ę╗Īó ▒│Š░ĮķĮB
śI䚎ĄĮyį┌ķLŲ┌▀\ąąĄ─▀^│╠ųąĢ■Ęe└█┤¾┴┐Ą─öĄō■Ż¼▀@ą®öĄō■ėąą®╩ŪąĶę¬ķLŲ┌▒Ż┤µĄ─Ż¼└²╚ńę╗ą®ėåå╬öĄō■Ż¼ėąą®ų╗ąĶę¬Č╠Ų┌▒Ż┤µŻ¼└²╚ńę╗ą®╚šųŠą┼ŽóĪŻśIäšöĄō■ę╗░ŃČ╝Ģ■ėąę╗éĆ╔·├³ų▄Ų┌Ż¼╔·├³ų▄Ų┌ā╚Ą─╬ęéāĮą╔·«aöĄō■Ż¼╔·├³ų▄Ų┌ų«═ŌŻ©╝┤śIäšęčĮøĻPķ]Ż®Ą─ĮąÜv╩ĘöĄō■Ż¼╬ęéā▀@└’╠ߥĮĄ─öĄō■ĮY▐DŻ¼ųĖĄ─╩ŪīóąĶę¬ķLŲ┌▒Ż┤µĄ─Üv╩ĘöĄō■Å─╔·«aÄņ▀węŲĄĮÜv╩ĘÄņŻ©▐DŻ®Ż¼Č°īóąĶę¬Č╠Ų┌▒Ż┤µĄ─öĄō■Č©Ų┌äh│²Ż©ĮYŻ®ĪŻ
╬ęéāęčĮø▀M╚ļ┴╦┤¾öĄō■Ģr┤·Ż¼Ą½į┌OLTPŅÉŽĄĮyųąŻ¼ĻPŽĄą═öĄō■Äņę└╚╗š╝ō■ų„ī¦Ąž╬╗Ż¼į┌ĻPŽĄą═öĄō■ÄņųąŻ¼╚ń╣¹▓╗╝░Ģr▀MąąöĄō■ĮY▐DŻ¼Ģ■ć└ųžė░ĒæŽĄĮyĄ─ąį─▄ĪŻ
ĻPŽĄą═öĄō■Äņå╬ÖC╚▌┴┐ėąŽ▐Ż¼ę“┤╦śIĮńŲš▒ķĄ─ū÷Ę©╩Ū▀Mąą┤╣ų▒ĘųÄņ║═╦«ŲĮĘųŲ¼Ż¼ę╗ą®┤¾ą═╗ź┬ōŠWŲ¾śIė╔ė┌śIäš┴┐²ŗ┤¾Ż¼āHĘųŲ¼Ą─╝»╚║ęÄ─ŻŠ═─▄▀_ĄĮ╔ŽŪ¦╣سcŻ¼į┘╝ė╔ŽĘųÄņĄ─╝»╚║Ż¼ęÄ─ŻĘŪ│ŻŠ▐┤¾ĪŻé„ĮyĄ─öĄō■ÜwÖnĘĮĘ©═∙═∙ßśī”å╬Äņ▓┘ū„Ż¼ļyęį╠Ä└Ē╚ń┤╦┤¾ęÄ─Ż╝»╚║Ą─öĄō■ÜwÖnĪŻ
═¼ĢrŻ¼į┌┤¾ą═╗ź┬ōŠWŲ¾śIŻ¼├┐╚šĄ─öĄō■į÷ķL┴┐ĘŪ│Ż┤¾Ż¼öĄō■ĮY▐DĄ─Ņl┬╩▀h┤¾ė┌é„ĮyąąśIŻ¼▀@ą®ąąśIĄ─ITŽĄĮy═∙═∙╩Ū7*24ąĪĢr▓╗ķgöÓ╠ß╣®Ę■䚯¼Č°Ūę╚½╠ņ24ąĪĢrĄ─▓ó░l┴┐Č╝║▄┤¾Ż¼ę“┤╦öĄō■ĮY▐D▓┘ū„▒žĒÜ▒M┴┐£p╔┘ī”╔·«aÄņĄ─ąį─▄ė░ĒæĪŻ
×ķ┤╦Ż¼╬ęéāūįų„čą░l┴╦öĄō■ĮY▐DŲĮ┼_Ż¼ęįĮŌøQ┤¾öĄō■▒│Š░Ž┬Ą─öĄō■ĮY▐Då¢Ņ}ĪŻ
Č■Īó ╝╝ąg╝▄śŗ
2.1 įOėŗę¬³c
Ż©1Ż®▒M┴┐£p╔┘ī”╔·«aÄņĄ─ė░Ēæ
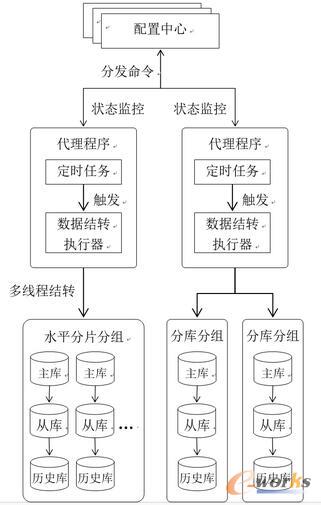
öĄō■ĮY▐D▓┘ū„ø]ėąÅ═ļsĄ─śIäš▀ē▌ŗŻ¼ę“┤╦ī”öĄō■Äņąį─▄Ą─ė░Ēæų„ę¬¾w¼Fį┌IOĘĮ├µŻ¼£p╔┘ī”╔·«aÄņĄ─ė░ĒæŻ¼ūŅų„ꬥ─Š═╩Ū£p╔┘ī”╔·«aÄņĄ─IO▓┘ū„ĪŻ─┐Ū░╬ęéā▓╔ė├Ą─ĘĮ░Ė╩Ū═©▀^Å─Äņ▓ķįāöĄō■Ż¼īóöĄō■▓Õ╚ļÜv╩ĘÄņŻ¼╚╗║¾į┘Å─ų„Äņųąäh│²Ż¼╚ńłD1öĄō■ĮY▐D▀ē▌ŗłD╦∙╩ŠŻ¼īó▓ķįāĄ─IO▓┘ū„▐D╝▐ĄĮÅ─Äņ╔ŽŻ¼┐╔ęį┤¾┤¾£p▌pī”ų„ÄņĄ─ė░ĒæĪŻ×ķ┴╦▒ŻšŽöĄō■ÄņĄ─Ė▀┐╔ė├Ż¼śIā╚╗∙▒ŠČ╝▓╔ė├┴╦ų„Å─▓┐╩─Ż╩ĮŻ¼ę“┤╦▀@éĆĘĮ░ĖŠ▀ėą║▄Ė▀Ą─═©ė├ąįĪŻ
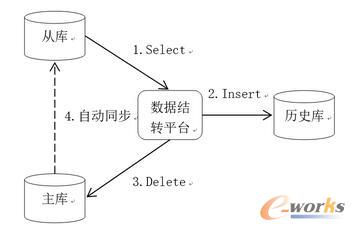
łD1 öĄō■ĮY▐D▀ē▌ŗłD
Ż©2Ż®ų¦│ųĘųÄņĘųŲ¼╝»╚║
╬ęéāŽŻ═¹öĄō■ĮY▐DŲĮ┼_Ą─┼õų├ūŃē“║åå╬▓óŪęęūė┌└ĒĮŌĪŻį┌║═ė├æ¶Ą─£Ž═©▀^│╠ųąŻ¼╬ęéā░l¼F╦¹éāūŅÅŖ┴ęĄ─ąĶŪ¾Š═╩ŪĘųÄņĘųŲ¼╝»╚║Ą─öĄō■ĮY▐DĪŻé„ĮyĄ─å╬ÖCöĄō■ĮY▐D▓┘ū„┐╔ęį│ķŽ¾├Ķ╩÷×ķŻ║īóöĄō■ÄņīŹ└²Aųą▒ĒBĄ─Üv╩ĘöĄō■ĮY▐DĄĮÜv╩ĘÄņCŻ¼ė├æ¶Ą─┼õų├ų„ę¬ėą4éĆį¬╦žŻ║╔·«aÄņīŹ└²AĪóĮY▐D▒ĒBĪóĮY▐DŚl╝■║═Üv╩ĘÄņĪŻī”ė┌┤¾ęÄ─ŻĄ─ĘųÄņĘųŲ¼╝»╚║ęÄ─ŻŻ¼╚ń╣¹▓╔ė├é„Įyå╬ÖCöĄō■ĮY▐DĄ─┼õų├ĘĮ╩ĮŻ¼├┐ę╗éĆöĄō■ÄņīŹ└²Č╝ę¬┼õų├4éĆį¬╦žŻ¼┼õų├┴┐ĘŪ│Ż┤¾ĪŻ
į┌╬ęéāĄ─ĘĮ░ĖųąŻ¼░┤ššłD2╦∙╩Šī”öĄō■Äņ╝»╚║▀MąąäØĘųŻ¼īóų„ÄņĪóÅ─ÄņĪóÜv╩ĘÄņū„×ķę╗éĆĮY▐Då╬į¬Ż¼ī”ė┌ĘųŲ¼Ą─öĄō■Äņ╝»╚║Ż¼▒ĒĮYśŗŽÓ═¼Ż¼╬ęéāīóŲõū„×ķę╗éĆĘųĮMŻ¼ī”ė┌ĘųÄņĄ─╝»╚║Ż¼▒ĒĮYśŗ▓╗═¼ätäØĘų×ķ▓╗═¼Ą─ĘųĮMĪŻė├æ¶▀Mąą┼õų├Ą─Ģr║“▓╗╩Ū├µŽ“ę╗éĆöĄō■ÄņīŹ└²Ż¼Č°╩Ū├µŽ“ę╗éĆĘųĮMŻ¼öĄō■ĮY▐D▓┘ū„│ķŽ¾×ķŻ║ĮY▐DĘųĮMXųą▒ĒBĄ─Üv╩ĘöĄō■Ż¼ė├æ¶Ą─┼õų├į¬╦žėą3éĆŻ║ĘųĮMXĪóĮY▐D▒ĒB║═ĮY▐DŚl╝■ĪŻĘųĮMą┼ŽóāHąĶ┼õų├ę╗┤╬ĪŻ▀@śė┤¾┤¾║å╗»┴╦ė├æ¶Ą─┼õų├╣żū„ĪŻ
Ż©3Ż®ų¦│ų╦«ŲĮöUš╣
ė╔ė┌öĄō■Äņ╝»╚║ęÄ─Ż▌^┤¾Ż¼öĄō■ĮY▐DŲĮ┼_æ¬įōŠ▀éõ╦«ŲĮöUš╣─▄┴”ĪŻ╬ęéā▓╔ė├Ą─ĘĮ░Ė╩ŪīóöĄō■ĮY▐DūŅ║╦ą─Ą─ĮM╝■Č©Ģr╚╬äš║═öĄō■Äņ▓┘ū„Ż©öĄō■ĮY▐Dł╠ąąŲ„Ż®¬Ü┴ó│÷üĒŻ¼▀MąąĘų▓╝╩Į▓┐╩ĪŻ╚ńŽ┬łD3╦∙╩ŠŻ¼
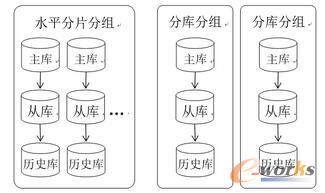
łD2 öĄō■Äņ╝»╚║─Żą═
┼õų├ųąą─×ķė├æ¶Ą─╚ļ┐┌Ż¼ė├æ¶═©▀^┼õų├ųąą─Č©┴xöĄō■ĮY▐D╚╬䚯¼╚╬䚥─ĻPµIī┘ąį░³└©Ż║ė|░lŚl╝■Īół╠ąąŚl╝■Īó─┐ś╦ĘųĮMĄ╚Ż¼┼õų├ųąą─īóĮY▐D╚╬äšĘų░lĮo┤·└Ē│╠ą“Ż¼═¼Ģrī”┤·└Ē│╠ą“Ą─ł╠ąąĀŅæB▀Mąą▒O┐žĪŻĮY▐D╚╬䚥─ė|░lŚl╝■┼õų├į┌┤·└Ē│╠ą“ųąĄ─Č©Ģr╚╬äšųąŻ¼Č°ł╠ąąŚl╝■║═─┐ś╦ĘųĮMätū„×ķöĄō■ĮY▐Dł╠ąąŲ„Ą─ł╠ąąģóöĄĪŻ═©▀^╦«ŲĮöUš╣┤·└Ē│╠ą“Ż¼╬ęéāī”Ė³ČÓĄ─öĄō■Äņ▀MąąĮY▐DĪŻ
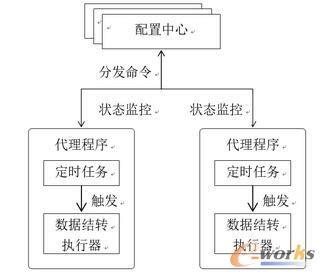
łD3 öĄō■ĮY▐DĮM╝■ĻPŽĄłD
2.2 ┐é¾w╝▄śŗ
ŠC║Ž╔Ž├µ╠ߥĮĄ─3éĆįOėŗę¬³cŻ¼╬ęéāĄ├ĄĮłD4╦∙╩ŠĄ─┐é¾w╝▄śŗŻ¼ąĶę¬╠žäešf├„Ą─╩ŪŻ¼ī”ė┌╦«ŲĮĘųŲ¼Ą─ĘųĮMŻ¼╬ęéā▓╔ė├Ą─╩ŪČÓŠĆ│╠ĮY▐DŻ¼ī”ė┌▓╗═¼ĮY▐Då╬į¬▓╗┤µį┌öĄō■╣▓ŽĒå¢Ņ}Ż¼╦∙ęį¤oąĶ┐╝æ]▓ó░lµiĄ╚å¢Ņ}ĪŻ
╚²Īó ę╗ą®Įø“×┐éĮY
a) ┼õų├ųąą─┼c┤·└Ē│╠ą“ų«ķgĄ─ą┼Žó═¼▓Į
łD4 öĄō■ĮY▐D┐é¾w╝▄śŗłD
┼õų├ųąą─║═┤·└Ē│╠ą“į┌╬ęéāĄ─ĘĮ░Ėųą▒╗įOėŗ×ķę╗ĘN╦╔±Ņ║ŽĮYśŗŻ║į┌ŽĄĮyĄ─▀\ąą▀^│╠ųąŻ¼┤·└Ē│╠ą“Õ┤ÖC▓╗Ģ■ė░Ēæ┼õų├ųąą─Ą─▀\ąąŻ¼═¼śė┼õų├ųąą─Č╠Ģ║Ą─▓╗┐╔ė├ę▓▓╗Ģ■ė░Ēæ┤·└Ē│╠ą“Ą─▀\ąąĪŻ╦╔±Ņ║ŽĮYśŗ┐╔ęį┤¾┤¾į÷ÅŖŽĄĮyĄ─┐╔ė├ąįŻ¼Č°Ūę┼õų├ųąą─Īó┤·└Ē│╠ą“╔²╝ēĄ─Ģr║“▓╗Ģ■ė░Ēæš¹éĆŽĄĮyĄ─š²│Ż▀\ąąĪŻ
×ķ┴╦īŹ¼F╦╔±Ņ║ŽĄ─ĮYśŗŻ¼┼õų├ųąą─┼c┤·└Ē│╠ą“ų«ķgĄ─ą┼Žó═¼▓Į╬ęéāČ╝╩Ū▓╔ė├Ą─«É▓Į╠Ä└ĒŻ¼▒╚╚ń┼õų├ųąą─Ž“┤·└Ē│╠ą“Ęų░lĮY▐D╚╬䚯¼īŹļH╠Ä└ĒĄ─Ģr║“╬ęéā▓╔ė├Ą─╩Ū└ŁĄ─ĘĮ╩ĮŻ¼Č°▓╗╩Ū═ŲĄ─ĘĮ╩ĮŻ¼╬ęéāį┌┼õų├ųąą─║═┤·└Ē│╠ą“ų«ķgŠS│ų┴╦ę╗éĆą─╠°Ż¼ą─╠°Ą─ā╚╚▌╩Ū┤·└Ē│╠ą“žō▌dĄ─╦∙ėąĮY▐D╚╬䚥─ąŻ“×┤aŻ©įōąŻ“×┤aį┌┤·└Ē│╠ą“Ž“┼õų├ųąą─░l╦═ą─╠°ą┼ŽóĢrė╔┼õų├ųąą─ėŗ╦ŃŻ®Ż¼«ö┤·└Ē│╠ą“░l¼FÅ─┼õų├ųąą─Ą├ĄĮĄ─ąŻ“×┤a║═▒ŠĄžąŻ“×┤a▓╗═¼ĢrŻ¼ätšf├„ė├æ¶ī”ĮY▐D╚╬äš▀Mąą┴╦ą▐Ė─Ż©░³└©ą┬į÷Īóą▐Ė─Īóäh│²Ż®Ż¼┤╦Ģr┤·└Ē│╠ą“ų„äėŽ“┼õų├ųąą─░lŲ═¼▓ĮĮY▐D╚╬䚥─šłŪ¾ĪŻ▀@śėū÷Ą─║├╠Ä╩ŪŻ¼┤·└Ē│╠ą“į┌░l╔·Õ┤ÖCųžåó║¾Ż¼Ģ■ūįäė▀Mąą╚╬䚥─═¼▓ĮĪŻ
b) ▀MČ╚┐╔ęĢ╗»
ĮY▐D╚╬䚥─▀MČ╚į┌╬ęéāĄ─ĘĮ░Ėųą╩ŪīŹĢrģR┐éĄĮ┼õų├ųąą─Ą─Ż¼╬ęéāĘQ×ķ▀MČ╚┐╔ęĢ╗»Ż¼┤·└Ē│╠ą“═©▀^ę╗éƬÜ┴óĄ─ŠĆ│╠üĒ«É▓Į╠Ä└Ē▀MČ╚┐╔ęĢ╗»Ż¼ę╗ĘĮ├µ▀@śė┐╔ęįĮĄĄ═ī”ĮY▐D╚╬äšąį─▄Ą─Ė╔ö_Ż¼┴Ēę╗ĘĮ├µ┐╔ęį▒▄├Ōė╔ė┌ŠWĮjå¢Ņ}Īó┼õų├ųąą─Ģ║Ģr▓╗┐╔ė├Ą╚å¢Ņ}ī¦ų┬ĮY▐D╚╬äš«É│ŻĪŻ▀MČ╚┐╔ęĢ╗»ī”ė┌ė├æ¶üĒšfĘŪ│Żųžę¬Ż¼ė├æ¶į┌Ą┌ę╗┤╬Č©┴xĮY▐D╚╬äš▓ół╠ąąįō╚╬䚥─Ģr║“Ż¼▀MČ╚┐╔ęĢ╗»ą┼Žó╩Ūė├æ¶║═ŽĄĮy╗źäėĄ─╬©ę╗┤░┐┌Ż¼ī”ė├æ¶üĒšf╩Ū─¬┤¾Ą─ą─└Ē░▓╬┐ĪŻ
c) «É│Ż┐╔ęĢ╗»
┤·└Ē│╠ą“į┌ł╠ąąöĄō■ĮY▐D╚╬äšĢrŻ¼Ģ■ė÷ĄĮĖ„ĘN«É│Żą┼ŽóŻ¼▒╚╚ńöĄō■ÄņURL┼õų├Õeš`Ż¼Üv╩ĘÄņ╔·«aÄņ▒ĒĮYśŗ▓╗ę╗ų┬Ą╚Ż¼ī”ė┌▀@ą®«É│Żą┼ŽóŻ¼│²┴╦į┌▒ŠĄžėøõø╚šųŠ═ŌŻ¼╬ęéā▀Ćīó╦³éā░l╦═ĄĮ┴╦┼õų├ųąą─ĪŻīó▀@ą®«É│Ż┐╔ęĢ╗»Ż¼Č°▓╗╩Ūūīė├æ¶į┌┤¾┴┐Ą─╚šųŠųą╚źÖz╦„Ż¼▀@ĘNĘĮ╩ĮĘŪ│Ż▒Ńė┌į┌ŠĆå¢Ņ}Ą─į\öÓĪŻ
d) ╩┬äšę╗ų┬ąį
īó╔·«aÄņöĄō■▐DĄĮÜv╩ĘÄņ▒Š╔Ē╩Ūę╗éĆĘų▓╝╩ĮĄ─╩┬䚯¼į┌╬ęéāĄ─ĘĮ░ĖųąŻ¼▓╗─▄▒ŻūCöĄō■Ą─ÅŖę╗ų┬ąįŻ¼▒╚╚ńį┌Üv╩ĘöĄō■InsertĄĮÜv╩ĘÄņĄ─╦▓ķgŻ¼ė├æ¶ą▐Ė─┴╦╔·«aÄņĄ─öĄō■Ż¼╬ęéāĄ─ĘĮ░Ė▓╗Ģ■Öz£y▀@ĘNūā╗»Ż¼Ģ■ī¦ų┬ė├æ¶Ą─ą▐Ė─▓ó▓╗Ģ■Ę┤ė│ĄĮÜv╩ĘÄņųąŻ¼įņ│╔öĄō■▓╗ę╗ų┬ĪŻļm╚╗į┌╔·«aÄņųąäh│²Üv╩ĘöĄō■ĢrŻ¼┐╔ęįį÷╝ėÅŖę╗ų┬ąįĄ─ąŻ“ׯ¼ęįĮŌøQ▀@ĘNå¢Ņ}Ż¼Ą½╩Ū▀@śėĢ■ī”╔·«aÄņįņ│╔ę╗Č©Ą─ē║┴”Ż¼═¼Ģr┐╝æ]ĄĮ▀@ĘNŪķør░l╔·Ą─Ė┼┬╩śOĄ═Ż¼ę“┤╦▓óø]ėą▀Mąą╠ž╩Ō╠Ä└ĒĪŻ
Üv╩ĘöĄō■InsertĄĮÜv╩ĘÄņ║¾Ż¼┐╔─▄ė╔ė┌─│ĘN«É│Żī¦ų┬╔·«aÄņł╠ąąDelete▓┘ū„Ģr╩¦öĪŻ¼┤╦ĢrĢ■įņ│╔öĄō■╚▀ėÓŻ©╔·«aÄņ║═Üv╩ĘÄņ┤µį┌ŽÓ═¼öĄō■Ż®ĪŻī”ė┌▀@ĘNå¢Ņ}Ż¼╬ęéāĄ─ĘĮ░Ė╩Ū└¹ė├Redo LogŻ©ųžū÷╚šųŠŻ®ÖCųŲŻ¼į┌ĮY▐D╚╬äšųžą┬ł╠ąąĢrĖ∙ō■Redo Log╗ųÅ═«É│Ż¼Fł÷Ż¼╝mš²«É│ŻöĄō■ĪŻ
e) ĮY▐DöĄō■Ą─╗žØL
╬ęéā╠ß╣®┴╦ę╗éĆöĄō■╗žØL╣”─▄Ż¼┐╔ęįīóęčĮøĮY▐DĄĮÜv╩ĘÄņĄ─öĄō■─µŽ“╗žØLĄĮ╔·«aÄņŻ¼ė├æ¶┐╔ęį┼õų├WhereŚl╝■Š½┤_ųĖČ©ąĶę¬╗žØLĄ─öĄō■ĪŻėąą®╠ž╩ŌŪķørŻ¼śIäš╔ŽąĶę¬ī”ęčĮøĮY▐DĄ─Üv╩ĘöĄō■▀Mąąą▐Ė─Ż¼įō╣”─▄ų„ę¬ė├ė┌╠Ä└Ē▀@ĘNŪķørĪŻ═¼Ģrį┌£yįćļAČ╬Ż¼╬ęéā┐╔ęį═©▀^įō╣”─▄┐ņ╦┘╗ųÅ═£yįćöĄō■Ż¼ĘĮ▒Ńī”öĄō■ĮY▐DŲĮ┼_Ą─£yįćĪŻ
f) ┤·└Ē│╠ą“Ą─ūįäė╔²╝ē
┤·└Ē│╠ą“║═┼õų├ųąą─▒Š┘|╔Ž╩Ūę╗ĘNĄõą═Ą─C/SŻ©┐═æ¶Č╦/Ę■äšČ╦Ż®ĮYśŗŻ¼┐═æ¶Č╦╩ŪČÓīŹ└²▓┐╩Ż¼Ę■äšŲ„Č╦╩Ū╝»╚║▓┐╩Ż¼×ķ┴╦ŽĄĮy─▄ē“ŲĮ╗¼Ąž▀Mąą╔²╝ēŻ¼╬ęéāąĶę¬ī”┐═æ¶Č╦Ą─░µ▒Š▀MąąĮyę╗╣▄└ĒŻ¼═¼Ģr╬ęéā╠ß╣®┴╦┤·└Ē│╠ą“Ą─ūįäė╔²╝ē╣”─▄Ż¼ŽĄĮy╣▄└ĒåT┐╔ęį═©▀^┼õų├ųąą─ī”┤·└Ē│╠ą“▓┐╩īŹ└²▀Mąą╔²╝ēĪŻūįäė╔²╝ē╣”─▄Ż¼Įyę╗┴╦┤·└Ē│╠ą“Ą─░µ▒ŠŻ¼╩╣Ą├╬ęéā┐╔ęį▓╗ė├▒╗╝µ╚▌ąįå¢Ņ}┴bĮOŻ¼╩Ū╬ęéā─▄ē“▀Mąą┐ņ╦┘Ą³┤·ķ_░lėą┴”ų¦ō╬ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║OLTPŅÉŽĄĮyöĄō■ĮY▐DūŅ╝čīŹ█`
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/11121820556.html