



ę²╬─Ęų╬÷╩Ūųą╬─╔ńĢ■(hu©¼)┐ŲīW(xu©”)ę²╬─╦„ę²Ż©CSSCIŻ®Ą─ųžę¬ĮM│╔▓┐ĘųĪŻ┼cöĄ(sh©┤)ō■(j©┤)õø╚ļ▀@ĘN╩┬äš(w©┤)ą═╠Ä└ĒŽĄĮy(t©»ng)▓╗═¼Ż¼ę²╬─Ęų╬÷ŽĄĮy(t©»ng)╩Ūę╗éĆ(g©©)Ąõą═Ą─Ęų╬÷ą═╠Ä└ĒŽĄĮy(t©»ng)ĪŻé„Įy(t©»ng)Ą─ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)└Ēšō║═ĘĮĘ©į┌╠Ä└Ē▀@ę╗ŅÉ(l©©i)ą═Ą─æ¬(y©®ng)ė├Ģr(sh©¬)Ż¼’@Ą├▓ó▓╗▀mę╦ĪŻ▒žĒÜ░čĘų╬÷öĄ(sh©┤)ō■(j©┤)Å─õø╚ļŽĄĮy(t©»ng)ųą╠ß╚Ī│÷üĒ(l©ói)Ż¼░┤ššĘų╬÷╠Ä└ĒĄ─ąĶę¬▀M(j©¼n)ąąųžą┬ĮM┐ŚŻ¼Į©┴óå╬¬Ü(d©▓)Ą─Ęų╬÷╠Ä└ĒŁh(hu©ón)Š│ĪŻöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)š²╩Ū×ķ┴╦śŗ(g©░u)Į©▀@ĘNą┬Ą─Ęų╬÷╠Ä└ĒŁh(hu©ón)Š│Č°│÷¼F(xi©żn)Ą─ę╗ĘNöĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)║═ĮM┐Ś╝╝ąg(sh©┤)ĪŻ×ķ┤╦Ż¼ū„š▀į┌▀M(j©¼n)ąąCSSCIĘų╬÷ŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)Ģr(sh©¬)Ż¼ę²╚ļ┴╦öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)║═┬ō(li©ón)ÖC(j©®)Ęų╬÷╠Ä└ĒĄ─Ė┼─Ņ║═╝╝ąg(sh©┤)ĪŻīŹ(sh©¬)█`▒Ē├„Ż¼▀@ę╗ą┬╝╝ąg(sh©┤)æ¬(y©®ng)ė├į┌ę²╬─Ęų╬÷ŽĄĮy(t©»ng)«ö(d©Īng)ųą╩Ū╩«Ęų▀m║Ž║═Ė▀ą¦Ą─ĪŻ
1 ŽĄĮy(t©»ng)¾wŽĄ┐“╝▄
CSSCI═©▀^(gu©░)╚╦╣żś╦(bi©Īo)ę²Īóõø╚ļĄ─ĘĮ╩Į├┐─Ļ▓╔╝»500ėÓĘNųąć°(gu©«)╚╦╬─Īó╔ń┐ŲīW(xu©”)ąg(sh©┤)Ų┌┐»╦∙░l(f©Ī)▒Ēšō╬─Ą─░l(f©Ī)╬─║═ę²╬─ą┼ŽóŻ¼Į©įO(sh©©)ę²╬─╦„ę²öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼╠ß╣®ę²╬─╬─½I(xi©żn)Öz╦„║═Ęų╬÷įu(p©¬ng)ār(ji©ż)Ę■äš(w©┤)ĪŻĖ∙ō■(j©┤)ŽĄĮy(t©»ng)╣”─▄Ż¼┐╔ęįäØĘų╚²éĆ(g©©)ūėŽĄĮy(t©»ng)Ż║öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)Īóę²╬─Öz╦„ŽĄĮy(t©»ng)║═ę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ż©Ž▐ė┌ų„Ņ}Ż¼▒Š╬─▓╗ėæšōę²╬─Öz╦„ŽĄĮy(t©»ng)Ż®ĪŻ
öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)║═ę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ą─śŗ(g©░u)įņ▒žĒÜĘųļxķ_(k©Īi)üĒ(l©ói)Ż¼▓╗─▄╗ņį┌═¼ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│ųąĪŻ▀@╩Ūę“?y©żn)ķŻ║╩ūŽ╚Ż¼ö?sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)║═ę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ą─ąį┘|(zh©¼)║═╠ž³c(di©Żn)ėą║▄┤¾▓╗═¼Ż║öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)╩Ūę╗éĆ(g©©)Ąõą═Ą─╩┬äš(w©┤)ą═╠Ä└ĒŽĄĮy(t©»ng)Ż¼ę¬Ū¾▀M(j©¼n)ąąŅlĘ▒Ą─į÷ähĖ─Ą╚öĄ(sh©┤)ō■(j©┤)┤µ╚Ī▓┘ū„Ż¼├┐┤╬▓┘ū„Ą─öĄ(sh©┤)ō■(j©┤)┴┐ąĪĪó╠Ä└ĒĢr(sh©¬)ķgČ╠Ż¼öĄ(sh©┤)ō■(j©┤)═Ļš¹ąį║═ģóšš═Ļš¹ąį╝s╩°ę¬Ū¾Ė▀Ż¼┐╔ęį░┤ššé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)└Ēšō║═ĘĮĘ©▀M(j©¼n)ąąśŗ(g©░u)įņŻ╗ę²╬─Ęų╬÷ŽĄĮy(t©»ng)┼cöĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)▓╗═¼Ż¼╦³Ą─öĄ(sh©┤)ō■(j©┤)║▄╔┘╗“š▀▓╗Ģ■(hu©¼)Ė³ą┬Ż¼├┐┤╬Öz╦„╔µ╝░ĄĮ┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)įL(f©Żng)å¢(w©©n)Ż¼ī”(du©¼)ė┌Ēææ¬(y©®ng)Ģr(sh©¬)ķgę¬Ū¾▓╗Ė▀ĪŻŲõ┤╬Ż¼įSČÓŠC║ŽČ╚▌^Ė▀Ą─Ęų╬÷¤o(w©▓)Ę©Å─öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)─Ż╩Įųąų▒ĮėĄ├ĄĮŽÓĻP(gu©Īn)Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▒žĒÜ▀M(j©¼n)ąąīŻ(zhu©Īn)ķT(m©”n)Ą─öĄ(sh©┤)ō■(j©┤)│ķ╚ĪŻ¼ėŗ(j©¼)╦Ń│÷┤¾┴┐Ą─ųąķgöĄ(sh©┤)ō■(j©┤)ĪŻ╚ń╣¹ø](m©”i)ėąĮø(j©®ng)▀^(gu©░)ŽĄĮy(t©»ng)Ą─ęÄ(gu©®)äØŻ¼┤¾┴┐ļsüy¤o(w©▓)š┬Ą─│ķ╚ĪöĄ(sh©┤)ō■(j©┤)ä▌(sh©¼)▒žą╬│╔Ī░ų®ųļŠW(w©Żng)Ī▒ą═ĮY(ji©”)śŗ(g©░u)Ż¼įņ│╔öĄ(sh©┤)ō■(j©┤)┐╔ą┼Č╚▓ŅĪóŽĄĮy(t©»ng)ą¦┬╩ĮĄĄ═ęį╝░öĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)ļH¤o(w©▓)Ę©▐D(zhu©Żn)ōQ×ķą┼ŽóĄ╚ĘNĘNå¢(w©©n)Ņ}ĪŻį┘┤╬Ż¼õø╚ļŽĄĮy(t©»ng)║═Ęų╬÷ŽĄĮy(t©»ng)ā╔š▀Ą─ŽĄĮy(t©»ng)ąį─▄ā×(y©Łu)╗»─┐ś╦(bi©Īo)┤µį┌ų°├¼Č▄ĪŻ└²╚ńŻ¼Ęų╬÷ą═╠Ä└Ē╗∙ė┌ąį─▄Ą─┐╝æ]ąĶę¬Į©┴ó┤¾┴┐Ą─╦„ę²Ż¼Č°▀@ī”(du©¼)ė┌õø╚ļŽĄĮy(t©»ng)üĒ(l©ói)šf(shu©Ł)ģsĢ■(hu©¼)ĮĄĄ═ŽĄĮy(t©»ng)Ą─ą¦┬╩ĪŻūŅ║¾Ż¼Ęų╬÷ą═ąĶŪ¾╩Ū¤o(w©▓)Ę©╩┬Ž╚┤_Č©Ą─Ż¼╚ń╣¹ø](m©”i)ėąßśī”(du©¼)ąįĄ─ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐ŚŻ¼ätūŅē─ŪķørŽ┬├┐ę╗ĘNĘų╬÷Č╝▒žĒÜŠÄīæ(xi©¦)īŻ(zhu©Īn)ķT(m©”n)Ą─│╠ą“Ż¼½@╚ĪĘų╬÷öĄ(sh©┤)ō■(j©┤)Ą─╣żū„īóūāĄ├Å═(f©┤)ļs╗»Ż¼▀@╩╣Ą├Ęų╬÷╣żū„īŹ(sh©¬)ļHšŲ╬šį┌│╠ą“åTČ°ĘŪĘų╬÷╚╦åTĄ─╩ųųąĪŻ
öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)└ĒšōĄ─│÷░l(f©Ī)³c(di©Żn)Š═į┌ė┌šJ(r©©n)ūR(sh©¬)ĄĮ┤µį┌ų°ā╔ĘN▓╗═¼Ą─ą┼Žó╠Ä└ĒŽĄĮy(t©»ng)Ż║╩┬äš(w©┤)ą═╠Ä└ĒŽĄĮy(t©»ng)║═Ęų╬÷ą═╠Ä└ĒŽĄĮy(t©»ng)Ż¼ā╔š▀ų«ķg┤µį┌ų°Š▐┤¾Ą─▓Ņ«É╩╣Ą├╩┬äš(w©┤)ą═╠Ä└Ē║═Ęų╬÷ą═╠Ä└ĒĄ─Ęųļx│╔×ķ▒ž╚╗Ż¼Å─Č°╠ß│÷ę╗š¹╠ūĻP(gu©Īn)ė┌Į©įO(sh©©)¾wŽĄ╗»Ą─öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│Ą─└Ēšō║═ĘĮĘ©ĪŻöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─╠ß│÷Ż¼įŁęŌ╩Ūßśī”(du©¼)Ų¾śI(y©©)øQ▓▀ų¦│ųŽĄĮy(t©»ng)Ż©DSSŻ®Ż¼╚╗Č°▀@▓ó▓╗Ę┴ĄK╦³į┌ę²╬─Ęų╬÷ŽĄĮy(t©»ng)Į©įO(sh©©)ųąĄ─æ¬(y©®ng)ė├ĪŻ╩ūŽ╚Ż¼ę²╬─Ęų╬÷╩Ūę╗ĘNĄõą═Ą─Ęų╬÷ą═╠Ä└ĒŻ¼öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ųąĄ─ČÓŠSĘų╬÷─Ż╩Įį┌▀@└’ę▓║▄▀mė├ĪŻŲõ┤╬Ż¼ę²╬─Ęų╬÷╦∙╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)╠ž³c(di©Żn)┼cöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─öĄ(sh©┤)ō■(j©┤)╠ž³c(di©Żn)ę╗ų┬Ż¼Č╝╩ŪÜv╩ĘĘe└█ąįĄ─ĪóŠC║ŽĄ─║═ĘŪĖ³ą┬ąįĄ─ĪŻūŅ║¾Ż¼öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)└ĒšōĄ─ę²╚ļŻ¼╩╣Ą├CSSCIę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ą─┐“╝▄ūāĄ├├„└╩Ż¼Ė³Š▀ėąŽĄĮy(t©»ng)ąįĪŻ«ö(d©Īng)╚╗Ż¼öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)į┌ę²╬─Ęų╬÷ųąĄ─æ¬(y©®ng)ė├┼cę╗░ŃŲ¾śI(y©©)DSSæ¬(y©®ng)ė├ę▓┤µį┌ų°▓╗═¼³c(di©Żn)ĪŻ▒╚╚ńŻ¼ė╔ė┌į┤öĄ(sh©┤)ō■(j©┤)śŗ(g©░u)│╔▒╚▌^å╬ę╗Ż¼ę²╬─Ęų╬÷öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─öĄ(sh©┤)ō■(j©┤)╝»│╔╚╬äš(w©┤)Š═’@Ą├▓╗╩Ū║▄ųžę¬ĪŻ
░┤ššöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)└Ēšōīó╩┬äš(w©┤)ą═Łh(hu©ón)Š│┼cĘų╬÷ą═Łh(hu©ón)Š│Ęųķ_(k©Īi)śŗ(g©░u)įņĄ─╦╝┬ĘŻ¼įO(sh©©)ėŗ(j©¼)CSSCIę²╬─Ęų╬÷ŽĄĮy(t©»ng)¾wŽĄ┐“╝▄╚ńŽ┬Ż║į┌õø╚ļŽĄĮy(t©»ng)║═Ęų╬÷ŽĄĮy(t©»ng)ų«ķgŻ¼═©▀^(gu©░)öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ│╠ą“?q©▒)óį┤ö?sh©┤)ō■(j©┤)╚Ī│÷▓ó▐D(zhu©Żn)ōQ×ķ─┐ś╦(bi©Īo)─Ż╩ĮŻ¼╚╗║¾čb╚ļöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ż╗═©▀^(gu©░)OLAPĘ■äš(w©┤)Å─ČÓŠSöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╬÷╚ĪČÓŠSĘų╬÷öĄ(sh©┤)ō■(j©┤)Ż╗Ęų╬÷╚╦åT╩╣ė├OLAP╣żŠ▀═Ė▀^(gu©░)OLAPĘ■äš(w©┤)įL(f©Żng)å¢(w©©n)ČÓŠSöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▀M(j©¼n)ąąę²╬─Ęų╬÷Ż©ęŖ(ji©żn)łD1Ż®ĪŻ
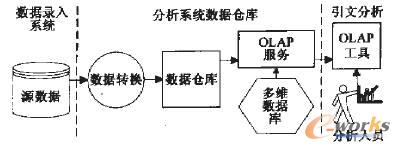
łD1 CSSCIŽĄĮy(t©»ng)¾wŽĄ┐“╝▄
ū„š▀īóį┌Ž┬╬─ųąĘųäeėæšō¾wŽĄųąĄ─Ė„ųžę¬Łh(hu©ón)╣Ø(ji©”)ĪŻ
2 į┤öĄ(sh©┤)ō■(j©┤)Ż║├µŽ“æ¬(y©®ng)ė├Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐Ś
CSSCIŽĄĮy(t©»ng)Ą─į┤öĄ(sh©┤)ō■(j©┤)üĒ(l©ói)į┤▒╚▌^å╬ę╗Ż¼Į^┤¾▓┐ĘųüĒ(l©ói)ūįė┌öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)Ą─╩ų╣żõø╚ļŻ¼ę▓ėąę╗ąĪ▓┐ĘųüĒ(l©ói)ūį═Ō▓┐öĄ(sh©┤)ō■(j©┤)Ż¼╚ńėŗ(j©¼)╦ŃŲ┌┐»ė░Ēæę“ūėĢr(sh©¬)Ż¼ąĶę¬▓╔╝»ĘŪ╩šõø┐»Ą─░l(f©Ī)╬─öĄ(sh©┤)ō■(j©┤)ĪŻöĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)├µ┼RŅlĘ▒Ą─į÷ähĖ─Ą╚öĄ(sh©┤)ō■(j©┤)▓┘ū„Ż¼═¼Ģr(sh©¬)ę¬ØM(m©Żn)ūŃöĄ(sh©┤)ō■(j©┤)═Ļš¹ąį║═╔╠śI(y©©)ęÄ(gu©®)ätĄ╚╝s╩°Śl╝■Ż¼╩Ūę╗éĆ(g©©)Ąõą═Ą─╩┬äš(w©┤)ą═╠Ä└ĒŽĄĮy(t©»ng)ĪŻ╬ęéāīóöĄ(sh©┤)ō■(j©┤)ĮM┐Ś×ķ╬ÕéĆ(g©©)ų„ꬥ─▒ĒŻ║╩šõøŲ┌┐»ĪóŲ┌┐»▌d╬─ĪóüĒ(l©ói)į┤╬─½I(xi©żn)ĪóüĒ(l©ói)į┤ū„š▀║═▒╗ę²╬─½I(xi©żn)ĪŻ╩šõøŲ┌┐»▒ĒėøõøCSSCI╩šõøĄ─500ĘNū¾ėęŲ┌┐»Ą─┤·┤a║═├¹ĘQ(ch©źng)Ż╗Ų┌┐»▌d╬─▒Ēėøõø├┐▒ŠŲ┌┐»Ą─ėøõøĪóś╦(bi©Īo)╩Š╠¢(h©żo)ĪóŲ┌┐»┤·┤aĪóŠĒŲ┌║═▌d╬─┴┐Ą╚ą┼ŽóŻ╗üĒ(l©ói)į┤╬─½I(xi©żn)▒Ēėøõø├┐▒ŠŲ┌┐»╦∙░l(f©Ī)▒Ēšō╬─Ą─ą┼ŽóŻ¼░³└©ėøõøś╦(bi©Īo)╩Š╠¢(h©żo)ĪóŲ¬├¹║═ĻP(gu©Īn)µIį~Ą╚ś╦(bi©Īo)ę²ą┼ŽóŻ╗üĒ(l©ói)į┤ū„š▀▒ĒėøõøüĒ(l©ói)į┤╬─½I(xi©żn)Ą─ū„š▀ą┼ŽóŻ¼░³└©ąš├¹║═ÖC(j©®)śŗ(g©░u)Ą╚Ż╗▒╗ę²╬─½I(xi©żn)▒Ēätėøõø┴╦üĒ(l©ói)į┤╬─½I(xi©żn)╦∙ę²ė├Ą─ģó┐╝╬─½I(xi©żn)Ą─ą┼ŽóŻ©Š▀¾wĮY(ji©”)śŗ(g©░u)šł(q©½ng)ģóęŖ(ji©żn)łD2Ż®ĪŻ▀@╬ÕéĆ(g©©)▒ĒĘųäe┼cīŹ(sh©¬)ļHõø╚ļ╣żū„┴„│╠ųąĄ─├┐ĘNŲ┌┐»Īó├┐▒ŠŲ┌┐»Īóšō╬─Īóū„š▀║═ģó┐╝╬─½I(xi©żn)ę╗ę╗ī”(du©¼)æ¬(y©®ng)Ż¼š¹éĆ(g©©)öĄ(sh©┤)ō■(j©┤)─Ż╩Į╩ŪĖ▀Č╚ęÄ(gu©®)ĘČ╗»Ą─Ż¼╝╚▒Ńė┌öĄ(sh©┤)ō■(j©┤)Ą─į÷ähĖ─▓┘ū„Ż¼ėųėą└¹ė┌š¹éĆ(g©©)╣żū„┴„│╠Ą─╣▄└ĒĪŻ
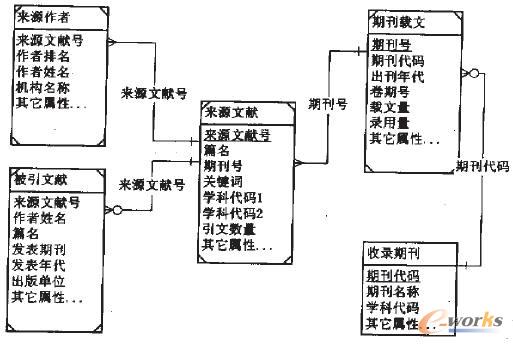
łD2 CSSCIõø╚ļŽĄĮy(t©»ng)öĄ(sh©┤)ō■(j©┤)─Żą═Ą─īŹ(sh©¬)¾w-ĻP(gu©Īn)ŽĄłD
3 ├µŽ“ų„Ņ}Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐Ś
õø╚ļŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)╩Ū├µŽ“æ¬(y©®ng)ė├Ż©Š▀¾wüĒ(l©ói)šf(shu©Ł)Š═╩ŪöĄ(sh©┤)ō■(j©┤)õø╚ļ╣żū„Ż®▀M(j©¼n)ąąĮM┐ŚĄ─Ż¼Ųõ│ķŽ¾│╠Č╚▀Ć▓╗ē“Ė▀ĪŻČ°Ęų╬÷ą═ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)æ¬(y©®ng)įō╩Ū├µŽ“ų„Ņ}▀M(j©¼n)ąąĮM┐ŚĄ─ĪŻ╦∙ų^ų„Ņ}Ż¼Š═╩ŪĘų╬÷ŅI(l©½ng)ė“ųą╦∙╔µ╝░Ą─Ęų╬÷ī”(du©¼)Ž¾Ą─▀ē▌ŗ│ķŽ¾ĪŻ├µŽ“ų„Ņ}Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐ŚŻ¼Ī░Š═╩Ūį┌▌^Ė▀īė┤╬╔Žī”(du©¼)Ęų╬÷ī”(du©¼)Ž¾Ą─öĄ(sh©┤)ō■(j©┤)Ą─ę╗éĆ(g©©)═Ļš¹Īóę╗ų┬Ą─├Ķ╩÷Īó─▄═Ļš¹ĪóĮy(t©»ng)ę╗Ąž┐╠«ŗ(hu©ż)Ė„éĆ(g©©)Ęų╬÷ī”(du©¼)Ž¾╦∙įO(sh©©)ėŗ(j©¼)Ą─Ė„ĒŚ(xi©żng)öĄ(sh©┤)ō■(j©┤)Ż¼ęį╝░öĄ(sh©┤)ō■(j©┤)ų«ķgĄ─┬ō(li©ón)ŽĄĪ▒Ż¼Ė∙ō■(j©┤)▀@ę╗įŁätŻ¼┤_Č©├┐éĆ(g©©)ų„Ņ}╦∙æ¬(y©®ng)░³║¼Ą─öĄ(sh©┤)ō■(j©┤)ā╚(n©©i)╚▌ĪŻų„Ņ}Ą─┤_Č©Ż¼┼cĘų╬÷╚╦åT╦∙ĻP(gu©Īn)ą─Ą─å¢(w©©n)Ņ}├▄ŪąŽÓĻP(gu©Īn)Ż¼Č°Ęų╬÷╚╦åTĄ─┼d╚ż¤o(w©▓)Ę©═Ļ╚½ŅA(y©┤)£y(c©©)Ż¼ų╗─▄═©▀^(gu©░)Ę┤Å═(f©┤)Ą─ų„Ņ}│ķ╚Ī▀^(gu©░)│╠ų▓ĮŪ¾Š½ĪŻ├┐éĆ(g©©)ų„Ņ}ė╔ę╗ĮMĻP(gu©Īn)ŽĄ▒ĒīŹ(sh©¬)¼F(xi©żn)Ż¼╦∙ėą▀@ą®▒Ē═©▀^(gu©░)ę╗éĆ(g©©)╣½╣▓┤aµIĻP(gu©Īn)┬ō(li©ón)ŲüĒ(l©ói)ĪŻ
ę²╬─Ęų╬÷ŅI(l©½ng)ė“Ą─Ęų╬÷ī”(du©¼)Ž¾┤¾ų┬ėąęįŽ┬ÄūĘNŻ║Ų┌┐»Īóšō╬─Īóū„š▀ĪóÖC(j©®)śŗ(g©░u)ĪóĄžģ^(q©▒)Ą╚ĪŻ╦∙ėąĻP(gu©Īn)ė┌Ų┌┐»Ą─ą┼ŽóĮM┐Śį┌ę╗ŲŻ¼ą╬│╔┴╦═ĻéõĄ─ų„Ņ}ė“ĪŻŲõŠ▀ėą¬Ü(d©▓)┴óąį║══ĻéõąįŻ¼╩Ūį┌▌^Ė▀īė┤╬╔Žī”(du©¼)öĄ(sh©┤)ō■(j©┤)Ą─│ķŽ¾Ż¼ę“Č°▀m║Žė┌į┌┤╦öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│╔ŽĘĮ▒ŃĄžķ_(k©Īi)░l(f©Ī)Ęų╬÷ą═æ¬(y©®ng)ė├ĪŻ
4 öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ
öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ╩ŪöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)īŹ(sh©¬)╩®ųąųžę¬Ą─ę╗Łh(hu©ón)Ż¼─┐Ą─╩ŪīóöĄ(sh©┤)ō■(j©┤)Å─▓┘ū„ą═Łh(hu©ón)Š│é„▀fĄĮöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ųąĪŻį┌é„Įy(t©»ng)Ą─DSSæ¬(y©®ng)ė├ųąŻ¼öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ╣żū„ŽÓ«ö(d©Īng)Å═(f©┤)ļsĪŻĄ┌ę╗Ż¼ė╔ė┌öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─Į©įO(sh©©)╩Ūį┌Ų¾śI(y©©)ęčėąĄ─Ė„ŅÉ(l©©i)MISų«╔Ž▀M(j©¼n)ąąŻ¼Č°▀@ą®MIS═∙═∙╩Ū¬Ü(d©▓)┴óķ_(k©Īi)░l(f©Ī)Ą─Ż¼Ė„ŽĄĮy(t©»ng)ų«ķg┤µį┌ų°öĄ(sh©┤)ō■(j©┤)╚▒Ę”╝»│╔Īó▀\(y©┤n)ąąŲĮ┼_(t©ói)▓╗Įy(t©»ng)ę╗Ą╚å¢(w©©n)Ņ}Ż¼╦∙ęįį┌öĄ(sh©┤)ō■(j©┤)Å─▓┘ū„ą═Łh(hu©ón)Š│Ž“öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ųą▐D(zhu©Żn)ęŲĄ─▀^(gu©░)│╠ųąę¬Įø(j©®ng)▀^(gu©░)┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)ŪÕŽ┤Īó▀xō±ĪóģR┐éĪó╝»│╔Īó▐D(zhu©Żn)ōQĄ╚╠Ä└ĒĪŻĄ┌Č■Ż¼Ų¾śI(y©©)øQ▓▀Ęų╬÷Ą─╝░Ģr(sh©¬)ąįę¬Ū¾Ż¼╩╣Ą├öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ╣żū„ŽÓ«ö(d©Īng)ŅlĘ▒Ż¼▐D(zhu©Żn)ōQĄ─ą¦┬╩å¢(w©©n)Ņ}│╔×ķļy³c(di©Żn)ĪŻ
▒Šę²╬─Ęų╬÷ŽĄĮy(t©»ng)┼cŲ¾śI(y©©)DSS▓╗═¼Ż¼╦³Ą─į┤öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│ŽÓī”(du©¼)║å(ji©Żn)å╬Ż¼ų„ę¬╩ŪöĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)║═╔┘┴┐Ą─═Ō▓┐öĄ(sh©┤)ō■(j©┤)ĪŻ▓óŪęė╔ė┌į┌öĄ(sh©┤)ō■(j©┤)õø╚ļŽĄĮy(t©»ng)Ą─ķ_(k©Īi)░l(f©Ī)ųąŠ═┐╝æ]ĄĮ┴╦║¾Ų┌öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Į©įO(sh©©)Ą─ąĶ꬯¼╩╣Ą├öĄ(sh©┤)ō■(j©┤)╝»│╔Ą─╚╬äš(w©┤)┤¾┤¾£p╔┘ĪŻę²╬─Ęų╬÷Ą─╝░Ģr(sh©¬)ąįę¬Ū¾ŽÓī”(du©¼)▓╗Ė▀Ż¼öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQą¦┬╩å¢(w©©n)Ņ}Ą─ųžę¬ąį▓ó▓╗═╗│÷ĪŻ
▒ŠŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQå¢(w©©n)Ņ}ų„ę¬╝»ųąį┌öĄ(sh©┤)ō■(j©┤)Ą─ŪÕŽ┤║═į¬öĄ(sh©┤)ō■(j©┤)Ą─╣▄└ĒĪŻę²╬─öĄ(sh©┤)ō■(j©┤)Ą─Õe(cu©░)š`ų„ę¬╝»ųąį┌Ż║ę╗Īóõø╚ļÕe(cu©░)š`Ż¼Č■Īóį┤┐»Ą─ėĪ╦óÕe(cu©░)š`Ż╗╚²Īóū„š▀įŁ╬─Ą─Õe(cu©░)š`ĪŻĄ┌ę╗ŅÉ(l©©i)Õe(cu©░)š`┐╔═©▀^(gu©░)╚╦╣żąŻī”(du©¼)╣żū„╝ėęį┼┼│²Ż¼║¾ā╔ŅÉ(l©©i)Õe(cu©░)š`ät▒žĒÜį┌┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ęe└█║¾Ż¼▀M(j©¼n)ąąūįäė(d©░ng)║═╚╦╣żĄ─▒╚ī”(du©¼)╝ėęį┼┼│²Ż¼ėąą®┐╔─▄ė└▀h(yu©Żn)¤o(w©▓)Ę©Ą├ĄĮ╝mš²ĪŻį¬öĄ(sh©┤)ō■(j©┤)į┌öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQųąĄ─ū„ė├ĘŪ│Żųžę¬Ż¼╦³├Ķ╩÷┴╦▓┘ū„ą═Łh(hu©ón)Š│ųąĄ─öĄ(sh©┤)ō■(j©┤)ĪóöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ųąĄ─öĄ(sh©┤)ō■(j©┤)ęį╝░öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ▀^(gu©░)│╠ųąĄ─╠Ä└ĒŻ¼╩ŪöĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ╠Ä└ĒĄ─ę└ō■(j©┤)ĪŻ╬ęéā?c©©)┌ö?sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQ│╠ą“Ą─ķ_(k©Īi)░l(f©Ī)ųąŻ¼▓╔ė├┴╦├µŽ“į¬öĄ(sh©┤)ō■(j©┤)Ą─ĘĮ╩ĮŻ¼╩╣│╠ą“Ė³╝ėņ`╗Ņ║═ęūė┌╣▄└ĒĪŻ
5 OLAPĘ■äš(w©┤)┼c╣żŠ▀
┬ō(li©ón)ÖC(j©®)Ęų╬÷╠Ä└ĒŻ©OLAPŻ®╩Ūę╗ķT(m©”n)┼cöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)├▄ŪąŽÓĻP(gu©Īn)Ą─ą┬┼dĄ─▄ø╝■╝╝ąg(sh©┤)Ż¼╦³īŻ(zhu©Īn)ķT(m©”n)įO(sh©©)ėŗ(j©¼)ė├ė┌ų¦│ųÅ═(f©┤)ļsĄ─Ęų╬÷▓┘ū„ĪŻ╦³Ą─ČÓŠSöĄ(sh©┤)ō■(j©┤)Ęų╬÷─Ż╩ĮĪ░╩Ūßśī”(du©¼)╠žČ©å¢(w©©n)Ņ}Ą─┬ō(li©ón)ÖC(j©®)öĄ(sh©┤)ō■(j©┤)įL(f©Żng)å¢(w©©n)║═Ęų╬÷Ż¼═©▀^(gu©░)ī”(du©¼)ą┼ŽóŻ©▀@ą®ą┼ŽóęčĮø(j©®ng)Å─įŁ╩╝Ą─öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą┴╦▐D(zhu©Żn)ōQŻ¼ęįĘ┤ė│ė├æ¶(h©┤)╦∙─▄└ĒĮŌĄ─Ų¾śI(y©©)Ą─šµīŹ(sh©¬)Ą─Ī«ŠSĪ»Ż®Ą─║▄ČÓĘN┐╔─▄Ą─ė^(gu©Īn)▓ņą╬╩Į▀M(j©¼n)ąą┐ņ╦┘ĪóĘĆ(w©¦n)Č©ę╗ų┬║═Į╗╗źąįĄ─┤µ╚ĪĪ▒Ż¼į╩įSĘų╬÷╚╦åTī”(du©¼)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą╔Ņ╚ļĄ─ė^(gu©Īn)▓ņĪŻČÓŠSöĄ(sh©┤)ō■(j©┤)Ęų╬÷─Ż╩Į░čöĄ(sh©┤)ō■(j©┤)Ęų╬÷╣żū„┐┤ū„╩Ūī”(du©¼)ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wĄ─ą²▐D(zhu©Żn)ĪóŪąŲ¼ĪóŪąēKĄ╚ę╗ŽĄ┴ą▓┘ū„▀^(gu©░)│╠ĪŻöĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wė╔ūā┴┐║═ŠSĮM│╔ĪŻūā┴┐╩ŪöĄ(sh©┤)ō■(j©┤)Ą─īŹ(sh©¬)ļHęŌ┴xŻ¼ę▓Š═╩Ū╚╦éā╦∙ĻP(gu©Īn)ą─Ą─öĄ(sh©┤)ųĄČ╚┴┐ųĖś╦(bi©Īo)Ż╗ŠS╩Ū╚╦éāė^(gu©Īn)▓ņöĄ(sh©┤)ō■(j©┤)Ą──│éĆ(g©©)╠žČ©ĮŪČ╚ĪŻČÓéĆ(g©©)ŠS┼cūā┴┐ĮM│╔ę╗éĆ(g©©)ČÓŠSĄ─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)Ż¼Š═╩ŪöĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wŻ¼Č°┴óĘĮ¾wĄ─įO(sh©©)ėŗ(j©¼)ät│╔×ķČÓŠSöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ĻP(gu©Īn)µIå¢(w©©n)Ņ}ĪŻOLAP╝╝ąg(sh©┤)Ą─ąį┘|(zh©¼)║═╠ž³c(di©Żn)╩╣Ą├╦³┐╔ęį│╔×ķę²╬─Ęų╬÷Ą─ėą┴”╣żŠ▀ĪŻį┌▒ŠŽĄĮy(t©»ng)ųąę²╚ļOLAP╝╝ąg(sh©┤)║═╣żŠ▀║¾Ż¼£p╔┘┴╦Ęų╬÷│╠ą“Ą─öĄ(sh©┤)┴┐Ż¼Įy(t©»ng)ę╗┴╦æ¬(y©®ng)ė├▀ē▌ŗŻ¼Ė─╔Ų┴╦ė├æ¶(h©┤)Įń├µĪŻ
OLAP«a(ch©Żn)ŲĘ╩ŪĮ©┴óį┌┐═æ¶(h©┤)Ż»Ę■äš(w©┤)Ų„¾wŽĄĮY(ji©”)śŗ(g©░u)╔ŽĄ─ĪŻOLAPĘ■äš(w©┤)Ų„═Ļ│╔öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)öĄ(sh©┤)ō■(j©┤)ĄĮČÓŠSöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─▐D(zhu©Żn)ōQĪóČÓŠSöĄ(sh©┤)ō■(j©┤)Ą─┤µ┘A║═öĄ(sh©┤)ō■(j©┤)ėŗ(j©¼)╦Ńę²ŪµĄ╚╣”─▄ĪŻOLAP╣żŠ▀ätŠ▀ėąČÓŠSöĄ(sh©┤)ō■(j©┤)┤µ╚Ī║═ČÓŠSęĢłD▒Ē¼F(xi©żn)Ą──▄┴”ĪŻĘų╬÷╚╦åT═©▀^(gu©░)OLAP╣żŠ▀┼cOLAPĘ■äš(w©┤)Ų„▀M(j©¼n)ąąĮ╗╗źŻ¼▀M(j©¼n)ąąČÓŠSöĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪŻį┌#$%&Ę■äš(w©┤)Ų„Č╦Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐ŚĘĮĘ©ėąā╔ĘNĘĮ╩ĮŻ║ę╗ĘN╩ŪĮ©┴óīŻ(zhu©Īn)ė├Ą─ČÓŠSöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)Ż©MOLAPŻ®Ż╗┴Ēę╗ĘN╩Ū╚į╚╗└¹ė├¼F(xi©żn)ėąĄ─ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝╝ąg(sh©┤)üĒ(l©ói)─ŻöMČÓŠSöĄ(sh©┤)ō■(j©┤)Ż©ROLAPŻ®ĪŻMOLAP╩╣ė├Č■ŠSŠžĻćĄ─ą╬╩ĮĮM┐ŚöĄ(sh©┤)ō■(j©┤)Ż¼Č°OLAP╩╣ė├ąŪą═─Ż╩ĮŻ©Star SchemaŻ®╗“č®╗©─Ż╩ĮŻ©SnowFlake SchemaŻ®üĒ(l©ói)ĮM┐ŚöĄ(sh©┤)ō■(j©┤)ĪŻąŪą═─Ż╩ĮīóČÓŠSöĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)äØĘų×ķā╔ŅÉ(l©©i)▒ĒŻ¼ę╗ŅÉ(l©©i)╩Ū╩┬īŹ(sh©¬)▒ĒŻ¼ė├üĒ(l©ói)┤µā”(ch©│)╩┬īŹ(sh©¬)Ą─Č╚┴┐ųĄęį╝░Ė„éĆ(g©©)ŠSĄ─┤aųĄŻ╗┴Ēę╗ŅÉ(l©©i)╩ŪŠS▒ĒŻ¼ī”(du©¼)├┐ę╗éĆ(g©©)ŠSüĒ(l©ói)šf(shu©Ł)Ż¼ų┴╔┘ėąę╗éĆ(g©©)▒Ēė├üĒ(l©ói)▒Ż┤µįōŠSĄ─į¬öĄ(sh©┤)ō■(j©┤)Ż¼╝┤ŠSĄ─├Ķ╩÷ą┼ŽóŻ¼░³└©ŠSĄ─īė┤╬╝░│╔åTŅÉ(l©©i)äeĄ╚ĪŻ╩┬īŹ(sh©¬)▒Ē═©▀^(gu©░)├┐ę╗éĆ(g©©)ŠSĄ─ųĄ║═ŠS▒Ē┬ō(li©ón)ŽĄį┌ę╗ŲŻ¼śŗ(g©░u)│╔ąŪą═─Ż╩ĮĪŻłD3╦∙╩ŠĄ─╩Ū▒ŠŽĄĮy(t©»ng)ųąÖC(j©®)śŗ(g©░u)░l(f©Ī)╬─žĢ½I(xi©żn)öĄ(sh©┤)ō■(j©┤)┴óĘĮ¾w╦∙ī”(du©¼)æ¬(y©®ng)Ą─ąŪą═┤µā”(ch©│)─Ż╩ĮĪŻ
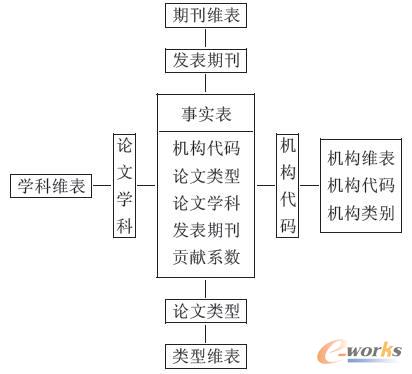
łD3 ░l(f©Ī)╬─žĢ½I(xi©żn)ąŪą═─Ż╩Į
¼F(xi©żn)į┌╩ął÷(ch©Żng)ųąėąįSČÓOLAPĘ■äš(w©┤)║═╣żŠ▀▄ø╝■Ż¼INFORMIXĪóOracleĪóSvbaseĪóMicrosoftęį╝░IBMĄ╚öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╣▄└ĒŽĄĮy(t©»ng)╣®æ¬(y©®ng)╔╠Č╝ėąūį╝║Ą─OLAPĮŌøQĘĮ░ĖĪŻ«a(ch©Żn)ŲĘĄ─▀xō±ų„ę¬æ¬(y©®ng)įō┐╝æ]ąį─▄ār(ji©ż)Ė±▒╚ĪóČ■┤╬ķ_(k©Īi)░l(f©Ī)─▄┴”ęį╝░┼c¼F(xi©żn)ėąŽĄĮy(t©»ng)Ą─┼õ║ŽČ╚ĪŻė╔ė┌▒ŠŽĄĮy(t©»ng)╩╣ė├┴╦SQL Serverū„×ķöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╣▄└ĒŽĄĮy(t©»ng)Ż¼╗∙ė┌ęūė├ąį║═Įø(j©®ng)Ø·(j©¼)ąįĄ─┐╝æ]Ż¼╬ęéā▓╔ė├┴╦╬ó▄ø╣½╦ŠĄ─SQL Server 7.0 OLAPĮŌøQĘĮ░ĖĪŻ╦³ų„ę¬░³└©ęįŽ┬ĮM│╔▓┐ĘųŻ║OLAPĘ■äš(w©┤)Ų„ĪóöĄ(sh©┤)ō■(j©┤)═ĖęĢ▒ĒĘ■äš(w©┤)ĪóöĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQĘ■äš(w©┤)ĪóČÓŠSöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪóExcei 2000Ą╚ĪŻ╦³Ą─ę╗┤¾ā×(y©Łu)³c(di©Żn)Š═╩Ū┼c▓┘ū„ŽĄĮy(t©»ng)ęį╝░Ųõ╦¹Ą─╣żŠ▀ĮY(ji©”)║Ž▌^║├Ż¼║▄ČÓ▓┐╝■ų▒Įė╝»│╔į┌WindowsŽĄĮy(t©»ng)ųąŻ¼╣Ø(ji©”)╩Ī┴╦ė├æ¶(h©┤)Ą─═Č┘YĪŻ═¼Ģr(sh©¬)▀Ć╠ß╣®┴╦ČÓŠSöU(ku©░)š╣Ż©MDXŻ®šZ(y©│)čįū„×ķSQLšZ(y©│)čįĄ─öU(ku©░)š╣Ż¼ė├ė┌Ęų╬÷╣żŠ▀Ą─Č■┤╬ķ_(k©Īi)░l(f©Ī)ĪŻ
6 ę²╬─┬ō(li©ón)ÖC(j©®)Ęų╬÷īŹ(sh©¬)└²
×ķ┴╦Š▀¾wšf(shu©Ł)├„▒Šę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ą─īŹ(sh©¬)╩®║═ą¦╣¹Ż¼¼F(xi©żn)ęį1998─ĻČ╚CSSCIŽĄĮy(t©»ng)öĄ(sh©┤)ō■(j©┤)×ķ╗∙ĄA(ch©│)Ż¼ĮķĮB▒ŠŽĄĮy(t©»ng)ųąOLAPĄ─æ¬(y©®ng)ė├Ż©╬─ųąĄ─öĄ(sh©┤)ō■(j©┤)▒ĒŠ∙üĒ(l©ói)ūįė┌ŽĄĮy(t©»ng)ūįäė(d©░ng)╔·│╔Ą─Excel▒ĒĖ±Ż®ĪŻęįĘų╬÷ÖC(j©®)śŗ(g©░u)ī”(du©¼)░l(f©Ī)▒Ēšō╬─Ą─žĢ½I(xi©żn)ŽĄöĄ(sh©┤)×ķ└²Ż║ę╗Ų¬šō╬─┐╔─▄ėąČÓéĆ(g©©)ū„š▀Ż¼├┐éĆ(g©©)ū„š▀Ą─╦∙į┌ÖC(j©®)śŗ(g©░u)ė╔ė┌ū„š▀┼┼├¹▓╗═¼ī”(du©¼)▀@Ų¬šō╬─ū÷│÷┴╦┤¾ąĪ▓╗ę╗Ą─žĢ½I(xi©żn)ĪŻ░┤šššō╬─ųąū„š▀┼┼├¹Ēśą“Ż¼ĮoÖC(j©®)śŗ(g©░u)┘xėĶę╗Č©Ą─žĢ½I(xi©żn)ŽĄöĄ(sh©┤)Ż¼▀@éĆ(g©©)ŽĄöĄ(sh©┤)Š═Ę┤ė│┴╦┤╦ÖC(j©®)śŗ(g©░u)ī”(du©¼)įōšō╬─Ą─žĢ½I(xi©żn)│╠Č╚ĪŻ░čžĢ½I(xi©żn)ŽĄöĄ(sh©┤)«ö(d©Īng)ū„ūā┴┐Ż¼ÖC(j©®)śŗ(g©░u)ĪóÖC(j©®)śŗ(g©░u)ŅÉ(l©©i)äeĪóšō╬─īW(xu©”)┐ŲĪóšō╬─ŅÉ(l©©i)ą═║═░l(f©Ī)▒ĒŲ┌┐»«ö(d©Īng)ū„ŠSŻ¼Š═śŗ(g©░u)│╔┴╦ę╗éĆ(g©©)Ęų╬÷ÖC(j©®)śŗ(g©░u)░l(f©Ī)╬─žĢ½I(xi©żn)Ą─öĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wĪŻ═©▀^(gu©░)ī”(du©¼)▀@éĆ(g©©)┴óĘĮ¾wĄ─ą²▐D(zhu©Żn)ĪóŪąŲ¼ĪóŪąēKĄ╚▓┘ū„Ż¼╬ęéā┐╔ęįĄ├ĄĮĖ„ĘNėąęŌ┴xĄ─Ęų╬÷öĄ(sh©┤)ō■(j©┤)ĪŻ
7 ĮY(ji©”) šZ(y©│)
ųą╬─╔ńĢ■(hu©¼)┐ŲīW(xu©”)ę²╬─╦„ę²ŽĄĮy(t©»ng)Ą─Į©įO(sh©©)Ż¼Ųõ║╦ą─Š═╩Ūę²╬─öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─Į©įO(sh©©)ĪŻį┌ę²╬─Ęų╬÷ŽĄĮy(t©»ng)Ą─įO(sh©©)ėŗ(j©¼)║═īŹ(sh©¬)╩®▀^(gu©░)│╠ųąŻ¼╬ęéāĮĶĶb┴╦öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)║═┬ō(li©ón)ÖC(j©®)Ęų╬÷╠Ä└ĒĄ─└Ēšō║═╝╝ąg(sh©┤)Ż¼╚ĪĄ├┴╦║▄║├Ą─ą¦╣¹ĪŻę╗ĘĮ├µŻ¼öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ĻP(gu©Īn)ė┌śŗ(g©░u)Į©¾wŽĄ╗»öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│Ą─└Ēšōī”(du©¼)ė┌CSSCIŽĄĮy(t©»ng)Üv╩ĘĘe└█öĄ(sh©┤)ō■(j©┤)Ą─ėąą¦ĮM┐Ś┤µā”(ch©│)╠ß╣®┴╦ųĖī¦(d©Żo)Ż¼┴Ēę╗ĘĮ├µŻ¼ČÓŠSöĄ(sh©┤)ō■(j©┤)Ęų╬÷─Żą═╝╝ąg(sh©┤)£p▌p┴╦ķ_(k©Īi)░l(f©Ī)╚╦åTĄ─ŠÄ│╠╣żū„┴┐Ż¼═¼Ģr(sh©¬)ę▓╩╣Ą├╚╦ÖC(j©®)Įń├µĖ³╝ėėč║├Ż¼─▄ē“ØM(m©Żn)ūŃ▓╗═¼ė├æ¶(h©┤)Ą─Ė„ĘNĘų╬÷ąĶŪ¾ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ć(l©żi)ŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://www.guhuozai8.cn/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╗∙ė┌öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą─ę²╬─Ęų╬÷ŽĄĮy(t©»ng)蹊┐
▒Š╬─ŠW(w©Żng)ųĘŻ║http://www.guhuozai8.cn/html/consultation/1082055250.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å(g©░u)┘I(m©Żi)")
æ(zh©żn)┬į║Žū„")















