



į┌┤¾ęÄ─Ż╬─╝■ŽĄĮyųąŻ¼┤¾ČÓöĄ╬─╝■ķLŲ┌▓╗ė├Ż¼╔┘öĄ╬─╝■Įø│Ż╩╣ė├Ż¼Š═å╬éĆ╬─╝■üĒšfŻ¼äéäōĮ©ų«║¾Ą─ę╗Č╬Ģrķgā╚įLå¢Ņl┬╩ūŅĖ▀Ż╗ļSų°Ģrķg═ŲęŲŻ¼įLå¢Ņl┬╩Ž┬ĮĄŻ¼Ķbė┌▓╗═¼öĄō■ų«ķg┤µį┌ų°’@ų°Ą─įLå¢Ņl┬╩▓Ņ«ÉŻ¼╚╦éā╠ß│÷┴╦Ęų╝ē┤µā”ŽĄĮyŻ¼╦³ė╔Š▀ėą▓╗═¼Ą─┤µā”╚▌┴┐ĪóIŻ»O╦┘Č╚Īóå╬╬╗ārĖ±Ą─ČÓ╝ē┤µā”įOéõśŗ│╔Ż╗░┤ššĮ³Ų┌įLå¢ŪķørĄ─▓╗═¼Ż¼īóöĄō■┤µĘ┼ĄĮ║Ž▀mĄ─┤µā”įOéõ╔ŽŻ¼─┐ś╦╩Ūį┌ØMūŃ┤µā”╚▌┴┐║═ė▓╝■│╔▒Š╝s╩°Ą─Ū░╠ߎ┬Ż¼╠ß╣®▌^Ė▀Ą─IŻ»Oąį─▄ĪŻ
į┌Ęų╝ē┤µā”ŽĄĮyųąŻ¼öĄō■Ą─įLå¢Ņl┬╩║═Ę■äš┘|┴┐ąĶŪ¾╩Ū▓╗öÓūā╗»Ą─Ż¼×ķ┴╦╩╣öĄō■─▄ē“┼c┤µā”įOéõäėæBŲź┼õŻ¼ąĶę¬į┌▓╗═¼╝ēäeĄ─┤µā”įOéõų«ķg▀węŲöĄō■Ż¼öĄō■▀węŲĄ─ęÄät═©│Żė╔öĄō■Ą─įLå¢Ņl┬╩Īó┤µā”įOéõĄ─╚▌┴┐║═ąį─▄Ą╚ę“╦ž┤_Č©Ż¼▀@Š═ę¬Ū¾Ęų╝ē┤µā”ŽĄĮy─▄ē“Öz£yĄĮöĄō■ĀŅæBĄ─ūā╗»Ż¼▓ó▀MąąöĄō■į┌ŠĆ▀węŲŻ¼═¼ĢrŻ¼öĄō■╬╗ų├Ą─ęŲäėąĶę¬ī”æ¬ė├╩Ū═Ė├„Ą─Ż¼öĄō■▀węŲ▀^│╠ī”ė┌æ¬ė├IŻ»Oąį─▄ė░Ēæ▓╗┤¾ĪŻ
¼FėąĄ─Ęų╝ē┤µā”ŽĄĮyųąĄ─öĄō■▀węŲĘĮĘ©ī”Ū░┼_IŻ»Oąį─▄ė░Ēæ▌^┤¾Ż¼įŁę“░³└©öĄō■Ęų╝ēų╗┐╝æ]╬─╝■Ą─äōĮ©ĢrķgĪó╔Ž┤╬įLå¢Ģrķg╗“╬─╝■┤¾ąĪĄ╚å╬ę╗ę“╦žŻ╗öĄō■įLå¢╚▒╩¦ätė|░löĄō■╔²╝ē╗ŅäėŻ¼įņ│╔öĄō■▀węŲ┴┐▌^┤¾Ż╗öĄō■ĮĄ╝ē▀węŲ▀^│╠╚▒Ę”ūįäė┐žųŲĪŻ
▒Š╬─╠ß│÷┴╦Ęų╝ē┤µā”ŽĄĮyųąę╗ĘNöĄō■ūįäė▀węŲĘĮĘ©AutoMigŻ¼╦³ŠC║Ž┐╝æ]┴╦╬─╝■įLå¢Üv╩ĘĪó╬─╝■┤¾ąĪĪóįOéõĄ─┐šķg└¹ė├ŪķørĪó╬─╝■ĻP┬ōąįĄ╚ę“╦žŻ¼ī”╬─╝■▀MąąäėæBĘų╝ēŻ¼▓óį┌öĄō■▀węŲ▀^│╠ųąŻ¼Ė∙ō■žō▌dūā╗»ūį▀mæ¬Ąžš{š¹▀węŲ╦┘┬╩Ż¼į┌īŹļHŽĄĮyųąĄ─īŹ“×▒Ē├„Ż║┼cęčėąĘĮĘ©ŽÓ▒╚Ż¼AutoMigėąą¦┐sČ╠┴╦Ū░┼_IŻ»OĒææ¬ĢrķgĪŻ
1 ŽÓĻP╣żū„
HeĄ╚╚╦╠ß│÷┴╦ę╗ĘN╗∙ė┌├µŽ“ī”Ž¾╬─╝■ŽĄĮyLustreĄ─Ęų╝ē┤µā”ŽĄĮyŻ¼öĄō■Å─┤┼ĦĄĮ┤┼▒PĄ─▀węŲ╩Ūė╔įLå¢╚▒╩¦ė|░lĄ─Ż¼╚▒³c╩Ū╔²╝ēĄ─╬─╝■▀^ČÓŻ¼SANBoostŽĄĮy┐┌3╩╣ė├SSDįOéõ║═┤┼▒Pśŗ│╔ā╔╝ē┤µā”ŽĄĮyŻ¼╦³ę²╚ļę╗éĆ▀węŲķōųĄęį£p╔┘öĄō■▀węŲ┴┐Ż¼ų╗ėąė├æ¶įLå¢▀_ĄĮę╗Č©┤╬öĄ║¾▓┼▀Mąą▀węŲĪŻ
ėąą¦Ą─öĄō■ŅA╚Ī─▄ē“ĮĄĄ═IŻ»OįLå¢čė▀tŻ¼Č°Õeš`Ą─ŅA╚Īų╗Ģ■Ė╔ö_Ū░┼_IŻ»Ožō▌dŻ¼ęčĮøėąę╗ą®öĄō■ŅA╚Ī╦ŃĘ©Ż¼╚ńĘĆ╣╠║¾└^ŅA£yĘĮĘ©Īó╩ū┤╬ĘĆ╣╠║¾└^ĪóūŅĮ³ūŅ│ŻęŖŅA£yĘĮĘ©Ą╚Ż¼╦³éāĄ─╚▒³c╩Ūų╗ŅA£yŽ┬ę╗éĆįLå¢Ż¼┐╔ė├ė┌ŅA╚ĪĄ─ĢrķgķgŽČ║▄Č╠ĪŻ
ĮĄ╝ē▀węŲ╦ŃĘ©ąĶę¬▀xō±▀węŲ──ą®╬─╝■ĄĮ┬²╦┘įOéõŻ¼¼FėąĄ─ĮĄ╝ē▀węŲ╦ŃĘ©ų„ę¬░³└©FIFOŻ¼LRUŻ¼size—onlyŻ¼space—time║═file—agingŻ¼space—time╦ŃĘ©Ė∙ō■╬─╝■┤¾ąĪ║═╬─╝■╔Ž┤╬╩╣ė├ķgĖ¶Ą─│╦ĘeüĒĘų╝ēŻ¼file-aging╦ŃĘ©Ė∙ō■╬─╝■╔Ž┤╬╩╣ė├ĢrķgĪó╬─╝■┤¾ąĪ║═ęįŪ░ėŗ╦ŃĄ─▀węŲųĄüĒėŗ╦Ń«öŪ░Ą─▀węŲųĄŻ¼æ¬ė├į┌Web╬─╝■ŠÅ┤µųąĄ─GreedyDualSize╠µōQ╦ŃĘ©Ż¼Ė∙ō■╬─╝■Ą─Ģrą¦ąįĪó┤¾ąĪ║═ŅA╚Ī│╔▒ŠĮo│÷╬─╝■╠µōQøQ▓▀ĪŻ
Ęų╝ē┤µā”ŽĄĮyTH—TSųąīŹ¼F┴╦ę╗ĘNūįäėĄ─öĄō■▀węŲĘĮĘ©CuteMigŻ¼╦³Ą─╚▒³c╩Ūø]ėą┐╝æ]╬─╝■įLå¢ų«ķgĄ─ĻP┬ōąįĪŻ
į┌öĄō■▀węŲ╦┘┬╩┐žųŲĘĮ├µŻ¼Ą┌1ĘNĘĮ╩Įį┌▒ŻūCöĄō■▀węŲŲ┌Ž▐Ą─Ū░╠ߎ┬Ż¼▒M┴┐╩╣ė├┤┼▒PĄ─┐šķeų▄Ų┌▀MąąöĄō■▀węŲŻ¼Ą┌2ĘNĘĮ╩ĮMS MannersŻ¼«öÖz£yĄĮĘŪųžę¬▀M│╠Ą─Ū░▀M╦┘Č╚Ę┼ŠÅĢrŻ¼▀Mę╗▓ĮĮĄĄ═╦³Ą─▀\ąą╦┘┬╩Ż¼Ą┌3ĘNĘĮ╩ĮAqueduct░č┤µā”ŽĄĮy┐┤ū„ę╗éĆ║┌║ąūėŻ¼ų╗£y┴┐æ¬ė├╦∙▓ņėXĄĮĄ─ąį─▄Ż¼ę“┤╦¤oĘ©čĖ╦┘Öz£yĄĮ┤µā”ŽĄĮy╔ŽĄ─æ¬ė├žō▌dĄ─ūā╗»Ż¼Ą┌4ĘNĘĮ╩Į╩Ūė├╩šęµūŅ┤¾╗»┐“╝▄üĒĮŌøQöĄō■▀węŲå¢Ņ}Ż¼╚▒³c╩ŪąĶę¬╩┬Ž╚įö╝ÜšŲ╬šŽĄĮy╠žąį║═žō▌d╠žš„Ż¼Å─Č°╩╣įōĘĮĘ©╩▄ĄĮę╗Č©Ą─īŹė├ąįŽ▐ųŲĪŻ
2 öĄō■▀węŲĘĮĘ©AutoMig
öĄō■ūįäė▀węŲĘĮĘ©AutoMigė╔3▓┐ĘųĮM│╔Ż║1)öĄō■äėæBĘų╝ē▓▀┬įŻ¼öĄō■Ęų╝ēĄ─Ė─ūāė|░löĄō■Ą─▀węŲŻ╗2)ĻP┬ō╬─╝■═┌Š“╝╝ągŻ¼ĻP┬ōĄ─╬─╝■ė├ė┌ūįäėŅA╚ĪŻ╗3)▀węŲ▀^│╠ųąĄ─╦┘┬╩┐žųŲŻ¼į┌Ū░┼_IŻ»Oąį─▄ė░Ēæ║═öĄō■▀węŲ═Ļ│╔Ų┌Ž▐ų«ķgīżšę║Ž└ĒĄ─ÖÓ║ŌĪŻ
2.1öĄō■äėæBĘų╝ē▓▀┬į
AutoMigųąĄ─öĄō■Ęų╝ēįuār░³└©╬─╝■╔²╝ēįuār║═╬─╝■ĮĄ╝ēįuār2▓┐ĘųĪŻ
AutoMigĖ∙ō■öĄō■╔²╝ēĄ─å╬╬╗│╔▒Š╩šęµą¦┬╩üĒøQČ©╩Ūʱī”╬─╝■ł╠ąą╔²╝ē▓┘ū„Ż¼╬─╝■╔²╝ēĄ─╩šęµą¦┬╩ė├╬─╝■╔²╝ē║¾å╬╬╗Ģrķgā╚▒╗įLå¢Ą─öĄō■┴┐üĒ║Ō┴┐Ż¼┴ŅAS║═AFĘųäe▒Ē╩Š╬─╝■╔²╝ē║¾Ą─╬─╝■įLå¢┤¾ąĪ║═╬─╝■įLå¢Ņl┬╩Ż¼ät╬─╝■╔²╝ē║¾Ą─ąį─▄╩šęµą¦┬╩×ķAS×AFŻ¼╬─╝■╔²╝ēĄ─│╔▒Š┐╔ęį╩╣ė├╬─╝■┤¾ąĪFSüĒ║Ō┴┐Ż¼ė╔┤╦Ż¼öĄō■╔²╝ēĄ─å╬╬╗│╔▒Š╩šęµą¦┬╩Ż©╝┤ą¦ė├ųĄŻ®ėŗ╦Ń×ķutil=(AS×AF)/FSŻ¼╚ń╣¹ę╗éĆ╬─╝■Ą─╔²╝ēą¦ė├ųĄĖ▀ė┌╔²╝ēķōųĄŻ¼ät╔²╝ēįō╬─╝■ĪŻ
į┌Įo│÷╔²╝ēøQ▓▀ĢrŻ¼ų╗ėą╬─╝■┤¾ąĪFS╩Ū┤_Č©Ą─Ż¼AutoMigĮyėŗ╬─╝■Üv┤╬įLå¢┤¾ąĪĄ─ŲĮŠ∙ųĄŻ¼ū„×ķ╬┤üĒįLå¢┤¾ąĪASĄ─╣└ėŗųĄŻ¼×ķ┴╦─▄ē“į┌╬─╝■įLå¢ķgĖ¶Ą─ŅA£yųą¾w¼Fūā╗»┌ģä▌Ż¼ę²╚ļĢrą¦ąįę“ūė(recency factor)Ė┼─ŅŻ¼ŅA£y╬─╝■įLå¢ķgĖ¶Ą─╣½╩Į×ķIk=β×Ik-1+Ż©1-βŻ®×MkŻ¼▀@└’Ż¼M×ķĄ┌k┤╬įLå¢ķgĖ¶Ą─£y┴┐ųĄŻ╗β×ķĢrą¦ąįę“ūėŻ¼ę“×ķ0 <β<1Ż¼ę╗┤╬£y┴┐ųĄī”ė┌╬┤üĒŅA£yųĄĄ─žĢ½IļSų°ĢrķgČ°ęįę“ūėβ╦ź£pĪŻ
AutoMigĮĄ╝ē╦ŃĘ©Ą─╗∙▒Š╦╝Žļ╩ŪŻ¼Ė∙ō■įLå¢Ūķørį┌LRUĻĀ┴ąųąŠSūo┐ņ╦┘┤µā”įOéõ╔ŽĄ─╦∙ėą╬─╝■Ż¼ę╗éĆĮĄ╝ēŠĆ│╠├┐Ė¶ę╗Č©ĢrķgÅ─LRUĻĀ┴ąųą╚Ī│÷ūŅ└õĄ─╬─╝■ū„×ķĮĄ╝ēī”Ž¾Ż¼įōĮĄ╝ēķgĖ¶ĢrķgķLČ╠┼c┐ņ╦┘┤µā”įOéõĄ─┐šķg┐šķe┬╩ėąĻPĪŻ
AutoMigĄ─öĄō■╔²╝ē╦ŃĘ©╝µŅÖ┴╦╬─╝■įLå¢Üv╩Ę║═╬─╝■┤¾ąĪā╔éĆųĖś╦Ż¼╝╚╩╣Ą├╬─╝■▀węŲ╦∙ąĶ┤·ārŽÓī”▌^ąĪŻ¼ę▓▒ŻūC▀węŲ║¾Ą├ĄĮĄ─╬─╝■I/Oąį─▄╩šęµ▌^Ė▀Ż¼ĮĄ╝ēķgĖ¶Ą─┤_Č©ĘĮ╩Į▒ŻūC┴╦┐ņ╦┘┤µā”įOéõ╩╝ĮKėąūŃē“Ą─┐šķe┐šķgŻ¼«ö┤µā”į┌┬²╦┘┤µā”įOéõ╔ŽĄ─╬─╝■▒╗įLå¢ĢrŻ¼ėŗ╦Ń╔²╝ē▀węŲĄ─ą¦ė├ųĄŻ╗«ö┤µā”į┌┐ņ╦┘įOéõ╔ŽĄ─╬─╝■▒╗įLå¢ĢrŻ¼Ė³ą┬ī”æ¬LRUĻĀ┴ąĀŅæBŻ¼öĄō■äėæBĘų╝ē╦ŃĘ©¤oąĶČ©Ų┌Æ▀├Ķ╦∙ėą╬─╝■ęį▀Mąą╬─╝■ārųĄįuārŻ¼╣╩į÷╝ėĄ─ėŗ╦Ńķ_õN▓╗┤¾ĪŻ
2.2ĻP┬ō╬─╝■═┌Š“╝╝ąg
×ķ┴╦ėąą¦īŹ¼F╬─╝■ŅA╚ĪŻ¼AutoMig╩╣ė├öĄō■═┌Š“╝╝ągüĒėąą¦ūRäeŽĄĮyųąĄ─╬─╝■ĻP┬ōąįŻ¼╦³░čę╗éĆ╬─╝■ė│╔õ│╔ę╗éĆĒŚŻ¼░čę╗éĆįLå¢ą“┴ąė│╔õ│╔ą“┴ąöĄō■ÄņųąĄ─ę╗éĆą“┴ąŻ¼ę╗éĆŅlĘ▒ūėą“┴ą▒Ē╩ŠŽÓĻP╬─╝■Įø│Żę╗Ų▒╗įLå¢ĪŻ
ę╗éĆ╬─╝■─▄ęįĖ„ĘNĘĮ╩ĮįLå¢Ż¼│²┴╦┤“ķ_ĻPķ]Ż¼▀Ć┐╔─▄ęį▀M│╠ą╬╩Įł╠ąąŻ¼AutoMig═©▀^ėøõø▀@ą®ŽĄĮyš{ė├üĒśŗĮ©ę╗éĆķLĄ─įLå¢trace. AutoMig▓╔ė├║åå╬ŪąĖŅĄ─ĘĮĘ©░čķLtraceŪą│╔įSČÓČ╠ą“┴ąŻ¼AutoMig░čå¢Ņ}▐D╗»×ķ═┌Š“ŅlĘ▒ķ]║Žą“┴ąå¢Ņ}Ż¼▓╔ė├═┌Š“╦ŃĘ©BIDEŻ¼▓óū„┴╦ę╗Č©│╠Č╚Ą─Ė─▀MĪŻ
BIDE╦ŃĘ©▒Š┘|╩Ūęį╔ŅČ╚ā׎╚Ą─ĘĮ╩ĮŻ¼ę╗▀ģśŗĮ©ŅlĘ▒ūėśõŻ¼ę╗▀ģÖz▓ķķ]║ŽąįŻ¼ę╗▀ģ▀Mąą╝¶ų”Ż¼BIDE╦ŃĘ©īŹ¼FĄ─ā╔éĆĻPµI╚╬äš╩ŪŻ║1Ż®ķ]║ŽąįÖz▓ķŻ╗2)╦č╦„┐šķg╝¶ų”Ż¼BIDE╦ŃĘ©▓╔ė├┴╦ļpŽ“öUš╣─Ż╩ĮŻ║Ž“Ū░öUš╣ė├ė┌į÷ķLŪ░ŠY─Ż╩Į║═Ū░ŠY─Ż╩ĮĄ─ķ]║ŽąįÖz▓ķŻ╗Ž“║¾öUš╣ė├ė┌Ū░ŠY─Ż╩ĮĄ─ķ]║ŽąįÖz▓ķ║═╦č╦„┐šķg╝¶ų”Ż¼ī”ė┌«öŪ░ą“┴ąŻ¼BIDEŽ“Ū░Æ▀├Ķ├┐éĆė│╔õą“┴ąŻ¼šęĄĮŠų▓┐ŅlĘ▒ĒŚŻ¼ī”ė┌├┐éĆŠų▓┐ŅlĘ▒ĒŚŻ¼Öz▓ķ╩Ūʱ┐╔ęį╝¶ų”Ż¼╚ń╣¹▓╗─▄╝¶ų”ätŽ“Ū░öUš╣«öŪ░ą“┴ąĪŻ
į┌AutoMigīŹ¼FųąŻ¼▀\ė├▀ē▌ŗČ╠┬ĘįŁ└ĒŻ¼ī”BIDEū„┴╦3³cā×╗»Ż║
1)ķ]║ŽąįÖz▓ķĢrŻ¼ę“×ķŽ“Ū░öUš╣Öz▓ķ╩Ū╚▌ęū═Ļ│╔Ą─Ż¼╣╩Ž╚ū÷Ž“Ū░Öz▓ķŻ¼╚¶“ø]ėąŽ“Ū░öUš╣ĒŚ”▀@ę╗├³Ņ}×ķ╝┘Ż¼ät¤oąĶ▀MąąŽ“║¾Öz▓ķŻ╗
2)į┌├┐┤╬▀Mąąķ]║ŽąįÖz▓ķĢrŻ¼Č╝ęčĮøėąį┌░ļūŅ┤¾Č╬ĮMųą╦č╦„▓╗ĄĮŽ“║¾öUš╣ĒŚ▀@ę╗ĮYšōŻ¼╚ń╣¹įōŪ░ŠYą“┴ąĄ─Ą┌ę╗īŹ└²Ą─ūŅ║¾ę╗ĒŚ║═ūŅ║¾īŹ└²Ą─ūŅ║¾ę╗ĒŚ╬╗ų├ŽÓ═¼Ż¼ät▓╗▒žÖz▓ķūŅ┤¾Č╬Š═┐╔öÓČ©ø]ėąŽ“║¾öUš╣ĒŚŻ╗
3)▒ŖČÓūŅ┤¾Č╬ĮMųąų╗ꬥ├ĄĮę╗éĆūŅ┤¾Č╬ĮMųąĖ„ą“┴ąĮ╗╝»ĘŪ┐š╝┤┐╔öÓČ©Ž“║¾öUš╣ĒŚ┤µį┌ĪŻ
×ķ┴╦░čŅlĘ▒ą“┴ą▐DōQ│╔ĻP┬ōęÄätŻ¼AutoMigė╔├┐éĆą“┴ą╔·│╔ę╗ą®ęÄätŻ¼AutoMigęÄČ©ę╗éĆęÄätėę▀ģĄ─ĒŚöĄ×ķ1Ż¼ę“×ķ▀@ī”ė┌╬─╝■ŅA╚Ī╩ŪūŃē“Ą─Ż¼×ķ┴╦Ž▐ųŲęÄätöĄ─┐Ż¼AutoMig╝s╩°ę╗éĆęÄätū¾▀ģĄ─ĒŚöĄ▓╗│¼▀^2ĪŻ
AutoMig▀Ćė├┐╔ą┼Č╚ģóöĄüĒ║Ō┴┐ęÄätĄ─┐╔ę└┘ć│╠Č╚Ż¼ę╗ŚlęÄätaę╗bĄ─┐╔ą┼Č╚┐╔ęį═©▀^╚ńŽ┬╣½╩Įėŗ╦ŃŻ║confŻ©a-6Ż®=supŻ©abŻ®/sup(a)Ż¼▀@└’Ż¼sup(a)║═sup(ab)Ęųäe▒Ē╩Šą“┴ąa║═ą“┴ąabĄ─ų¦│ųČ╚Ż¼«öė├ę╗ŚlĻP┬ōęÄätüĒŅA£y╬┤üĒįLå¢ĢrŻ¼ęÄätĄ─┐╔ą┼Č╚▒Ē╩ŠŅA£yĄ─Š½Č╚Ż¼AutoMig╩╣ė├ūŅąĪ┐╔ą┼Č╚ķōųĄ▀^×VĄ═┘|┴┐Ą─ĻP┬ōęÄätŻ¼╩ŻŽ┬Ą─ęÄätĘQ×ķÅŖĻP┬ōęÄätĪŻ
░č▀@ą®ÅŖĻP┬ōęÄätų▒Įėė├ė┌╬─╝■ŅA╚ĪŻ¼┤µį┌ć└ųžĄ─╚▀ėÓ¼FŽ¾Ż¼Å─Č°╝ėųž┴╦ŠSūo║═▓ķšęĄ─│╔▒ŠŻ¼░čŪ░╝■ķLČ╚×ķLĄ─ęÄätĘQ×ķ“L_ęÄät”Ż¼ī”ė┌ę╗Śl2-ęÄätxy-zŻ¼AutoMig═©▀^Öz▓ķ╩Ūʱ┤µį┌═¼ĢrØMūŃ╚ńŽ┬Śl╝■Ą─1-ęÄäta-büĒ┼ąöÓ╦³╩Ūʱ×ķ╚▀ėÓęÄätŻ║1)b=zŻ¼╝┤ėąų°ŽÓ═¼║¾╝■Ż╗2Ż®a-x╗“š▀a-yŻ¼╝┤1-ęÄätĄ─Ū░╝■┼c2ę╗ęÄätĄ─Ū░╝■ųą─│ĒŚŽÓ═¼Ż¼AutoMig -Ą®Öz£yĄĮ╚▀ėÓęÄätŻ¼Š═īóŲõÅ─ęÄät╝»║Žųąäh│²Ż¼╩ŻŽ┬ĘŪ╚▀ėÓĄ─ÅŖĻP┬ōęÄät┐╔ęįų▒Įėė├ė┌╬─╝■ŅA╚ĪĪŻ
ŅA╚Ī┼c╔²╝ē╬─╝■ŽÓĻP┬ōĄ─╬─╝■┐╔ęįĮĄĄ═ī”▀@ą®╬─╝■Ą─įLå¢čė▀tŻ¼╚╗Č°Ż¼ę╗éĆŲš▒ķō·ą─Ą─╩ŪöĄō■ŅA╚Ī╩ŪʱĢ■ė░Ēæš²│ŻöĄō■╔²╝ēĄ─ąį─▄Ż¼AutoMig▓╔╚Īā╔ĘNĘĮĘ©üĒ▒▄├Ō╬─╝■ŅA╚ĪĄ─ąį─▄ė░ĒæŻ¼ī”ė┌ĻP┬ōĄ─ąĪ╬─╝■ĮMŻ¼į┌Ą═╝ēįOéõ╔Ž╝»ųą┤µĘ┼Ż¼▓ó▓╔╚Ī╔²╝ē╔ėĦĄ─ĘĮ╩Į▀MąąŅA╚ĪŻ¼ī”ė┌╔į┤¾Ą─ĻP┬ō╬─╝■Ż¼▓╔╚ĪŽ┬├µĮķĮBĄ─╦┘┬╩┐žųŲÖCųŲüĒ▒ŻūCį┌Ū░┼_žō▌d▌^▌pĢrł╠ąąöĄō■ŅA╚ĪĪŻ
2.3 ▀węŲ╦┘┬╩┐žųŲÖCųŲ
AutoMigųąĄ─▀węŲ╦┘┬╩┐žųŲĘĮĘ©Ż¼īó▀węŲ╚╬äšäØĘų│╔Šo╝▒▀węŲ║═┐╔┐ž▀węŲ2ĘNŻ¼▓ó▓╔ė├▓╗═¼Ą─▀węŲ╦┘┬╩┐žųŲ▓▀┬įŻ¼╬─╝■╔²╝ēĄ╚╚╬äš▒╚▌^ŠoŲ╚Ż¼ę“Č°▓╔ė├“▒M┴”Č°×ķ”Ą─▓▀┬įŻ╗ĮĄ╝ē╚╬äšĪóöĄō■ŅA╚ĪĄ╚╚╬䚎Óī”▓╗ŠoŲ╚Ż¼┐╔ęį▀Mąą╦┘┬╩┐žųŲĪŻ
AutoMigĄ─▀węŲ╦┘┬╩┐žųŲĄ─║╦ą─╦╝Žļ╩ŪĘ┤ü┐žųŲŻ¼ŽĄĮyÖz£y«öŪ░┤µā”ūėŽĄĮyĄ─žō▌d├▄╝»│╠Č╚Ż¼ŽÓæ¬Ą─š{š¹▀węŲ╦┘┬╩Ż¼Å─Č°ŲĮ║ŌŽĄĮyąį─▄║═▀węŲą¦┬╩ķgĄ─├¼Č▄Ż¼łD1Įo│÷┴╦Ę┤ü┐žųŲĄ─▀ē▌ŗ╩ŠęŌłDŻ¼ł╠ąąŲ„ęįę╗Č©╦┘┬╩ł╠ąąöĄō■▀węŲ▓┘ū„Ż¼Öz£yŲ„ī”┤µā”ūėŽĄĮy▀Mąą▓╔śėŻ¼▓ó░č╦∙Ą├Ą─žō▌dą┼ŽóW (k)é„▀fĮo┐žųŲŲ„Ż¼┐žųŲŲ„▒╚ī”W(k)║═ąį─▄ģóššųĄŻ¼▓ó═©▀^┐žųŲ║»öĄüĒš{š¹▀węŲ╦┘┬╩Ż¼▌ö│÷ą┬Ą─▀węŲ╦┘┬╩R(k)Įoł╠ąąŲ„Ż¼ł╠ąąŲ„ŽÓæ¬Ąžš{š¹öĄō■ĮĄ╝ēĄ─╦┘┬╩ĪŻ
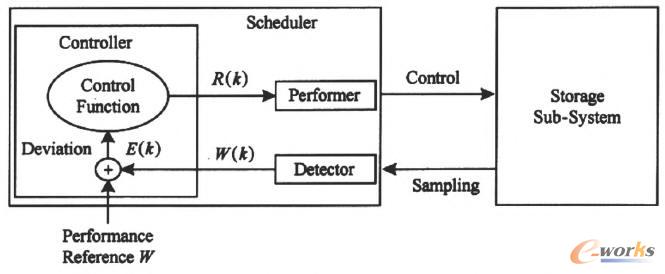
łD1 Ę┤ü┐žųŲĄ─▀ē▌ŗ╩ŠęŌłD
į┌Ęų╝ē┤µā”ŽĄĮyųąŻ¼┐ņ╦┘┤µā”įOéõ═∙═∙žō▌d▌^ųžŻ¼Č°┬²╦┘┤µā”įOéõę╗░Ń╩ŪĄ═žō▌d╗“š▀¤ožō▌dĄ─Ż¼╦∙ęįį┌╦┘┬╩┐žųŲ▀^│╠ųąŻ¼ų„ę¬┐╝æ]Ą─╩Ū┐ņ╦┘┤µā”įOéõ╦∙│ą╩▄Ą─IOPSĪŻ
┐žųŲŲ„Ą─ąį─▄ģóššųĄ×ķWŻ¼╦³╩Ū┐ņ╦┘┤µā”įOéõ╦∙─▄│ą╩▄Ą─ūŅ┤¾žō▌dŻ¼žō▌d┐é┴┐wė╔Ū░┼_I/OšłŪ¾║═▀węŲI/OšłŪ¾ā╔▓┐ĘųĮM│╔Ż¼├┐éĆ▓╔śėų▄Ų┌Ż¼┐žųŲŲ„Ą├ĄĮ┤µā”įOéõĄ─žō▌dģóöĄW(k)Ż¼╩ūŽ╚Ż¼┐žųŲŲ„ėŗ╦ŃW(k)┼cąį─▄ģóššųĄų«ķgĄ─▓ŅųĄŻ║E(k)=W-W(k)Ż¼į┌Ą├ĄĮE(k)ų«║¾Ż¼═©▀^┐žųŲ║»öĄėŗ╦Ń│÷ą┬Ą─▀węŲ╦┘┬╩Ż║R(k) =R(k-1)+E(k)ĪŻ
AutoMigųąĄ─▀węŲ╦┘┬╩┐žųŲĘĮĘ©īóģ^äe▀węŲąĶŪ¾║═Ę┤ü┐žųŲ╦╝ŽļŽÓĮY║ŽŻ¼Ė∙ō■Ū░┼_I/Ožō▌dūā╗»Ż¼ūį▀m欚{š¹öĄō■▀węŲ╦┘┬╩Ż¼╩╣Ą├öĄō■▀węŲäėū„▒Š╔Ēī”ė┌Ū░┼_I/Oąį─▄Ą─ė░ĒæĘŪ│ŻąĪŻ¼═¼Ģr╩╣Ą├öĄō■▀węŲ╚╬äš─▄ē“▒M┐ņ═Ļ│╔ĪŻ
3 ąį─▄£yįć
▒Š╬─īóöĄō■ūįäė▀węŲĘĮĘ©AutoMigæ¬ė├ĄĮĘų╝ē┤µā”ŽĄĮyTri-RightųąŻ¼▀Mąą┴╦▒╚▌^╚½├µĄ─ąį─▄£yįćĪŻ
3.1Ęų╝ē┤µā”ŽĄĮyįŁą═
╚ńłD2╦∙╩ŠŻ¼Tri-Right▓╔ė├Ħ═Ō╝▄śŗŻ¼▓óį┌╬─╝■ŽĄĮyā╚▓┐īŹ¼FŻ¼╦³ė╔╬─╝■ŽĄĮy┐═æ¶Č╦Īóį¬öĄō■Ę■äšŲ„║═öĄō■Ę■äšŲ„ĮM│╔Ż¼┐═æ¶Č╦╣سcŽ“ė├æ¶╠ß╣®I/OįLå¢Įė┐┌Ż¼╦³Įė╩šė├æ¶Ą─╬─╝■įL墚łŪ¾Ż╗Ž“į¬öĄō■Ę■äšŲ„ūxīæŽÓĻP╬─╝■Ą─į¬öĄō■Ż╗Ž“öĄō■Ę■äšŲ„ūxīæŽÓĻP╬─╝■Ą─ā╚╚▌Ż╗▓óūŅĮK░čĮY╣¹ĘĄ╗žĮoė├æ¶ĪŻ
łD2 Tri-RightĄ─ŽĄĮy╝▄śŗ
į¬öĄō■Ę■äšŲ„ŠSūo╦∙ėą╬─╝■Ą─ŽÓĻPą┼ŽóŻ¼░³└©╬─╝■öĄō■į┌ČÓéĆöĄō■Ę■äšŲ„╔ŽĄ─Ęų▓╝ŪķørĄ╚Ż╗Ė∙ō■╬─╝■įLå¢Ūķør║═įOéõĘų╝ēą┼ŽóŻ¼Įo│÷öĄō■▀węŲĄ─øQ▓▀Ż╗Ė∙ō■öĄō■Ę■äšŲ„Ą─žō▌dŪķør▀Mąą╬─╝■▀węŲĄ─╦┘┬╩┐žųŲŻ¼öĄō■Ę■äšŲ„ė├üĒīŹļH┤µā”ĘųŲ¼║¾Ą─╬─╝■öĄō■Ż¼╦³╠Ä└ĒüĒūį┐═æ¶Č╦Ą─╬─╝■I/0šłŪ¾Ż╗░čūį╔Ēžō▌dŪķørĘĄ╗žĮoį¬öĄō■Ę■äšŲ„Ż╗▓óį┌į¬öĄō■Ę■äšŲ„Ą─ųĖ╩ŠŽ┬ł╠ąą╬─╝■Ą─▀węŲ▓┘ū„ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║Ęų╝ē┤µā”ŽĄĮyųąę╗ĘNöĄō■ūįäė▀węŲĘĮĘ©(╔Ž)
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/1112156920.html






















