



Ą┌2š┬ ŠWĮją┼Žóā╚╚▌Ą─½@╚Ī
į┌ęį╚fŠSŠWŻ©WWWŻ®×ķų„ę¬│ą▌dŲĮ┼_Ą─ć°ļH╗ź┬ōŠW│╔×ķ┼cł¾╝łé„├ĮĪóļŖ┼_ÅV▓ź╝░ļŖęĢ├Į¾w▓óųžĄ─Ą┌4┤¾ą┼Žóé„▓ź├Į¾wų«Ū░Ż¼Üv╩Ę╬─ĖÕĪóūŅą┬▓─┴ŽĄ╚Ž“ėŗ╦ŃÖCĄ─╩ųäėõø╚ļ╩Ūą┼ŽóĘų╬÷ŽĄĮyūŅ×ķų„ꬥ─öĄō■üĒį┤ĪŻį┌ŠWĮj├Į¾wą┼Žó┼cŠWĮj═©ą┼ą┼Žó▒ķ▓╝╩└ĮńĖ„éĆĮŪ┬õĄ─Į±╠ņŻ¼├µŽ“║Ż┴┐╗ź┬ōŠWą┼ŽóīŹ¼F╚½├µ╗“ėąßśī”ąįĄ─ā╚╚▌½@╚ĪŻ¼ęčĮø│╔×ķę╗éĆŹõą┬Ą─šnŅ}│╩¼Fį┌ŠWĮjā╚╚▌Ęų╬÷╚╦åT├µŪ░ĪŻ
Ķbė┌┤╦Ż¼▒Šš┬ų°ųž╠Įėæ╗ź┬ōŠWé„▓źą┼ŽóĄ─½@╚Īå¢Ņ}ĪŻį┌░č╗ź┬ōŠWé„▓źą┼ŽóäØĘų│╔ŠWĮj├Į¾wą┼Žó┼cŠWĮj═©ą┼ą┼ŽóĄ─╗∙ĄA╔ŽŻ¼▒Šš┬ųž³cĮķĮBŠWĮj├Į¾wą┼ŽóĄ─½@╚ĪįŁ└Ē┼c½@╚ĪĘĮĘ©Ż¼═¼Ģr║åę¬ųvĮŌŠWĮj═©ą┼ą┼Žó½@╚ĪĘĮ░ĖĪŻ
2.1 ╗ź┬ōŠWą┼ŽóŅÉą═
╩▄ęµė┌ć°ļH╗ź┬ōŠW╗∙ĄAįO╩®Į©įOĄ─ķLūŃ░lš╣Ż¼«öŪ░╗∙ė┌╗ź┬ōŠWīŹ¼Fą┼Žóé„▓ź▀@ę╗ŠWĮjæ¬ė├ęčĮøŽÓ«öŲš╝░ĪŻ├└ć°ę“╠žŠW▒O£y╣½╦Šš{▓ķöĄō■ųĖ│÷Ż¼Įžų╣ĄĮ2009─Ļ3į┬╩└ĮńĘČć·ā╚ŠWšŠĄ─┐éöĄ╩Ū224749695éĆĪŻ2009─Ļ1į┬Ą─ĪČųąć°╗ź┬ōŠWŠWĮj░lš╣ĀŅørĮyėŗł¾ĖµĪĘ’@╩ŠŻ¼ĄĮ2008─ĻĄūė“├¹ūóāįš▀į┌ųąć°Š│ā╚ūóāįĄ─ŠWšŠöĄŻ©░³└©į┌Š│ā╚Įė╚ļ║═Š│═ŌĮė╚ļŻ®▀_ĄĮ287.8╚féĆŻ¼ŠWĒō┐éöĄ▀_ĄĮ16086370233éĆŻ¼ŲĮŠ∙├┐éĆŠWšŠĄ─ŠWĒōöĄ╩Ū5588éĆŻ¼ŲĮŠ∙├┐éĆŠWĒōĄ─ūų╣ØöĄ╩Ū28.6KBĪŻ
╚▌╝{ų°öĄęį╚fTBĄ─ą┼Žó┐é┴┐Ż¼▓óŪęš²╠Äė┌ā╚╚▌▒¼š©ąįį÷ķLĄ─ć°ļH╗ź┬ōŠWŻ¼░³║¼┴╦Ė„╩ĮĖ„śėĪóā╚╚▌Õ─«ÉĄ─ą┼ŽóŻ¼Ą½Å─║Ļė^ĮŪČ╚╔ŽüĒųvŻ¼╗ź┬ōŠW╣½ķ_é„▓źą┼Žó┐╔ęįĘų×ķŠWĮj├Į¾wą┼Žó┼cŠWĮj═©ą┼ą┼Žóā╔┤¾ŅÉą═ĪŻ
2.1.1 ŠWĮj├Į¾wą┼Žó
ŠWĮj├Į¾wą┼Žó╩ŪųĖé„ĮyęŌ┴x╔ŽĄ─╗ź┬ōŠWŠWšŠĄ─╣½ķ_░l▓╝ą┼ŽóŻ¼ŠWĮjė├æ¶═©│Ż┐╔ęį╗∙ė┌═©ė├ŠWĮj×gė[Ų„Ż©└²╚ńŻ¼Microsoft╣½╦ŠĄ─Internet ExplorerŻ¼Netscape╣½╦ŠĄ─NavigatorŻ¼Mozilla╣½╦ŠĄ─Mozilla FirefoxŻ®½@Ą├╗ź┬ōŠW╣½ķ_░l▓╝Ą─ą┼ŽóĪŻė╔ė┌▒ŠĢ°ßśī”▀@ŅÉą┼ŽóōĒėąĮyę╗Ą─ą┼Žó½@╚ĪĘĮĘ©Ż¼ę“┤╦īóŲõĮyĘQ×ķŠWĮj├Į¾wą┼ŽóĪŻ║Ļė^ęŌ┴x╔ŽĄ─ŠWĮj├Į¾wą┼Žó╔µ╝░├µ▌^ÅVŻ¼┐╔ęį═©▀^ŠWĮj├Į¾wą╬æBĪó░l▓╝ą┼ŽóŅÉą═Īó├Į¾w░l▓╝ĘĮ╩ĮĪóŠWĒōŠ▀¾wą╬æB┼cą┼ŽóĮ╗╗źģfūhĄ╚ČÓĘNäØĘųĘĮĘ©▀Mę╗▓Į╝ÜĘų┼cģ^äeŠWĮj├Į¾wą┼ŽóĄ─ĮM│╔ĪŻ
1Ż«ŠWĮj├Į¾wą╬æB
Ė∙ō■ŠWĮj├Į¾wŠ▀¾wą╬æBĄ─▓╗═¼Ż¼ŠWĮj├Į¾w┐╔ęįĘų×ķÅV▓ź╩Į├Į¾w┼cĮ╗╗ź╩Į├Į¾wā╔ŅÉĪŻŲõųąŻ¼é„ĮyĄ─ÅV▓ź╩Į├Į¾wų„ę¬░³║¼ą┬┬äŠWšŠĪóšōē»Ż©BBSŻ®Īó▓®┐═Ż©BlogŻ®Ą╚ą╬æBŻ╗ą┬┼dĄ─Į╗╗ź╩Į├Į¾w║Ł╔w╦č╦„ę²ŪµĪóČÓ├Į¾wŻ©ęĢ/ę¶ŅlŻ®³c▓źĪóŠW╔ŽĮ╗ėčĪóŠW╔ŽšąŲĖ┼cļŖūė╔╠䚯©ŠWĮj┘Å╬’Ż®Ą╚ą╬æBĪŻ▓óŪęŻ¼├┐ĘNą╬æBĄ─ŠWĮj├Į¾wČ╝ęįĖ„ūįĄ─ĘĮ╩ĮŽ“╗ź┬ōŠWė├æ¶═Ų╦═Ųõ╣½ķ_░l▓╝ą┼ŽóĪŻ
2Ż«░l▓╝ą┼ŽóŅÉą═
Å─╣½ķ_░l▓╝ą┼ŽóĄ─Š▀¾wŅÉą═╔Ž┐┤Ż¼ŠWĮj├Į¾wą┼Žó┐╔ęį╝ÜĘų×ķ╬─▒Šą┼ŽóĪółDŽ±ą┼ŽóĪóę¶Ņlą┼Žó┼cęĢŅlą┼Žó4ĘNŅÉą═Ż¼ŲõųąŻ¼ŠWĮj╬─▒Šą┼Žó╩╝ĮK╩ŪŠWĮj├Į¾wą┼Žóųąš╝▒╚ūŅ┤¾Ą─ą┼ŽóŅÉą═ĪŻ
3Ż«├Į¾w░l▓╝ĘĮ╩Į
░┤ššŠWĮj├Į¾w╦∙▀xō±ą┼Žó░l▓╝ĘĮ╩ĮĄ─▓╗═¼Ż¼ŠWĮj├Į¾wą┼Žó▀Ć┐╔ęįĘų│╔┐╔ų▒Įė─õ├¹×gė[Ą─╣½ķ_░l▓╝ą┼ŽóŻ¼ęį╝░ąĶīŹ¼F╔ĒĘ▌šJūC▓┼┐╔▀Mę╗▓Į³cō¶ķåūxĄ─ŠWĮj├Į¾w░l▓╝ą┼ŽóĪŻ
4Ż«ŠWĒōŠ▀¾wą╬æB
ĪČųąć°╗ź┬ōŠWŠWĮj░lš╣ĀŅørĮyėŗł¾ĖµĪĘĖ∙ō■│¼µ£ĮėŠWĮjĄžųĘŻ©Įyę╗┘Yį┤Č©╬╗Ę¹Ż¼URLŻ®Ą─ĮM│╔Ż¼īóŠWĒōĘų│╔URLųą▓╗║¼Ī░Ż┐Ī▒╗“▌ö╚ļģóöĄĄ─ņoæBŠWĒōŻ¼ęį╝░URLųą║¼Ī░Ż┐Ī▒╗“▌ö╚ļģóöĄĄ─äėæBŠWĒōā╔ŅÉĪŻßśī”ŠWĒōā╚╚▌Ą─Š▀¾wśŗ│╔ą╬æBŻ¼▀Ć┐╔ęįī”ŠWĮj├Į¾wą┼ŽóųąĄ─ņoæBŠWĒō┼cäėæBŠWĒō▀MąąĖ³╝ė├„┤_Ąžģ^ĘųĪŻ
ŠWĒōų„¾wā╚╚▌ęį╬─▒Šą╬╩ĮŻ¼Č°ŠWĒōā╚Ūȵ£Įėą┼Žóęį│¼µ£ĮėŠWĮjĄžųĘĖ±╩Į┤µį┌ė┌ŠWĒōį┤╬─╝■ųąĄ─ŠWĒōī┘ė┌ņoæBŠWĒōŻ¼╚ńłD2-1╦∙╩ŠĪŻŠWĒōų„¾wā╚╚▌╗“ŠWĒōā╚Ūȵ£Įėą┼Žó═Ļ╚½ĘŌčbė┌ŠWĒōį┤╬─╝■ųąĄ──_▒ŠšZčįŲ¼Č╬ā╚Ą─ŠWĒōī┘ė┌äėæBŠWĒōŻ¼╚ńłD2-2╦∙╩ŠĪŻ

łD2-1 ņoæBŠWĒōīŹ└²
łD2-2 äėæBŠWĒōīŹ└²
Å─ŠWĒōā╚╚▌Ą─śŗ│╔ą╬æB▓╗ļy░l¼FŻ¼äėæBŠWĒō┼cņoæBŠWĒō▓╗═¼Ż¼╦³╩Ū╩╣ė├é„ĮyĄ─╗∙ė┌HTMLś╦ėøŲź┼õĄ─ŠWĒōĮŌ╬÷ĘĮĘ©╠ß╚ĪŠWĒōų„¾wā╚╚▌Ż¼ęį╝░ŠWĒōā╚Ūȵ£Įė╦∙ī”æ¬Ą─ŠWĮj│¼µ£ĮėĄžųĘĪŻ
5Ż«ą┼ŽóĮ╗╗źģfūh
░┤šš╦∙╩╣ė├Ą─ą┼ŽóĮ╗╗źģfūhĄ─▓╗═¼Ż¼ŠWĮj├Į¾wą┼Žó┐╔ęįĘų×ķHTTPŻ©SŻ®ą┼ŽóĪóFTPą┼ŽóĪóMMSą┼ŽóĪóRTSPą┼Žó┼cęčĮø▓╗ČÓęŖĄ─Gopherą┼ŽóĄ╚ĪŻŲõųąŻ¼MMSą┼Žó┼cRTSPą┼Žóī┘ė┌ęĢ/ę¶Ņl³c▓źģfūhĪŻ«ö╗ź┬ōŠWė├æ¶═©▀^ŠWĮj×gė[Ų„³cō¶MMS╗“RTSPģfūhą┼ŽóĢrŻ¼×gė[Ų„Ģ■═©▀^▓┘ū„ŽĄĮyš{ė├įōģfūhĮŌ╬÷╦∙ī”æ¬Ą──¼šJæ¬ė├│╠ą“Ż¼īŹ¼F╗ź┬ōŠWė├涚łŪ¾Ą─ęĢ/ę¶ŅlŲ¼Č╬▓źĘ┼ĪŻ
2.1.2 ŠWĮj═©ą┼ą┼Žó
╗ź┬ōŠWė├æ¶╩╣ė├│²ŠWĮj×gė[Ų„ęį═ŌĄ─īŻė├┐═æ¶Č╦▄ø╝■Ż¼īŹ¼F┼c╠žČ©³cĄ─═©ą┼╗“▀Mąą³cī”³c═©ą┼Ģr╦∙Į╗╗źĄ─ą┼Žóī┘ė┌ŠWĮj═©ą┼ą┼ŽóĪŻ│ŻęŖĄ─ŠWĮj═©ą┼ą┼Žó░³└©╩╣ė├ļŖūėÓ]╝■┐═æ¶Č╦╩š░lą┼╝■Ģr═©▀^ŠWĮjé„▌öĄ─ą┼ŽóŻ¼ęį╝░╩╣ė├╝┤Ģr┴─╠ņ╣żŠ▀▀Mąą³cī”³cĮ╗┴„Ģr╦∙é„▌öĄ─ŠWĮją┼ŽóĪŻĶbė┌ŠWĮj═©ą┼ą┼Žóį┌ę╗Č©│╠Č╚╔Ž▓ó▓╗ī┘ė┌ŠWĮj╣½ķ_░l▓╝ą┼ŽóŻ¼▒Šš┬īóų╗ī”▀@ŅÉą┼ŽóĄ─½@╚ĪįŁ└Ē┼c½@╚ĪĘĮĘ©▀Mąą║åę¬╠ĮėæĪŻ
2.2 ŠWĮj├Į¾wą┼Žó½@╚ĪįŁ└Ē
┼c├µŽ“╠žČ©³cĄ─ŠWĮj═©ą┼ą┼ŽóĄ─½@╚ĪĘČć·▓╗═¼Ż¼ŠWĮj├Į¾wą┼ŽóĄ─½@╚ĪĘČć·į┌└Ēšō╔Ž┐╔ęį╩Ūš¹éĆć°ļH╗ź┬ōŠWĪŻé„ĮyĄ─ŠWĮj├Į¾wą┼ŽóĄ─½@╚ĪÅ─ŅAŽ╚įOČ©Ą─Īó░³║¼ę╗Č©öĄ┴┐URLĄ─│§╩╝ŠWĮjĄžųĘ╝»║Ž│÷░lŻ¼½@╚Ī│§╩╝╝»║Žųą├┐éĆŠWĮjĄžųĘ╦∙ī”æ¬Ą─░l▓╝ā╚╚▌ĪŻČ°ŠWĮj├Į¾wą┼ŽóĄ─½@╚ĪŻ¼ę╗ĘĮ├µīó│§╩╝ŠWĮjĄžųĘ░l▓╝ą┼ŽóĄ─ų„¾wā╚╚▌░┤ššŽĄ┴ąā╚╚▌┼ąųžÖCųŲŻ¼ėą▀xō±Ąž┤µ╚ļ╗ź┬ōŠWą┼ŽóÄņĪŻ┴Ēę╗ĘĮ├µŻ¼▀Mę╗▓Į╠ß╚Īęč½@╚Īą┼Žóā╚ŪČĄ─│¼µ£ĮėŠWĮjĄžųĘŻ¼▓óīó╦∙ėą│¼µ£ĮėŠWĮjĄžųĘų├╚ļ┤²½@╚ĪĄžųĘĻĀ┴ąŻ¼ęįĪ░Ž╚╚ļŽ╚│÷Ī▒ĘĮ╩Įųę╗╠ß╚ĪĻĀ┴ąųąĄ─├┐ę╗éĆŠWĮjĄžųĘ░l▓╝Ą─ą┼ŽóĪŻŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Ø裣hķ_š╣┤²½@╚ĪĻĀ┴ąųąĄ─ŠWĮjĄžųĘ░l▓╝ą┼Žó½@╚ĪĪóęč½@╚Īą┼Žóų„¾wā╚╚▌╠ß╚ĪĪó┼ąųž┼cą┼Žó┤µā”Ż¼ęį╝░ęč½@╚Īą┼Žóā╚ŪČŠWĮjĄžųĘ╠ß╚Ī▓ó┤µ╚ļ┤²½@╚ĪĄžųĘĻĀ┴ą▓┘ū„Ż¼ų▒ų┴▒ķ▓╝╦∙ąĶĄ─╗ź▀BŠWĮjĘČć·ĪŻ
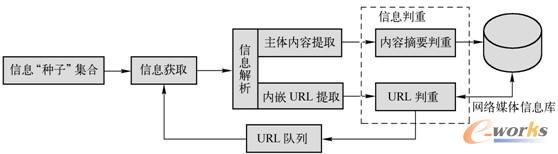
2.2.1 ŠWĮj├Į¾wą┼Žó½@╚Ī└ĒŽļ┴„│╠
└ĒŽļĄ─ŠWĮj├Į¾wą┼Žó½@╚Ī┴„│╠ų„ę¬ė╔│§╩╝URL╝»║ŽĪ¬Ī¬ą┼ŽóĪ░ĘNūėĪ▒╝»║ŽĪóĄ╚┤²½@╚ĪĄ─URLĻĀ┴ąĪóą┼Žó½@╚Ī─ŻēKĪóą┼ŽóĮŌ╬÷─ŻēKĪóą┼Žó┼ąųž─ŻēK┼c╗ź┬ōŠWą┼ŽóÄņ╣▓═¼ĮM│╔Ż¼╚ńłD2-3╦∙╩ŠĪŻ
łD2-3 ŠWĮj├Į¾wą┼Žó½@╚Ī└ĒŽļ┴„│╠
1Ż«│§╩╝URL╝»║Ž
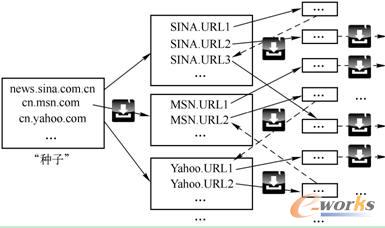
│§╩╝URL╝»║ŽĖ┼─ŅūŅ│§ė╔╦č╦„ę²ŪµčąŠ┐╚╦åT╠ß│÷Ż¼╔╠ė├╦č╦„ę²Ūµ×ķ┴╦╩╣ūį╔ĒōĒėąĄ─ą┼Žó│õĘųĖ▓╔wš¹éĆć°ļH╗ź┬ōŠWŻ¼ąĶꬊSūo░³║¼ŽÓ«ööĄ┴┐ŠWĮjĄžųĘĄ─│§╩╝URL╝»║ŽĪŻ╦č╦„ę²ŪµĖ·ļS│§╩╝URL╝»║Ž░l▓╝Ēō├µ╔ŽĄ─ŠWĮjµ£Įė▀M╚ļĄ┌ę╗╝ēŠWĒōŻ¼▓ó▀Mę╗▓ĮĖ·ļSĄ┌ę╗╝ēŠWĒōā╚Ūȵ£Įė▀M╚ļĄ┌Č■╝ēŠWĒōŻ¼ūŅĮKą╬│╔ų▄Č°Å═╩╝Ą─Ė·ļSŠWĒōā╚ŪČĄžųĘĄ─▀fÜw▓┘ū„Ż¼Å─Č°═Ļ│╔╦∙ėąŠWĒō░l▓╝ą┼ŽóĄ─½@╚Ī╣żū„ĪŻę“┤╦Ż¼│§╩╝URL╝»║Ž═©│Ż▒╗ą╬Ž¾ĄžĘQ×ķą┼ŽóĪ░ĘNūėĪ▒╝»║ŽŻ¼╚ńłD2-4╦∙╩ŠĪŻ
łD2-4 Ė·ļSŠWĒōā╚Ūȵ£Įėų╝ē▀fÜw▒ķÜv╗ź┬ōŠWĮj
Å─└Ēšō╔ŽųvŻ¼ų╗ꬊSūo░³║¼ūŃē“öĄ┴┐ŠWĮjĄžųĘĄ─│§╩╝URL╝»║ŽŻ¼╦č╦„ę²Ūµ╝┤┐╔▒ķÜvš¹éĆć°ļH╗ź┬ōŠWŻ©═©│Ż▀ĆąĶꬊWšŠų„äėŽ“╦č╦„ę²Ūµ╠ß╣®ŠWšŠĄžłDSitemapŻ®ĪŻį┤ė┌╦č╦„ę²Ūµæ¬ė├蹊┐Ą─ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣ØŻ¼═¼śėąĶę¬Ė∙ō■║¾└mŠWĮj├Į¾wą┼ŽóĘų╬÷Łh╣Ø╦∙ĻPūóĄ─╗ź┬ōŠWĮjĘČć·Ż¼╩┬Ž╚ŠSūo░³║¼ę╗Č©öĄ┴┐ŠWĮjĄžųĘĄ─│§╩╝URL╝»║ŽŻ¼ū„×ķą┼Žó½@╚Ī▓┘ū„Ą─Ų³cĪŻ
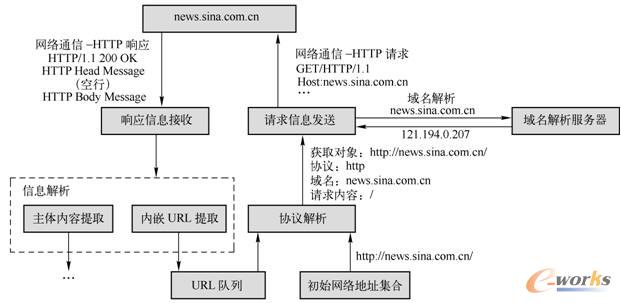
2Ż«ą┼Žó½@╚Ī
ą┼Žó½@╚Ī─ŻēKŽ╚Ė∙ō■üĒūį│§╩╝ŠWĮjĄžųĘ╝»║Ž╗“URLĻĀ┴ąųąĄ─├┐ŚlŠWĮjĄžųĘą┼ŽóŻ¼┤_Č©┤²½@╚Īā╚╚▌╦∙▓╔ė├Ą─ą┼Žó░l▓╝ģfūhĪŻį┌═Ļ│╔┤²½@╚Īā╚╚▌ģfūhĮŌ╬÷▓┘ū„║¾Ż¼ą┼Žó½@╚Ī─ŻēKīó╗∙ė┌╠žČ©═©ą┼ģfūh╦∙Č©┴xĄ─ŠWĮjĮ╗╗źÖCųŲŻ¼Ž“ą┼Žó░l▓╝ŠWšŠšłŪ¾╦∙ąĶā╚╚▌Ż¼▓óĮė╩šüĒūįŠWšŠĄ─Ēææ¬ą┼ŽóŻ¼īó╦³éāé„▀fĮo║¾└mĄ─ą┼ŽóĮŌ╬÷─ŻēKĪŻ╗∙ė┌HTTPģfūh░l▓╝Ą─╬─▒Šą┼Žó½@╚ĪĘČ└²╚ńłD2-5╦∙╩ŠŻ¼ī”ė┌HTTPą┼ŽóŠWĮjĮ╗╗ź▀^│╠╝Ü╣Ø┐╔▓ķķåģfūhęÄĘČĪ¬Ī¬Hypertext Transfer Protocol-HTTP/1.1,RFC 2616,June1999ĪŻ
łD2-5 HTTP╬─▒Šą┼Žó½@╚ĪĘČ└²
į┌└ĒšōįŁ└Ēīė├µ╔ŽŻ¼┴óūŃė┌ķ_Ę┼ŽĄĮy╗ź▀Bģó┐╝─Żą═Ż©OSI/RMŻ®Ą─é„▌öīėŻ¼┐╔ęį═©▀^ųžśŗĖ„ŅÉ═©ą┼ģfūhŻ©└²╚ńHTTP║═FTPĄ╚Ż®╦∙Č©┴xĄ─ŠWĮjĮ╗╗ź▀^│╠Ż¼īŹ¼F╗∙ė┌▓╗═¼═©ą┼ģfūhĄ─░l▓╝ā╚╚▌½@╚ĪĪŻļSų°╗ź┬ōŠWųą╬─▒ŠĪółDŽ±ą┼Žó░l▓╝ą╬æBĄ─▓╗öÓ═ŲĻÉ│÷ą┬Ż©╚╦ÖCĮ╗╗ź╩Įą┼Žó░l▓╝ą╬æBĄ─│÷¼Fų▒Įėī¦ų┬╬─▒ŠĪółDŽ±ą┼ŽóšłŪ¾ŠWĮj═©ą┼▀^│╠ė·╝ėÅ═ļsŻ®Ż¼ęĢ/ę¶Ņl░l▓╝ā╚╚▌Ą─īė│÷▓╗ĖFŻ©ęĢ/ę¶Ņlą┼ŽóŠWĮjĮ╗╗ź▀^│╠ųžśŗ└¦ļyŻ¼▓┐ĘųęĢ/ę¶ŅlŠWĮj═©ą┼ģfūhĮ╗╗ź╝Ü╣Ø▓ó╬┤╣½ķ_Ż®Ż¼╝ā┤Ōę└┘ćė┌Ė„ŅÉģfūhĄ─ŠWĮj═©ą┼Į╗╗ź▀^│╠ųžśŗŻ¼īŹ¼Fą┼Žóā╚╚▌½@╚ĪĄ─▓┘ū„Å═ļsČ╚║═ŠWĮjĮ╗╗źųžśŗļyČ╚│╩ųĖöĄ╝ēį÷ķLĪŻ
ę“┤╦Ż¼«öŪ░ĻPė┌ą┼Žó½@╚ĪĄ─蹊┐š²į┌ų▓Į▐DŽ“į┌æ¬ė├īė└¹ė├ķ_į┤×gė[Ų„▓┐ĘųĮM╝■Ż¼╔§ų┴š¹éĆķ_į┤×gė[Ų„īŹ¼FŠWĮj├Į¾wą┼Žóā╚╚▌Ą─ų„äė½@╚ĪŻ¼ŲõŽÓĻPā╚╚▌īóį┌▒Šš┬Ī░ŠWĮj├Į¾wą┼Žó½@╚ĪĘĮĘ©Ī▒ę╗╣Øųąū÷▀Mę╗▓ĮųvĮŌĪŻ
3Ż«ą┼ŽóĮŌ╬÷
į┌ą┼Žó½@╚Ī─ŻēK½@Ą├ŠWĮj├Į¾wĒææ¬ą┼Žó║¾Ż¼ą┼ŽóĮŌ╬÷─ŻēKĄ─║╦ą─╣żū„╩ŪĖ∙ō■▓╗═¼═©ą┼ģfūhĄ─Š▀¾wČ©┴xŻ¼Å─ŠWĮjĒææ¬ą┼ŽóŽÓæ¬╬╗ų├╠ß╚Ī░l▓╝ą┼ŽóĄ─ų„¾wā╚╚▌ĪŻ×ķ┴╦▒Ńė┌ķ_š╣ą┼Žó▓╔╝»┼cʱ┼ąöÓŻ¼ą┼ŽóĮŌ╬÷─ŻēK═©│Ż▀Ćīó░┤ššą┼Žó┼ąųžĄ─ę¬Ū¾Ż¼▀Mę╗▓ĮŠSūo┼cŠWĮjā╚╚▌░l▓╝Šo├▄ŽÓĻPĄ─ĻPµIą┼ŽóūųČ╬Ż¼└²╚ńą┼ŽóüĒį┤Īóą┼Žóś╦Ņ}Ż¼ęį╝░į┌ŠWĮjĒææ¬ą┼ŽóŅ^▓┐┐╔─▄┤µį┌Ą─ą┼Žó╩¦ą¦ĢrķgŻ©ExpiresŻ®╗“ą┼ŽóūŅĮ³ą▐Ė─ĢrķgŻ©Last-ModifiedŻ®Ą╚ĪŻą┼ŽóĮŌ╬÷─ŻēKĢ■░č╠ß╚ĪĄĮĄ─ā╚╚▌ų▒ĮėĮ╗Įoą┼Žó┼ąųž─ŻēKŻ¼į┌═©▀^▒žę¬Ą─ųžÅ═ā╚╚▌Öz▓ķ║¾Ż¼ŠWĮj├Į¾w░l▓╝ą┼ŽóĄ─ų„¾wā╚╚▌╝░Ųõī”æ¬Ą─ĻPµIūųČ╬īó▒╗┤µ╚ļ╗ź┬ōŠWą┼ŽóÄņĪŻ
×ķ┴╦īŹ¼FĖ·ļSŠWĒōā╚Ūȵ£Įė▀fÜw▒ķÜv╦∙ĻPūóĄ─ŠWĮjĘČć·▀@ę╗╝╝ągąĶŪ¾Ż¼ī”ė┌Ēææ¬ą┼ŽóŅÉą═Ż©Content-TypeŻ®╩Ūtext/*Ą─HTTP╬─▒Šą┼ŽóŻ¼ą┼ŽóĮŌ╬÷─ŻēKį┌═Ļ│╔Ēææ¬ą┼Žóų„¾wā╚╚▌╝░ĻPµIą┼ŽóūųČ╬╠ß╚ĪĄ─═¼ĢrŻ¼▀ĆąĶę¬▀Mę╗▓Įķ_š╣HTTP╬─▒Šą┼Žóā╚ŪČURLĄ─╠ß╚Ī▓┘ū„ĪŻą┼ŽóĮŌ╬÷─ŻēKīŹ¼FHTTP╬─▒Šą┼Žóā╚ŪČURL╠ß╚ĪĄ─└Ēšōę└ō■Ż¼╩ŪHTMLšZčįĻPė┌ŠWĮj│¼╬─▒Šµ£ĮėŻ©Hyper Text LinkŻ®ś╦ėøĄ─ŽĄ┴ąČ©┴xĪŻą┼ŽóĮŌ╬÷─ŻēKę╗░Ń═©▀^▒ķÜvHTTP╬─▒Šą┼Žó╚½╬─Ż¼▓ķšęŠWĮj│¼╬─▒Šµ£Įėś╦ėøĄ─ĘĮĘ©Ż¼īŹ¼FHTTP╬─▒Šą┼Žóā╚ŪČURLĄ─╠ß╚ĪĪŻ«öŪ░ą┼ŽóĮŌ╬÷─ŻēK▀Ć┐╔ęįŽ╚├µŽ“HTTP╬─▒Šą┼ŽóśŗĮ©╬─Önī”Ž¾─Żą═Ż©Document Object ModuleŻ¼DOMŻ®śõŻ¼▓óÅ─HTML DOMśõĄ─ŽÓæ¬ĮY³c½@╚ĪHTTP╬─▒Šā╚ŪČURLą┼ŽóŻ¼▒Šš┬ļS║¾ę╗╣Øīó▀MąąĻPė┌HTML DOMśõĄ─įö╝ÜĮķĮBĪŻ
4Ż«ą┼Žó┼ąųž
į┌ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣ØŻ¼ą┼Žó┼ąųž─ŻēKų„ę¬╗∙ė┌ŠWĮj├Į¾wą┼ŽóURL┼cā╚╚▌š¬ę¬ā╔┤¾į¬╦žŻ¼īŹ¼Fą┼Žó▓╔╝»/┤µā”Ą─┼cʱ┼ąöÓĪŻŲõųąŻ¼URL┼ąųž═©│Ż╩Ūį┌ą┼Žó▓╔╝»▓┘ū„åóäėŪ░▀MąąŻ¼Č°ā╚╚▌š¬ę¬┼ąųžät╩Ūį┌▓╔╝»ą┼Žó┤µā”Ģr░lō]ū„ė├ĪŻ
üĒūįHTTP╬─▒Šą┼ŽóĄ─ā╚ŪČURLą┼ŽóŻ¼╩ūŽ╚═©▀^URL┼ąųž▓┘ū„┤_Č©├┐éĆā╚ŪČURL╩ŪʱęčĮøīŹ¼Fą┼Žó½@╚ĪĪŻī”ė┌╔ą╬┤īŹ¼F░l▓╝ā╚╚▌▓╔╝»Ą─╚½ą┬URLŻ¼ą┼Žó½@╚Ī─ŻēKīóĢ■åóäė═Ļš¹Ą─ą┼Žó▓╔╝»┴„│╠ĪŻī”ė┌ęčĮøīŹ¼Fā╚╚▌▓╔╝»Ż¼═¼Ģrūó├„ą┼Žó╩¦ą¦Ģrķg╝░ūŅĮ³ą▐Ė─ĢrķgĄ─URLŻ©URLą┼Žó╩¦ą¦Ģrķg╝░ūŅĮ³ą▐Ė─Ģrķgęčė╔ą┼ŽóĮŌ╬÷─ŻēKÅ─ŠWĮjĒææ¬ą┼Žóųą╠ß╚ĪĄ├ĄĮŻ¼▓ó┤µė┌╗ź┬ōŠWą┼ŽóÄņųąŻ®Ż¼ą┼Žó▓╔╝»─ŻēKīóĢ■Ž“ī”æ¬Ą─ŠWĮjā╚╚▌░l▓╝├Į¾w░lŲą┼Žó▓ķą┬½@╚Ī▓┘ū„ĪŻ┤╦ĢrŻ¼ą┼Žó▓╔╝»─ŻēKų╗Ģ■ī”ė┌ęčĮø╩¦ą¦╗“š▀ęč▒╗ųžą┬ą▐Ė─Ą─ŠWĮjā╚╚▌ųžą┬åóäė═Ļš¹Ą─ą┼Žó▓╔╝»▓┘ū„ĪŻą┼Žó▓╔╝»─ŻēK═©│Ż▒╗ę¬Ū¾ųžą┬▓╔╝»ęčĮøīŹ¼Fą┼Žó½@╚ĪŻ¼Ą½╬┤ūó├„ą┼Žó╩¦ą¦Ģrķg╝░ūŅĮ³ą▐Ė─ĢrķgĄ─URL╦∙ī”æ¬Ą─░l▓╝ā╚╚▌ĪŻ
į┌├µŽ“ø]ėą╠ß╣®░l▓╝ą┼Žó╩¦ą¦Ģrķg╝░ūŅĮ³ą▐Ė─ĢrķgĄ─ŠWĮj├Į¾wŻ©ŠWĮj═©ą┼ģfūh▓ó╬┤ÅŖųŲę¬Ū¾Ēææ¬ą┼Žó▒žĒÜ╠ß╣®ą┼Žó╩¦ą¦Ģrķg╝░ūŅĮ³ą▐Ė─ĢrķgŻ®ĢrŻ¼āHę└┐┐URL┼ąųžÖCųŲŻ¼╩Ū¤oĘ©▒▄├Ō═¼ę╗ā╚╚▌▒╗ųžÅ═½@╚ĪĄ─ĪŻę“┤╦į┌½@╚Īą┼Žó┤µā”Ū░Ż¼ąĶę¬▀Mę╗▓Įę²╚ļā╚╚▌š¬ę¬┼ąųžÖCųŲĪŻŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Ø┐╔ęį╗∙ė┌MD5╦ŃĘ©Ż¼ųę╗ŠSūoęč▓╔╝»ą┼ŽóĄ─ā╚╚▌š¬ę¬Ż¼Č┼Į^ŽÓ═¼ā╚╚▌ųžÅ═┤µā”Ą─¼FŽ¾ĪŻ
2.2.2 ŠWĮj├Į¾wą┼Žó½@╚ĪĄ─ĘųŅÉ
░┤ššą┼Žó½@╚Īąą×ķ╦∙╔µ╝░Ą─ŠWĮjĘČć·äØĘųŻ¼ŠWĮj├Į¾wą┼Žó½@╚Ī┐╔ęįĘų×ķ├µŽ“š¹éĆć°ļH╗ź┬ōŠWĄ─╚½ŠWą┼Žó½@╚ĪŻ¼ęį╝░ßśī”─│ą®Š▀¾wŠWĮjģ^ė“Ą─Č©³cą┼Žó½@╚ĪĪŻ░┤ššą┼Žó½@╚Īąą×ķį┌╣żū„ĘČć·ā╚╦∙ĻPūóĄ─ī”Ž¾äØĘųŻ¼ŠWĮj├Į¾wą┼Žó½@╚Ī▀Ć┐╔ęįĘų×ķßśī”╣żū„ĘČć·ā╚╦∙ėą░l▓╝ą┼ŽóĄ─├µŽ“╚½▓┐ā╚╚▌Ą─ą┼Žó½@╚ĪŻ¼ęį╝░āHĻPūó╣żū„ŠWĮjĘČć·ā╚─│ą®¤ßķTįÆŅ}Ą─╗∙ė┌Š▀¾wų„Ņ}Ą─ą┼Žó½@╚ĪĪŻ▒Š╣Øųž³cĮķĮB╚½ŠWą┼Žó½@╚Ī┼cČ©³cą┼Žó½@╚Īį┌╝╝ągę¬Ū¾┼cīŹ¼FĘĮĘ©ĘĮ├µĄ─ģ^äeŻ¼▓ó▀Mę╗▓ĮųvĮŌ╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚ĪĘĮĘ©Ż¼ęį╝░įōŅIė“┤·▒Ēąį╝╝ągĪ¬Ī¬į¬╦č╦„ĪŻ
1Ż«╚½ŠWą┼Žó½@╚Ī
╚½ŠWą┼Žó½@╚Ī╣żū„ĘČć·╔µ╝░š¹éĆć°ļH╗ź┬ōŠWā╚╦∙ėąŠWĮj├Į¾w░l▓╝ą┼ŽóŻ¼ų„ę¬æ¬ė├ė┌╦č╦„ę²ŪµŻ©Search EngineŻ®Ż¼└²╚ńGoogleĪóBaidu╗“YahooĄ╚Ż¼║═┤¾ą═ā╚╚▌Ę■äš╠ß╣®╔╠Ż©Content Service ProviderŻ®Ą─ą┼Žó½@╚ĪĪŻļSų°ŠWĮją┬ą═├Į¾wĄ─▓╗öÓ│÷¼FĪóŠWĮją┼Žó░l▓╝ą╬╩ĮĄ─Ė³ą┬ōQ┤·Ż¼╝ā┤Ō═©▀^Ė·ļSŠWĮjµ£ĮėęčĮø║▄ļy▀_ĄĮ▒ķÜvš¹éĆ╗ź┬ōŠWĄ─ą¦╣¹ĪŻę“┤╦Ż¼╚½ŠWą┼Žó½@╚Ī░lŲĘĮį┌▓╗öÓĖ³ą┬ĪóöUš╣ė├ė┌ą┼Žó½@╚ĪĄ─│§╩╝URL╝»║ŽĄ─═¼ĢrŻ¼▀ĆĮ©ūhą┬Įė╚ļ╗ź┬ōŠWĄ─ŠWĮj├Į¾wų„äėŽ“ą┼Žó½@╚ĪĘĮ╠ßĮ╗ūį╔ĒŠWšŠĄžłDŻ©SiteMapŻ®ĪŻ▀@ėą└¹ė┌╚½ŠWą┼Žó½@╚ĪÖCųŲ├µŽ“ą┬ŠWĮj├Į¾wīŹ¼F░l▓╝ā╚╚▌▓╔╝»Ż¼Å─Č°▒ŻūCŲõ▒M┐╔─▄╚½├µĄžĖ▓╔wš¹éĆć°ļH╗ź┬ōŠWĪŻ
š²╚ńŪ░╬─╦∙╩÷Ż¼š¹éĆć°ļH╗ź┬ōŠWą┼Žó┐é┴┐ĘŪ│Ż²ŗ┤¾Ż¼┐╝æ]ĄĮ▒ŠĄžė├ė┌ą┼Žó▓╔╝»Ą─┤µā”┐šķgėąŽ▐Ż¼╚½ŠWą┼Žó½@╚Ī░lŲĘĮīŹļH╔Ž▓óø]ėą░č╦∙ėąŠWĮj├Į¾wą┼ŽóČ╝▓╔╝»ĄĮ▒ŠĄžĪŻ╦č╦„ę²Ūµ╗“┤¾ą═ā╚╚▌Ę■äš╠ß╣®╔╠į┌▀Mąą╚½ŠWą┼Žó½@╚ĪĢrŻ¼═©│Ż╗∙ė┌╠žČ©Ą─ėŗ╦ŃĘĮĘ©Ż©└²╚ńGoogleĄ─PageRank╦ŃĘ©Ż®ī”├┐ŚlŠWĮją┼Žó▀Mąąįu┼ąŻ¼ų╗╩Ū½@╚Ī╗“ķLĢrķg▒Ż┤µį┌ą┼Žóįu┼ąŽĄĮyųą┼┼├¹┐┐Ū░Ą─ŠWĮją┼ŽóŻ¼└²╚ńµ£Įėę²ė├┬╩▌^Ė▀Ą─ŠWĮj├Į¾w░l▓╝ā╚╚▌ĪŻ┴Ēę╗ĘĮ├µŻ¼ė╔ė┌╣żū„ī”Ž¾▒ķ▓╝š¹éĆć°ļH╗ź┬ōŠWŻ¼å╬┤╬╚½ŠWą┼Žó½@╚Īę╗░ŃąĶę¬öĄų▄─╦ų┴öĄį┬Ą─ĢrķgĪŻę“┤╦į┌├µī”ą┼ŽóĖ³ą┬ŽÓī”ŅlĘ▒Ą─ŠWĮj├Į¾wŻ©╚ńšōē»╗“▓®┐═Ż®ĢrŻ¼╚½ŠWą┼Žó½@╚ĪÖCųŲĄ─ā╚╚▌╩¦ą¦┬╩ŽÓī”▌^Ė▀Ż¼Ųõī”ė┌├┐éĆŠWĮj├Į¾w░l▓╝ā╚╚▌½@╚ĪĄ─Ģrą¦ąį¤oĘ©īŹ¼FĮyę╗▒ŻūCĪŻ▒M╣▄╚ń┤╦Ż¼╚½ŠWą┼Žó½@╚Īū„×ķ╦č╦„ę²Ūµ┼cā╚╚▌Ę■äš╠ß╣®╔╠▓╗┐╔╗“╚▒Ą─ą┼Žó½@╚ĪÖCųŲŻ¼ę└╚╗į┌ŠWĮją┼Žóæ¬ė├ųąŲĄĮśO×ķĻPµIĄ─ū„ė├ĪŻ
2Ż«Č©³cą┼Žó½@╚Ī
ė╔ė┌╚½ŠWą┼Žó½@╚Ī▓╗āHī”ė┌ā╚╚▌┤µā”┐šķgę¬Ū¾▀^Ė▀Ż¼Č°Ūę¤oĘ©▒ŻūCŠWĮj├Į¾w░l▓╝ā╚╚▌½@╚ĪĄ─Ģrą¦ąįŻ¼ę“┤╦į┌ŠWĮj├Į¾wą┼Žó½@╚Īų╗╩Ūųž³cĻPūó─│ą®╠žČ©Ą─ŠWĮjģ^ė“Ż¼▓óŪꎓą┼Žó½@╚ĪÖCųŲŽÓī”ė┌├Į¾wā╚╚▌░l▓╝Ą─ŠWĮjĢrčė╠ß│÷▌^Ė▀ę¬Ū¾ĢrŻ¼Č©³cą┼Žó½@╚ĪĄ─Ė┼─Ņæ¬▀\Č°╔·ĪŻ
Č©³cą┼Žó½@╚ĪĄ─╣żū„ĘČć·Ž▐ųŲį┌Ę■äšė┌ą┼Žó½@╚ĪĄ─│§╩╝URL╝»║Žųą├┐éĆURL╦∙ī┘Ą─ŠWĮj─┐õøā╚Ż¼╔Ņ╚ļ½@╚Ī├┐éĆ│§╩╝URL╦∙ī┘Ą─ŠWĮj─┐õø╝░ŲõŽ┬ūė─┐õøųą░³║¼Ą─ŠWĮj░l▓╝ā╚╚▌Ż¼▓╗į┘Ž“│§╩╝URL╦∙ī┘ŠWĮj─┐õøĄ─╔Ž╝ē─┐õøŻ¼─╦ų┴š¹éĆ╗ź┬ōŠWöU╔óą┼Žó½@╚Īąą×ķĪŻ╚ń╣¹šf╚½ŠWą┼Žó½@╚ĪĻPūóĄ─╩Ūą┼Žó½@╚Ī▓┘ū„Ą─╚½├µąįŻ¼╝┤ą┼Žó½@╚Īį┌š¹éĆ╗ź┬ōŠWųąĄ─Ė▓╔wŪķørŻ¼Č©³cą┼Žó½@╚ĪÖCųŲätĖ³╝ėųžęĢį┌Ž▐Č©Ą─ŠWė“ĘČć·ā╚Ż¼▀Mąą╔Ņ╚ļĄ─ŠWĮj├Į¾w░l▓╝ā╚╚▌½@╚ĪŻ¼═¼Ģrėąą¦▒ŻūC½@╚Īą┼ŽóĄ─Ģrą¦ąįĪŻ
Č©³cą┼Žó½@╚Īš²╩Ū═©▀^ų▄Ų┌ąįĄž▒ķÜv├┐éĆ│§╩╝URL╦∙ī┘Ą─ŠWĮj─┐õøŻ¼▀_ĄĮį┌│§╩╝URLįOČ©Ą─ŠWė“ĘČć·ā╚╔Ņ╚ļ½@╚ĪŠWĮj░l▓╝ā╚╚▌Ą─╝╝ągąĶŪ¾ĪŻ┼c┤╦═¼ĢrŻ¼ų▄Ų┌ąį▒ķÜv│§╩╝URL╦∙ī┘ŠWĮj─┐õøĄ─ĢrķgķgĖ¶Ż¼╩ŪČ©³cą┼Žó½@╚Īė├ė┌┤_▒Żā╚╚▌▓╔╝»Ģrą¦ąįĄ─ĻPµIģóöĄĪŻ║Ž└ĒįOČ©ų▄Ų┌▌åįāĪó▓ķą┬½@╚Ī│§╩╝URL╦∙ī┘ŠWĮj─┐õøĄ─ĢrķgķgĖ¶Ż¼┐╔ęį┤_▒ŻČ©³cą┼Žó½@╚ĪÖCųŲ▓╗ų┴ė┌Õe╩¦─┐ś╦ŠWĮj├Į¾w▓╗öÓĖ³ą┬Ą─░l▓╝ā╚╚▌Ż¼▓óŪęĘ└ų╣ą┼Žó½@╚ĪÖCųŲ▀^Ęųį÷╝ė─┐ś╦├Į¾wĄ─╣żū„žō▌dĪŻ
3Ż«╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚Ī┼cį¬╦č╦„
ė╔ė┌į┌š¹éĆć°ļH╗ź┬ōŠW╗“Ž▐Č©Ą─ŠWė“ĘČć·ā╚Ż¼╚½├µ½@╚Ī╦∙ėąŠWĮj├Į¾w░l▓╝ā╚╚▌┐╔─▄įņ│╔▒ŠĄž┤µā”ą┼ŽóĘ║×EŻ¼ę“┤╦į┌╦∙ĻPūóĄ─ŠWĮjĘČć·ā╚ų╗├µŽ“─│ą®╠žČ©įÆŅ}▀Mąą╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚ĪŻ¼╩Ūį┌├µŽ“╚½▓┐ā╚╚▌Ą─ą┼Žó½@╚Īęį═Ō┴Ēę╗éĆąąų«ėąą¦Ą─ą┼Žó½@╚ĪÖCųŲĪŻŅÖ├¹╦╝┴xŻ¼╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚Īų╗░č┼cŅAįOų„Ņ}ŽÓĘ¹Ą─ā╚╚▌▓╔╝»ĄĮ▒ŠĄžŻ¼▓óį┌ą┼Žó½@╚Ī▀^│╠ųąį÷╝ė┴╦ā╚╚▌ūRäeŁh╣ØŻ¼┐╔ęįų╗╩Ū║åå╬Ą─ų„Ņ}į~ģRŲź┼õŻ¼ę▓┐╔ęį├µŽ“░l▓╝ā╚╚▌▀Mąą╗∙ė┌ų„Ņ}Ą──Ż╩ĮūRäeŻ¼Å─Č°į┌ĻPūóĄ─ŠWĮjĘČć·ā╚ėą▀xō±Ąž½@╚ĪŠWĮj├Į¾w░l▓╝ā╚╚▌ĪŻŽÓī”ė┌├µŽ“╚½▓┐ā╚╚▌Ą─ą┼Žó½@╚ĪŻ¼╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚ĪÖCųŲš²╩Ū═©▀^ėąą¦£p╔┘ąĶę¬▓╔╝»Ą─ā╚╚▌┐é┴┐Ż¼▀Mę╗▓ĮĮĄĄ═ęč▓╔╝»ā╚╚▌Ą─╩¦ą¦┬╩Ż¼═¼Ģr’@ų°£p╔┘Ę■äšė┌ą┼Žó▓╔╝»Ą─ā╚╚▌┤µā”┐šķgĪŻ
░ķļS╦č╦„ę²Ūµæ¬ė├Ą─▓╗öÓ╔Ņ╚ļŻ¼į┌╦č╦„ę²ŪµĄ─ģfų·Ž┬▀Mąą╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚Ī╝╝ągĪ¬Ī¬į¬╦č╦„╝╝ągŻ¼Ą├ĄĮ┴╦įĮüĒįĮČÓĄ─æ¬ė├ĪŻį¬╦č╦„ī┘ė┌╠ž╩ŌĄ─╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚ĪŻ¼╦³īóų„Ņ}├Ķ╩÷į~é„▀fĮo╦č╦„ę²Ūµ▀Mąąą┼ŽóÖz╦„Ż¼▓ó░č╦č╦„ę²Ūµßśī”ų„Ņ}├Ķ╩÷į~Ą─ą┼ŽóÖz╦„ĮY╣¹ū„×ķ╗∙ė┌ų„Ņ}ą┼Žó½@╚ĪĄ─ĘĄ╗žā╚╚▌ĪŻ
į¬╦č╦„╝╝ągĄ├ęįīŹ¼FĄ─ĻPµIįŁę“╩ŪŻ¼├┐éĆ╦č╦„ę²Ūµį┌×ķ▌ö╚ļį~─┐śŗįņą┼ŽóÖz╦„URLĢr╩ŪėąęÄ┬╔┐╔裥─ĪŻęįųą/ėó╬─ą┼ŽóÖz╦„į~─┐×ķ└²Ż¼│Żė├╦č╦„ę²Ūµ╩Ū░čėó╬─į~─┐įŁ▒Šā╚╚▌Ż¼╗“ųą╬─į~─┐╦∙ī”æ¬Ą─ØhūųŠÄ┤aū„×ķą┼ŽóÖz╦„URLĄ─ģóöĄ▌ö╚ļĪŻ└²╚ńŻ¼Baidu╩Ū▀xō±ųą╬─į~─┐Ą─GBŠÄ┤aū„×ķą┼ŽóÖz╦„URLģóöĄĪŻ│²▌ö╚ļģóöĄ▓╗═¼ęį═ŌŻ¼ė├ė┌ŽÓ═¼╦č╦„ę²ŪµĄ─ą┼ŽóÖz╦„URLĄ─ŲõėÓ▓┐Ęų═Ļ╚½ŽÓ═¼Ż¼╚ńłD2-6╦∙╩ŠĪŻ

łD2-6 ╦č╦„ę²Ūµą┼ŽóÖz╦„URLśŗįņĘČ└²
į¬╦č╦„╝╝ągš²╩Ū═©▀^į┌▓╗═¼╦č╦„ę²ŪµĄ─ŠWĮjĮ╗╗ź▀^│╠ųąŻ¼Ė∙ō■├┐éĆ╦č╦„ę²ŪµĄ─Š▀¾wę¬Ū¾śŗįņų„Ņ}├Ķ╩÷į~ą┼ŽóÖz╦„URLŻ¼Ž“╦č╦„ę²Ūµ░lŲą┼ŽóÖz╦„šłŪ¾ĪŻį¬╦č╦„╝╝ąg└¹ė├╦č╦„ę²Ūµ▀Mąą╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚Ī▓┘ū„Ż¼╦³░č╦č╦„ę²ŪµĻPė┌ų„Ņ}├Ķ╩÷į~Ą─ą┼ŽóÖz╦„ĮY╣¹ū„×ķą┼Žó½@╚Īī”Ž¾Ż¼Å─Č°īŹ¼F├µŽ“╠žČ©ų„Ņ}Ą─ŠWĮj░l▓╝ā╚╚▌½@╚ĪĪŻ
2.2.3 ŠWĮj├Į¾wą┼Žó½@╚ĪĄ─╝╝ągļy³c
į┌ŠWĮj├Į¾wą┼Žó½@╚Ī╣”─▄īŹ¼F▀^│╠ųąŻ¼¤ošō╩Ū╚½ŠWą┼Žó½@╚ĪŻ¼▀Ć╩ŪČ©³cą┼Žó½@╚ĪŻ¼Č╝┤µį┌ŽÓ«ö│╠Č╚Ą─╝╝ągæ¬ė├īŹ¼FļyČ╚ĪŻ┴Ē═ŌŻ¼į¬╦č╦„ū„×ķ╠ž╩ŌĄ─╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚ĪŻ¼Ųõį┌ą┼Žó½@╚ĪĮY╣¹┼┼ą“ĘĮ├µ╚į╚╗┤µį┌╔ą╬┤═Ļ╚½ĮŌøQĄ─╝╝ągļy³cĪŻ
╩ūŽ╚Ż¼ŠWĮj├Į¾wą┼Žó½@╚ĪĄ─╣żū„ī”Ž¾╩Ūą┼Žóą╬æBĖ„«ÉĪóą┼ŽóŅÉą═ČÓśėĄ─╗ź┬ōŠW├Į¾wĪŻį┌ą┼Žó┐é┴┐čĖ╦┘┼“├øĄ─╗ź┬ōŠWą┼Žó├µŪ░Ż¼ŠWĮj├Į¾wą┼Žó½@╚ĪÖCųŲ═©│ŻąĶę¬į┌½@╚Īā╚╚▌Ą─╚½├µąį║═Ģrą¦ąįų«ķgū÷│÷╚Ī╔ßĪŻ┼c┤╦═¼ĢrŻ¼į┌├µī”═Ļ╚½«ÉśŗĄ─ŠWĮj├Į¾w░l▓╝ą┼ŽóĢrŻ¼ą┼Žó½@╚Ī╝╝ągąĶę¬į┌Ė„ŅÉ▓╗═¼Ą─ŠWĮj├Į¾wķgŲš▒ķ▀mė├Ż¼▀@ėų×ķŠWĮj├Į¾wą┼Žó½@╚Ī╣”─▄╠ß│÷┴╦Ė³Ė▀Ą─╝╝ągę¬Ū¾ĪŻ«öŪ░ŠWĮj├Į¾wą┼Žó½@╚ĪÖCųŲį┌▒Ż┴¶é„ĮyĄ─╗∙ė┌ŠWĮjĮ╗╗ź▀^│╠ųžśŗÖCųŲīŹ¼Fą┼Žó½@╚ĪĄ─╗∙ĄA╔ŽŻ¼ų▓Į▐DŽ“į┌ą┼Žó½@╚Ī▀^│╠ųą╝»│╔ķ_į┤×gė[Ų„▓┐ĘųĮM╝■╔§ų┴š¹¾wŻ¼ė├ė┌╠ßĖ▀╝╝ąg╣”─▄─▄╝ēĪóĮĄĄ═╝╝ągīŹ¼FļyČ╚Ż¼ų┴ė┌ŽÓĻPā╚╚▌īóį┌▒Šš┬║¾└m▓┐ĘųėĶęįįö╝ÜĮķĮBĪŻ
Ųõ┤╬Ż¼ė╔ė┌▓┐ĘųŠWĮj├Į¾w▀xō±Ų┴▒╬▀^ė┌ŅlĘ▒Ą─ĪóüĒūįŽÓ═¼┐═æ¶Č╦Ą─ą┼Žó½@╚Ī▓┘ū„Ż¼ę“┤╦Č©³cą┼Žó½@╚Ī╝╝ągīŹ¼FĄ─ļy³c▀Ć░³└©į┌ų▄Ų┌ąįĄž▒ķÜvįOČ©ŠWė“░l▓╝ā╚╚▌Ż¼┤_▒ŻČ©³cą┼Žó½@╚ĪĄ─╔Ņ╚ļąį┼cĢrą¦ąįĄ─╗∙ĄA╔ŽŻ¼ėąą¦╗ž▒▄─┐ś╦├Į¾wī”ė┌╦∙ų^Ī░É║ęŌĪ▒ą┼Žó½@╚Īąą×ķĄ─ĘŌĮ¹ĪŻę¬ĮŌøQ▀@ę╗╝╝ągļy³cŻ¼ę╗ĘĮ├µ┐╔ęį═©▀^▀m«ö▀xō±ų▄Ų┌▒ķÜvĢrķgķgĖ¶Ż¼Ę└ų╣ą┼Žó½@╚Īąą×ķįņ│╔ŠWĮj├Į¾wžō▌d▀^ųžŻ╗┴Ēę╗ĘĮ├µät╔µ╝░Č©Ų┌ą▐Ė─ė├ė┌ā╚╚▌½@╚ĪĄ─ŠWĮj┐═æ¶Č╦ą┼ŽóšłŪ¾ā╚╚▌Ż©ā╚╚▌ģf╔╠ąą×ķŻ®Ż¼ęį▒▄├ŌįŌė÷─┐ś╦ŠWĮj├Į¾wĄ─Š▄Į^Ę■äšĪŻ
ūŅ║¾Ż¼į¬╦č╦„į┌═©▀^╦č╦„ę²ŪµīŹ¼F╗∙ė┌ų„Ņ}Ą─ą┼Žó½@╚Ī▀^│╠ųąŻ¼┐╔ęį▀xō±Ž“ČÓéĆ╦č╦„ę²Ūµ┤«/▓óąą░l╦═ą┼ŽóÖz╦„šłŪ¾Ż¼öU┤¾į¬╦č╦„╝╝ągĄ─ŠWĮjĖ▓╔w├µĪŻš²╩Ūė╔ė┌▀@ę╗æ¬ė├ąĶŪ¾Ż¼ī”▓╗═¼ų„Ņ}▀xō±ŪĪ«öĄ─╦č╦„ę²ŪµŻ¼═¼Ģr╗∙ė┌║Ž▀mĄ─ų„Ņ}ŽÓĻPČ╚┼ąöÓĘ©ätŻ¼ī”üĒūį▓╗═¼╦č╦„ę²ŪµĄ─ą┼ŽóÖz╦„ĮY╣¹īŹ¼F╗∙ė┌ų„Ņ}Ą─ŽÓĻPČ╚┼┼ą“Ż¼š²╩Ū«öŪ░į¬╦č╦„╝╝ąg蹊┐Ą─ļy³c╦∙į┌ĪŻ
2.3 ŠWĮj├Į¾wą┼Žó½@╚ĪĘĮĘ©
į┌═Ļ│╔ĻPė┌ŠWĮj├Į¾wą┼Žó½@╚Ī╝╝ągĄ─ę╗░ŃąįįŁ└Ē├Ķ╩÷║¾Ż¼▒Š╣Ø▐DČ°ĮķĮBßśī”Ė„ŅÉŠWĮj├Į¾wĄ─░l▓╝ą┼Žó½@╚ĪĘĮĘ©ĪŻ░┤ą┼Žó░l▓╝ĘĮ╩ĮĘųŅÉŻ¼ŠWĮj├Į¾wą┼Žó┐╔Ęų│╔ų▒Įė─õ├¹×gė[ą┼Žó┼cąĶ╔ĒĘ▌šJūCŠWĮj├Į¾w░l▓╝ą┼Žóā╔ŅÉŻ╗░┤ŠWĒōŠ▀¾wą╬æBĘųŅÉŻ¼ŠWĮj├Į¾wą┼Žóėų┐╔Ęų│╔ņoæBŠWĒō┼cäėæBŠWĒōā╔ŅÉŻ¼▒Š╣Ø╩ūŽ╚ĮķĮB▓╔ė├ŠWĮjĮ╗╗ź▀^│╠ųžśŗÖCųŲŻ¼īŹ¼FąĶę¬╔ĒĘ▌šJūCĄ─ņoæBŠWĒō░l▓╝ą┼Žó½@╚ĪĘĮĘ©ĪŻ
į┌┤╦╗∙ĄA╔ŽŻ¼▒Š╣Ø▀Mę╗▓ĮĮķĮB╗∙ė┌ķ_į┤×gė[Ų„─_▒ŠĮŌ╬÷ĮM╝■Ż¼īŹ¼Fā╚ŪČ─_▒ŠšZčįŲ¼Č╬Ą─äėæBŠWĒō░l▓╝ą┼Žó½@╚ĪĘĮĘ©ĪŻūŅ║¾ųž³cĮķĮB╗∙ė┌×gė[Ų„─ŻöM╝╝ągŻ¼īŹ¼Fą╬æBĖ„«ÉĪóŅÉą═Ė„«ÉĄ─ŠWĮj├Į¾w░l▓╝ą┼Žó½@╚ĪĪŻ
2.3.1 ąĶ╔ĒĘ▌šJūCņoæB├Į¾w░l▓╝ą┼Žó½@╚Ī
ļSų°ŠWĮj╔ńģ^Ė┼─Ņ╝░éĆąį╗»ą┼ŽóĖ┼─ŅĄ─▓╗öÓŲš╝░Ż¼«öŪ░ČÓöĄŠWĮj├Į¾w╩ūŽ╚ąĶę¬╔ĒĘ▌šJūCŻ¼▓┼┐╔▀Mąąš²│ŻĄ─ā╚╚▌įLå¢ĪŻī”ė┌š²į┌▀MąąŠWĮj×gė[Ą─ė├æ¶Č°čįŻ¼╔ĒĘ▌▀^│╠╩ŪŽÓī”║åå╬Ą─ĪŻ╗ź┬ōŠWė├æ¶ų╗ąĶę¬Ė∙ō■ŠWĮjā╚╚▌░l▓╝š▀Ą─╠ß╩ŠŻ¼į┌╔ĒĘ▌šJūCŠWĒō╔Ž╠Ņīæš²┤_Ą─ė├æ¶├¹Īó├▄┤aą┼ŽóŻ¼▀Mąą▒žę¬Ą─łDņ`£yį毩š²┤_▌ö╚ļęįłDŽ±ą┼Žó’@╩ŠĄ─╔ĒĘ▌šJūC“×ūC┤aā╚╚▌Ż®Ż¼▓ó╠ßĮ╗╦∙ėąą┼ŽóŻ¼Š═─▄│╔╣”═Ļ│╔╔ĒĘ▌šJūCĪŻ▒M╣▄╚ń┤╦Ż¼ī”ė┌═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼Fą┼Žó½@╚ĪĄ─ėŗ╦ŃÖCČ°čįŻ¼į÷╝ė╔ĒĘ▌šJūC▀^│╠īóų▒Įėī¦ų┬ė├ė┌ą┼Žó½@╚ĪĄ─ŠWĮj═©ą┼▀^│╠─ŻöMūāĄ├Ė³╝ėÅ═ļsĪŻį┌┤╦ųž³c╠Įėæ╗∙ė┌ŠWĮjĮ╗╗źųžśŗÖCųŲŻ¼├µŽ“ąĶę¬╔ĒĘ▌šJūCĄ─ī”═Ō░l▓╝Ą─ŠWĒōą╬æBŻ©Č╝ī┘ė┌ņoæBŠWĒōĘČ«ĀĄ─ņoæBŠWĮj├Į¾wŻ®Ż¼īŹ¼F░l▓╝ā╚╚▌╠ß╚ĪĄ─Š▀¾wĘĮĘ©ĪŻ
į┌╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼Fą┼Žó½@╚ĪĄ─▀^│╠ųąŻ¼╚ń╣¹ŠWĮj├Į¾wę¬Ū¾╔ĒĘ▌šJūCŻ¼ą┼Žó½@╚ĪŁh╣ØŠ═ąĶę¬į┌įŁėąĄ─ą┼ŽóšłŪ¾▀^│╠ųžśŗŪ░Ż¼╩ūŽ╚─ŻöM╗∙ė┌HTTPģfūhĄ─ŠWĮj╔ĒĘ▌šJūC▀^│╠Ż¼▀@╩Ūė╔ė┌├µŽ“ŠWĮj├Į¾wĄ─╔ĒĘ▌šJūC═©│Ż╗∙ė┌HTTPģfūhĪŻ╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼F╔ĒĘ▌šJūCą┼Žó½@╚Īų„ę¬╔µ╝░ė├ė┌▒Ē├„╔ĒĘ▌šJūC│╔╣”Ą─Cookieą┼Žó½@Ą├Ż¼ęį╝░öyĦŽÓĻPCookieą┼Žó▀Mę╗▓ĮŽ“ŠWĮj├Į¾wšłŪ¾░l▓╝ā╚╚▌ā╔éƬÜ┴óŁh╣ØĪŻ
Ż©1Ż®╗∙ė┌CookieÖCųŲīŹ¼F╔ĒĘ▌šJūC
CookieÖCųŲė├ė┌═¼ę╗╗ź┬ōŠW┐═æ¶Č╦į┌▓╗═¼Ģr┐╠įL墎Ó═¼ŠWĮj├Į¾wĢrŻ¼┐═æ¶Č╦ą┼ŽóĄ─╗ųÅ═┼c└^│ąĪŻHTTP/1.1ßśī”CookieÖCųŲČ©┴x┴╦ā╔ŅÉł¾Ņ^▀xĒŚŻ©Header FieldsŻ®Ż¼Ęųäe╩ŪSet-Cookie▀xĒŚ║═Cookie▀xĒŚĪŻŲõųąŻ¼Cookie▀xĒŚ┤µį┌ė┌╗ź┬ōŠW┐═æ¶Č╦░l╦═Ą─šłŪ¾ą┼ŽóųąŻ¼Č°Set-Cookie▀xĒŚät│÷¼Fį┌ŠWĮj├Į¾wĒææ¬ą┼ŽóĄ─Ņ^▓┐ĪŻ
į┌╗ź┬ōŠW┐═æ¶Č╦Ž“ŠWĮj├Į¾w░l╦═ą┼ŽóšłŪ¾Ż¼ė╚Ųõ╩ŪéĆąį╗»Ż©ūįČ©┴xŻ®Ą─ą┼ŽóšłŪ¾ĢrŻ¼ŠWĮj├Į¾wĒææ¬ą┼ŽóŅ^▓┐═©│ŻĢ■░³║¼Set-Cookie▀xĒŚŻ¼ĘĄ╗žėøõøį┌ŠWĮj├Į¾wČ╦Ą─╗ź┬ōŠWė├æ¶╔ĒĘ▌ą┼ŽóĪŻį┌½@Ą├ŠWĮj├Į¾wĒææ¬ą┼Žó║¾Ż¼╗ź┬ōŠW┐═æ¶Č╦į┌╠ß╚ĪĒææ¬ą┼Žóų„¾wā╚╚▌Ą─═¼ĢrŻ¼▀ĆĢ■īóĒææ¬ą┼ŽóųąĄ─Set-Cookie▀xĒŚā╚╚▌┤µ╚ļ▒ŠĄžCookieą┼Žóėøõø╬─╝■ĪŻ«ö╗ź┬ōŠW┐═æ¶Č╦į┘┤╬Ž“ŽÓ═¼Ą─ŠWĮj├Į¾w░l╦═ą┼ŽóšłŪ¾ĢrŻ¼šłŪ¾ą┼ŽóŠ═Ģ■░³║¼Cookie▀xĒŚŻ¼╚¶Cookie▀xĒŚā╚╚▌┼cŽ╚Ū░Ą─Set-Cookie▀xĒŚā╚╚▌ę╗ų┬Ż¼ät╗ź┬ōŠW┐═æ¶Č╦į┌ŠWĮj├Į¾wČ╦▒Ż┴¶Ą─╔ĒĘ▌ą┼ŽóŠ═Ģ■Ą├ęį└^│ąŻ¼ŠWĮj├Į¾wĢ■ūįäėĖ∙ō■Ž╚Ū░Ą─ė├æ¶ūįČ©┴xą┼ŽóĘĄ╗žŽÓæ¬Ą─Ēææ¬ā╚╚▌Ż¼╚ńłD2-7╦∙╩ŠĪŻ
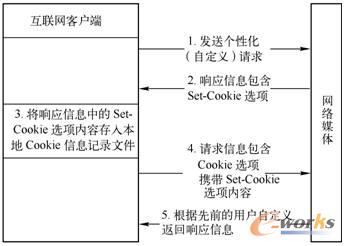
łD2-7 ╗∙ė┌CookieÖCųŲĄ─HTTPą┼ŽóĮ╗╗ź▀^│╠
└¹ė├CookieÖCųŲīŹ¼F╔ĒĘ▌šJūCŻ¼Š═╩Ūį┌╗ź┬ōŠW┐═æ¶Č╦├µŽ“ąĶ╔ĒĘ▌šJūCŠWĮj├Į¾wšJūC│╔╣”║¾Ż¼ŠWĮj├Į¾wŽ“┐═æ¶Č╦ĘĄ╗žėøõøį┌├Į¾wČ╦Ą─ė├æ¶ą┼ŽóŻ¼╝┤ė├ė┌▒Ē├„╔ĒĘ▌šJūC│╔╣”Ą─Cookieą┼ŽóĪŻų╗ę¬┐═æ¶Č╦į┌ļS║¾Ą─░l▓╝ą┼ŽóšłŪ¾ųąöyĦ▒Ē├„šJūC│╔╣”Ą─Cookieą┼ŽóŻ¼ŠWĮj├Į¾wŠ═Ģ■Ž“┐═æ¶Č╦ĘĄ╗žąĶę¬╔ĒĘ▌šJūC▓┼┐╔įLå¢Ą─ŠWĮj░l▓╝ā╚╚▌ĪŻī”ė┌ø]ėąöyĦ▒Ē├„šJūC│╔╣”CookieĄ─┐═æ¶Č╦šłŪ¾Ż¼ŠWĮj├Į¾wätĘĄ╗ž╔ĒĘ▌šJūC╩¦öĪą┼ŽóŻ¼▓óę¬Ū¾ė├æ¶▀Mąą╔ĒĘ▌šJūCŻ¼╚ńłD2-8╦∙╩ŠĪŻ
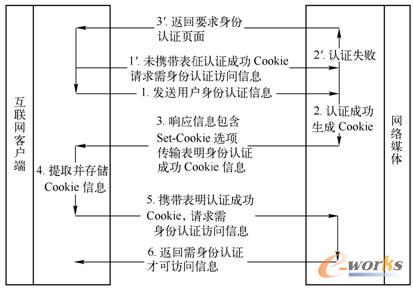
łD2-8 ╗∙ė┌CookieÖCųŲīŹ¼FąĶ╔ĒĘ▌šJūC▓┼┐╔įLå¢ą┼ŽóšłŪ¾
Ż©2Ż®╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼Fą┼Žó½@╚Ī
╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼F├Į¾wą┼Žó½@╚Ī╩ŪųĖ┴óūŃė┌šµīŹĄ─ŠWĮj═©ą┼▀^│╠Ż¼═©▀^ŠWĮjŠÄ│╠Ēśą“─ŻöMŠWĮj├Į¾wą┼ŽóšłŪ¾▀^│╠Ą─Ė„éĆŁh╣ØŻ¼ūŅĮKīŹ¼FŠWĮj├Į¾w░l▓╝ą┼Žó½@╚ĪĪŻį┌├µī”ąĶ╔ĒĘ▌šJūC▓┼┐╔×gė[Ą─ņoæB├Į¾w▀Mąą░l▓╝ą┼Žó½@╚ĪĢrŻ¼ŠWĮj╔ĒĘ▌šJūC▀^│╠┼cņoæB├Į¾w╦∙║¼ŠWĒō╝░Ųõā╚ŪČURL░l▓╝ą┼ŽóšłŪ¾▀^│╠Ż¼Č╝ąĶę¬▀Mąąš²┤_Ą─ŠWĮjĮ╗╗ź▀^│╠─ŻöMŻ¼▓┼─▄▀_ĄĮ½@╚ĪņoæB├Į¾w░l▓╝ą┼ŽóĄ─ūŅĮK─┐ś╦ĪŻ
į┌╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼F├Į¾wą┼Žó½@╚Ī▀^│╠ųąŻ¼├Į¾wą┼Žó½@╚ĪŁh╣Ø╩Ū═©▀^Ēææ¬ą┼ŽóĘĄ╗ž┤a┼ąöÓą┼Žó½@╚ĪšłŪ¾╩Ūʱ│╔╣”Ą─ĪŻę╗░ŃČ°čįŻ¼HTTP/1.X 20XŻ©└²╚ńHTTP/1.1 200OKŻ®ś╦ųŠų°ą┼ŽóšłŪ¾│╔╣”Ż¼HTTP/1.X 40Xś╦ųŠų°ą┼ŽóšłŪ¾╩¦öĪŻ¼Č°HTTP/1.X 401ätś╦ųŠų°į┌ą┼ŽóšłŪ¾▀^│╠ųą╔ĒĘ▌šJūC╩¦öĪŻ¼┤╦ĢrŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣ØąĶę¬ųŪ─▄Ąž▀Mąą╔ĒĘ▌šJūC▀^│╠─ŻöMŻ¼╚ńłD2-9╦∙╩ŠĪŻ
«ößśī”╩ū┤╬ą┼ŽóšłŪ¾Ą─Ēææ¬ĘĄ╗ž┤a╩Ū401ĢrŻ¼├Į¾wą┼Žó½@╚ĪŁh╣Ø╩ūŽ╚┼ąöÓā╚╚▌░l▓╝├Į¾w╔ĒĘ▌šJūC▀^│╠╩ŪʱąĶꬳDņ`Öz£yĪŻ╦∙ų^łDņ`Öz£y╩ŪųĖ─┐Ū░į┌ŠWĮj├Į¾w╔ĒĘ▌šJūC▀^│╠ųąŲš▒ķ╩╣ė├Ą─Ė▀įļ┬ĢöĄūų/ūų─ĖłDŽ±Ż¼į┌╗ź┬ōŠW┐═æ¶Č╦╠Ņīæė├æ¶├¹/├▄┤aą┼ŽóĢrŻ¼▒žĒÜ═¼Ģr▒µūRöĄūų/ūų─Ėą┼ŽóŻ¼▓ó┼cė├æ¶├¹/├▄┤aą┼Žóę╗═¼╠ßĮ╗Ż¼▓┼┐╔ęį═©▀^╔ĒĘ▌šJūCĪŻė├ė┌ŠWĮj├Į¾wą┼Žó½@╚ĪĄ─ė├æ¶├¹/├▄┤aą┼ŽóŻ¼┐╔ęį╩┬Ž╚į┌─┐ś╦├Į¾w╔Ž╩ųäė╔ĻšłĄ├ĄĮŻ¼▓óßśī”▓╗═¼ŠWĮj├Į¾wŠSūoė├æ¶├¹/├▄┤aÄņĪŻĻPė┌łDņ`Öz£yŻ¼╝┤ė├ė┌╔ĒĘ▌šJūCĄ─“×ūC┤aÖCŲ„ūRäeŽÓĻPā╚╚▌Ż¼ūxš▀┐╔ęįūįąą▓ķķå▒ŠĢ°ĻPė┌łDŽ±ą┼Žó╠Ä└ĒĄ─ŽÓĻPš┬╣ØĪŻ
ąĶę¬╠žäešf├„Ą─╩ŪŻ¼į┌╗∙ė┌ŠWĮjĮ╗╗źųžśŗīŹ¼FņoæB├Į¾w░l▓╝ą┼Žó½@╚Ī▀^│╠ųąŻ¼ŠWĮjŠÄ│╠─ŻöMą┼ŽóšłŪ¾▀^│╠Ż¼└Ēšō╔Ž┐╔ęį═©▀^│õĘų┴╦ĮŌŽÓĻP═©ą┼ģfūhĄ─Š▀¾wĮ╗╗ź▀^│╠ėĶęįīŹ¼FĪŻĄ½╩Ū┐╝æ]ĄĮ├┐éĆŠWĮj├Į¾w╔ĒĘ▌šJūC▀^│╠▓╗▒MŽÓ═¼Ż¼▓óŪęßśī”▓╗═¼ŠWĮj├Į¾w░l▓╝ą┼ŽóĄ─šłŪ¾öĄō■░³ā╚╚▌ĮM│╔Ė„«ÉŻ¼═Ļ╚½╗∙ė┌└Ēšō▀Mąą═©ą┼ģfūhöĄō■Į╗╗ź▀^│╠─ŻöMį┌ŠWĮjĮ╗╗źöĄō■░³ųžĮM┼cĘų╬÷Łh╣Ø┤µį┌ųTČÓļy³cĪŻ
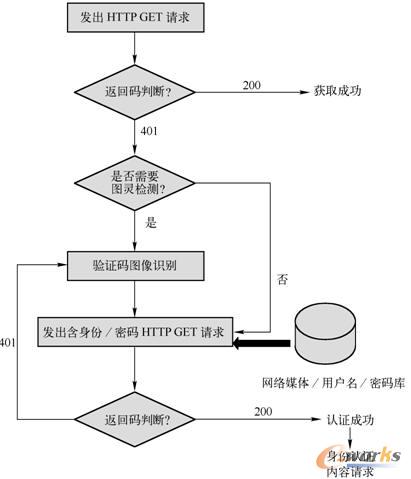
łD2-9 ŠWĮj├Į¾wą┼Žó½@╚Ī╔ĒĘ▌šJūC─ŻöM
▀@Ģr┐╔ęįį┌│ŻęŖĄ─Šųė“ŠWé╔┬Ā╣żŠ▀ģfų·Ž┬Ż¼╩ųäė═Ļ│╔╔ĒĘ▌šJūCšłŪ¾┼cņoæBŠWĒōą┼Žó×gė[╚½▀^│╠Ż¼▓óÅ─é╔┬Ā╣żŠ▀ųą½@Ą├╔ĒĘ▌šJūCšłŪ¾öĄō■░³ĪóŠWĮj├Į¾wĒææ¬öĄō■░³Ż¼ęį╝░ņoæBŠWĒōą┼ŽóšłŪ¾öĄō■░³Ą─Š▀¾wśŗ│╔Ż¼╚ńłD2-10╦∙╩ŠĪŻ
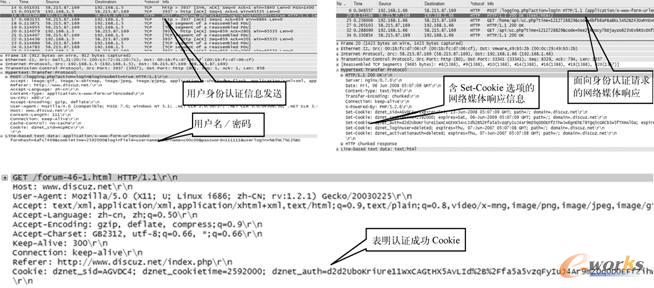
łD2-10 ╗∙ė┌Šųė“ŠWé╔┬Ā╣żŠ▀┴╦ĮŌŠWĮjĮ╗╗źöĄō■░³ĮM│╔
į┌┤╦╗∙ĄA╔ŽŠÄ│╠─ŻöMŠWĮjĮ╗╗ź▀^│╠ĢrŻ¼┐╔ęįų▒Įė░┤ššą┼ŽóšłŪ¾öĄō■░³Ą─īŹļHĮM│╔Ż¼śŗįņ╔ĒĘ▌šJūC╝░ŠWĒōą┼ŽóšłŪ¾öĄō■░³Ż©öyĦ▒Ē├„šJūC│╔╣”Ą─CookieŻ®Ż¼▓óį┌├µŽ“╔ĒĘ▌šJūCšłŪ¾Ą─Ēææ¬öĄō■░³ŽÓæ¬╬╗ų├╠ß╚Ī▒Ē├„╔ĒĘ▌šJūC│╔╣”Ą─Cookieą┼ŽóŻ¼└²╚ńSet-Cookie▀xĒŚā╚╚▌ĪŻį┌═Ļ╚½šŲ╬ššµīŹŠWĮj═©ą┼▀^│╠Ą─Ū░╠ߎ┬▀MąąŠWĮjĮ╗╗źųžśŗŻ¼─▄ē“ėąą¦ĮĄĄ═ŠWĮj═©ą┼öĄō■░³Ą─ųžĮM┼cĘų╬÷Ż¼ęį╝░ŠÄ│╠ųžśŗŠWĮjĮ╗╗ź▀^│╠Ą─╣żū„Å═ļsČ╚ĪŻ
═©▀^ŠWĮjĮ╗╗źųžśŗ½@╚ĪĄĮņoæBŠWĮj├Į¾wŲ╩╝ŠWĒō░l▓╝ą┼Žó║¾Ż¼┐╔ęį▓╔ė├é„ĮyĄ─╗∙ė┌HTMLś╦ėøŲź┼õĄ─ŠWĒōĮŌ╬÷ĘĮĘ©Ż¼╠ß╚ĪŠWĒōų„¾wā╚╚▌╝░Ųõā╚ŪČURLą┼ŽóĪŻ└²╚ńŻ¼┐╔ęįÅ─Ī░
┼cĪ▒ś╦ėøī”ųą╠ß╚ĪņoæBŠWĒōų„¾wā╚╚▌Ż¼Å─Ī░┼cĪ▒ś╦ėøī”ųą╠ß╚ĪŠWĒōā╚ŪČURLą┼ŽóĪŻĻPė┌ŠWĒōĮŌ╬÷ĘĮĘ©┐╔─▄╔µ╝░Ųõ╦¹HTMLś╦ėøŻ¼ūxš▀┐╔ęįūįąą▓ķķå╬─½IĪ¬Ī¬HTML 4.01 Specification, W3C Recommendation, December 1999ĪŻų«║¾Ż¼ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Øīó└^└m×ķ├┐éĆā╚ŪČURLśŗĮ©▓ó░l╦═ą┼ŽóšłŪ¾░³Ż©ā╚║¼▒Ē├„╔ĒĘ▌šJūC│╔╣”Ą─CookieŻ®Ż¼ęį½@╚ĪŲõ░l▓╝ā╚╚▌Ż¼ūŅĮKį┌╦∙ĻPūóĄ─╗ź┬ōŠWĘČć·ā╚Ż¼ßśī”ąĶę¬╔ĒĘ▌šJūCĄ─ņoæBŠWĮj├Į¾w╩┬Ž╚░l▓╝ą┼Žó╠ß╚Ī╣żū„ĪŻ
2.3.2 ā╚ŪČ─_▒ŠšZčįŲ¼Č╬Ą─äėæBŠWĒōą┼Žó½@╚Ī
äėæBŠWĒōų„¾wā╚╚▌╝░Ųõā╚ŪČURLą┼Žó═Ļ╚½ĘŌčbė┌ŠWĒōį┤╬─╝■ųąĄ──_▒ŠšZčįŲ¼Č╬ā╚Ż¼╚ńłD2-11╦∙╩ŠĪŻ«ö═©▀^ŠWĮjĮ╗╗źųžśŗ½@Ą├äėæBŠWĒō░l▓╝ą┼ŽóĢrŻ¼¤oĘ©ų▒Įė╩╣ė├╗∙ė┌HTMLś╦ėøŲź┼õĘĮĘ©╠ß╚ĪŠWĒōų„¾wā╚╚▌╝░Ųõā╚ŪČURLą┼ŽóĪŻį┌▀@ĘNŪķørŽ┬Ż¼┐╔ęįŽ╚░čäėæBŠWĒōųą░³║¼Ą─╦∙ėą─_▒ŠšZčįŲ¼Č╬é„▀fĮoMozilla×gė[Ų„Ą──_▒ŠĮŌßīĮM╝■Ī¬Ī¬SpiderMonkeyŻ¼╗“¬Ü┴ó─_▒ŠĮŌßīę²ŪµĪ¬Ī¬RhinoŻ¼īŹ¼FäėæB─_▒ŠĮŌ╬÷▓ó½@Ą├─_▒ŠŲ¼Č╬╦∙ī”æ¬Ą─ņoæBŠWĒōā╚╚▌Ż¼▀MČ°░┤ššņoæBŠWĒōą┼Žó½@╚ĪĘĮĘ©═Ļ│╔äėæBŠWĒō╝░Ųõā╚ŪČURL░l▓╝ā╚╚▌Ą─½@╚Ī╣żū„ĪŻ
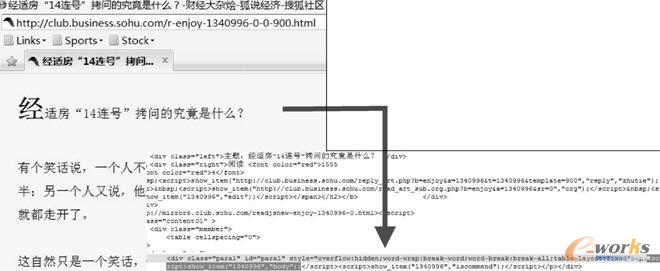
łD2-11 äėæBŠWĒōų„¾wā╚╚▌ĘŌčbė┌į┤╬─╝■─_▒ŠšZčįŲ¼Č╬ųą
Ķbė┌«öŪ░JavaScriptÅVĘ║æ¬ė├ė┌äėæBŠWĒōĄ─ŠÄīæŻ¼▒Š╣Øų„ę¬ųvĮŌ╚ń║╬╗∙ė┌─_▒ŠĮŌßīę²ŪµRhinoŻ¼├µŽ“░³║¼JavaScriptĄ─äėæBŠWĒōīŹ¼F░l▓╝ą┼Žó½@╚ĪĪŻ▓╗▀^į┌▀@ęįŪ░Ż¼╩ūŽ╚ĮķĮB└¹ė├╬─Önī”Ž¾─Żą═DOMśõŻ¼╠ß╚ĪäėæBŠWĒō╦∙║¼─_▒ŠšZčįŲ¼Č╬Ą─Š▀¾wĘĮĘ©ĪŻįōĘĮĘ©═¼śė▀mė├ė┌╠ß╚ĪņoæBŠWĒōų„¾wā╚╚▌Ż¼ęį╝░ŠWĒōā╚ŪČURLą┼ŽóĪŻ
Ż©1Ż®└¹ė├HTML DOMśõ╠ß╚ĪäėæBŠWĒōā╚Ą──_▒ŠšZčįŲ¼Č╬
╬─Önī”Ž¾─Żą═DOM╩Ūęįīė┤╬ĮYśŗĮM┐ŚĄ─ĮY³c╗“ą┼ŽóŲ¼Č╬╝»║ŽŻ¼╦³╠ß╣®┐ńŲĮ┼_▓óŪę┐╔æ¬ė├ė┌▓╗═¼ŠÄ│╠šZčįĄ─ś╦£╩│╠ą“Įė┐┌ĪŻDOM░č╬─Ön▐DōQ│╔śõą╬ĮYśŗŻ¼╩╣╬─ÖnųąĄ─├┐éĆ▓┐ĘųČ╝│╔×ķDOMśõĄ─ĮY³cĪŻHTML DOM╩ŪīŻķTæ¬ė├ė┌HTML/XHTMLĄ─╬─Önī”Ž¾─Żą═Ż¼ų„ę¬░³║¼WindowĪóDocumentĪóLocationĪóScreenĪóNavigator┼cHistoryĄ╚HTML DOMī”Ž¾ĪŻHTMLŠWĒō┼cHTML DOMśõķgĄ─ī”æ¬ĻPŽĄ╚ńłD2-12╦∙╩ŠĪŻ
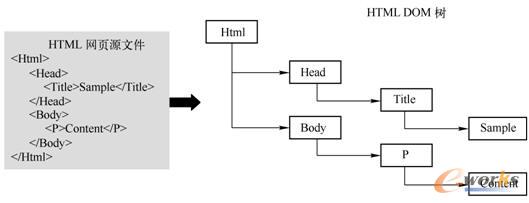
łD2-12 HTMLŠWĒōī”æ¬Ą─HTML DOMśõ
HTMLŠWĒōī”æ¬Ą─HTML DOMśõ┤µā”ė┌×gė[Ų„ā╚┤µī”Ž¾ųąŻ¼įōī”Ž¾īŹ¼F┴╦░³║¼╚¶Ė╔ĘĮĘ©Ą─ś╦£╩│╠ą“Įė┐┌ĪŻŠWĒōķ_░l╚╦åT┐╔ęį═©▀^ŽÓæ¬Įė┐┌Ż¼ī”HTML DOMśõ╔ŽĄ─├┐éĆĮY³c▀Mąą▒ķÜvĪó▓ķįāĪóą▐Ė─╗“äh│²Ą╚▓┘ū„Ż¼Å─Č°äėæBįLå¢║═īŹĢrĖ³ą┬HTMLŠWĒōĄ─ā╚╚▌ĪóĮYśŗ┼cśė╩ĮĪŻ
äėæBHTMLŠWĒōĄ──_▒ŠšZčįŲ¼Č╬═©│ŻĢ°īæė┌ Ī░ < Script > ┼c < / Script > Ī▒ ś╦ėøī”ųąŻ¼Č°╠žČ©Ą─JavaScript─_▒ŠšZčįŲ¼Č╬┐╔ęį╩╣ė├ Ī░ JavaScript : Ī▒ į┌Ų¼Č╬ķ_╩╝╠Ä▀Mąąś╦ėøĪŻę“┤╦┐╔ęįį┌HTML DOMśõųąŻ¼═©▀^▒ķÜvś╦ėø─_▒ŠŲ¼Č╬Ą─ Ī░ Script Ī▒ ĮY³c╗“ Ī░ JavaScript :Ī▒ĮY³cŻ¼½@Ą├äėæBHTMLŠWĒōā╚░³║¼Ą─╦∙ėą─_▒ŠšZčįŲ¼Č╬ĪŻ═¼└ĒŻ¼┐╔ęį═©▀^▓ķįāĪ░BodyĪ▒ĮY³cŻ¼½@Ą├ņoæBŠWĒōų„¾wā╚╚▌ĪŻ┴Ē═ŌŻ¼ė╔ė┌ņoæBŠWĒōā╚ŪČŠWĮj│¼µ£ĮėĄžųĘ═©│Ż╬╗ė┌ Ī░ < a href > ║═ < / a > Ī▒ ś╦ėøī”ųąŻ¼┐╔ęį═©▀^▒ķÜvĪ░AĪ▒ĮY³cŻ¼½@Ą├ņoæBŠWĒōā╚ŪČURLą┼ŽóĪŻ
Ż©2Ż®╗∙ė┌RhinoīŹ¼FJavaScriptäėæBŠWĒōą┼Žó½@╚Ī
š²╚ń╔Ž╣Ø╦∙╩÷Ż¼▒ķÜvHTML DOMśõ┐╔ęįĄ├ĄĮJavaScriptäėæBŠWĒō╦∙░³║¼Ą──_▒ŠŲ¼Č╬ĪŻ×ķ┴╦īŹ¼FJavaScriptŠWĒō░l▓╝ą┼ŽóĄ─½@╚ĪŻ¼ąĶę¬░č╠ß╚ĪĄĮĄ─JavaScriptŲ¼Č╬▌ö╚ļ¬Ü┴óĮŌßīę²ŪµRhinoīŹ¼FäėæB─_▒ŠĮŌ╬÷Ż¼½@Ą├─_▒ŠŲ¼Č╬╦∙ī”æ¬Ą─ņoæBŠWĒōą╬╩ĮŻ¼▓óūŅĮK═Ļ│╔JavaScriptäėæBŠWĒō░l▓╝ą┼Žó½@╚Ī╣żū„Ż¼╚ńłD2-13╦∙╩ŠĪŻ
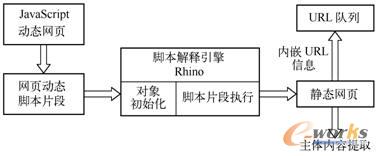
łD2-13 ╗∙ė┌RhinoīŹ¼FJavaScriptäėæBŠWĒō░l▓╝ą┼Žó½@╚Ī
į┌Rhino▀MąąJavaScriptŠWĒōäėæB─_▒ŠĮŌ╬÷▀^│╠ųąŻ¼ąĶę¬╩ūŽ╚═Ļ│╔─_▒ŠŲ¼Č╬░³║¼Ą─╦∙ėąī”Ž¾│§╩╝╗»▓┘ū„Ż¼╚╗║¾░┤ššäėæBŠWĒō╝ė▌d▀^│╠Ēśą“ł╠ąąJavaScript─_▒ŠŲ¼Č╬ĪŻ
1Ż«ī”Ž¾│§╩╝╗»
ū„×ķ─_▒ŠĮŌßīę²ŪµŻ¼Rhinoļm╚╗┐╔ęįų▒ĮėūRäeJavaScriptšZčįā╚ų├ī”Ž¾┼cäėæBŠWĒō─_▒ŠŲ¼Č╬ūįČ©┴xī”Ž¾Ż¼▓óūįäėš{ė├┐╔ūRäeī”Ž¾Č©┴xĄ─ĘĮĘ©Ż¼Ą½╩Ū╦³¤oĘ©ūRäe┼cš{ė├─│ą®╠ž╩Ōī”Ž¾Č©┴xĄ─ĘĮĘ©ĪŻį┌─_▒ŠĮŌßīę²Ūµī”Ž¾│§╩╝╗»ļAČ╬Ż¼Rhino¤oĘ©ūRäeĄ─╠ž╩Ōī”Ž¾ų„ę¬╩ŪųĖ╔Ž╬─╠ߥĮĄ─WindowĪóDocumentĪóLocationĪóScreenĪóNavigator┼cHistoryĄ╚HTML DOMī”Ž¾ĪŻ
ę“┤╦Ż¼į┌åóäėRhinoĒśą“ł╠ąąJavaScriptŲ¼Č╬Ū░Ż¼╩ūŽ╚ąĶę¬ūįČ©┴x─_▒ŠŲ¼Č╬╦∙║¼HTML DOMī”Ž¾ĘĮĘ©Ą─Š▀¾w╣”─▄Ż¼═Ļ│╔HTML DOMī”Ž¾Ą─▒ŠĄžäōĮ©╣żū„Ż¼╚ńłD2-14╦∙╩ŠĪŻļSų°AjaxÖCųŲį┌Web 2.0æ¬ė├ųąĄ─▓╗öÓŲš╝░Ż¼ČÓöĄäėæBŠWĒō▀Ć▀xō±Ajax╝╝ągš{ė├ņoæB╬─▒Šą┼ŽóĪŻī”ė┌░³║¼AjaxÖCųŲĄ─äėæBŠWĒōŻ¼į┌ī”Ž¾│§╩╝╗»ļAČ╬Ż¼▀ĆąĶę¬ĖĮ╝ėī”AjaxÖCųŲųąXmlHttpRequestī”Ž¾ĘĮĘ©Ą─ūįČ©┴xĪŻ
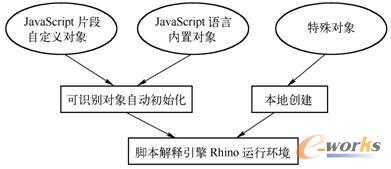
łD2-14 ─_▒ŠĮŌßīę²ŪµRhinoī”Ž¾│§╩╝╗»
į┌ī”Ž¾│§╩╝╗»ļAČ╬▀MąąRhino¤oĘ©ūRäeĄ─╠ž╩Ōī”Ž¾▒ŠĄžäōĮ©Ż¼Š═╩Ūį┌Rhino▀\ąąŁhŠ│ųąČ©┴x╠ž╩Ōī”Ž¾ĘĮĘ©║»öĄĄ─Š▀¾w╣”─▄ĪŻ└²╚ńŻ¼HTML DOMī”Ž¾WindowĘĮĘ©║»öĄOpenĄ─ģóöĄ╩ŪäėæBĒō├µā╚ŪČURLą┼ŽóŻ¼─¼šJ╣”─▄╩Ūą┬Į©×gė[Ų„┤░┐┌’@╩ŠįōURL░l▓╝ā╚╚▌ĪŻį┌Windowī”Ž¾OpenĘĮĘ©Ą─▒ŠĄžäōĮ©▀^│╠ųąŻ¼┐╔į┌Rhino▀\ąąŁhŠ│ųąūįČ©┴xįōĘĮĘ©Ą─╣”─▄Ż¼░čī”æ¬URLą┼Žóų├╚ļą┼Žó½@╚ĪŁh╣ØĄ─URLĻĀ┴ąŻ¼Ą╚┤²▀Mąąą┼Žó½@╚Ī▓┘ū„ĪŻŽÓæ¬ĄžŻ¼HTML DOMī”Ž¾DocumentĘĮĘ©║»öĄWriteĄ─ģóöĄ╩ŪņoæBŠWĒōą┼ŽóŻ¼─¼šJ╣”─▄╩Ūį┌«öŪ░×gė[Ų„┤░┐┌ųą’@╩ŠņoæBŠWĒō░l▓╝ā╚╚▌ĪŻ┐╔į┌Documentī”Ž¾WriteĘĮĘ©╣”─▄ūįČ©┴xĢršf├„įōĘĮĘ©Ż¼ė├ė┌░čņoæBŠWĒōą┼Žóīæ╚ļ╬╗ė┌ą┼Žó▓╔╝»Č╦Ą─╠žČ©╬─╝■ųąĪŻ
į┌Rhino▀MąąJavaScriptŲ¼Č╬ĮŌ╬÷▀^│╠ųąŻ¼╚ń╣¹ė÷ĄĮ¤oĘ©ų▒ĮėūRäeĄ─╠ž╩Ōī”Ž¾Ż¼╦³Ģ■į┌▀\ąąŁhŠ│ųąīżšęįōī”Ž¾ĘĮĘ©║»öĄĄ─Š▀¾wČ©┴xŻ¼╝┤š{ė├╠ž╩Ōī”Ž¾į┌▒ŠĄžäōĮ©Ģr┬Ģ├„Ą─ĘĮĘ©╣”─▄ĪŻ
2Ż«Rhinoł╠ąąJavaScript─_▒ŠŲ¼Č╬
į┌░┤ššäėæBŠWĒō╝ė▌d▀^│╠Ēśą“ł╠ąąJavaScript─_▒ŠŲ¼Č╬▀^│╠ųąŻ¼─_▒ŠĮŌßīę²ŪµRhino▀ē▌ŗ╔Ž┐╔ęįĘų×ķŪ░Č╦Łh╣Ø║═║¾Č╦Łh╣Øā╔▓┐ĘųĪŻŪ░Č╦Łh╣ØĒśą“▀Mąąį~Ę©╝░šZĘ©Ęų╬÷Ż¼ŲõųąšZĘ©Ęų╬÷«a╔·šZĘ©śõŻ¼Ū░Č╦Łh╣Øš²╩Ū╗∙ė┌šZĘ©śõ╔·│╔ųąķg┤·┤aĪŻŪ░Č╦Łh╣Ø«a╔·Ą─ųąķg┤·┤aŠ═╩Ū║¾Č╦Łh╣ØąĶę¬ĮŌßīł╠ąąĄ──┐ś╦┤·┤aŻ¼║¾Č╦Łh╣Øī”ė┌ųąķg┤·┤aĮŌßīł╠ąąĄ─ūŅĮK▌ö│÷╩ŪJavaScript─_▒ŠŲ¼Č╬ī”æ¬Ą─ņoæBŠWĒōą┼ŽóĪŻ─_▒ŠŲ¼Č╬ūā┴┐ą┼ŽóĮyę╗┤µā”ė┌ėøõø▒Ē─ŻēKĄ─Ę¹╠¢▒ĒųąŻ¼│Ż┴┐ą┼Žó╝░ī”Ž¾ī┘ąį├¹ą┼Žó┤µā”ė┌ėøõø▒Ē─ŻēKĄ─│Ż┴┐▒ĒųąŻ¼ėøõø▒Ē─ŻēKž×┤®─_▒ŠŲ¼Č╬ĮŌßī╚½▀^│╠Ż¼╚ńłD2-15╦∙╩ŠĪŻ
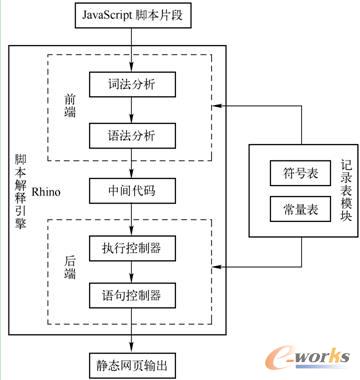
łD2-15 JavaScript─_▒ŠŲ¼Č╬į┌RhinoųąĄ─ł╠ąą▀^│╠
Rhino░┤šš╝ė▌d▀^│╠Ēśą“ł╠ąąJavaScriptäėæBŠWĒō─_▒ŠŲ¼Č╬║¾Ą─▌ö│÷Ż¼╩Ū─_▒ŠŲ¼Č╬╦∙ī”æ¬Ą─ņoæBŠWĒōą╬╩ĮĪŻį┌┤╦╗∙ĄA╔ŽŻ¼┐╔ęį└¹ė├é„ĮyĄ─HTMLś╦ėøŲź┼õĘĮĘ©Ż¼ę▓┐╔ęį═©▀^▒ķÜvņoæBŠWĒōĄ─HTML DOMśõŻ¼½@Ą├ņoæBŠWĒōų„¾wā╚╚▌Ż¼╠ß╚ĪŠWĒōā╚ŪČURLą┼Žó▓óų├╚ļ┤²½@╚ĪURLĻĀ┴ąŻ¼Å─Č°ūŅĮK═Ļ│╔JavaScriptäėæBŠWĒō░l▓╝ą┼ŽóĄ─½@╚Ī╣żū„ĪŻ
2.3.3 ╗∙ė┌×gė[Ų„─ŻöMīŹ¼FŠWĮj├Į¾wą┼Žó½@╚Ī
ų«Ū░ĮķĮBĄ─ŠWĮj├Į¾wą┼Žó½@╚ĪĘĮĘ©Ą─╝╝ągīŹ┘|Ż¼┐╔ęįĮyę╗Üwī┘ė┌▓╔ė├ŠWĮjĮ╗╗źųžśŗÖCųŲīŹ¼FŠWĮj├Į¾wą┼Žó½@╚ĪĪŻę╗ĘĮ├µŻ¼į┌├µŽ“ąĶę¬╔ĒĘ▌šJūCĄ─ņoæBŠWĒōīŹ¼F░l▓╝ą┼Žó½@╚Ī▀^│╠ųąŻ¼ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Ø═©▀^ŠWĮjĮ╗╗źųžśŗ═Ļš¹īŹ¼F╔ĒĘ▌šJūC▀^│╠┼cą┼ŽóšłŪ¾/Ēææ¬▀^│╠Ż╗┴Ēę╗ĘĮ├µŻ¼×ķ┴╦īŹ¼FäėæBŠWĒō░l▓╝ą┼ŽóĄ─½@╚ĪŻ¼į┌═©▀^ŠWĮjĮ╗╗źųžśŗ╚ĪĄ├äėæBŠWĒō░l▓╝ā╚╚▌║¾Ż¼╩ūŽ╚ąĶę¬╗∙ė┌¬Ü┴óĮŌßīę²ŪµīŹ¼FäėæB─_▒ŠŲ¼Č╬ĮŌ╬÷Ż¼½@Ą├äėæBŠWĒō╦∙ī”æ¬Ą─ņoæBŠWĒōą╬æBŻ¼▀MČ°└^└m▓╔ė├ŠWĮjĮ╗╗źųžśŗÖCųŲīŹ¼FņoæBŠWĒōų„¾wā╚╚▌┼cā╚ŪČURL░l▓╝ą┼ŽóĄ─½@╚ĪĪŻ
ŠWĮjĮ╗╗źųžśŗÖCųŲ╩ŪŠWĮj├Į¾wą┼Žó½@╚ĪĄ─ę╗░ŃąįĘĮĘ©Ż¼Å─└Ēšō╔ŽųvŻ¼ų╗꬚Ų╬šŠWĮj═©ą┼ģfūhĄ─ą┼ŽóĮ╗╗ź▀^│╠Ż¼Š═┐╔ęį═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼Fī”æ¬ģfūh░l▓╝ą┼Žó½@╚ĪĪŻĄ½╩ŪŻ¼ļSų°ŠWĮjæ¬ė├Ą─ų▓Į╔Ņ╚ļĪóŠWĮj├Į¾w░l▓╝ą╬æBĄ─▓╗öÓ═ŲĻÉ│÷ą┬Ż¼▓╗═¼ŠWĮj├Į¾wą┼ŽóĮ╗╗ź▀^│╠┤µį┌ų°śO┤¾▓ŅäeĪŻ═¼ĢrŻ¼ą┬ą═ŠWĮj═©ą┼ģfūhš²į┌▓╗öÓĄ├ĄĮæ¬ė├Ż¼Č°▓┐ĘųŠWĮj═©ą┼ģfūhŻ¼ė╚Ųõ╩ŪęĢ/ę¶Ņlą┼ŽóĄ─ŠWĮjĮ╗╗ź▀^│╠▓ó╬┤ī”═Ō╣½ķ_░l▓╝ĪŻ
ę“┤╦Ż¼į┌═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼FŠWĮj├Į¾wą┼Žó½@╚Ī▀^│╠ųąŻ¼ąĶę¬ī”▓╗═¼ŠWĮj├Į¾wųę╗▀MąąŠWĮją┼ŽóĮ╗╗źųžśŗŻ¼Ųõą┼Žó½@╚Ī╝╝ągīŹ¼FĄ─╣żū„┴┐«É│Ż²ŗ┤¾ĪŻ┼c┤╦═¼ĢrŻ¼ī”ė┌ŠWĮjĮ╗╗ź▀^│╠╔ą╠Äė┌▒Ż├▄ļAČ╬Ą─▓┐ĘųŠWĮj═©ą┼ģfūhČ°čįŻ¼¤oĘ©ų▒Įė═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼Fī”æ¬ģfūh░l▓╝ą┼Žó½@╚ĪĪŻ
š²╩Ūė╔ė┌═©▀^ŠWĮjĮ╗╗źųžśŗÖCųŲīŹ¼F├Į¾wą┼Žó½@╚Ī┤µį┌ŽÓ«ö│╠Č╚Ą─╝╝ągŠųŽ▐ąįŻ¼į┌WebŠWšŠūįäė╗»╣”─▄/ąį─▄£yįćĄ─åó░lŽ┬Ż¼×gė[Ų„─ŻöM╝╝ągį┌ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Øš²Ą├ĄĮįĮüĒįĮÅVĘ║Ą─æ¬ė├ĪŻ╗∙ė┌×gė[Ų„─ŻöMīŹ¼FŠWĮj├Į¾w░l▓╝ą┼Žó½@╚ĪĄ─╝╝ągŻ¼īŹ¼F▀^│╠╩Ū└¹ė├Ąõą═Ą─JSSh┐═æ¶Č╦Ž“ā╚ŪČJSShĘ■äšŲ„Ą─ŠWĮj×gė[Ų„░l╦═JavaScriptųĖ┴ŅŻ¼ųĖ╩ŠŠWĮj×gė[Ų„ķ_š╣ŠWĒō▒Ēå╬ūįäė╠ŅīæĪóŠWĒō░┤Ōo/µ£Įė▒╗³cō¶ĪóŠWĮj╔ĒĘ▌šJūCĮ╗╗źĪóŠW░l▓╝Ēōą┼Žó×gė[Ż¼ęį╝░ęĢ/ę¶Ņlą┼Žó³c▓źĄ╚ŽĄ┴ą▓┘ū„ĪŻ
į┌┤╦╗∙ĄA╔ŽŻ¼JSSh┐═æ¶Č╦▀Mę╗▓Įę¬Ū¾ŠWĮj×gė[Ų„ī¦│÷ŠWĒō╬─▒Šā╚╚▌Īó┤µā”ŠWĒōłDŽ±ą┼ŽóŻ¼╗“į┌ė├ė┌ą┼Žó½@╚ĪĄ─ėŗ╦ŃÖC╔Žī”š²į┌▓źĘ┼Ą─ęĢ/ę¶Ņlą┼Žó▀MąąŲ┴─╗õøŽ±Ż¼ūŅĮK├µŽ“Ė„ĘNŅÉą═Ą─ŠWĮjā╚╚▌ĪóĖ„ĘNą╬æBĄ─ŠWĮj├Į¾wīŹ¼F░l▓╝ą┼Žó½@╚ĪŻ¼╚ńłD2-16╦∙╩ŠĪŻ
łD2-16 ╗∙ė┌×gė[Ų„─ŻöMīŹ¼FŠWĮj├Į¾wą┼Žó½@╚Ī
1Ż«ā╚ŪČJSShĘ■äšŲ„Ą─Firefox×gė[Ų„
Mozilla Firefoxī┘ė┌Ąõą═Ą─ā╚ŪČJSShĘ■äšŲ„Ą─ķ_į┤×gė[Ų„Ż¼╦³īóJSShĘ■äšŲ„ū„×ķūį╔ĒĄ─ĖĮ╝ėĮM╝■ĪŻ═Ō▓┐æ¬ė├│╠ą“Ī¬Ī¬JSSh┐═æ¶Č╦┐╔┼cFirefox×gė[Ų„ā╚ŪČĄ─JSShĘ■äšŲ„Ż©─¼šJé╔┬Ā9997Č╦┐┌Ż®Į©┴ó═©ą┼▀BĮėŻ¼▓óŽ“Ųõ░l╦═JavaScriptųĖ┴ŅŻ¼ųĖ╩ŠFirefox▓┘ū„«öŪ░ŠWĒōĄ─╬─Önī”Ž¾Ż¼╚ńłD2-17╦∙╩ŠĪŻā╚ŪČJSShĘ■äšŲ„Ą─FirefoxĒśą“ł╠ąąüĒūįJSSh┐═æ¶Č╦Ą─JavaScriptųĖ┴ŅŻ¼Ųõš¹¾w▀^│╠┼cFirefoxĮŌ╬÷äėæBŠWĒōā╚Ą─JavaScript─_▒ŠŲ¼Č╬ŅÉ╦ŲĪŻ
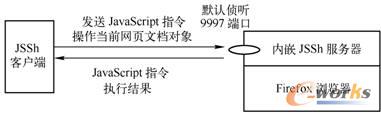
łD2-17 JSShĘ■äšŲ„┼c┐═æ¶Č╦ķgĄ─JavaScriptųĖ┴ŅĮ╗╗ź
2Ż«Ąõą═JSSh┐═æ¶Č╦Ī¬Ī¬FireWatir
ū„×ķĄõą═Ą─JSSh┐═æ¶Č╦Ż¼FireWatirÅVĘ║æ¬ė├ė┌WebŠWšŠ╣”─▄║═ąį─▄ūįäė╗»£yįćĪŻFireWatir╩Ū╗∙ė┌─_▒ŠšZčįRubyŠÄīæĄ─Ż¼┐╔═©▀^░l╦═JavaScriptųĖ┴ŅŻ¼ųĖ╩Šā╚ŪČJSSh Ę■äšŲ„Ą─ŠWĮj×gė[Ų„Ż©└²╚ńMozilla FirefoxŻ®▀MąąŠWĒō▒Ēå╬╠ŅīæĪó░┤Ōo/µ£Įė³cō¶Ż¼ęį╝░ŠWĒōā╚╚▌×gė[Ą╚ŽĄ┴ą▓┘ū„ĪŻ┴Ē═ŌŻ¼FireWatir═©▀^JavaScriptųĖ┴Ņ▀Ć┐╔ęįĘĮ▒ŃĄž▓┘┐v×gė[Ų„╝ė▌dŠWĒōĄ─DOMī”Ž¾Ż¼Å─Č°ī¦│÷ŠWĒōų„¾wā╚╚▌Ż¼īŹ¼FŠWĮj├Į¾wą┼ŽóĄ─½@╚ĪĪŻ
Ż©1Ż®╗∙ė┌×gė[Ų„─ŻöMīŹ¼F╔ĒĘ▌šJūC┼cŠWšŠą┼Žó▓╔╝»
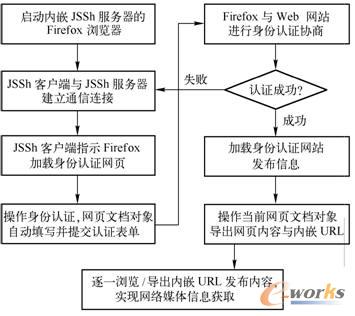
«öŪ░WebŠWšŠų„ę¬═©▀^╠Ņīæ▓ó╠ßĮ╗HTTPŠWĒō╔ŽĄ─šJūC▒Ēå╬Ż¼īŹ¼FŠWĮj┐═æ¶Č╦╔ĒĘ▌šJūCĪŻę“┤╦Ż¼ŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Ø┐╔ęį═©▀^JSSh┐═æ¶Č╦Ž“ā╚ŪČJSShĘ■äšŲ„Ą─Firefox×gė[Ų„░l╦═JavaScriptųĖ┴ŅŻ¼ųĖ╩Š×gė[Ų„ūįäė╠ŅīæŠWĒō╔ŽĄ─╔ĒĘ▌šJūC▒Ēå╬Ż¼▓ó³cō¶ŽÓæ¬░┤Ōo╠ßĮ╗╔ĒĘ▌šJūCšłŪ¾ĪŻ╔ĒĘ▌šJūCģf╔╠▀^│╠╝┤╔ĒĘ▌šJūCŠWĮjĮ╗╗ź▀^│╠Ż¼╩Ūė╔×gė[Ų„ūįąą╠Ä└ĒĄ─Ż¼š¹éĆ▀^│╠╚ń═¼š²į┌×gė[ŠWĮjĄ─ė├æ¶┼cWebŠWšŠ▀Mąą╔ĒĘ▌šJūCŠWĮjĮ╗╗źĪŻ
į┌╔ĒĘ▌šJūC│╔╣”║¾Ż¼JSSh┐═æ¶Č╦└^└mŽ“ā╚ŪČJSShĘ■äšŲ„░l╦═JavaScriptųĖ┴ŅŻ¼ųĖ╩Š×gė[Ų„╝ė▌d╔ĒĘ▌šJūCŠWšŠ░l▓╝ą┼ŽóĪŻ×gė[Ų„ūįąą═Ļ│╔ė├ė┌░l▓╝ą┼ŽóšłŪ¾Ą─ŠWĮjĮ╗╗źŻ¼▓óĖµų¬JSSh┐═æ¶Č╦ŠWšŠ░l▓╝Ēō├µ╝ė▌d═Ļ│╔ĪŻį┌┤╦╗∙ĄA╔ŽŻ¼JSSh┐═æ¶Č╦ųĖ╩Š×gė[Ų„ī¦│÷«öŪ░╝ė▌dŠWĒōų„¾wā╚╚▌Ż¼▓óī”ŠWĒōā╚ŪČURLųę╗▀Mąą³cō¶×gė[┼cā╚╚▌ī¦│÷Ż¼ūŅĮK═Ļ│╔ī”ė┌╔ĒĘ▌šJūCŠWšŠ░l▓╝ą┼ŽóĄ─½@╚Ī╣żū„ĪŻ
1Ż®╔ĒĘ▌šJūC▒Ēå╬ūįäė╠ŅīæĪŻį┌īŹ¼FHTTPšJūCŠWĒō╔ĒĘ▌šJūC▒Ēå╬Ą─ūįäė╠ŅīæŪ░Ż¼╩ūŽ╚ąĶę¬ūRäe╔ĒĘ▌šJūC▒Ēå╬į¬╦žŻ¼╝┤╔ĒĘ▌šJūC▒Ēå╬╦∙╔µ╝░Ą─HTTPī”Ž¾Ī¬Ī¬ė├ė┌ė├æ¶├¹Īó├▄┤aą┼Žó▌ö╚ļĄ─╬─▒Š┐“ī”Ž¾ŅÉą═┼cī”Ž¾├¹ĘQĪŻį┌┤╦╗∙ĄA╔ŽŻ¼┐╔ęį╩╣ė├ęčį┌─┐ś╦├Į¾w╔Ž╔ĻšłĄ├ĄĮĄ─ė├æ¶├¹Īó├▄┤aą┼ŽóŻ¼Ė∙ō■─_▒ŠšZčįRubyĄ─šZĘ©Ė±╩ĮŻ¼śŗĮ©▓óŽ“JSShĘ■äšŲ„░l╦═ė├ė┌╔ĒĘ▌šJūC▒Ēå╬ūįäė╠ŅīæĄ─JavaScriptųĖ┴ŅŻ¼ųĖ╩Šā╚ŪČJSShĘ■äšŲ„Ą─ŠWĮj×gė[Ų„Ż¼Å─Č°═Ļ│╔╔ĒĘ▌šJūC▒Ēå╬Ą─ūįäė╠ŅīæĪŻ
į┌╗∙ė┌×gė[Ų„─ŻöMīŹ¼F╔ĒĘ▌šJūC▒Ēå╬ūįäė╠ŅīæĄ─╝╝ągīŹ¼F▀^│╠ųąŻ¼ų╗ąĶĖ∙ō■▓╗═¼ŠWĮj├Į¾wšJūC▒Ēå╬į¬╦žĄ─ģ^äeŻ¼śŗĮ©ė├ė┌šJūC▒Ēå╬ūįäė╠ŅīæĄ─JavaScriptųĖ┴Ņ╝┤┐╔ĪŻį┌ųĖ╩ŠŠWĮj×gė[Ų„═Ļ│╔šJūC▒Ēå╬ūįäė╠Ņīæ║¾Ż¼╔ĒĘ▌šJūCŠWĮjĮ╗╗ź▀^│╠╚½▓┐ė╔×gė[Ų„ūįąą═Ļ│╔ĪŻ▀@┼c═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼F╔ĒĘ▌šJūC┼cŠWšŠ░l▓╝ą┼Žó½@╚ĪŲ┌ķgŻ¼ąĶę¬ßśī”▓╗═¼ŠWĮj├Į¾wųžśŗ╝░▓╗═¼ŠWĮjĮ╗╗ź▀^│╠ŽÓ▒╚Ż¼╣”─▄īŹ¼FĄ─Å═ļsČ╚’@ų°ĮĄĄ═Ż¼╝╝ągĘĮ░ĖĄ─Ųš▀mąį├„’@╠ßĖ▀ĪŻ
2Ż®╔ĒĘ▌šJūCģf╔╠┼c░l▓╝ą┼Žó½@╚ĪĪŻį┌JSSh┐═æ¶Č╦═Ļ│╔╔ĒĘ▌šJūC▒Ēå╬ūįäė╠Ņīæ┼c╠ßĮ╗║¾Ż¼ŠWĮj×gė[Ų„▐DŽ“┼cWebŠWšŠ▀Mąą╔ĒĘ▌šJūCģf╔╠Ż¼▀@Ų┌ķg▓╗į┘ąĶę¬JSSh┐═æ¶Č╦└^└mģó┼cĪŻį┌×gė[Ų„│╔╣”═Ļ│╔ŠWĮj╔ĒĘ▌šJūC║¾Ż¼JSSh┐═æ¶Č╦└^└mųĖ╩ŠJSShĘ■äšŲ„╝ė▌d╔ĒĘ▌šJūC┼cŠWšŠ░l▓╝ą┼ŽóŻ¼▓ó▀Mę╗▓Į═©▀^JavaScriptųĖ┴Ņ▓┘ū„╦∙╝ė▌dŠWĒōĄ─╬─Önī”Ž¾Ż¼╠ß╚ĪŠWĒōų„¾wā╚╚▌┼cŠWĒōā╚ŪČURLą┼ŽóĪŻā╚ŪČJSShĘ■äšŲ„Ą─×gė[Ų„į┌JSSh┐═æ¶Č╦Ą─ųĖ╩ŠŽ┬Ż¼ųę╗×gė[▓óī¦│÷«öŪ░ŠWĒōā╚ŪČURL╦∙ī”æ¬Ą─ŠWĒōų„¾wā╚╚▌Ż¼ūŅĮK═Ļ│╔╔ĒĘ▌šJūCŠWšŠ░l▓╝ą┼Žó½@╚Ī╣żū„Ż¼╚ńłD2-18╦∙╩ŠĪŻ
Ż©2Ż®╗∙ė┌×gė[Ų„─ŻöMīŹ¼FäėæBŠWĒōą┼Žó½@╚Ī
▓╔ė├×gė[Ų„─ŻöM╝╝ąg▀MąąäėæBŠWĒō░l▓╝ą┼Žó½@╚ĪŻ¼╩ūŽ╚ąĶę¬ė╔JSSh┐═æ¶Č╦═©▀^JavaScriptųĖ┴ŅŻ¼ųĖ╩Šā╚ŪČJSShĘ■äšŲ„Ą─ŠWĮj×gė[Ų„╝ė▌däėæBŠWĒō░l▓╝ą┼ŽóĪŻį┌½@Ą├ŠWĮj├Į¾wĻPė┌äėæBŠWĒōĄ─Ēææ¬ą┼Žó║¾Ż¼×gė[Ų„ūįäė═Ļ│╔ī”ė┌äėæBŠWĒōā╚Ė„ŅÉ─_▒ŠŲ¼Č╬Ą─ĮŌ╬÷╣żū„Ż¼Å─Č°½@Ą├äėæBŠWĒō╦∙ī”æ¬Ą─ņoæBŠWĒōą╬æBĪŻįōļAČ╬▓╗į┘ų╗╩Ūßśī”Š▀¾wĄ──_▒ŠšZčįŻ©└²╚ńJavaScriptŻ®▀MąąäėæB─_▒ŠŲ¼Č╬ĮŌ╬÷ĪŻĘ▓╩Ū─▄į┌═©ė├×gė[Ų„ųąš²│Ż×gė[Ą─äėæBŠWĒōŻ¼Ųõ░³║¼Ą─╚╬║╬─_▒ŠŲ¼Č╬Č╝┐╔ęį╗∙ė┌×gė[Ų„─ŻöM╝╝ągīŹ¼FäėæB─_▒ŠĮŌ╬÷ĪŻ
łD2-18 ╗∙ė┌×gė[Ų„─ŻöMīŹ¼F╔ĒĘ▌šJūCģf╔╠┼c░l▓╝ą┼Žó½@╚Ī
į┌┤╦╗∙ĄA╔ŽŻ¼×gė[Ų„▀Mę╗▓Į═©▀^ūį╔Ē░³║¼Ą─ŠWĒō┼┼░µę²ŪµGeckoŻ¼╔·│╔ņoæBŠWĒōĄ─HTML DOMśõĪŻ╚╗║¾JSSh┐═æ¶Č╦┐╔ęį═©▀^JavaScriptųĖ┴Ņ▓┘ū„ņoæBŠWĒōĄ─HTML DOMśõŻ¼ųę╗ī¦│÷ņoæBŠWĒō╝░Ųõā╚ŪČURL╦∙ī”æ¬Ą─░l▓╝ā╚╚▌Ż¼ūŅĮK═Ļ│╔äėæBŠWĒō░l▓╝ą┼ŽóĄ─½@╚Ī╣żū„Ż¼╚ńłD2-19╦∙╩ŠĪŻ
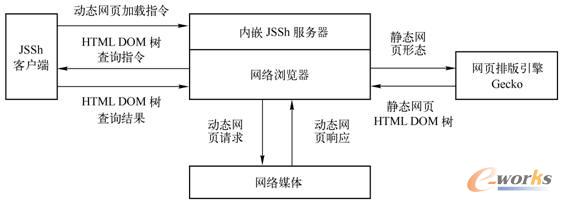
łD2-19 ╗∙ė┌×gė[Ų„─ŻöMīŹ¼FäėæBŠWĒō░l▓╝ą┼ŽóĄ─½@╚Ī
į┌═©▀^RhinoīŹ¼FJavaScriptäėæBŠWĒō░l▓╝ą┼ŽóĄ─½@╚ĪĢrŻ¼╩ūŽ╚ąĶę¬╗∙ė┌ŠWĮjĮ╗╗źųžśŗ½@╚ĪäėæBŠWĒō░l▓╝ā╚╚▌Ż¼▓ó▀Mę╗▓Į▒ķÜväėæBŠWĒōHTML DOMśõŻ¼╠ß╚ĪŠWĒō╦∙║¼JavaScript─_▒ŠŲ¼Č╬ĪŻį┌ī”JavaScript─_▒ŠŲ¼Č╬ųąĄ─HTML DOMī”Ž¾īŹ¼F▒ŠĄžäōĮ©║¾Ż¼ Rhino░┤ššäėæBŠWĒō╝ė▌d▀^│╠Ēśą“ł╠ąąJavaScript─_▒ŠŲ¼Č╬Ż¼╚╗║¾▌ö│÷äėæBŠWĒō╦∙ī”æ¬Ą─ņoæBŠWĒōą╬æBŻ¼ūŅĮKīŹ¼FäėæB─_▒ŠĮŌ╬÷ĪŻ
┼cŲõī”æ¬Ż¼į┌╗∙ė┌×gė[Ų„─ŻöMīŹ¼FäėæBŠWĒōą┼Žó½@╚Ī▀^│╠ųąŻ¼äėæBŠWĒō░l▓╝ā╚╚▌½@╚Ī┼cäėæBŠWĒō─_▒ŠŲ¼Č╬ĮŌ╬÷╣żū„╚½ė╔×gė[Ų„ūįąą═Ļ│╔ĪŻJSSh┐═æ¶Č╦ų╗╩Ū═©▀^JavaScriptųĖ┴ŅųĖ╩ŠŠWĮj×gė[Ų„╝ė▌däėæBŠWĒōŻ¼▓óį┌JSShĘ■äšŲ„Ėµų¬┼c╦∙šłŪ¾Ą─äėæBŠWĒōī”æ¬Ą─ņoæBŠWĒōą╬æB╝ė▌d│╔╣”║¾Ż¼└^└m═©▀^JavaScriptųĖ┴Ņ▓┘ū„«öŪ░ŠWĒōHTML DOMśõ½@╚ĪäėæBŠWĒō░l▓╝ą┼ŽóĪŻš¹¾w▀^│╠┼cJSSh┐═æ¶Č╦ųĖ╩Š×gė[Ų„╝ė▌dņoæBŠWĒōŻ¼▓ó¤oīŹ┘|ģ^äeĪŻ
Ż©3Ż®└¹ė├×gė[Ų„─ŻöM▀MąąŠWĮj├Į¾wą┼Žó½@╚ĪĄ─╝╝ągā×ä▌
ę╗ĘĮ├µŻ¼┼c═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼FŠWĮj├Į¾wą┼Žó½@╚Ī▓╗═¼Ż¼į┌╗∙ė┌×gė[Ų„─ŻöM▀MąąŠWĮj├Į¾wą┼Žó½@╚Ī▀^│╠ųąŻ¼┼c╔ĒĘ▌šJūCĪóą┼ŽóšłŪ¾ŽÓĻPĄ─ŠWĮjĮ╗╗ź▀^│╠Ż¼┼c─_▒ŠĮŌ╬÷ĪóHTML DOMśõ╔·│╔ŽÓĻPĄ─ŠWĒō╠Ä└Ē▀^│╠Ż¼╚½Č╝╩Ūį┌JSSh┐═æ¶Č╦Ą─ųĖ╩ŠŽ┬Ż¼ė╔ā╚ŪČJSShĘ■äšŲ„Ą─ŠWĮj×gė[Ų„ūįąą═Ļ│╔ĪŻŠWĮj├Į¾wą┼Žó½@╚ĪŁh╣Ø▓╗į┘ąĶę¬ßśī”▓╗═¼ŠWĮj├Į¾wŻ¼ųžÅ═īŹ¼FŠWĮjĮ╗╗źųžśŗÖCųŲŻ¼Å─Č°ėąą¦ĮĄĄ═┴╦ŠWĮj├Į¾wą┼Žó½@╚Ī╣żū„Ą─Å═ļsČ╚Ż¼’@ų°╠ßĖ▀┴╦ŠWĮj├Į¾wą┼Žó½@╚ĪÖCųŲĄ─Ųš▀mąįĪŻ
┴Ēę╗ĘĮ├µŻ¼į┌├µī”ŠWĮjĮ╗╗ź▀^│╠śO×ķÅ═ļsŻ¼╔§ų┴ŠWĮjĮ╗╗źĘĮ╩Į▓ó╬┤ī”═Ō╣½ķ_Ą─ęĢ/ę¶Ņlą┼ŽóĢrŻ¼┐╔ęį╗∙ė┌×gė[Ų„─ŻöMÖCųŲīŹ¼FęĢ/ę¶Ņlā╚╚▌ūįäė³c▓źŻ¼▓óī”š²į┌▓źĘ┼Ą─ęĢ/ę¶Ņl┴„▀MąąŲ┴─╗õøŽ±Ż¼ūŅĮK═Ļ│╔ęĢ/ę¶Ņlą┼ŽóĄ─Įyę╗½@╚ĪĪŻį┌▀@ĘNŪķørŽ┬Ż¼╦∙ėą─▄ē“═©▀^ŠWĮj×gė[Ų„Ą├ĄĮĄ─Ż¼Ė„ĘNą╬æBĪóĖ„éĆŅÉą═Ą─╗ź┬ōŠWą┼ŽóŻ¼Č╝┐╔ęį▓╔ė├×gė[Ų„─ŻöM╝╝ągīŹ¼FŠWĮj├Į¾w░l▓╝ą┼ŽóĄ─½@╚ĪŻ¼▀@ę▓╩Ū▒ŠĢ°īó▀@ŅÉ╗ź┬ōŠW╣½ķ_é„▓źą┼ŽóĮyĘQ×ķŠWĮj├Į¾wą┼ŽóĄ─Ė∙▒ŠįŁę“ĪŻ
2.4 ŠWĮj═©ą┼ą┼Žó½@╚ĪĘĮ░Ė
╩╣ė├╠žČ©┐═æ¶Č╦▀MąąŠWĮj═©ą┼Ģr╦∙é„▌öĄ─╗ź┬ōŠWą┼Žóī┘ė┌ŠWĮj═©ą┼ą┼ŽóŻ¼▀@ŅÉą┼Žó░³║¼╩╣ė├┐═æ¶Č╦▄ø╝■Ż©└²╚ńŻ¼Microsoft OutlookĪóFoxMailĄ╚Ż®╩š░lļŖūėÓ]╝■Ż¼╗∙ė┌╝┤Ģr═©ą┼▄ø╝■▀MąąŠW╔Ž┴─╠ņŻ¼▓╔ė├Į╚┌ÖCśŗ░l▓╝Ą─┐═æ¶Č╦▀MąąŠW╔ŽžöĮøĮ╗ęūĄ╚ĪŻ┼cŠWĮj├Į¾węįÅV▓źĘĮ╩ĮŽ“╗ź┬ōŠW┐═æ¶Č╦é„▓źą┼Žó▓╗═¼Ż¼ČÓöĄŠWĮj═©ą┼┐═æ¶Č╦ęįī”Ą╚Ą─Īó³cī”³cĄ─ĘĮ╩Į▀Mąą╗ź┬ōŠW═©ą┼Į╗╗źĪŻę“┤╦į┌├µŽ“ŠWĮj═©ą┼ą┼Žó▀Mąą╗ź┬ōŠWĮ╗╗źā╚╚▌½@╚ĪĢrŻ¼¤oĘ©ų▒ĮėĮĶĶbų«Ū░╠ߥĮĄ─ŠWĮj├Į¾wą┼Žó½@╚ĪĘĮĘ©Ż¼▀MąąŠWĮj═©ą┼ą┼Žó½@╚ĪĪŻ
«öŪ░ŠWĮj═©ą┼ą┼Žó½@╚Ī▀^│╠ų„ę¬╔µ╝░ŠWĮj═©ą┼ą┼ŽóńRŽ±ĪóŠWĮjĮ╗╗źöĄō■ųžĮMĪó═©ą┼ģfūhöĄō■╗ųÅ═ĪóŠWĮj═©ą┼ą┼Žó┤µā”Ą╚╝╝ągŁh╣ØĪŻŠWĮj═©ą┼ą┼Žó½@╚Īų„ę¬═©▀^Šųė“ŠW┐éŠĆöĄō■é╔┬ĀŻ¼│Ūė“ŠWŻ©└²╚ńöĄūų╔ńģ^Ż¼ōĒėą╗ź┬ōŠWĮė╚ļĄ─╣½įóģ^Ą╚Ż®╚²īėĮ╗ōQÖC═©ą┼Č╦┐┌öĄō■ī¦│÷Ą─ĘĮ╩ĮŻ¼īŹ¼F░³║¼ŠWĮj═©ą┼ą┼Žóį┌ā╚Ą─╗ź┬ōŠWĮ╗╗źöĄō■ńRŽ±ĪŻ
į┌┤╦╗∙ĄA╔ŽŻ¼ŠWĮj═©ą┼ą┼Žó½@╚ĪÖCųŲ▀xō±į┌OSI/RMŠWĮjīėßśī”Š▀¾wĄ─╗ź┬ōŠW┐═æ¶Č╦Ż¼īŹ¼F╠žČ©ģfūhĄ─ŠWĮj═©ą┼öĄō■░³ųžĮMĪŻī”ė┌├„╬─é„▌öŪę╣½ķ_░l▓╝ģfūhĮ╗╗ź▀^│╠Ą─ŠWĮj═©ą┼ģfūhŻ¼ą┼Žó½@╚ĪÖCųŲ═©▀^ģfūhöĄō■╗ųÅ═½@Ą├═©ą┼Į╗╗źā╚╚▌Ż¼▓óīóŲõ┤µ╚ļŠWĮj═©ą┼ą┼ŽóÄņŻ¼īŹ¼FŠWĮj═©ą┼ą┼Žó½@╚ĪŻ¼╚ńłD2-20╦∙╩ŠĪŻ▓╗▀^Ż¼į┌ŠWĮj═©ą┼ą┼Žó═©▀^├▄╬─é„▌öĄ─ŪķørŽ┬Ż¼╗“š▀▓┐ĘųŠWĮj═©ą┼ģfūh╔ą╬┤╣½ķ_ģfūhĮ╗╗ź▀^│╠ĢrŻ¼ŠWĮją┼Žó½@╚ĪŁh╣ؤoĘ©═©▀^ģfūhöĄō■╗ųÅ═½@Ą├ŠWĮj═©ą┼ą┼ŽóĪŻ
ąĶę¬╠žäešf├„Ą─╩ŪŻ¼į┌╩╣ė├╠žČ©┐═æ¶Č╦▀MąąŠWĮj═©ą┼Į╗╗źĢrŻ¼╦∙é„▌öĄ─ŠWĮją┼Žó▓ó▓╗╦Ń╩Ū╗ź┬ōŠW╣½ķ_é„▓źą┼ŽóĪŻę“┤╦į┌ø]ėąĄ├ĄĮŠWĮj═©ą┼«ö╩┬╚╦╗“ŠWĮj▒O╣▄▓┐ķT╩┌ÖÓĄ─ŪķørŽ┬Ż¼▒ŠĢ°▓ó▓╗Į©ūh├µŽ“ī┘ė┌éĆ╚╦ļ[╦ĮĘČ«ĀĄ─ŠWĮj═©ą┼ą┼Žó▀Mąąā╚╚▌ńRŽ±┼cą┼Žó½@╚ĪćLįćĪŻ
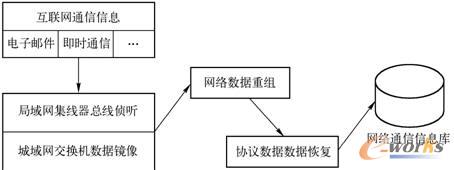
łD2-20 ŠWĮj═©ą┼ą┼Žó½@╚Ī┴„│╠
2.5 ▒Šš┬ąĪĮY
ļSų°ŠWĮj╗∙ĄAĮ©įO▓╗öÓ╔Ņ╚ļĪóŠWĮj═©ą┼æ¬ė├▓╗öÓŲš╝░Ż¼╗ź┬ōŠWęčĮø│╔×ķ└^ł¾╝łĪóÅV▓ź┼cļŖęĢ├Į¾węį║¾Ą─Ą┌4┤¾ą┼Žó░l▓╝ŲĮ┼_ĪŻš²╩Ūė╔ė┌▀@ę╗įŁę“Ż¼▒Š╣Øį┌ųvĮŌą┼Žóā╚╚▌Ą─½@╚ĪĢrŻ¼▀xō±ęį╗ź┬ōŠWé„▓źą┼Žóū„×ķā╚╚▌½@╚ĪĄ─╣żū„ī”Ž¾ĪŻĖ∙ō■╗ź┬ōŠWé„▓źą┼Žó╩Ūʱ┐╔ęį╩╣ė├═©ė├ŠWĮj×gė[Ų„ų▒Įė½@Ą├Ż¼▒Šš┬īó╗ź┬ōŠWą┼ŽóĘų│╔ŠWĮj├Į¾wą┼Žó┼cŠWĮj═©ą┼ą┼Žóā╔┤¾ŅÉą═ĪŻ
į┌┤╦╗∙ĄA╔ŽŻ¼▒Š╣Øų„ę¬ßśī”ŠWĮj├Į¾wą┼Žó▀Mąąā╚╚▌½@╚ĪĄ─ę╗░ŃąįįŁ└ĒĮķĮBŻ¼▓óųvĮŌ═©▀^ŠWĮjĮ╗╗źųžśŗīŹ¼FąĶę¬╔ĒĘ▌šJūCĄ─ņoæBŠWĮj├Į¾wą┼Žó½@╚ĪĄ─ĘĮĘ©Ż╗╗∙ė┌─_▒ŠĮŌßīę²ŪµīŹ¼FäėæBŠWĒō░l▓╝ą┼Žó½@╚ĪĄ─ĘĮĘ©Ż¼ęį╝░└¹ė├×gė[Ų„─ŻöM╝╝ągī”Ė„ŅÉŠWĮj├Į¾wą┼ŽóĮyę╗Ż¼īŹ¼Fą┼Žó½@╚ĪĄ─Š▀¾w▐kĘ©ĪŻ│÷ė┌š┬╣Øöó╩÷ā╚╚▌Ą─╚½├µąį┐╝æ]Ż¼▒Šš┬ūŅ║¾▀Ćī”ė┌▓ó▓╗ī┘ė┌╣½ķ_é„▓źĘČ«ĀĄ─ŠWĮj═©ą┼ą┼Žó▀Mąą┴╦║åę¬ā╚╚▌½@╚ĪĘĮ░ĖĮķĮBĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ą┼Žóā╚╚▌░▓╚½╣▄└Ē╝░æ¬ė├Ż©Č■Ż®
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112155106.html






















