



0 ę²čį
ļSų°ļŖūė╔╠䚥─░lš╣Ż¼Ų¾śIĄ─«aŲĘįĮüĒįĮ┌ģŽ“ė┌═¼┘|╗»Ż¼āHāHę└┐┐«aŲĘ▒Š╔Ē║▄ļyį┌╚š┌ģ╝ż┴ęĄ─ĖéĀÄųą╚Īä┘Ż¼╦∙ęįė·üĒė·ČÓĄ─Ž╚▀MŲ¾śIīóųž³cÅ─Ī░ęį«aŲĘ×ķųąą─Ī▒Ž“Ī░ęį┐═æ¶×ķųąą─Ī▒Ą─ą┬ą═╔╠śI─Ż╩Į▐DęŲŻ¼┐═æ¶ĻPŽĄ╣▄└Ēę▓Š═æ¬▀\Č°╔·ĪŻ┐═æ¶ĻPŽĄ╣▄└Ē×ķŲ¾śIĮøĀIĪóøQ▓▀║═╣▄└Ē╠ß╣®┴╦ę╗ĘNą┬ą═╔╠śI─Ż╩ĮĪŻ
«öĮ±įSČÓŲ¾śIĄ─öĄō■Äņ╗“öĄō■é}ÄņųąČ╝╦č╝»║═┤µā”┴╦┤¾┴┐ĻPė┌┐═æ¶Ą─īÜ┘FöĄō■Ż¼▀@ą®öĄō■║Ł╔w┴╦Å─┐═æ¶╗∙▒ŠöĄō■Īó┘Å┘Iėøõø╝░┐═æ¶Ę┤üĄ─Ė„éĆŁh╣ØĪŻ│õĘų└¹ė├▀@ą®öĄō■Ż¼╔Ņ╚ļĘų╬÷Īó═┌Š“ļ[║¼į┌▀@ą®öĄō■ųąĄ─ėąė├ą┼ŽóŻ¼īóėąų·ė┌Ų¾śIĖ³║├Ąž╣▄└Ē┐═æ¶ĻPŽĄŻ¼īŹ¼FCRMĄ─╣”─▄║═─┐ś╦ĪŻöĄō■═┌Š“╝╝ągĄ──┐Ą─╩Ūī”▀@ą®öĄō■▀Mąą│ķ╚ĪĪó▐DōQĪóĘų╬÷║═─Żą═╗»╠Ä└ĒŻ¼Å─ųą╠ß╚Ī▌oų·╔╠śIøQ▓▀Ą─ĻPµIąįöĄō■┬╔ĪŻ┐═æ¶ĻPŽĄ╣▄└Ē╩ŪöĄō■═┌Š“╝╝ągį┌Ų¾śIøQ▓▀ų¦│ųŽĄĮyųąĄ─ųžę¬æ¬ė├ŅIė“ĪŻ
1 CRM┼cöĄō■═┌Š“Ą─╗∙▒Š└Ēšō
1.1 CRMĄ─Ė┼─Ņ
┐═æ¶ĻPŽĄ╣▄└Ē(Customer Relationship ManagementŻ¼║åĘQCRM)╩ŪųĖī”Ų¾śI║═┐═æ¶ų«ķgĄ─Į╗╗ź╗Ņäė▀Mąą╣▄└ĒĄ─▀^│╠ĪŻ╦³╩ŪŲ¾śI×ķ┴╦╠ßĖ▀║╦ą─ĖéĀÄ┴”Ż¼═©▀^Ė─▀Mī”┐═æ¶Ą─Ę■äš╦«ŲĮŻ¼╠ßĖ▀┐═æ¶ØMęŌČ╚║═ųęš\Č╚╦∙śõ┴óŲüĒĄ─ęį┐═æ¶×ķ║╦ą─Ą─ĮøĀI└Ē─ŅŻ╗╩Ū═©▀^ķ_š╣ŽĄĮy╗»Ą─└Ēšō蹊┐Ż¼ā×╗»Ų¾śIĮM┐Ś¾wŽĄ║═śIäš┴„│╠Ż¼īŹ╩®ė┌Ų¾śIĄ─╩ął÷ĀIõNĪóõN╩█ĪóĘ■äšĪó╝╝ągų¦│ųĄ╚┼c┐═涎ÓĻPĄ─ŅIė“Ż¼ų╝į┌Ė─╔ŲŲ¾śI┼c┐═æ¶ų«ķgĻPŽĄĄ─ą┬ą═ÖCųŲŻ╗ę▓╩ŪŲ¾śI═©▀^╝╝ąg═Č┘YŻ¼Į©┴ó─▄╦č╝»ĪóĖ·█Ö║═Ęų╬÷┐═æ¶ą┼ŽóĄ─ŽĄĮyŻ¼äōįņ▓ó╩╣ė├Ž╚▀MĄ─ą┼Žó╝╝ągĪó▄øė▓╝■Ż¼ęį╝░ā×╗»Ą─╣▄└ĒĘĮĘ©║═ĮŌøQĘĮ░ĖĄ─┐é║═ĪŻ
1.2 öĄō■═┌Š“Ą─Č©┴x
öĄō■═┌Š“(╗“KDD)╩ŪÅ─┤¾┴┐öĄō■ųą╠ß╚Ī│÷┐╔ą┼Ą─Īóą┬ĘfĄ─Īóėąą¦Ą─▓ó─▄▒╗╚╦└ĒĮŌĄ──Ż╩ĮĄ─╠Ä└Ē▀^│╠Ż¼▀@ĘN╠Ä└Ē▀^│╠╩ŪĘŪŲĮĘ▓Ą─▀^│╠ĪŻ
öĄō■═┌Š“Å─öĄō■╝»ųąūRäe│÷Ą──Ż╩ĮüĒ▒Ē╩ŠĄ─ų¬ūRĄ─╠Ä└Ē▀^│╠╩Ūę╗éĆČÓ▓Į¾EĄ─╠Ä└Ē▀^│╠Ż¼ČÓ▓Į¾Eų«ķgŽÓ╗źė░ĒæŻ¼Ę┤Å═š{š¹Ż¼ą╬│╔ę╗ĘN┬▌ą²╩Į╔Ž╔²▀^│╠Ż¼═┌Š“Ą─ų¬ūR▒Ē╩Š×ķĖ┼─Ņ(Concepts)ĪóęÄät(Rules)ĪóęÄ┬╔(Regularities)Ą╚ą╬╩ĮĪŻ
1.3 öĄō■═┌Š“╝╝ągį┌CRMųąĄ─æ¬ė├
ļSų°ą┼Žó╝╝ągĄ─čĖ╦┘░lš╣Ż¼╠žäe╩ŪöĄō■Äņ╝╝ąg║═ėŗ╦ŃÖCŠWĮjĄ─ÅVĘ║æ¬ė├Ż¼Ų¾śIōĒėąĄ─öĄō■┴┐╝▒äĪį÷┤¾ĪŻį┌┤¾┴┐Ą─öĄō■┼cą┼ŽóųąŻ¼╠N▓žų°Ų¾śI▀\ū„Ą─└¹▒ūĄ├╩¦ĪŻ╚¶─▄ē“ī”▀@ĘN║Ż┴┐Ą─öĄō■┼cą┼Žó▀Mąą┐ņ╦┘ėąą¦Ąž╔Ņ╚ļĘų╬÷║═╠Ä└ĒŻ¼Š═─▄Å─ųąšę│÷ęÄ┬╔║═─Ż╩ĮŻ¼½@╚Ī╦∙ąĶų¬ūRŻ¼Ä═ų·Ų¾śIĖ³║├Ąž▀MąąŲ¾śI▀\╗IøQ▓▀ĪŻöĄō■═┌Š“╝╝ąg║═«aŲĘį┌▀@ĘN╩ął÷ąĶŪ¾ųąųØu░lš╣│╔╩ņŻ¼▓ó╩╣Ų¾śI½@Ą├śOĖ▀Ą─═Č┘Y╗žł¾ĪŻį┌Ų¾śI╣▄└Ē┐═æ¶╔·├³ų▄Ų┌Ą─Ė„éĆļAČ╬Č╝Ģ■ė├ĄĮöĄō■═┌Š“╝╝ągĪŻöĄō■═┌Š“─▄ē“Ä═ų·Ų¾śI┤_Č©┐═æ¶Ą─╠ž³cŻ¼Å─Č°┐╔ęį×ķ┐═æ¶╠ß╣®ėąßśī”ąįĄ─Ę■äšĪŻ
2 öĄō■═┌Š“ųąĄ─øQ▓▀śõ╦ŃĘ©
2.1 øQ▓▀śõĄ─╗∙▒Š└Ēšō
╦∙ų^øQ▓▀śõŠ═╩Ūę╗éĆŅÉ╦Ų┴„│╠łDĄ─śõą═ĮYśŗŻ¼ŲõųąśõĄ─├┐éĆā╚▓┐ĮY³c┤·▒Ēī”ę╗éĆī┘ąį(╚ĪųĄ)Ą─£yįćŻ¼ŲõĘųų¦Š═┤·▒Ē£yįćĄ─├┐éĆĮY╣¹Ż╗Č°śõĄ─├┐éĆ╚~ĮY³cŠ═┤·▒Ēę╗éĆŅÉäeĪŻśõĄ─ūŅĖ▀īėĮY³cŠ═╩ŪĖ∙ĮY³cĪŻ×ķ┴╦ī”╬┤ų¬öĄō■ī”Ž¾▀MąąĘųŅÉūRäeŻ¼┐╔ęįĖ∙ō■øQ▓▀śõĄ─ĮYśŗī”öĄō■╝»ųąĄ─ī┘ąįųĄ▀Mąą£yįćŻ¼Å─øQ▓▀śõĄ─Ė∙ĮY³cĄĮ╚~ĮY³cĄ─ę╗Śl┬ĘÅĮŠ═ą╬│╔┴╦ī”ŽÓæ¬ī”Ž¾Ą─ŅÉäeŅA£yĪŻ
2.2 øQ▓▀śõĄ─╔·│╔
øQ▓▀śõĄ─╔·│╔Ą─╗∙▒Š╦ŃĘ©╩ŪžØą─╦ŃĘ©ĪŻ╦³ęįūįĒöŽ“Ž┬▀fÜwĄ─Ė„éĆō¶ŲŲĘĮ╩ĮśŗįņøQ▓▀śõĪŻĮ©┴óę╗┐├øQ▓▀śõ═©│ŻĘų×ķā╔éĆļAČ╬Ż║Į©śõ(Tree Building)║═╝¶ų”(Tree Pruning)ĪŻ
2.3 øQ▓▀śõ╦ŃĘ©
SPRINT╦ŃĘ©╬³╚Ī┴╦SLIQ╦ŃĘ©Ą─ŅA┼┼ą“╝╝ągŻ¼Ą½╦³╩╣ė├▓╗═¼Ą─öĄō■ĮYśŗŻ¼Ž¹│²┴╦╦∙ėąĄ─ā╚┤µŽ▐ųŲŻ¼Ūęęūė┌▓óąą╗»Ż¼▀Mę╗▓Įį÷ÅŖ┴╦┐╔╔ņ┐sąįĪŻ╦∙▓╔ė├Ą─╝¶ų”╦ŃĘ©┼cSLIQŽÓ═¼ĪŻę“×ķøQ▓▀śõ╦ŃĘ©ųąĄ─ĻPµIå¢Ņ}╩ŪĮ©śõŻ¼Č°Į©śõļAČ╬┼c╝¶ų”ļAČ╬ŽÓ▒╚Ż¼Ųõ╦∙ąĶĢrķg▀h▀h┤¾ė┌╝¶ų”╦∙ąĶĢrķgĪŻŽ┬├µī”SPRINT╦ŃĘ©ųąĄ─ÄūéĆĻPµI▓Į¾E╝ėęįĻU├„ĪŻ
2.3.1 öĄō■ĮYśŗ
ī┘ąį▒Ē(Attribute List)Ż║SPRINT╦ŃĘ©╩╣ė├ę╗ĘNą┬Ą─ī┘ąį▒ĒöĄō■ĮYśŗŻ¼┤µĘ┼ŅÉ║═rid(index of the record)ą┼ŽóĪŻ├┐éĆī┘ąįŠ▀ėąę╗éĆī┘ąį▒ĒŻ¼▒Ēųą├┐Ślėøõøė╔ī┘ąįųĄĪóŅÉś╦╠¢║═ridĮM│╔ĪŻ│§╩╝ĀŅæBŽ┬Ż¼ī”öĄųĄą═ī┘ąį░┤Ųõī┘ąįųĄ▀Mąą┼┼ą“ĪŻ╚ń╣¹ā╚┤µ▓╗ē“Ż¼ī┘ąį▒Ē┐╔ęį±v┴¶┤┼▒PĪŻūŅ│§Ą─Ė∙ō■ė¢ŠÜ╝»╦∙äōĮ©Ą─ī┘ąį▒ĒŠ∙ųĖŽ“śõĖ∙Ż¼ļSų°śõĄ─╔·ķLŻ¼«ö╣سcĘų┴čĢrŻ¼ī┘ąį▒Ē▒╗äØĘųŻ¼▓óį┌ĮY╣¹ūė┼«╣سcĘų▓╝Ż¼«ö▒ĒäØĘųĢrŻ¼▒ĒųąėøõøĄ─┤╬ą“ŠS│ų▓╗ūāŻ¼ę“┤╦Ż¼äØĘų▒Ē▓╗ąĶę¬ųžą┬┼┼ą“ĪŻ
ų▒ĘĮłD(Histograms)Ż║SPRINT╦ŃĘ©ųąĄ─ų▒ĘĮłD╩Ūė├ė┌ėŗ╦Ń├┐ę╗ĘNĘų┴čĘĮ░ĖĄ─giniųĖöĄųĄĪŻī”ė┌öĄųĄą═ī┘ąįŻ¼├┐ę╗éĆ╣سcŻ¼ī”æ¬ā╔éĆų▒ĘĮłDŻ¼Ęųäeė├CaboveŻ¼║═Cbelow▒Ē╩ŠĪŻ╦³éā▒Ē╩Šī┘ąįėøõøį┌ĮoČ©╣سc╔ŽĄ─ŅÉĘų▓╝ŪķørĪŻ▒ķÜvī┘ąį▒ĒĢrŻ¼ų▒ĘĮłDę▓ļSų«Ė─ūāŻ¼ŲõųąŻ║Cabove▒Ē╩Š╬┤Æ▀├Ķ▀^Ą─ī┘ąįėøõøĄ─ŅÉĘų▓╝ŪķørĪŻCbelow▒Ē╩Š╝║Æ▀├Ķ▀^Ą─ī┘ąįėøõøĄ─ŅÉĘų▓╝ŪķørĪŻī”ė┌ļx╔óī┘ąįŻ¼├┐éĆ╣سcī”æ¬ėąę╗éĆų▒ĘĮłDŻ¼╦³░³║¼ĮoČ©ī┘ąį╔Ž├┐ę╗éĆųĄĄ─ŅÉĘų▓╝ŪķørĪŻ
2.3.2 ╣سcĄ─Ęų┴čĘĮĘ©
ėŗ╦ŃūŅ╝čĘų┴čŻ║į┌SPRINT╦ŃĘ©ųąŻ¼▓╔ė├giniųĖöĄū„×ķįuār╣سcĘų┴č┘|┴┐Ą─ģóöĄĪŻīżšęūŅ╝čĘų┴čĄ─ĘĮĘ©╩ŪŻ║▒ķÜv├┐ę╗éĆ╣سcĄ─ī┘ąį▒ĒŻ¼═¼Ģrįuār├┐éĆī┘ąį▒ĒĄ─Ęų┴čārųĄŻ¼═Ļ│╔▒ķÜv║¾Ż¼░³║¼gini╦„ę²ūŅĄ═Ą─Ęų┴č³cĄ─ī┘ąįū„×ķūŅ╝čĘų┴čĘĮ░ĖĪŻ
ł╠ąą╣سcĘų┴čŻ║äōĮ©╣سcŻ¼ł╠ąą╣سcĘų┴č▀@ę╗▓ĮĄ─ų„ę¬╚╬äš╩Ūī”╣سcĄ─├┐ę╗éĆī┘ąį▒Ē▀MąąäØĘųĪŻ░³║¼Ęų┴čī┘ąįĄ─ī┘ąį▒ĒĄ─äØĘų╩«Ęų╚▌ęūĪŻ╝┤═©▀^▒ķÜvī┘ąį▒ĒŻ¼æ¬ė├Ęų┴čŚl╝■╚ź£yįćŻ¼╚╗║¾Ė∙ō■£yįćĄ─ĮY╣¹īóėøõøĘųäeĘ┼╚ļ├┐ę╗éĆūė╣سcĄ─ī┘ąį▒ĒųąĪŻ
2.3.3 ╦ŃĘ©Ą─╝¶ų”
SPRINTĄ─╝¶ų”╦ŃĘ©MDLī┘ė┌╩┬║¾ą▐╝¶(post pruning)╦ŃĘ©ĪŻ═©│ŻĄ─╩┬║¾╝¶ų”Ą─öĄō■į┤▓╔ė├ę╗éĆTraining SetĄ─ę╗éĆūė╝»╗“š▀┼cTraining Set¬Ü┴óĄ─öĄō■╝»▀Mąą▓┘ū„ĪŻMDL(Minimum Description Length)Ą──┐ś╦╩Ū╔·│╔ę╗┐├├Ķ╩÷ķLČ╚ūŅąĪĄ─øQ▓▀śõĪŻMDLįŁ└ĒšJ×ķŻ║ūŅāץ─ŠÄ┤a─Żą═╩Ū├Ķ╩÷öĄō■┤·ārūŅąĪĄ──Żą═ĪŻ╚ń╣¹─Żą═Mī”öĄō■╝»D▀MąąŠÄ┤aŻ¼─Ū├┤├Ķ╩÷┤·ārŻ║cost(DIM)=cost(D|M)+cost(M)
ŲõųąŻ║cost(M|D)▒Ē╩Š▒Ē╩ŠŠÄ┤aĄ─┐é┤·ārŻ╗cost(D|M)▒Ē╩Šė├─Żą═Mī”öĄō■DŠÄ┤aĄ─ŠÄ┤a┤·ārŻ¼å╬╬╗bitsŻ¼cost(M)▒Ē╩Š├Ķ╩÷─Żą═▒Š╔Ē╦∙ąĶĄ─ŠÄ┤aķLČ╚ĪŻ
2.3.4 SPRINT╦ŃĘ©Ą─įuār
SPRINT╦ŃĘ©Ą─ā׳c╩Ū├„’@Ą─Ż¼╦³┐é─▄ē“╔·│╔ę╗┐├ūŅ║├Ą─śõĪŻĄ½╩ŪŻ¼▀@ĘN╦ŃĘ©į┌╠Ä└ĒöĄųĄą═ī┘ąįĄ─Ģr║“ę▓ėą├„’@Ą─▓╗ūŃŻ║1)╦³ąĶę¬ī”š¹éĆė¢ŠÜ╝»▀MąąŅAŽ╚┼┼ą“Ż╗2)ī”╦∙ėąĄ─öĄųĄą═ī┘ąįĄ─▓╗═¼ųĄČ╝ę¬▀MąąginiųĖöĄĄ─įu╣└ĪŻ
▀@ĘNĘĮĘ©╣żū„┴┐║▄┤¾Ż¼╠žäe╩Ūī”ė┌│¼┤¾öĄō■╝»Ż¼«öī┘ąį║¼ėą┤¾┴┐Ą─▓╗═¼╚ĪųĄĢrŻ¼ą¦┬╩ĘŪ│ŻĄ═ĪŻ×ķ┴╦£p╔┘SPRINT╦ŃĘ©Ą─ėŗ╦Ń┴┐Ż¼╠ßĖ▀╦ŃĘ©Ą─ą¦┬╩Ż¼╬ęéāĄ─╦ŃĘ©ų„ę¬Å─╠Ä└ĒöĄųĄą═ī┘ąįĘĮ├µī”SPRINT╦ŃĘ©▀MąąĖ─▀MĪŻ
3 SPRINT╦ŃĘ©Ą─Ė─▀M
3.1 Ė─▀M╦ŃĘ©Ą─├Ķ╩÷
į┌Ė─▀MĄ─╦ŃĘ©ųąŻ¼▓╔ė├īÆČ╚ā׎╚Ą─▓▀┬įüĒśŗĮ©øQ▓▀śõ║═╩╣ė├giniųĖöĄüĒįu╣└öĄųĄą═ī┘ąįĪŻ╬ęéāĖ─▀MĄ─ų„ę¬▓┐ĘųŠ═╩Ūį┌øQ▓▀śõĄ─śŗĮ©ļAČ╬ī”öĄųĄą═ī┘ąįĄ─╠Ä└Ē▓┐ĘųŻ¼▓╔ė├┴╦╔Ž╩÷╠ß│÷Ą─╝āģ^ķgÜw╝sĄ─ĘĮĘ©üĒ╠Ä└ĒöĄųĄą═ī┘ąįĪŻĖ─▀M╦ŃĘ©Ą─įö╝Ü├Ķ╩÷╚ń╦ŃĘ©3.1╦∙╩ŠĪŻ
╦ŃĘ©3.1Ė─▀MĄ─SPRINT╦ŃĘ©Ą─├Ķ╩÷

į┌╦ŃĘ©3.1ųąŻ¼╝»║ŽTĪóT1ĪóT2Ęųäe┤·▒ĒśõųąĄ─ĮY³cŻ¼ŲõųąT1║═T2╩ŪTĄ─ā╔éĆĘųų¦ĮY³cĪŻūŅ║¾╔·│╔Ą─øQ▓▀śõ╩Ūę╗┐├Č■▓µśõĪŻ
3.2 ā╔ĘN╦ŃĘ©Ą─▒╚▌^Ęų╬÷
ė╔ė┌Ė─▀MĄ─╦ŃĘ©║═SPRINT╦ŃĘ©Ą─▓╗═¼ų«╠Äų„ę¬╩Ūį┌śŗĮ©øQ▓▀śõļAČ╬ī”öĄųĄą═ī┘ąįĄ─╠Ä└ĒĘĮĘ©Ż¼╦ŃĘ©Ą─Ęų╬÷ų„ę¬╩Ū▒╚▌^ā╔ĘN╦ŃĘ©į┌śõĄ─śŗĮ©ļAČ╬Ą─I/OąĶŪ¾║═Ģrķg┤·ārĪŻ╬ęéāĄ─▒╚▌^Ęų×ķŅA╠Ä└ĒļAČ╬║═øQ▓▀śõųą├┐éĆĮY³cĄ─śŗĮ©ļAČ╬ĪŻ
į┌Ė─▀MĄ─╦ŃĘ©ųąŻ¼╣└╦Ń├┐ę╗éĆģ^ķg▀ģĮńĄ─giniųĄĄ─Ģrķg┤·ār×ķO(qc)Ż╗øQČ©├┐éĆĘŪ╝āģ^ķgĄ─ėøõøŻ¼Į©┴ó┼RĢrģ^ķgī┘ąį▒ĒąĶę¬ę╗┤╬ūx║═ę╗┤╬īæ▓┘ū„Ą─Ģrķg┤·ār×ķO(n)Ż╗ī”├┐éĆĘŪ╝āģ^ķg┼┼ą“║═ėŗ╦Ń├┐éĆĘŪ╝āģ^ķgųąĄ─Š½┤_giniųĄĄ─Ģrķg┤·ār

į┌SPRINT╦ŃĘ©ųąŻ¼ī”ī┘ąį▒ĒĄ─╚½▓┐ėøõø▀Mąą┼┼ą“╩Ūš¹éĆ╠Ä└Ē▀^│╠Ą─ų„ę¬Ģrķg╗©õNĪŻį┌Ė─▀MĄ─╦ŃĘ©ųąėąą¦Ąž▒▄├Ō┴╦╚½Šų┼┼ą“Ż¼ų╗╩Ūī”ĘŪ╝āģ^ķg▀MąąŠų▓┐┼┼ą“Ż╗═¼ĢrŻ¼╝āģ^ķg▀MąąÜw╝sŻ¼£pąĪ┴╦giniųĄĄ─ėŗ╦Ń┴┐ĪŻ
4 ┐═æ¶ĘųŅÉ─Żą═Ą─Į©┴ó
4.1 Į©┴óöĄō■═┌Š“─Żą═Ą─╗∙▒Š└Ēšō
į┌īŹ╩®öĄō■═┌Š“ų«Ū░Ż¼Ž╚ųŲČ©▓╔╚Ī╩▓├┤śėĄ─▓Į¾EŻ¼├┐ę╗▓ĮČ╝ū÷╩▓├┤Ż¼▀_ĄĮ╩▓├┤śėĄ──┐ś╦╩Ū▒žę¬Ą─ĪŻ║▄ČÓ▄ø╝■╣®æ¬╔╠║═öĄō■═┌Š“╣½╦ŠČ╝╠ß╣®┴╦ę╗ą®öĄō■═┌Š“▀^│╠─Żą═Ż¼CRISP-DM(Cross Industry Standard Process for Data Mining)╩Ū╣½šJĄ─ĪóūŅėąė░ĒæĄ─öĄō■═┌Š“ĘĮĘ©šōų«ę╗ĪŻCRISP-DMīóš¹éĆ═┌Š“▀^│╠Ęų×ķęįŽ┬┴∙éĆļAČ╬Ż║╔╠śI└ĒĮŌ(Business Understanding)Ż¼öĄō■└ĒĮŌ(Data Understanding)Ż¼öĄō■£╩éõ(Data Preparation)Ż¼Į©┴ó─Żą═(Modeling)Ż¼─Żą═įu╣└(Evaluation)║═─Żą═░l▓╝(Deployment)ĪŻ╚ńłD1╦∙╩ŠĪŻ
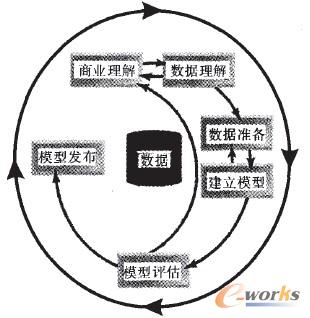
łD1 CRISP-DMöĄō■═┌Š“▀^│╠
į┌īŹļHĒŚ─┐ųąŻ¼CRISP-DM─Żą═ųąĄ─öĄō■└ĒĮŌĪóöĄō■£╩éõĪóĮ©─ŻĪóįu╣└▓ó▓╗╩Ūå╬Ž“▀\ū„Ą─Ż¼Č°╩Ūę╗éĆČÓ┤╬Ę┤Å═ĪóČÓ┤╬š{š¹Īó▓╗öÓą▐ėå═Ļ╔ŲĄ─▀^│╠ĪŻ
4.2 Į©┴ó┐═æ¶ĘųŅÉĄ──Żą═
░┤ššCRISP-DMĄ─öĄō■═┌Š“Ą─ę╗░Ń▀^│╠─Żą═Ż¼ī”ę╗éĆ┐═æ¶öĄō■╝»░┤šš┐═æ¶│ųėąĄ─┐═æ¶Ģ■åT┐©▀MąąĘųŅÉĪŻ
4.2.1 ╔╠śI└ĒĮŌ
ė├ū„£yįćĘų╬÷Ą─öĄō■╝»Food Mart 2000Ż¼╩ŪMicro Soft«aŲĘSQL Server 2000 Analysis Services╠ß╣®Ą─╩Š└²öĄō■ÄņĪŻį┌Food Mart 2000öĄō■Äņųą╠ß╣®┴╦24éĆ▒ĒŻ¼├┐ę╗éĆ▒ĒČ╝ėąę╗Č©öĄō■┴┐ĪŻŲõųąŻ¼Customer▒ĒųąČÓ▀_27éĆī┘ąįŻ¼╣▓ėą10281éĆ▓╗═¼┐═æ¶Ą─ėøõøŻ¼├┐éĆ┐═æ¶öĄō■ėøõø░³║¼ėą┐═æ¶öĄō■Ż║┐═æ¶ąš├¹ĪóąįäeĪóūĪųĘĪóļŖįÆĪó╗ķę÷ĀŅørĪó┐═æ¶│ųėąĄ─Ģ■åT┐©ŅÉą═Ą╚éĆ╚╦ą┼ŽóĪŻ╚ńłD2╦∙╩ŠĪŻ
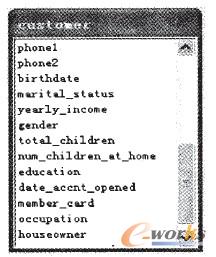
łD2 CustomeröĄō■▒Ē
4.2.2 öĄō■£╩éõ
┐═æ¶▒ĒCustomerėąČÓ▀_27éĆī┘ąįŻ¼╚ń╣¹╚½ė├üĒ▀Mąą┐═æ¶ĘųŅÉŻ¼īó╩╣╦∙Į©┴óĄ─øQ▓▀śõ▀^┤¾Īó▓╗║├└ĒĮŌŻ¼▓óŪęėąą®ī┘ąį├„’@ī”┐═æ¶▀xė├Ģ■åT┐©ø]ėą╚╬║╬žĢ½IĪŻ▒╚╚ńąš├¹ĪóļŖįÆ╠¢┤aĄ╚ĪŻį┌ķ_╩╝öĄō■═┌Š“Ū░Ż¼ė├æ¶Ģ■┐╔ęįĖ∙ō■│ŻūRĪóĮø“ץ╚ę“╦ž═©▀^│§▀xŻ¼▀x│÷ę╗ą®ų„ė^╔ŽšJ×ķ┼cĘųŅÉī┘ąįėąĻPĄ─ĪóĢ■▒╚▌^├„’@ė░ĒæĘųŅÉī┘ąį╚ĪųĄĄ─║“▀xī┘ąįŻ¼ę▓┐╔ęįė├öĄō■═┌Š“╣żŠ▀╠ß╣®Ą─ŽÓĻPĘų╬÷╝╝ągŻ¼║Y▀x│÷▀m║Žė├üĒ▀MąąĮ©─ŻĄ─ī┘ąįĪŻ
Ž┬├µ╬ęéā▀xė├Microsoft SQL Server 2005ųąĄ─Analysis Services╣żŠ▀ī”Customer▒ĒĄ─öĄō■▀MąąŽÓĻPĘų╬÷ĪŻŲõųąmember_card╩Ū╬ęéā╦∙ꬥ─ĘųŅÉī┘ąįĪŻŽÓĻPĘų╬÷Ą─ĮY╣¹╚ńłD3╦∙╩ŠŻ║
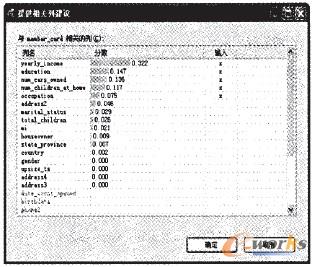
łD3 ī┘ąįŽÓĻPĘų╬÷ĮY╣¹
Å─łD3╦∙╩ŠĄ─ŽÓĻPĘų╬÷Ą─ĮY╣¹┐╔ęį┐┤ĄĮŻ¼ę¬▀Mąą╗∙ė┌Ģ■åT┐©Ą─ĘųŅÉŻ¼╬ęéā▀xō±╚ńŽ┬Ą─ī┘ąįŻ║yearly_incomeĪóeducationĪóBum_cars_ownedĪónum_children_at_homeĪóoccupationĄ╚╬ÕéĆī┘ąį▀MąąĘų╬÷ĪŻ
4.2.3 Į©┴ó─Żą═║═įu╣└
ė├Ė─▀MĄ─SPRINT╦ŃĘ©ĮŌøQ▒Šš┬Č©┴xĄ─┐═æ¶ĘųŅÉå¢Ņ}Ż¼Ęųā╔▓ĮŻ║Ą┌ę╗▓ĮŻ¼ė├ė¢ŠÜöĄō■╝»Į©┴óøQ▓▀śõ─Żą═Ż╗Ą┌Č■▓ĮŻ¼ī”─Żą═Ą─£╩┤_┬╩ė├£yįćöĄō■▀Mąą£yįćĪŻ
ė╔ė┌─Żą═▀^Ęų▀m║Žė¢ŠÜöĄō■Ż¼╚¶╩╣ė├ė¢ŠÜöĄō■įu╣└ĘųŅÉ─Żą═Ż¼┐╔─▄ī¦ų┬▀^ė┌śĘė^Ą─╣└ėŗĪŻ▒Ż│ų║═k-š█Į╗▓µ“×ūC╩Ūā╔ĘN╗∙ė┌ĮoČ©öĄō■ļSÖC╚ĪśėäØĘųĄ─Īó│Żė├Ą─įu╣└ĘųŅÉ─Żą═£╩┤_┬╩Ą─╝╝ągĪŻ▀@└’▓╔ė├▒Ż│ųĘĮĘ©ĪŻ
į┌▒Ż│ųĘĮĘ©ųąŻ¼ĮoČ©öĄō■╝»▒╗ļSÖCäØĘų│╔ā╔éƬÜ┴óĄ─╝»║ŽŻ║ė¢ŠÜ╝»║═£yįć╝»ĪŻ═©│ŻŻ¼╚²Ęųų«Č■Ą─öĄō■Ęų┼õĄĮė¢ŠÜ╝»Ż¼Ųõ╦¹╚²Ęųų«ę╗Ęų┼õĄĮ£yįć╝»ĪŻÅ─ĮoČ©öĄō■╝»ųą╚ĪśėŻ¼śŗ│╔ė¢ŠÜöĄō■╝»ĪŻė¢ŠÜöĄō■╝»┤¾ąĪŻ║10281Ī┴2/3=6854Ż¼£yįćöĄō■╝»┤¾ąĪ10281Ī┴1/3=3427ĪŻė├─│ę╗┤╬ļSÖC╚ĪśėĘĮĘ©Ą├ĄĮĄ─ė¢ŠÜ╝»║═Ė─▀MĄ─SPRINT╦ŃĘ©Į©┴óøQ▓▀śõ─Żą═ĪŻ
1)─Żą═Ą─Į©┴ó
į┌Ė─▀MĄ─SPRINT╦ŃĘ©ųąŻ¼ų╗┐╝æ]┴╦yearly_income(─Ļ╩š╚ļ)ī┘ąį║═child_Bum_at_home(į┌╝ęūė┼«öĄ)ī┘ąįū„×ķöĄųĄą═ī┘ąįŻ¼╬ęéāį┌øQ▓▀śõĄ─śŗĮ©▀^│╠ųąŻ¼īóyearly_incomeī┘ąįĘų×ķ8éĆģ^ķgŻ¼Ęųäe╩Ū(0Ż¼2]Īó(2Ż¼4]Īó(4Ż¼6]Īó(6Ż¼8]Īó(8Ż¼10]Īó(10Ż¼12]Īó(12Ż¼14]Īó(14Ż¼16]ĪŻøQ▓▀śõ╦ŃĘ©═©▀^╝¶ų”║¾┐╔ęįĄ├ĄĮ╚ńŽ┬─Żą═Ż¼╚ńłD4╦∙╩ŠĪŻ
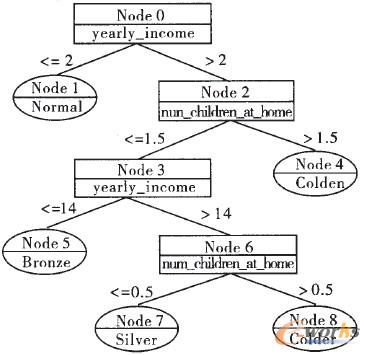
łD4 øQ▓▀śõłD╩Š
2)─Żą═Ą─įu╣└
ė├░³║¼3427ŚlėøõøĄ─£yįćöĄō■╝»ī”─Żą═▀Mąą£yįćŻ║ī”├┐Śl┐═æ¶ėøõøŻ¼Å─łD4ųąøQ▓▀śõĖ∙╣سc0ķ_╩╝Ż¼╩ūŽ╚ė├┐═æ¶yearly-income(─Ļ╩š╚ļ)▀Mąąī┘ąį£yįćŻ¼╚ń╣¹┐═æ¶Ą──Ļ╩š╚ļ╔┘ė┌Ī░2Ī▒Ż¼į┌øQ▓▀śõųąĄĮ▀_╣سc1Ż¼╚ń╣¹┐═æ¶▒ŠüĒ│ųėąĄ─Ģ■åT┐©Š═╩ŪNormalŻ¼─Ū├┤─Żą═ī”įō┐═æ¶ĘųŅÉš²┤_Ż¼Ę±ät░l╔·ĘųŅÉÕeš`Ż╗╚ń╣¹┐═æ¶Ą──Ļ╩š╚ļ┤¾ė┌Ą╚Ī░2Ī▒Ż¼ĄĮ▀_╣سc2Ż¼ę“×ķ╣سc2▓╗╩Ū╚~╣سcŻ¼▀Ćę¬ė├child_num_at_home(į┌╝ęūė┼«öĄ)ī┘ąį└^└m£yįćŻ¼┐═æ¶į┌įōī┘ąį╔ŽĄ─▓╗═¼╚ĪųĄČ°ĄĮ▀_╣سc3╗“╣سc4Ż¼╚╗║¾ī”╣سc3ė├yearly_income(─Ļ╩š╚ļ)▀Mąąī┘ąį£yįćŻ¼┐═æ¶į┌įōī┘ąį╔ŽĄ─▓╗═¼╚ĪųĄČ°ĄĮ▀_╣سc5╗“╣سc6Ż¼ūŅ║¾į┘ė├child_Bum_at_home(į┌╝ęūė┼«öĄ)ī┘ąįī”╣سc6└^└m£yįćŻ¼┐═æ¶į┌įōī┘ąį╔ŽĄ─▓╗═¼╚ĪųĄČ°ĄĮ▀_╣سc7╗“╣سc8ĪŻ
į┘ī”įŁöĄō■╝»▀Mąą╦─┤╬╚ĪśėŻ¼Ęųäeė├½@Ą├Ą─ė¢ŠÜ╝»║═£yįć╝»Į©┴óøQ▓▀śõ─Żą═▓óī”─Żą═ū„£yįćŻ¼├┐┤╬Į©┴óĄ──Żą═Ą─ĮYśŗę╗ų┬ĪóĖ„╣سc╦∙ī┘ŅÉäeø]ėą░l╔·ūā╗»ĪŻ
4.2.4 ─Żą═░l▓╝
─Żą═Ą─░l▓╝Š═╩Ūį┌ę╗éĆöĄō■═┌Š“─Żą═Į©┴ó║├ęį║¾Ż¼īóöĄō■═┌Š“╦∙½@Ą├Ą─ų¬ūRė├ę╗ĘNė├æ¶┐╔ęį╩╣ė├Ą─ĘĮ╩ĮüĒĮM┐Ś║═▒Ē╩Š│÷üĒĪŻŅAčį─Żą═ś╦ėøšZčįPMML(Predictive Model Markup Language)╩Ū└¹ė├XML├Ķ╩÷║═┤µā”öĄō■═┌Š“─Żą═Ą─ę╗ĘNś╦£╩ĪŻ
ū„×ķöĄō■═┌Š“ŅIė“╩┬īŹ╔ŽĄ─ąąśIś╦£╩Ż¼×ķ▓╗═¼öĄō■═┌Š“ŽĄĮyų«ķg╣▓ŽĒ─Żą═╠ß╣®┴╦ś╦£╩Ą─▒Ē╩ŠęÄĘČŻ¼╩ŪöĄō■═┌Š“ŲĮ┼_╦∙ū±čŁĄ──Żą═▒Ē╩ŠĖ±╩ĮŻ¼įōęÄĘČĄ─ā╚╚▌╩Ūę╗Ę▌XML DTD╬─ÖnĪŻ
5 ĮYšō
ļSų°ą┼Žó╝╝ągĄ─░lš╣║═öĄō■═┌Š“╝╝ągĄ─│╔╩ņŻ¼öĄō■═┌Š“Ą─蹊┐ųž³cųØuÅ─╦ŃĘ©Ą─蹊┐▐DŽ“┴╦╦ŃĘ©Ą─æ¬ė├Ż¼öĄō■═┌Š“╝╝ągį┌CRMųąĄ─æ¬ė├╩Ū«öŪ░Ą─蹊┐¤ß³cŻ¼╗∙ė┌øQ▓▀śõ╝╝ągį┌CRMųąėąų°ÅVĘ║Ą─æ¬ė├ĪŻ
Ų¾śI═©▀^ī”┐═æ¶Ą─ĘųŅÉ─Żą═Ż¼▓╔╚ĪŽÓæ¬Ą─┐═æ¶Ę■äš║═┐═æ¶õN╩█Ą─▓▀┬įŻ¼ūŅ┤¾│╠Č╚Ąž╠ßĖ▀┐═æ¶Ą─ārųĄ╝░┐═æ¶Ą─ųęš\Č╚Ż¼╩╣┐═æ¶╣▄└ĒĄ─┘Yį┤×ķš¹éĆŲ¾śIĄ─░lš╣äėŽ“║═Ę■äš▓▀┬į╠ß╣®ėą└¹Ą─ųĖī¦ĪŻĮøĀIøQ▓▀š▀ę╗ĘĮ├µ┐╔ęį═©▀^ī”┐═æ¶Ą─ĘųŅÉ║═įu╣└Ż¼ųĖī¦Ų¾śIøQ▓▀Ż╗┴Ēę╗ĘĮ├µŻ¼ę▓┐╔ęį═┌Š“Øōį┌Ą─┐═æ¶║═░l¼F┐═æ¶ąą×ķĄ─ĘųŅÉęÄätŻ¼ė╔┤╦▀_ĄĮ▒Ż│ų║═öU┤¾┐═æ¶╚║ĪŻÅ─▀@ā╔ĘĮ├µüĒ┐┤Ż¼öĄō■═┌Š“ī”Ų¾śIĄ─ĮøĀIøQ▓▀║═┐═æ¶ĻPŽĄ╣▄└ĒČ╝Š▀ėąŽÓ«öųžę¬Ą─ū„ė├║═ęŌ┴xĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║öĄō■═┌Š“╝╝ągį┌CRMųąĄ─æ¬ė├║═蹊┐
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/1083935014.html






















