ng)Š▀ėąĖ³Ė▀Ą─┐╔┐┐ąį║═Ė³║├Ą─┐╔ė├ąįĪŻ╚ńė╔ė┌öĄ(sh©┤)ō■(j©┤)Ęų▓╝į┌ČÓéĆł÷Ąž▓óėąįSČÓÅ═(f©┤)ųŲöĄ(sh©┤)ō■(j©┤)Ż¼į┌éĆäeł÷Ąž╗“éĆäe═©ą┼µ£┬Ę░l(f©Ī)╔·╣╩šŽĢrŻ¼▓╗ų┬ė┌ī¦ų┬š¹éĆŽĄĮy(t©»ng)Ą─▒└ØóŻ¼Č°ŪꎥĮy(t©»ng)Ą─Šų▓┐╣╩šŽ▓╗Ģ■ę²Ų╚½Šų╩¦┐žĪŻ
Ż©4Ż®į┌ę╗Č©Śl╝■Ž┬Ēææ¬(y©®ng)╦┘Č╚╝ė┐ņĪŻ╚ń╣¹┤µ╚ĪĄ─öĄ(sh©┤)ō■(j©┤)į┌▒ŠĄžöĄ(sh©┤)ō■(j©┤)ÄņųąŻ¼─Ū├┤Š═┐╔ęįė╔ė├æ¶╦∙į┌Ą─ėŗ╦ŃÖCüĒł╠(zh©¬)ąąŻ¼╦┘Č╚Š═┐ņĪŻ
Ż©5Ż®┐╔öUš╣ąį║├Ż¼ęūė┌╝»│╔¼F(xi©żn)ėąŽĄĮy(t©»ng)Ż¼ę▓ęūė┌öU│õĪŻ
4ŽĄĮy(t©»ng)š¹¾w╝▄śŗ(g©░u)
š¹éĆŽĄĮy(t©»ng)Ą─╝▄śŗ(g©░u)Ęų×ķ╚²éĆīė┤╬Ż¼╝┤ė╔ĄūīėĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)ĪóMap/Reduceėŗ╦Ń─Żą═║═╔ŽīėĄ─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņśŗ(g©░u)│╔ĪŻŲõųąĄūīėĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Map/Reduceėŗ╦Ń─Żą═▓╔ė├ķ_į┤Ą─HadoopüĒīŹ¼F(xi©żn)Ż¼╔ŽīėĄ─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩ŪHadoopĄ─ķ_į┤ūėĒŚ─┐HBaseŻ¼ūŅ║¾ė╔ZooKeeperüĒīŹ¼F(xi©żn)Ęų▓╝╩Įģf(xi©”)═¼Ę■äš(w©┤)ĪŻš¹éĆŽĄĮy(t©»ng)Ą─š{(di©żo)Č╚ĻP(gu©Īn)ŽĄ╚ńłD2╦∙╩ŠĪŻ
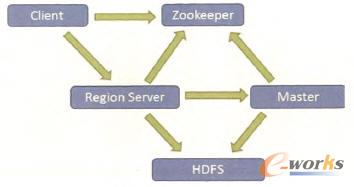
łD2ŽĄĮy(t©»ng)š{(di©żo)Č╚ĻP(gu©Īn)ŽĄ
░┤ššš¹éĆŽĄĮy(t©»ng)Ą─ąĶŪ¾Ż¼īóŽĄĮy(t©»ng)äØĘų×ķ╚²éĆūėŽĄĮy(t©»ng)Ż║öĄ(sh©┤)ō■(j©┤)▓╔╝»ūėŽĄĮy(t©»ng)ĪóĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŲĮ┼_║═öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷║══┌Š“ŽĄĮy(t©»ng)Ż¼╚ńłD3╦∙╩ŠĪŻ

łD3╚²éĆ▓╗═¼Ą─ūėŽĄĮy(t©»ng)
öĄ(sh©┤)ō■(j©┤)▓╔╝»ūėŽĄĮy(t©»ng)ī”ą┼┴ŅĘų╬÷ŽĄĮy(t©»ng)«a(ch©Żn)╔·Ą─ė├æ¶╔ŽŠW(w©Żng)įöå╬öĄ(sh©┤)ō■(j©┤)▀MąąīŹĢrĮŌ╬÷Ż¼╚╗║¾š{(di©żo)ė├Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)┐“╝▄hadoopĄ─Įė┐┌īóöĄ(sh©┤)ō■(j©┤)ī¦╚ļĄĮĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņųąŻ╗Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŲĮ┼_Į©┴óį┌Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)HDFSų«╔ŽŻ¼ė╔HDFSžōž¤╬─╝■Ą─Å═(f©┤)ųŲĪ󹯓×ĪóéõĘ▌Ą╚▓┘ū„Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ų„꬞ōž¤╠ß╣®öĄ(sh©┤)ō■(j©┤)ĘŌčbĮė┐┌Ż¼Ė∙ō■(j©┤)öĄ(sh©┤)ō■(j©┤)╠ž³cĮ©┴óöĄ(sh©┤)ō■(j©┤)─Żą═Ż¼īŹ¼F(xi©żn)keyvalueĄ─öĄ(sh©┤)ō■(j©┤)Äņ▓ķįāŻ╗öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷║══┌Š“ūėŽĄĮy(t©»ng)š{(di©żo)ė├ĄūīėĄ─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņHBaseĮė┐┌Ż¼īŹ¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)▓ķįāĪóĘų╬÷Īóš╣¼F(xi©żn)Ą╚╣”─▄Ż¼═¼ĢrĮoŲõ╦¹ŽĄĮy(t©»ng)╠ß╣®╗∙▒ŠĄ─╣”─▄Įė┐┌ĪŻ
š¹éĆŽĄĮy(t©»ng)Ą─╣”─▄ĮY(ji©”)śŗ(g©░u)├Ķ╩÷╚ńłD4╦∙╩ŠĪŻ
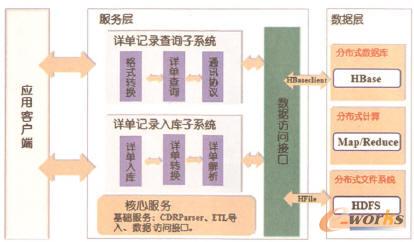
łD4ŽĄĮy(t©»ng)╣”─▄ĮY(ji©”)śŗ(g©░u)
5ĮY(ji©”)šō
▒Š╬─ęį╔ŽŠW(w©Żng)ėøõø▓ķįāŽĄĮy(t©»ng)×ķ└²Ż¼ųž³cöó╩÷┴╦Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņųą╔µ╝░Ą─ĻP(gu©Īn)µI╝╝ąg(sh©┤)║═ęįĘų▓╝╩Į×ķ╗∙ĄA(ch©│)Ą─ė├æ¶╔ŽŠW(w©Żng)ėøõø▓ķįāŽĄĮy(t©»ng)Ą─¾wŽĄ╝▄śŗ(g©░u)ĪŻ╗∙ė┌▄ø╝■Ą═│╔▒ŠĄ─Ęų▓╝╩Į┤µā”║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŻ¼ęčĮø(j©®ng)│╔×ķ╬┤üĒįŲ┤µā”░l(f©Ī)š╣Ą─ę╗ĘN┌ģä▌Ż¼Å─╝╝ąg(sh©┤)▒Š╔ĒĄ─░l(f©Ī)š╣üĒšfŻ¼ļSų°Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─▓╗öÓ░l(f©Ī)š╣Ż¼īóį┌Ė³ČÓĄ─ŅI(l©½ng)ė“Ą├ĄĮÅVĘ║æ¬(y©®ng)ė├ĪŻ▀@ĘN╗∙ė┌▄ø╝■Ą─įŲ┤µā”æ{ĮĶų°Ą═│╔▒ŠĪóęū╣▄└ĒĄ╚ā×(y©Łu)ä▌Ż¼║═¼F(xi©żn)ėąĄ─Ė„ŅÉöĄ(sh©┤)ō■(j©┤)æ¬(y©®ng)ė├ŽÓĮY(ji©”)║ŽŻ¼īŹ¼F(xi©żn)┐ņ╦┘┬õĄžŻ¼Ę■äš(w©┤)ė┌Ų¾śI(y©©)Ż¼Ę■äš(w©┤)ė┌ė├æ¶ĪŻ╬ęéāėą│õĘųĄ─└Ēė╔ŽÓą┼Ż¼▀@ĘNęįĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ×ķ┤·▒ĒĄ─įŲ┤µā”īóĄ├ĄĮĖ³ČÓŲ¾śI(y©©)Ą─ŪÓ▓AĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ęŲäė╗ź┬ō(li©ón)ŠW(w©Żng)╔ŽŠW(w©Żng)ąą×ķėøõøæ¬(y©®ng)ė├įŲėŗ╦Ń╝╝ąg(sh©┤)蹊┐
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.guhuozai8.cn/html/consultation/1083976262.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")















