



┐é¾wĮYśŗ┼cūĘ█ÖöĄō■╣▄└Ē
╬ęéāĄ─ĘĮ░ĖĘų×ķā╔┤¾▓┐ĘųŻ║╦∙ėąĘ■äš╝»│╔ĄĮūĘ█ÖÄņųąŻ¼Ęų┼õę╗éĆā╚┤µēKüĒ┤µā”┼c▓ķ┐┤ūĘ█ÖöĄō■ĪŻ╬ęéā▀xō±ZipkinŻ¼į┌Twitterķ_░l(f©Ī)Ą─ę╗éĆ┐╔öUš╣Ą─ķ_į┤ūĘ█Ö┐“╝▄Ż¼ė├ė┌┤µā”┼c▓ķ┐┤ūĘ█ÖöĄō■ĪŻZipkin═©│ŻęįFinagleī”Ą─ą╬╩Į│÷¼F(xi©żn)Ż¼Ą½╩ŪŻ¼Ž±╔Žę╗╣Ø(ji©”)╠ß╝░Ą─ę╗śėŻ¼╬ęéā┼┼│²┴╦┼c╬ęéā¼F(xi©żn)ėą╗∙ĄAįO╩®ø_═╗Ą─▓ó░l(f©Ī)░YĪŻKnewtonśŗĮ©ūĘ█ÖÄņŻ¼ĘQ×ķTDistŻ¼Å─Ąž├µŲŻ¼ķ_╩╝ū„×ķ╣½╦Š“║┌┐═╚š”Ą─īŹ“×ĪŻ

ūĘ█ÖöĄō■─Żą═
Š═╬ęéāĄ─ĘĮ░ĖČ°čįŻ¼╬ęéā▀xō±╩╣ė├ZipkinüĒŲź┼õöĄō■─Żą═Ż¼▌å┴„Å─Dapper┤¾┴┐ĮĶ╚ļĪŻę╗éĆūĘ█Öśõė╔ę╗ŽĄ┴ąĄ─┐ńČ╚ĮM│╔ĪŻ┐ńČ╚┤·▒Ēę╗éĆ╠ž╩ŌĄ─║¶ĮąÅ─Ę■äšŲ„Įė╩šķ_╩╝Ż¼ĄĮĘ■äšŲ„░l(f©Ī)╦═Ż¼ūŅ║¾╩Ū┐═æ¶Č╦Įė╩šĪŻ┼eéĆ└²ūėŻ¼į┌Ę■äšŲ„A║═Ę■äšŲ„Bų«ķgĄ─║¶Įą┼cĒææ¬īóĢ■ū„×ķę╗éĆ║åå╬Ą─┐ńČ╚Ż║
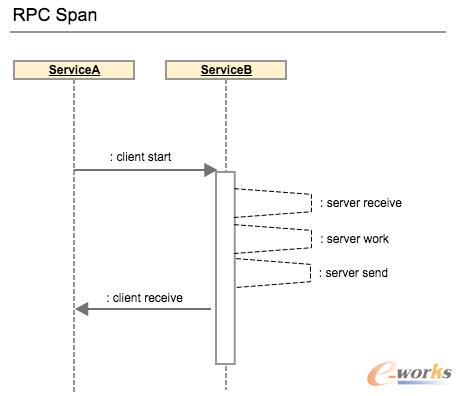
├┐ę╗éĆ┐ńČ╚(span)ėą╚²éĆIDŻ║
- Trace IDŻ║ę╗éĆ▄ē█Eųą╦∙ėąĄ─┐ńČ╚(span)╣▓ŽĒ═¼ę╗éĆTrace IDĪŻ
- Span IDŻ║ė├ęįś╦╩Š▓╗═¼Ą─┐ńČ╚(span)ĪŻSpan ID┼cTrace ID▓╗ę╗Č©ŽÓ═¼ĪŻ
- Parent Span IDŻ║ ų╗ėąūė┐ńČ╚│ųėą▀@éĆIDŻ¼Ė∙┐ńČ╚ø]ėąParent Span IDĪŻ
Ž┬├µĄ─łDš╣╩Š┴╦į┌ę╗éĆśõĮYśŗĄ─š{ė├ųąŻ¼╔Ž├µ╚²éĆID╩Ū╚ń║╬æ¬ė├Ą─ĪŻūóęŌį┌š¹éĆśõĮYśŗųąTrace ID╩Ūę╗ų┬Ą─ĪŻ
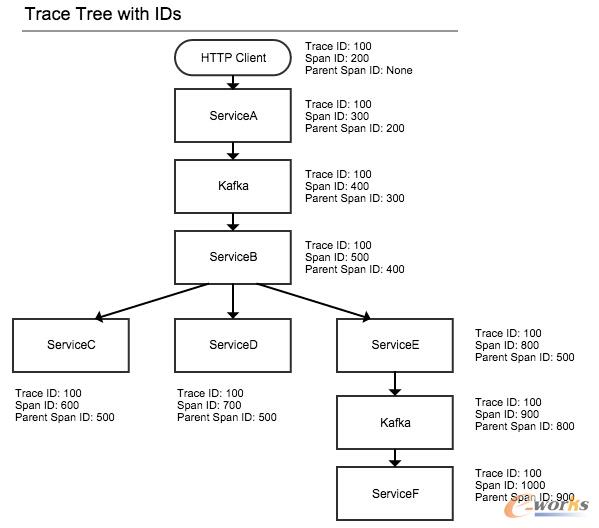
Ė³ČÓįöŪķŻ¼ šłģóęŖ Dapper paper.
TDist
TDist╩ŪKnewtonķ_░l(f©Ī)Ą─ę╗éĆJavaÄņĪŻ└¹ė├įōÄņ╬ęéā┐╔ęįūĘ█Ö╦∙ėąĄ─æ¬ė├. TDist ─┐Ū░ų¦│ųThriftŻ¼ HTTPŻ¼ and KafkaŻ¼ ▀Ć┐╔ęįė├üĒūĘ█Ö╩╣ė├┴╦ūóĮŌ(ģóęŖGuice)Ą─ĘĮĘ©Ą─š{ė├ĪŻ
ī”├┐ę╗éĆŠĆ│╠Ę■äš╗“š▀ī”┴Ē═Ōę╗éĆĘ■äš░l(f©Ī)ŲĄ─šłŪ¾Č╝Ęų┼õę╗éĆ┐ńČ╚(span)Ż¼ŅÉÄņĢ■į┌║¾┼_ī”┐ńČ╚▀Mąąé„▓ź║═Ė³ą┬ĪŻ╩šĄĮę╗éĆšłŪ¾(╗“š▀╝┤īó░l(f©Ī)│÷ę╗éĆšłŪ¾)Ż¼ūĘ█ÖöĄō■Ģ■▒╗╠Ē╝ėĄĮę╗éĆā╚▓┐ĻĀ┴ąųąŻ¼DataManagerīóTraceIDą▐Ė─╠Ē╝ėĄĮ╠Ä└ĒšłŪ¾Ą─ŠĆ│╠Ą─├¹ĘQųąĪŻ╣żū„ŠĆ│╠Ž¹┘MĻĀ┴ąŻ¼╚╗║¾īóūĘ█ÖöĄō■░l(f©Ī)▓╝ĄĮūĘ█ÖŽ¹Žó┐éŠĆĪŻJava ThreadLocal┐╔ęį║▄ĘĮ▒ŃĄ─┤µā”║═ūx╚ĪŠĆ│╠ĘČć·ā╚Ą─╚½Šųūā┴┐Ż¼╬ęéāį┌DataManagerųą╩╣ė├┴╦▀@ĘNĘĮĘ©ĪŻ
═©│ŻŻ¼ŠĆ│╠īó▀h│╠š{ė├╗“š▀ł¾Ėµ╗žĖĖŠĆ│╠▀@śėĄ─īŹļHĄ─╣żū„▐D╝▐ĮoŲõ╦¹ŠĆ│╠üĒū÷ĪŻę“┤╦Ż¼╬ęéāę▓īŹ¼F(xi©żn)┴╦ŠĆ│╠factory║═executorŻ¼▀@śėŠ═ų¬Ą└╚ń║╬Öz╦„ĖĖŠĆ│╠Ą─ūĘ█ÖöĄō■Ż¼▓óīóŲõĘų┼õĮoūėŠĆ│╠Ż¼Å─Č°╩╣Ą├ūėŠĆ│╠ę▓┐╔ęįūĘ█ÖĪŻ
Zipkin
ūĘ█ÖöĄō■ę╗Ą®Įø▀^TDistĄĮ▀_ūĘ█ÖŽ¹Žó┐éŠĆŻ¼Zipkin╗∙ĄAįO╩®Ģ■╠Ä└Ē╩ŻŽ┬Ą─┴„│╠ĪŻČÓ╩š╝»Ų„īŹ└²Ż¼Å─Ž¹Žó┐éŠĆųąŽ¹┘MŻ¼┤µā”ūĘ█ÖöĄō■ųą├┐éĆėøõøĪŻę╗éĆĘųļxĄ─▓ķįā╝»║Ž┼cwebĘ■䚯¼ZipkinĄ─▓┐Ęųį┤┤·┤aŻ¼×ķ┴╦ūĘ█Öę└┤╬▓ķįāöĄō■ÄņĪŻ╬ęéā?y©Łu)ķ┴╦╩╣Ą├╩┬ŪķūāĄ├║åå╬Ż¼øQČ©ģó┼c▓ķįā║═webĘ■䚯¼▓óŪęę▓ę“×ķ▀@ĘNĮM║ŽĘ■äš╩Ūā╚▓┐Ą─Ż¼▓óŪęėą┐╔ŅA£yĄ─Į╗═©─Ż╩ĮĪŻĄ½╩ŪŻ¼╩š╝»Ų„╩ŪÅ─▓ķįā┼cwebĘ■äšųąĘųļxĄ─Ż¼ę“×ķįĮČÓKnewtonĘ■äš╝»│╔ĄĮ╩š╝»Ų„Ż¼įĮČÓūĘ█ÖöĄō■ąĶę¬╠Ä└ĒĪŻ
Zip kin UI
║ąūė═Ō▓┐Ż¼Zipkinį┌š¹éĆĘ■äšųą╠ß╣®ę╗╠ū║åå╬Ą─UIĮoęĢłDūĘ█ÖĪŻ«öį┌╦∙ėąĘ■äšųąŻ¼ĘŪ│Ż╚▌ęūĄž┤“ėĪęĢłD╚šųŠė├ė┌ę╗éĆ╠ž╩ŌĄ─ūĘ█ÖID╠¢Ż¼Zipkin UIį┌├┐┤╬š{ė├Ą─│ų└m(x©┤)ĢrķLųą╠ß╣®ę╗éĆ┐é¾węĢłDŻ¼▓╗ąĶę¬▓ķįāöĄ░┘éĆ╚šųŠšZŠõĪŻį┌ę╗éĆ╠žČ©Ą─ų▄Ų┌Ģrķgā╚Ż¼╦³ę▓╩Ūę╗éĆėąą¦Ą─ĘĮ╩ĮüĒ▒µäeūŅ┤¾Ą─╗“š▀ūŅ┬²Ą─ūĘ█ÖĪŻį┌░l(f©Ī)¼F(xi©żn)▀@ą®«É│ŻųĄĄ─ŪķørŽ┬Ż¼į╩įS╬ęéāś╦ųŠ│÷──└’ųžÅ═š{ė├Ųõ╦¹Ę■䚯¼×ķ┴╦┐é¾wš{ė├µ£Č°Ę┼┬²╬ęéāĄ─SLAĪŻęįŽ┬╩ŪZipkin UIųąĄ─ūĘ█ÖĮžłDŻ║
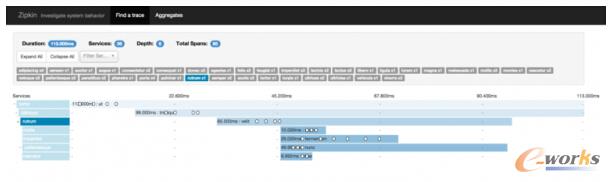
«ö╚╗Ż¼UI▓ó▓╗Ģ■│ĘõNĪŻļm╚╗╦³║▄╚▌ęū┐┤ŪÕ│■éĆ╚╦║██EŻ¼╬ęéā░l(f©Ī)¼F(xi©żn)Zipkin UI ╚▒Ę”Öz▓ķģR┐éöĄō■ĪŻ▒╚╚ńšfŻ¼─┐Ū░▀Ćø]ėąĘĮĘ©½@╚Ī┐éĄ─Ģrķgą┼Žó╗“š▀┐éĄ─öĄō■Ż¼ĘQų«×ķČ╦³cŻ¼Ę■䚥╚Ą╚ĪŻ
į┌š¹éĆ░l(f©Ī)š╣▀^│╠ųąŻ¼═Ų│÷Zipkin╗∙ĄAįO╩®Ż¼╬ęéāī”ZipkinĄ─ķ_į┤ū÷│÷┴╦ą®įSžĢ½IŻ¼Ėąųx╦³Ą─╗Ņ▄Sęį╝░│╔ķL╔ńģ^(q©▒)Ą─ų¦│ųĪŻ
Splunk
š²╚ń╔Ž├µ╦∙╠ߥĮŻ¼«öŪ░╠Ä└ĒšłŪ¾Ą─ŠĆ│╠├¹ę▓Ģ■ūāäėŻ¼ŲõTrace IDĢ■ūĘ╝ėį┌╔Ž├µĪŻę“×ķ▀@śėŻ¼╬ęéāį┌ąĶę¬╠žČ©šłŪ¾Ą─Ģr║“Ż¼▓┼─▄Å─╦∙ėąåóė├ūĘ█ÖĄ─Ę■äš╔Ž▓ķįā╚šųŠĪŻ▀@╩╣Ą├š{įćĖ³╝ėĘĮ▒ŃŻ¼═¼Ģr╩┬īŹūC├„Ųõė├ė┌╩┬║¾Ęų╬÷Īó╚šųŠŠ█║ŽĪó¬Ü┴óå¢Ņ}Ą─š{įć╝░ĮŌßīŲĮ┼_Ą─«É│Żąą×ķĢrę▓▒╚▌^ėąė├ŻĪ
Thrift
Thrift╩Ūę╗éĆė├ė┌śŗĮ©┐╔═žš╣Ę■䚥─┐ńŲĮ┼_Ą─RPC┐“╝▄ĪŻį┌ThriftųąŻ¼ė├æ¶┐╔ęįČ©┴xę╗éĆĘ■äšĪóöĄō■ŅÉą═Ą─ęÄ(gu©®)ätŻ¼ThriftŠ═Ģ■į┌įSČÓ▓╗═¼Ą─šZčįųąŠÄūgŲõęÄ(gu©®)ätŻ¼▀@Ģrė├涊═┐╔ęįė├Žļꬥ─ķ_░l(f©Ī)šZčįīŹ¼F(xi©żn)╦∙╔·│╔Ą─Ę■äšĮė┐┌ĪŻThrift═¼Ģrūįäė╔·│╔┐═æ¶Č╦┤·┤a╝░ė├æ¶×ķĘ■äš╦∙Č©┴xĄ─öĄō■ĮYśŗĪŻ
į┌KnewtonųąThrift╩ŪĘ■äšų«ķg╩╣ė├ūŅŲš▒ķ╩╣ė├Ą─RPC┐“╝▄Ż¼╬ęéāĘ■䚥─┤¾ČÓöĄ═©▀^╩╣ė├┤╦┐“╝▄▀Mąą═©ą┼Ż¼╦∙ęįį┌ŠSūo║¾Č╦╝µ╚▌ąįĄ─Ģr║“ų¦│ų╦³Ż¼ī”ė┌┤╦ĒŚ─┐Ą─│╔╣”ąįČ°čįėąų°ųž┤¾Ą─ė░ĒæĪŻĖ³£╩┤_Ą─šfŻ¼╬ęéāŽļūī╬┤åóė├ūĘ█ÖĄ─Ę■äš─▄┼cåóė├ūĘ█ÖĄ─Ę■äš═©ą┼ĪŻ
«ö╬ęéāķ_╩╝蹊┐ĮoThrift╠Ē╝ėūĘ█Öų¦│ųĄ─Ģr║“Ż¼╬ęéā┼c▓╗═¼Ą─ā╔éĆĘĮ╩Į▀MąąīŹ“×ĪŻĄ┌ę╗ĘNĘĮ╩Į╔µ╝░ĄĮę╗éĆą▐Ė─▀^Ą─ThriftŠÄūgŲ„Ż¼Č°Ą┌Č■ĘN╔µ╝░ĄĮą▐Ė─║¾Ą─ą“┴ąģf(xi©”)ūh╝░Ę■äš╠Ä└ĒŲ„ĪŻā╔ĘNĘĮĘ©Č╝ėąŲõā×(y©Łu)╚▒³cĪŻ
ūįČ©┴xŠÄūgŲ„
į┌▀@éĆĘĮĘ©ųąŻ¼╬ęéā¾w“׹▐Ė─C++║åęūŠÄūgŲ„üĒ╔·│╔Ņ~═ŌĄ─Ę■äšĮė┐┌Ż¼┐╔ęįé„▀fūĘ█ÖöĄō■Įoė├æ¶ĪŻ┐╔─▄ūŅų°├¹└²ūėŠ═╩ŪScroogeŻ¼ą▐Ė─║åęūĄ─ŠÄūgŲ„▓ó▓╗║▒ęŖĪŻą▐Ė─▀^Ą─ŠÄūgŲ„Ą─Ųõųąę╗éĆā×(y©Łu)ä▌╩ŪŻ¼┐═æ¶Č╦į┌╦³éā┤·┤aųąĮ╗ōQ▌^╔┘Ą─ŅÉīŹ¼F(xi©żn)Ż¼ė╔ė┌į┌╔·│╔Ą─┤·┤aųąų¦│ųūĘ█ÖĪŻ┐═æ¶Č╦ę▓┐╔ęį½@Ą├üĒūįĘ■äšĮė┐┌Ą─ūĘ█ÖöĄō■ū„×ķģó┐╝ĪŻ
ļm╚╗╬ęéāø]ėąÖz£yŻ¼╬ęéāę▓┐╔ęįšJ×ķ▀@éĆĘĮĘ©īóĢ■Ė³┐ņ╦┘Ąž╩▄ĄĮæ¬ė├Ż¼ė╔ė┌ų╗ėą▌^╔┘Ą─ŅÉš{ė├ūĘ█ÖīŹ¼F(xi©żn)ĪŻĄ½╩ŪŻ¼╬ęéā╬ę├┤īóĢ■ųžŠÄūg╬ęéā╦∙ėąĄ─║åęū┤·┤aŻ¼Ų½ļxķ_į┤░µ▒ŠŻ¼╩╣Ą├╦³į┌īóüĒĖ³ļy╔²╝ēĪŻ╬ęéāę▓īóĢ■šJūRĄĮŻ¼į╩įSė├æ¶įLå¢ūĘ█ÖöĄō■īó╚▒Ę”┐╩═¹╗“š▀░▓╚½Ż¼▓óŪęöĄō■╣▄└Ē┐╔ęįĖ³║├Ąž▒ŻūCTDistĄ─ę╗ų┬ąįĪŻ
ūįČ©┴xģf(xi©”)ūh┼cĘ■äš╠Ä└ĒŲ„
ūŅĮK╬ęéāæ¬ė├▀@éĆĘĮĘ©ĄĮ╔·«aųąĪŻ▓ó▓╗Ģ■ŠS│ųę╗éĆūįČ©┴xŠÄūgŲ„üĒ┤¾┴┐ĮĄĄ═╬ęéāķ_░l(f©Ī)│╔▒ŠĪŻūįČ©┴xģf(xi©”)ūh┼cĘ■äšĮė┐┌Ą─ūŅ┤¾╚▒Ž▌╩ŪŻ¼╬ęéā▓╗Ą├▓╗╔²╝ēüĒ╣Ø(ji©”)āĆ0.9.0Ż©Å─0.7.0Ż®Ż¼└¹ė├ę╗ą®╠žš„īóĢ■╩╣Ą├╦³Ė³╝ė╚▌ęū▓Õ╚ļ╬ęéāūįČ©┴xģf(xi©”)ūh┼c╠Ä└ĒŲ„Ą─ūĘ█ÖĮM╝■ųąĪŻ╔²╝ēąĶę¬įSČÓĮM┐ŚĄ─ģf(xi©”)š{ĪŻ┴Ņ╚╦æcąęĄ─╩ŪŻ¼Ė³ą┬Ą─║åęū░µ▒Š╩ŪŽ“║¾╝µ╚▌┼f░µ▒ŠĄ─Ż¼╬ęéā┐╔ęįį┌TDist╣żū„Ż¼«öKnewtonĘ■äš▒╗Ė³ą┬ĄĮą┬░µ▒ŠĢrĪŻĄ½╩ŪŻ¼į┌╬ęéā┐╔ęįķ_╩╝ė├╬ęéāĄ─Ęų▓╝╩ĮūĘ█ÖĘĮ░ĖüĒ╝»│╔╦³éāĢrŻ¼╬ęéā╚į╚╗▓╗Ą├▓╗ßīĘ┼╦∙ėąĄ─KnewtonĘ■äšĪŻ
╔²╝ē Thrift
ę╗░ŃüĒšf═©▀^ę└┘ć╣▄└Ē╣żŠ▀╔²╝ēę└┘ćÄņŽÓī”▒╚▌^╚▌ęūŻ¼Ą½╚ń╣¹╩Ū─Ūą®ŅÉ╦ŲThriftĄ─RPC┐“╝▄Ż¼╗“š▀ę╗ą®ėą║▄╔Ņš{ė├µ£Ą─SOA┐“╝▄Ż¼å¢Ņ}Š═Ģ■Å═ļs║▄ČÓĪŻę╗éĆĄõą═Ą─Ę■äš═©│ŻĢ■═¼Ģr░³║¼Ę■äšČ╦║═┐═æ¶Č╦Ą─┤·┤aŻ¼Č°Ę■äšČ╦Ą─┤·┤a═∙═∙Ģ■ę└┘ćŲõ╦¹Ą─ę╗ą®┐═æ¶Č╦Ą─ę└┘ćÄņĪŻ╦∙ęįŻ¼╔²╝ēĄ─Ģr║“ąĶę¬Å─Ę■äšš{ė├śõĄ─╚~ūė╣Ø(ji©”)³cķ_╩╝Ž“╔Žų╝ē╔²╝ēŻ¼ęį▒▄├ŌĘ■äšš{ė├Ą─╝µ╚▌ąįå¢Ņ}ĪŻę“×ķĘ■äš╠ß╣®ĘĮ┐╔─▄▓ó▓╗ų¬Ą└š{ė├ĘĮ╩Ūʱ┐╔ęįÖz£y│÷─Ūą®ĖĮ╝ėĄ─ūĘ█ÖöĄō■ĪŻ
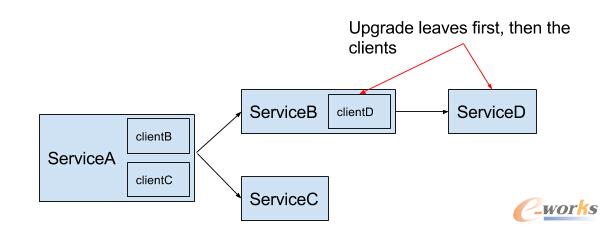
┴Ē═Ōę╗éĆšŽĄK╩ŪŻ¼ę╗ą®Ę■äšĢ■ę└┘ćThrift 0.7.0Ż©ūgš▀ūóŻ║╔Ž╬─šäĄĮąĶę¬╔²╝ē×ķ0.9.0Ż®Ż¼▒╚╚ńCassandra┐═æ¶Č╦ę└┘ćAstyanaxŻ¼Astyanaxę└┘ćĄ─ę╗ą®Ą┌╚²ĘĮę└┘ćÄņĢ■Ę┤▀^üĒę└┘ćThrift 0.7.0ĪŻī”ė┌AstyanaxŻ¼╬ęéā▓╗Ą├▓╗═©▀^Mavenīóę└┘ćĄ─JAR░³Ų┴▒╬Ż©shade Ż®▓óŪęą▐Ė─░³├¹üĒ▒▄├Ōą┬┼f░µ▒ŠThriftÄņų«ķgĄ─ø_═╗ĪŻš¹éĆ╔²╝ē▀^│╠▒žĒÜčĖ╦┘Ż¼▓óŪęø]ėą═ŻÖCĢrķgĪŻ×ķ┴╦▓╗ūī╔²╝ē▀^│╠ĮoKnewtonĄ─Ųõ╦¹łFĻĀĦüĒŅ~═Ō│╔▒ŠŻ¼Ęų▓╝╩ĮūĘ█ÖąĪĮM▓╗Ą├▓╗īŹ╩®▓ó═Ųäėš¹éĆūāĖ³▀^│╠ĪŻ
ūĘ█Ö║å╝sĮM╝■Ż║╦¹╩Ū╚ń║╬╣żū„Ą─
╬ęéāĄ─║å╝sĘĮ░Ėė╔ūįČ©┴xĪóŽ“║¾╝µ╚▌Ą─ģf(xi©”)ūh┼cūįČ©┴xĘ■äš╠Ä└ĒŲ„ĮM│╔Ż¼╠ß╚ĪĖ·█ÖöĄō■Ż¼Ę┼į┌┬Ęė╔ĄĮŽÓæ¬Ą─RPCš{ė├ĪŻ╬ęéāĄ─ģf(xi©”)ūh╗∙▒Š╔Žį┌├┐éĆŽ¹ŽóŅ^īæ╚ļūĘ█ÖöĄō■ĪŻ«öRPCš{ė├ĄĮ▀_Ę■äšŲ„Ż¼╠Ä└ĒŲ„īóĢ■ūRäe▓óŪęś╦ėø║¶╚ļš{ė├╩ŪʱėąūĘ█ÖöĄō■Ż¼ę“┤╦╦³┐╔ęįŪĪĄĮ║├╠ÄĄžĒææ¬ĪŻūĘ█ÖöĄō■Ą─š{ė├ę▓Å─ųą½@╚ĪĒææ¬Ż¼üĒūįĘŪ╝»│╔Ę■䚥─šłŪ¾▓╗Ģ■öyĦø]ėąĒææ¬Ą─ūĘ█ÖöĄō■ĪŻ▀@╩╣Ą├ūĘ█Öģf(xi©”)ūhŽ“║¾╝µ╚▌Ż¼ę“×ķĘ■äšŲ„é„│÷Ą─ģf(xi©”)ūh▓╗Ģ■īæūĘ█ÖöĄō■Ż¼╚ń╣¹ųĖ╩Š▓╗╩Ū│÷ūį╠Ä└ĒŲ„╦∙Ę■䚥─šłŪ¾ĪŻę╗éĆūĘ█Öģf(xi©”)ūh┐╔ęįÖz£yėąą¦▌d║╔╩Ūʱ░³║¼ūĘ█ÖöĄō■╗∙ė┌Ū░├µÄūéĆūų╣Ø(ji©”)ĪŻ║å╝sūĘ╝ėģf(xi©”)ūhIDĄĮģf(xi©”)ūhŅ^Ż¼╝┘╚ńūx╚Īģf(xi©”)ūhĢr░l(f©Ī)¼F(xi©żn)Ū░├µÄūéĆūų╣Ø(ji©”)▓╗’@╩ŠūĘ█ÖöĄō■Ż¼ŠÅ┤µ┼cėąą¦▌d║╔Ą─┤µį┌ū„×ķę╗éĆĘŪūĘ█Ö▌d║╔üĒųžūxĪŻ«öš²į┌ūx╚Īę╗éĆŽ¹ŽóĢrŻ¼ģf(xi©”)ūhīóĢ■╠ß╚ĪūĘ█ÖöĄō■Ż¼▓óŪę╩╣ė├öĄō■╣▄└ĒŲ„üĒ▒Ż┤µ╦³éāų┴▒ŠĄžŠĆ│╠Ż¼ė├ė┌RPC║¶╚ļš{ė├Ą─ŠĆ│╠Ę■äšĪŻ╝┘╚ńįōŠĆ│╠Ņ~═Ōš{ė├ė┌Ųõ╦¹Ę■䚥─Ž┬ė╬Ż¼ūĘ█ÖöĄō■īó═©▀^TDistÅ─öĄō■╣▄└ĒŲ„ūįäėĄž▒╗╠ß╚Ī│÷üĒŻ¼▓óŪę╠Ē╝ėĄĮ═Ō▓┐Ž¹ŽóĪŻ
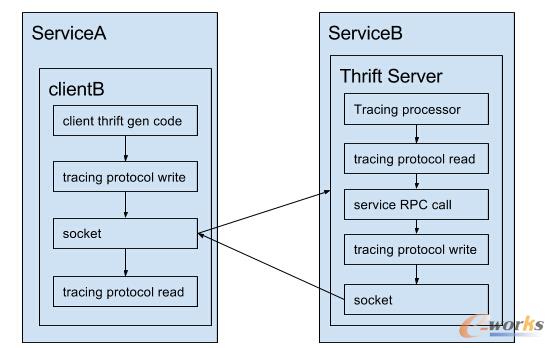
Ž┬├µ╩Ūę╗éĆłDĮŌŻ¼š╣╩Š╚ń║╬ą▐Ė─▌d║╔üĒ╠Ē╝ėūĘ█ÖöĄō■Ż║
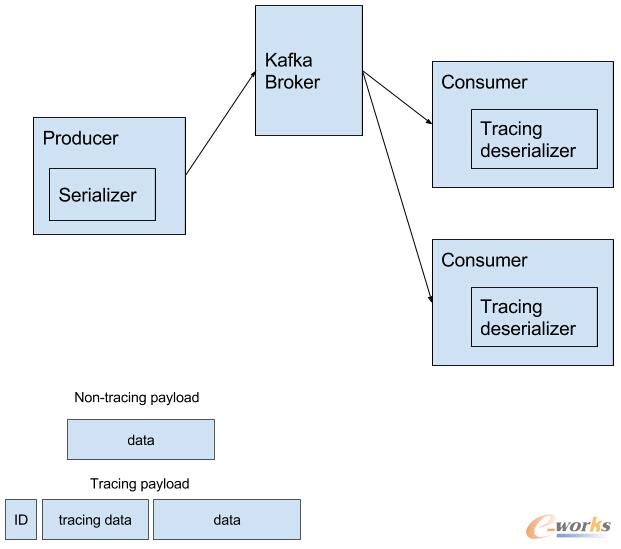
KafkaŽ¹ŽóūĘ█Öų¦│ų
«ö╬ęéā?y©Łu)ķkafka╠ß╣®Ž¹ŽóūĘ█Öų¦│ųĢrŻ¼╬ęéāŽŻ═¹░čKafkaĘ■䚯©ę▓▒╗ĘQ×ķbrokersŻ®Ż¼ū÷×ķę╗éĆ║┌Žõ┐┤┤²ĪŻōQčįų«Ż¼╬ęéāŽŻ═¹brokers▓╗ąĶę¬ų¬Ą└Ž¹Žó╩Ūʱ▒╗Ž¹┘MŻ©╝┤brokers▓╗ąĶę¬ų¬Ą└Ž¹Žó╩Ūʱ═©▀^╦³░l(f©Ī)╦═ĮoŽ¹┘Mš▀Ż®ę“┤╦╬ęéā▓╗ąĶꬹ▐Ė─KafkaĄ─į┤┤aĪŻ╬ęéā▓╔ė├┼cRPC Ę■äšŅÉ╦ŲĄ─╠Ä└ĒĘĮ╩ĮŻ¼į┌╔²╝ē╔·«aš▀ų«Ū░Ž╚╔²╝ēŽ¹┘Mš▀ĪŻŽ¹┘Mš▀Ę┤Ž“╝µ╚▌▓ó─▄Öz▓ķĄĮę╗éĆ░³║¼ūĘ█Öą┼ŽóĄ─Ž¹ŽóŻ¼ęįų«Ū░Thrift ģf(xi©”)ūh├Ķ╩÷Ą─ĘĮ╩ĮĘ┤ą“┴ą╗»ā╚╚▌ĪŻ×ķ┴╦─▄ē“īŹ¼F(xi©żn)╔Ž╩÷ĘĮ╩ĮŻ¼╬ęéāąĶę¬┐═æ¶Č╦ĘŌčb╦¹éāį┌ūĘ█ÖŽĄĮy(t©»ng)ųą╩╣ė├Ą─ą“┴ą╗»/Ę┤ą“┴ą╗»īŹ¼F(xi©żn)Ż¼ė├ė┌▓╗░³║¼ūĘ█Öą┼ŽóĄ─Ž¹Žó║═░³║¼ūĘ█Öą┼ŽóĄ─Ž¹Žóų«ķgĄ─ūxīæ▐DōQĪŻ
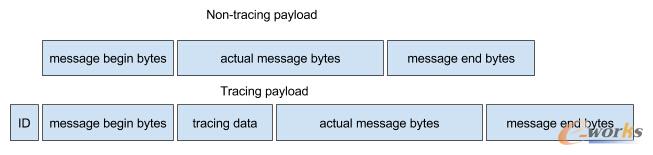
HTTP šłŪ¾ūĘ█Öų¦│ų
į┌Knewtonā╚▓┐Ą─ę╗ą®╗∙ĄAśŗ╝■ųą╦∙ėąī”═Ōķ_Ę┼Ą─╣Ø(ji©”)³cČ╝╩Ū╗∙ė┌HTTPĄ─Ż¼╬ęéāąĶę¬ęįę╗ĘN║å▒ŃĄ─ĘĮ╩Įį┌HTTPšłŪ¾ųą▓Õ╚ļąĶę¬öyĦĄ─ūĘ█Öą┼ŽóĪŻ
▀@éĆīŹ¼F(xi©żn)ŲüĒ║▄║åå╬Ż¼ę“×ķHTTPšłŪ¾ų¦│ųį┌Ž¹ŽóŅ^ųąĘ┼╚ļ╚╬ęŌöĄō■ĪŻĖ∙ō■rfc2047Ą─Ą┌5š┬╣Ø(ji©”)ųąĄ─ā╚╚▌Ż¼╬©ę╗Ą─ģó┐╝╩Ūį┌Ę┼ų├ūįČ©┴xĄ─Ž¹ŽóŅ^ąĶę¬×ķ╦¹éā╝ė╚ļŪ░ŠY’X-‘ĪŻ
╬ęéā▒Ż│ųZipkiné„Įy(t©»ng)▓óŪę╩╣ė├ę╗Ž┬ś╦Ņ}é„▓źą┼ŽóŻ║
- X-B3-TraceId
- X-B3-SpanId
- X-B3-ParentSpanId
Knewton Ą─Ę■äšų„ę¬╩╣ė├Jetty HTTP Server ║═ Apache HTTP ClientĪŻ╦∙ėąę└ō■▀@ā╔ĘNųąķg╝■śŗĮ©Ą─ĒŚ─┐Č╝─▄ęį▒ŃĮ▌Ą─ĘĮ╩ĮīŹ¼F(xi©żn)ī”HTTPŽ¹ŽóŅ^Ą─▓┘ū„ĪŻ
Jetty Ę■äššłŪ¾▒╗┬Ęė╔ĄĮę╗éĆ ServletĪŻū„×ķ▀@éĆ┬Ęė╔Ą─ę╗▓┐ĘųŻ¼ Jetty į╩įSšłŪ¾║═╗žæ¬═©▀^ę╗ŽĄ┴ą▀^×VĪŻ╬ęéāėXĄ├╠Ä└ĒūĘ█ÖöĄō■Ż¼▀@╩ŪūŅ└ĒŽļĄ─ĪŻ«ö╚╬║╬é„╚ļšłŪ¾ĖĮĦĖ·█ÖöĄō■Ņ^ĢrŻ¼╬ęéāśŗįņĄ─┐ńöĄō■Ģ■╠ßĮ╗ĄĮ DataManager ĪŻ
┼c Apache HTTP ┐═æ¶Č╦ę╗ŲŻ¼╬ęéā╩╣ė├ę╗éĆ HttpRequestInterceptor ║═ HttpResponseInterceptorŻ¼╦³▒╗įOėŗ│╔┼cŅ^▓┐ā╚╚▌─▄Į╗╗źŻ¼▓ó─▄ą▐Ė─╦¹éāĪŻ▀@ą®örĮžŲ„╩╣ė├ DataManagerŻ¼ ▓ó─▄Å─Ņ^ųąūx│÷ūĘ█ÖöĄō■Ż¼Ę┤ų«ęÓ╚╗ĪŻ
Guice
┤¾ČÓöĄ╚╦▓╗╩ņŽż Guice Ż¼▀@╩Ūę╗éĆ╣╚ĖĶķ_░l(f©Ī)Ą─ę└┘ćĻPŽĄ╣▄└Ē┐“╝▄ĪŻTDist ╝»│╔ĄĮ╬ęéā¼F(xi©żn)ėąĄ─Ę■äš─ŻēKŻ¼─Ū├┤╬ęéāĄ─┐═æ¶Č╦īóĖ³║åØŹĪóĖ³╔┘│÷ÕeŻ¼╬ęéāę└┐┐Ą─Š═╩Ū Guice Ż¼▓óŪęīŹ¼F(xi©żn)┴╦ČÓéĆ─ŻēK┐╔ęįūī╬ęéāĄ─┐═æ¶Č╦Ė³ęūė┌░▓čbĪŻGuice ╠Ä└Ēę└┘ćė┌į┌ī”Ž¾īŹ└²╗»Ų┌ķgūó╚ļŻ¼į┌Į╗ōQĮė┐┌ę▓─▄Ė³║åØŹĪŻ╚ń╣¹═©▀^▀@Ų¬╬─š┬─ŃęčĮøķ_╩╝╦╝┐╝╝»│╔ TDist Ż¼─Ū├┤┬ĀŲüĒ║▄Å═ļsĪŻ║▄ČÓĢr║“Ż¼╬ęéāĄ─┐═æ¶Č╦ąĶę¬░▓čbĖĮ╝ėĄ─ Guice ─ŻēKŻ¼▀@ą®─ŻēKīóĮēČ©ĄĮ╬ęéāĄ─ūĘ█ÖīŹ¼F(xi©żn)╔ŽŻ¼īŹ¼F(xi©żn)¼F(xi©żn)ėąĄ─ Thrift Įė┐┌ĪŻ▀@ę▓ęŌ╬Čų°Ż¼╬ęéāĄ─┐═æ¶Č╦▓╗─▄īŹ└²╗»╚╬║╬╬ęéāūĘ█ÖåóäėĄ─śŗįņĪŻ¤ošō╩▓├┤Ģr║“Ż¼ę╗éĆ TDist ┐═æ¶Č╦║÷┬įĮēČ©ę╗ą®¢|╬„Ż¼Guice Č╝Ģ■į┌ŠÄūgĢr═©ų¬╬ęéāĄ─┐═æ¶Č╦ĪŻ╬ęéā░č║▄ČÓą─╦╝Ę┼į┌╚ń║╬ųŲČ©╬ęéāĄ─ Guice ─ŻēKīė┤╬ĮYśŗ╔ŽŻ¼ę“┤╦ TDist ▓╗Ģ■┼c╬ęéāĄ─┐═æ¶Č╦ø_═╗Ż¼╬ęéāČ╝║▄ąĪą─Ż¼¤ošō╩▓├┤Ģr║“Ż¼╬ęéāČ╝▒žĒÜ▒®┬Čį¬╦žĄĮ═Ō▓┐╩└ĮńĪŻ
ūĘ█ÖŽ¹Žó┐éŠĆ
╦∙ėą╬ęéāĄ─┐═æ¶Ę■äšį┌╩╣ė├ų«Ū░Č╝Ģ■Ę┼ų├ūĘ█ÖöĄō■Ż¼ūĘ█ÖŽ¹Žó┐éŠĆ╩Ū═©▀^ Zipkin ╩š╝»Ų„üĒ│ų└m(x©┤)╩š╝»Ą─ĪŻ ╬ęéāĄ─ā╔éĆ▀xĒŚ╩Ū Kafka ║═ KinesisŻ¼▓╗▀^ūŅĮK╬ęéā▀xō±┴╦ Kinesis ĪŻ╬ęéā┐╝æ]ĄĮ Kafka ╩Ūę“×ķ Knewton ęčĮøĘĆ(w©¦n)Č©▓┐╩ Kafka ║▄ČÓ─ĻĪŻį┌─ŪĢrŻ¼╬ęéāĄ─ Kafka ╝»╚║ę╗ų▒╩╣ė├╬ęéāĄ─ūė╩┬╝■┐éŠĆŻ¼į┌╔·«aŁh(hu©ón)Š│ųą├┐├ļ«a╔·│¼▀^300ŚlŽ¹ŽóĪŻ╬ęéā│§▓Į╣└ėŗīó│¼▀^ 400Ż¼000 ŚlĄ─Ė·█Öą┼ŽóŻ¼├┐├ļų╗ėą▓┐Ęų▀Mąą╝»│╔ĪŻ╔·«aŽĄĮy(t©»ng)┼cāx▒ĒöĄō■╩╣╬ęéāŠoÅłĪŻKinesis ╦Ų║§╩Ūę╗éĆėą╬³ę²┴”Ą─╠µ┤·Ż¼╦³īó╬ęéāÅ─ Kafka Ę■äšŲ„ĘųļxŻ¼▀@ų╗╩Ū╔·«aöĄō■Ż¼Č°▓╗╩Ūāx▒Ē╔ŽĄ─öĄō■ĪŻį┌īŹ¼F(xi©żn)Ą─Ģr║“Ż¼Kinesis ╩Ūę╗éĆą┬Ą─ AWS Ę■䚯¼╬ęéāī”╦³║▄╩ņŽżĪŻ╦³Ą─ārĖ±Ż¼═╠═┬─▄┴”Ż¼▓╗ė├╠½ČÓŠSūoŻ¼▀@ą®┤┘│╔┴╦╬ęéā▀_│╔ę╗ų┬ĪŻ┐éĄ─üĒšfŻ¼╬ęéāęčĮøØMęŌ╦³Ą─ąį─▄║═ĘĆ(w©¦n)Č©ąįĪŻ╦³ø]ėą Kafka ─Ū├┤┐ņŻ¼Ą½╩Ū Kafka öĄō■«a╔·Ą─ąį┘|Ż¼╦³Å─«a╔·ĄĮöz╚ļ SLA ╔§ų┴ę¬ÄūĘųńŖĪŻūįÅ─╬ęéā▓┐╩ūĘ█ÖŽ¹Žó┐éŠĆĄĮ╔·«aŁh(hu©ón)Š│Ż¼╬ęéāę▓║▄─▄╚▌ęūöUš╣┤¾┴┐ KinesisŻ¼ Ūę▓╗Ģ■ę²Ų╚╬║╬Õ┤ÖCĪŻ
ūĘ█ÖöĄō■Ą─┤µā”
╦∙ėą╬ęéāūĘ█ÖĄ─öĄō■Č╝Ģ■▒╗Ę┼į┌ūĘ█ÖöĄō■┤µā”ĪŻöĄō■Ę┼į┌─Ū└’╩Ūėąę╗éĆ┼õų├ĢrķgĄ─Ż¼▓óŪęė╔ Zipkin ▓ķįāĘ■äš’@╩Šį┌ UI ╔ŽĪŻZipkin ╠ß╣®┴╦┤¾┴┐ķ_Žõ╝┤ė├Ą─öĄō■┤µā”Ż¼░³└© CassandraŻ¼ RedisŻ¼MongoDBŻ¼ Postgres ║═ MySQLĪŻ╬ęéāī” Cassandra ║═ DynamoDB ū÷▀^īŹ“ׯ¼▀@ų„ę¬╩Ūę“×ķ╬ęéāį┌ Knewton ųą½@Ą├Ą─┴Ģęį×ķ│ŻĄ─ų¬ūRŻ¼ūŅĮK╬ęéā▀Ć╩Ū▀xō±┴╦üå±R▀dĄ─ Elasticache Redis ĪŻŽ┬├µ▀@ą®╩Ū╬ęéāū÷│÷▀@éĆøQČ©Ą─ūŅųžę¬įŁę“ĪŻ
- ╗©į┌╔·«a╔ŽĄ─ĢrķgŻ¼╬ęéā▀Ćø]õüķ_Š═ę¬Į╗ĖČ┴╦Ż¼▓óŪęŻ¼╬ęéā▀ĆꬊSūoę╗éĆą┬Ą─╝»╚║
- │╔▒Š
- ┼c Zipkin ╝»│╔Ė³║åå╬Ż¼┤·┤aĖ³╔┘
- į┌öĄō■╔Žų¦│ųTTLs
ĮY šō
¼F(xi©żn)į┌į┌ KnewtonŻ¼ ╬ęéāĄ─ūĘ█ÖĮŌøQĘĮ░Ėį┌š¹éĆŁh(hu©ón)Š│ųąęčĮø▀\ąą║├ČÓéĆį┬┴╦ĪŻ─┐Ū░╦³ęčĮø▒╗ūC├„╩ŪĘŪ│ŻėąārųĄĄ─ĪŻ╬ęéāų╗ėąį┌ķ_╩╝▓┴│²─ŪéĆ├µĄ─Ģr║“Ż¼╬ęéā▓┼┐╔ęįūĘ█Ö▓óŪę╩š╝»ĢrķgöĄō■ĪŻ╬ęéāėą║▄ČÓėą╚żĄ─īŹ¼F(xi©żn)Ż¼▓óŪęį┌ Knewton Į╗ĖČŻ¼ų«║¾Ż¼╬ęéāŠ═└ĒĮŌ┴╦▀@éĆöĄō■Ą─ārųĄĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║Ęų▓╝╩ĮūĘ█ÖŽĄĮy(t©»ng)╝▄śŗ┼cįOėŗ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/support/11121520058.html



▀xą═ųąą─")
¾w“×ųąą─")
«aŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")














