



ū„×ķę╗éĆū÷Ų¾śI┤µā”╩ął÷Ą─┤µā”╚╦Ż¼ūŅĮ³ā╔─Ļ╬ę▓╗öÓ▒╗ųžähē║┐s┴├ō▄ų°ĪŻī”ė┌ųžähē║┐s▀@éĆ╝╝ągĄ─║├ē─Ż¼šµīŹąĶŪ¾▀Ć╩Ūé╬ąĶŪ¾┤¾╝ę┐┤Ę©▓╗ę╗ĪŻĮ±╠ņ╬ęŠ═ų╗─▄šäšä╬ęéĆ╚╦Ą─┐┤Ę©ĪŻĖ³ČÓė^³cšłĻPūó“ć·Ātų¾ŠŲšōIT”╣½▒Ŗ╠¢

ųžähē║┐s╩Ū╩▓├┤Ż┐
ųžäh║═ē║┐sĢr═Ļ╚½▓╗═¼Ą─ā╔ĘN╝╝ągŻ¼ĮŌøQ▓╗═¼Ą─å¢Ņ}ĪŻ
ųžähŻ║Š═╩Ūšfėą║▄ČÓĘųŽÓ═¼Ą─öĄō■Ż¼╬ęų╗┤µā”Ųõųąę╗Ę▌Ż¼Ųõ╦¹Ą─ųžÅ═öĄō■ēK╬ę▒Ż┴¶ę╗éĆĄžųĘę²ė├ĄĮ▀@éĆ╬©ę╗┤µā”Ą─ēK╝┤┐╔ĪŻ
ē║┐sŻ║īóę╗éĆ┤¾ūųĘ¹┤«ųąĄ─ūė┤«ė├ę╗éĆ║▄║åČ╠Ą─öĄūųüĒś╦ėøŻ¼╚╗║¾Öz╦„įōūųĘ¹┤«│÷¼FĄ─╬╗ų├Ż¼ė├éĆ║åå╬Ą─ūųĘ¹üĒ╠µ┤·ĪŻÅ─Č°üĒ£p╔┘öĄō■▒Ē▀_╦∙ąĶꬥ─┐šķgŻ¼Ä¦üĒ┐šķg╣Ø╩ĪĪŻ
▒╚╚ńšfė├1┤·▒Ē“AB”Ż¼ė├2┤·▒Ē“CD”Ż¼╚╗║¾ė├255 üĒ┤·▒Ē“hanfute”ĪŻ1ĄĮ255ų╗ąĶę¬8éĆbitŻ¼Č°“AB”“CD”╗“š▀“hanfute”ätąĶę¬║▄ČÓĄ─┐šķgŻ¼▀@śėČÓ┤╬Æ▀├Ķ╠µ┤·ų«║¾Ż¼Š═┐╔ęį┐ņ╦┘Ą─īóöĄō■┐s£pĪŻ
ė├═©╦ūĄ─įÆšfŻ║ųžähŠ═╩ŪųvŽÓ═¼Ą─¢|╬„ų╗┤µā”ę╗┤╬Ż¼Č°ē║┐sät╩ŪĖ─įņöĄō■┼┼▓╝ė├ę╗ĘN╦ŃĘ©üĒĮyėŗöĄō■Ą─┼┼▓╝─Ż╩ĮŻ¼Å─Č°▀_ĄĮ£p╔┘öĄō■┤µā”Ą──Ż╩ĮĪŻ

ųžähĄ─īŹ¼F
ųžähĄ─īŹ¼F╝╝ąg▒╚▌^║åå╬Ż¼ūŅ║åå╬Ą─╩╣ė├Š═▒╚╚ń╬ęéāĄ─Ó]╝■Ę■äšŲ„Ż¼╬ę▐D░lę╗Ę▌Ó]╝■Įo100éĆ╚╦Ż¼┤¾╝ę╩šĄĮ╬ęĄ─Ó]╝■║¾Š═Ģ■«a╔·100éĆę╗śėĄ─╬─╝■Ż¼╝┘įO┤¾╝ęĄ─öĄō■▒P╩╣ė├Ą─╣▓ŽĒ┤µā”Ż¼┤µā”ų╗ąĶę¬į┌├┐éĆ╚╦┤µ╚ļ╬─╝■Ą─Ģr║“▓ķįāę╗Ž┬▀@éĆ╬─╝■▒ŠĄžėąø]ėąŻ¼ėą╬ęŠ═▓╗į┘┤µā”ĪŻ▀@śėį┌┤µā”╔ŽŠ═ų╗┤µā”┴╦ę╗éĆ╬─╝■ĪŻ▀@╩Ūę╗éĆūŅśŃ╦žĄ─└ĒĮŌĪŻ
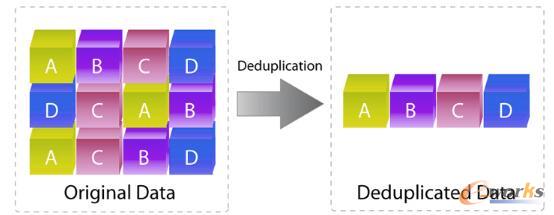
▀@└’├µ╔µ╝░ĄĮÄūéĆå¢Ņ}Ż║
1Īó┤µā”į§├┤ų¬Ą└▀@éĆ╬─╝■ūį╝║ęčĮø┤µā”┴╦Ż┐
2Īó╚ń╣¹▓╗╩Ū┤µ╬─╝■Ż¼Č°╩ŪēK┤µā”įōį§├┤▐kŻ┐
┤µā”į§├┤ų¬Ą└▀@éĆ╬─╝■ūį╝║ęčĮøėą┴╦─žŻ┐
į┌ėŗ╦ŃÖC└’├µėąéĆ╝╝ąg├¹ūųĮąū÷”ųĖ╝y”Ż¼ĘŪ│ŻĄ─ą╬Ž¾╔·äėŻ¼Š═║├Ž±├┐éĆ╚╦Ą─ųĖ╝y┐ŽČ©▓╗ę╗śėŻ¼─Ū├┤╬ęéā╩Ū▓╗╩Ū┐╔ęįė├ę╗éĆ║▄ąĪĄ─öĄō■üĒś╦ėøę╗éĆ╬─╝■Ą─╬©ę╗ą┼ŽóĪŻ
▀@└’ėą║▄ČÓĄ─╦ŃĘ©┐╔ęį┐ņ╦┘Ą─Ą├ĄĮę╗éĆ╬©ę╗ųĄŻ¼▒╚╚ńšfMD5╦ŃĘ©ĪóSha╦ŃĘ©ĪŻ
- Sha╦ŃĘ©╩Ūę╗ĘN▓╗┐╔─µĄ─öĄō■╝ė├▄╦ŃĘ©Ż¼ų╗─▄╦ŃųĖ╝y│÷üĒŻ¼Ą½╩Ū¤oĘ©═©▀^ųĖ╝yĘ┤═Ų│÷üĒā╚╚▌ĪŻ
- ╦¹┐╔ęįĮøę╗éĆąĪė┌2^64Ą─öĄō■▐D╗»│╔ę╗éĆ160╬╗Ą─▓╗ųžÅ═Ą─ųĖ╝yŻ¼ūŅĻPµIĄ─╩Ū╦¹Ą─ėŗ╦Ń▀Ć║▄┐ņĪŻ
- ╦∙ęį▒╚▌^ā╔éĆöĄō■╩ŪʱŽÓ═¼Ż¼Š═┐╔ęį═©▀^ėŗ╦Ń╦¹Ą─ųĖ╝yŻ¼╚╗║¾╚źī”▒╚ųĖ╝yŻ¼Č°▓╗╩Ū▀MąąöĄō■Ą─ųūų╣Ø▒╚ī”ĪŻą¦┬╩ę¬Ė▀Ą├ČÓĪŻ
▀@éĆųĖ╝yėąø]ėą┐╔─▄ųžÅ═Ż¼▒╚╚ńšfā╔éĆ╚╦Ą─ųĖ╝yŽÓ═¼Ż┐
░┤ššsha256╦ŃĘ©Ż¼į┌4.8*10^29éĆöĄō■ųą│÷¼Fā╔éĆöĄō■ųĖ╝yųžÅ═Ą─Ė┼┬╩┤¾Ė┼ąĪė┌10^-18.10^-18Š═╩Ū╬ęéā╦∙šfĄ─16éĆ9Ą─┐╔┐┐ąįĪŻ

▐D╗»│╔┤µā”šZčį╬ęéāüĒėæšōę╗Ž┬ĪŻ╝┘╚ńšf╬ęéāĄ─┤µā”├┐├ļńŖīæ╚ļĄ─10╚féĆ╬─╝■Ż¼░┤šš┤µā”7*24*365╠ņ╣żū„Ż¼─Ū├┤├┐─Ļīæ╚ļĄ─öĄō■×ķ365*24*3Ż¼600*10Ż¼000=3.15*10^12éĆ╬─╝■ĪŻ╚ń╣¹Žļūī┤µā”│÷¼F╣■ŽŻ┼÷ū▓Č°ī¦ų┬ųžähüGöĄō■Ż©Ė┼┬╩┤¾ė┌10^-18Ż®Ż¼─Ū├┤ąĶę¬▀\ąą1.52*10^17─ĻŻ¼┐╔─▄Ģ■ė÷ĄĮę╗┤╬ĪŻ

ŲõīŹ╬ęéāų„┴„┤µā”įOéõĄ─┐╔┐┐ąįę╗░Ń×ķ99.9999%ę▓Š═╩Ū╬ęéā│ŻšfĄ─6éĆ9Ż¼╩Ū▀h▀h▓╗╚ń╣■ŽŻųĄ┐╔┐┐Ą─ĪŻ▀@ę▓╩Ū║▄ČÓ╚╦ō·ą─Ą─ųžähĢ■▓╗Ģ■░č╬ęĄ─öĄō■äh│²ø]ėą┴╦Ż¼ī¦ų┬╬ęĄ─öĄō■ōpē──žŻ¼ŲõīŹ▓╗ė├▀@éĆō·ą─ĪŻ
Ą½╩Ū▀Ć╩Ūėą╚╦Ģ■ō·ą─Ż¼į§├┤▐k─žŻ┐▀Ćėą┴Ē═Ōę╗ĘNĘĮĘ©Ż¼─ŪŠ═╩Ūė÷ĄĮę╗éĆą┬öĄō■Ż¼╬ęŠ═ė├ā╔ĘN╦ŃĘ©Ż¼┤µā”ā╔éĆhashųĄŻ¼ė÷ĄĮ┴╦ųžÅ═öĄō■▀Mąąā╔ųžhash▒╚ī”ĪŻĄ½╩Ūėą╚╦▀Ć╩Ūī”hash╦ŃĘ©ėąō·ą─Ż¼ę▓║åå╬Ż¼ī”ė┌ųžÅ═öĄō■╬ęéāį┘▀Mąąę╗┤╬ųūų╣Ø▒╚ī”┬’Ż¼▓╗▀^Š═╩ŪĢ■╔į╬óė░Ēæąį─▄ĪŻ
╚ń╣¹▓╗╩Ū╬─╝■Ż¼ēK┤µā”įōį§├┤╠Ä└ĒŻ┐
ųžÅ═öĄō■äh│²╝╝ągį┌ēK┤µā”Ą─īŹ¼F▒╚▌^ČÓśė╗»ĪŻ
ūŅ║åå╬ūŅ╗∙▒ŠĄ─ĘĮ╩ĮŠ═╩Ūų▒ĮėČ©ķLųžähĪŻ╦∙ęįīæ╚ļĄ─öĄō■░┤šš╣╠Č©ķLČ╚▀MąąŪąŲ¼Ż¼ŪąŲ¼║¾▀Mąąhashėŗ╦ŃŻ¼╚╗║¾▀Mąąīæ╚ļ╠Ä└ĒŻ¼ĘŪųžÅ═öĄō■Š═å╬¬Üīæ╚ļŻ¼ųžÅ═öĄō■Š═īæ╚ļę²ė├╝┤┐╔ĪŻ
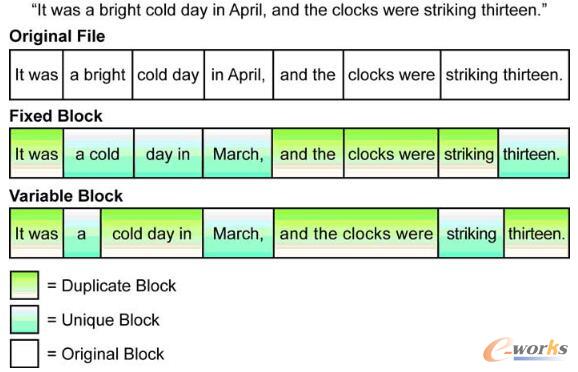
Ą½╩Ū▀@ĘN╠Ä└ĒĘĮ╩Įųžäh┬╩╩Ū▒╚▌^Ą═Ą─Ż¼▒╚╚ńšfę╗éĆ╬─╝■Ż¼╬ęéāų╗į┌╬─╝■╔Ž╠Ē╝ėę╗éĆūųĘ¹Ż¼╚╗ųžą┬īæ╚ļŻ¼▀@éĆ╬─╝■▓╔ė├Č©ķLĘĮ╩ĮŪąŲ¼║¾Š═¤oĘ©šęĄĮ║═ęįŪ░ŽÓ═¼Ą─ēKŻ¼ī¦ų┬¤oĘ©▒╗ųžähĄ¶öĄō■ĪŻę“┤╦śIĮńę▓ėą║▄ČÓĄ─▀ģķLųžähĄ─╦ŃĘ©ĪŻ
Ą½╩ŪūāķLųžähī”ąį─▄║═╦ŃĘ©ę¬Ū¾Č╝▒╚▌^Ė▀Ż¼═¼Ģrī”ė┌CPUā╚┤µŽ¹║─ę▓┤¾Ż¼ė░Ēæ┴╦öĄō■Ą─īŹĢr╠Ä└Ēą¦┬╩ĪŻ«ģŠ╣┤µā”ų„ę¬▀Ć╩Ū╠Ä└Ēų„ÖCĄ─IOūxīæĒææ¬Ą─ĪŻų╗ėąį┌éõĘ▌ÜwÖnŅIė“ė├Ą─▒╚▌^ČÓŻ¼ę“×ķ▀@éĆł÷Š░╣Ø╩Ī┐šķg▒╚┐ņ╦┘Ēææ¬ę¬Ū¾Ė▀Ą─ČÓĪŻ
ęįŽ┬├µ▀@éĆłDŲ¼×ķ└²Ż¼ūāķLųžähą¦┬╩┐╔─▄▀_ĄĮ10Ż║1Ż¼Č°Č©ķLųžähų╗ėą3Ż║1.

ę“┤╦Ż¼ī”ė┌╚½ķW┤µ┤µā”▀@ĘNĒææ¬ę¬Ū¾Ė▀Ą─Ż¼Į©ūhČ©ķLųžähŻ¼╦┘Č╚┐ņĪŻī”ė┌ÜwÖnĪóéõĘ▌▀@ĘN└õ┤µā”Į©ūhūāķLųžähŻ¼ųžäh┬╩Ė▀╣Ø╩Ī│╔▒ŠĪŻ
ųžäh┐éĮY
ŲõīŹųžäh▀@éĆ╣”─▄į┌╚½ķW┤µ╩ął÷ė├╠Ä▓ó▓╗┤¾Ż¼ę“×ķ║▄ČÓĢr║“Č©ķLųžähĄ─ą¦╣¹║▄ėąŽ▐Ż¼▒╚▌^Ąõą═Ą─▒╚╚ńöĄō■Äņł÷Š░Ż¼ųžäh┬╩ų╗ėą┐╔æzĄ─1.05Ż║1Äū║§┐╔ęį║÷┬į▓╗ėŗĪŻ
ī”ė┌╚½ķW┤µüĒšfē║┐sĖ³ėąą¦Ż¼Ž┬├µ╬ęéāüĒ┐┤┐┤ē║┐s╝╝ągĪŻ
ē║┐s╝╝ągĄ─īŹ¼F
ē║┐s╝╝ągė╔üĒęčŠ├Ż¼Ęų×ķ¤oōpē║┐s║═ėąōpē║┐sĪŻ
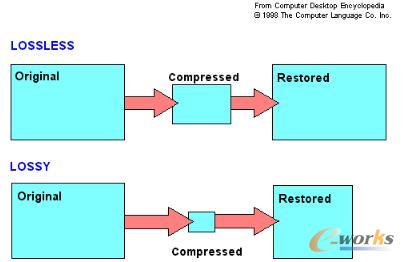
ėąōpē║┐sų„ę¬ė├ė┌łDŽ±╠Ä└ĒŅIė“Ż¼▒╚╚ńšf╬ę╬óą┼░lę╗éĆššŲ¼Ż¼├„├„▒ŠĄž10MĄ─Ė▀ŪÕłDŲ¼é„▌öĄĮ┼¾ėč╩ųÖC└’├µŠ═ėą300KĄ─łDŲ¼ĪŻ▀@ų„ę¬×ķ┴╦╣Ø╩ĪŠWĮjé„▌öĄ─┴„┴┐ęį╝░╬óą┼┤µā”┐šķg╣Ø╩ĪĪŻ
┤µā”ŽĄĮyŅIė“ė├Ą─ē║┐sČ╝╩Ū¤oōpē║┐sĪŻĮĶų·ė┌╦ŃĘ©Ą─Ųš╝░Ż¼śIĮńų„┴„┤µā”ÅS╔╠Ą─ē║┐sīŹ¼FÄū║§Č╝ø]ėą╦ŃĘ©╔ŽĄ─ģ^äeŻ¼ų╗╩Ūį┌ė┌ē║┐sĄ─īŹ¼F▀xō±╔ŽŻ¼ų„ę¬┐╝æ]╝µŅÖąį─▄║═öĄō■┐s£p┬╩ĪŻ
─Ū├┤ē║┐sī”┤µā”Ą─ąį─▄ė░ĒæėąČÓ┤¾Ż┐
ē║┐sī”┤µā”Ą─ąį─▄ė░ĒæėąČÓ┤¾
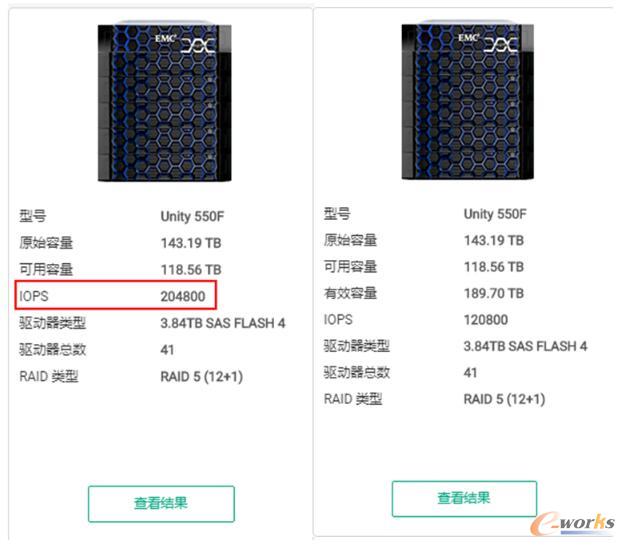
╗∙ė┌EMC Unity SizerĄ─ąį─▄įu╣└╣żŠ▀Ż¼╬ęéā┤¾Ė┼┐╔ęį┐┤ĄĮķ_åóē║┐sŽÓī”ė┌▓╗ķ_åóē║┐sŻ¼IOPSÅ─20╚fū¾ėęĮĄĄ═ĄĮ┴╦12╚fŻ¼┤µā”ąį─▄Ž┬ĮĄ┤¾Ė┼╩Ū40%ĪŻ
ŲõīŹ╬ęéāūŅą┬Ą─intel CPU└’├µęčĮø╝»│╔┴╦ē║┐s╦ŃĘ©Ż¼╬ę╔Ž┤╬╦ĮŽ┬└’║═╬ęéā£yįćĮø└Ē▀Mąą┴╦öĄō■Ą─┴╦ĮŌŻ¼į┌ķ_åóē║┐sŻ¼ØMžō▌dĄ─▀Mąą┤µā”ąį─▄ē║┴”£yįćŻ¼┤µā”CPU└¹ė├┬╩75%Ą─Ģr║“Ż¼Ųõųąė├ė┌ē║┐s╦∙Ž¹║─Ą─CPU┘Yį┤▓╗ĄĮ3%ĪŻ×ķ╩▓├┤┤µā”ąį─▄Ž┬ĮĄ┴╦▀@├┤ČÓŻ┐Ż┐Ż┐
īŹ¼Fē║┐sĦüĒĄ─ROW╝▄śŗąįą¦┬╩Ž┬ĮĄ
╬ęéāé„ĮyĄ─┤µā”Ż¼▓╗ąĶę¬ē║┐sĄ─Ģr║“Ż¼╬ęéā├┐éĆöĄō■Č╝╩Ūė╔ūį╝║į┌ė▓▒P╔ŽĄ─╣╠Č©ĄžųĘĄ─ĪŻ▒╚╚ńšfLUN1Ą─LBA00xx64~00x128 ┤µā”į┌5╠¢┤┼▒PĄ─Ą═8éĆ╔╚ģ^Ą─Ą┌X╬╗ķ_╩╝Ą─▀B└m64bitĄžųĘ╔ŽĪŻ╚ń╣¹╬ęęį8KB×ķ┤µā”Ą─ūŅąĪēK┤¾ąĪŻ¼─Ū├┤├┐éĆ8KBČ╝╩Ū┤µā”į┌ę╗éĆ╣╠Č©Ą─8KBĄ─╬’└Ē▒PŲ¼Ą─Š▀¾w╬’└ĒĄžųĘ╔ŽĪŻį┌╬ęĄ┌ę╗┤╬īæ╚ļĄ─Ģr║“▒╗╬ę╦∙¬Üš╝ĪŻ
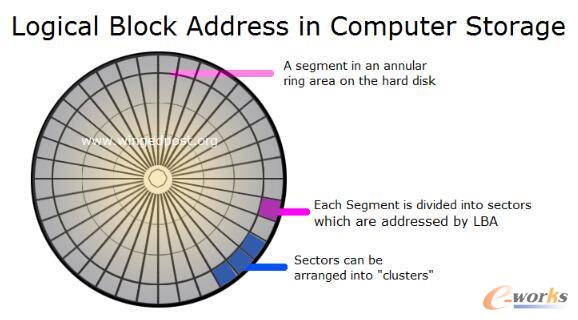
ęį║¾▀@éĆ8KB▓╗╣▄į§├┤Ė─īæūx╚ĪŻ¼Č╝╩Ū8KBĪŻėøõø▀@ą®öĄō■┤µā”Ą─╬╗ų├Ą─ĘĮ╩ĮĘŪ│Ż║åå╬ĪŻ╝┘╚ńšfę╗éĆLUNę╗╣▓1TBŻ¼─Ū├┤╬ęŠ═ėøõø▀@├┤1TBĘų▓╝į┌ÄūéĆ▒P└’├µŻ¼ė├ę╗éĆ║▄║åå╬Ą─╦ŃĘ©īó╦¹Ęų▓╝į┌─ŪéĆ▒PĄ──ŪéĆ╬’└ĒĄžųĘ▌p╦╔ĄžŠ═╦Ń┴╦│÷üĒĪŻ╬ęų╗ąĶę¬ėøõøę╗╣▓ė╔ÄūēK▒PŻ¼ę╗╣▓ĮM│╔┴╦ÄūéĆRAIDĮMŻ¼├┐éĆRAIDŚlĦ╔ŅČ╚╩ŪČÓ╔┘Ż¼Ų╩╝ĄžųĘ╩ŪČÓ╔┘Ż¼Š═─▄į┌ā╚┤µųą┐ņ╦┘Ą─ė├▀@ą®╗∙▒ŠöĄō■╦Ń│÷öĄō■ī”æ¬Ą─╬’└ĒĄžųĘ╩ŪČÓ╔┘ĪŻ
▀@ĘN╗∙▒ŠĄ─īæ╚ļ─Ż╩ĮĮąū÷COWŻ©copy on writeŻ®Ż¼Š═╩ŪšfīæŪ░┐ĮžÉĪŻ
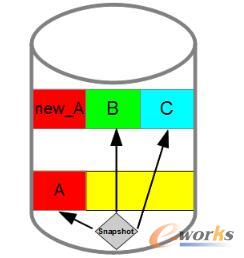
é„ĮyĄ─RAID─Ż╩ĮūóČ©┴╦ ╬ęéāų╗ę¬Ė─īæę╗éĆ╬╗Ż¼Š═ąĶę¬īóįŁėąöĄō■║═ąŻ“×öĄō■═¼Ģrūx╚ĪŻ¼╚╗║¾į┌ā╚┤µųąėŗ╦Ń║¾į┘īæ▀M╚źĪŻūx╚ĪĄ─įŁę“╩Ū×ķ┴╦ĘĮ╩Įīæ╚ļ╩¦öĪ╬ę┐╔ęį╗ųÅ═╗ž╚ź.
Č°īæŪ░┐ĮžÉ▓ó▓╗╩ŪųĖĄ─▀@éĆå¢Ņ}Ż¼Č°╩ŪųĖį┌ėąöĄō■┐ņššĄ─ŪķørŽ┬╚ń║╬īæ╚ļŻ¼▀@éĆĢr║“╬ęéā▓╗─▄ŲŲē─┐ņššĄ─öĄō■Ż¼Š═ų╗─▄īóįŁėą╬╗ų├Ą─öĄō■┐ĮžÉĄĮę╗éĆīŻķTĄ─┐ņšš┤µā”ģ^ė“ĪŻ▀@ĘQų«×ķCOWŻ¼╦¹╩ŪŽÓī”ė┌ROWŻ©redirect on writeŻ®Č°░l├„Ą─ę╗éĆį~ĪŻ
ć°ā╚║▄ČÓ╚╦ī”ė┌COWĮąū÷“┐┐”╝▄śŗĪŻ
ė╔ė┌ē║┐s║¾ę╗éĆ8KBĄ─öĄō■ėą┐╔─▄ūā│╔┴╦1KbĪó2KBĪó3KBę▓┐╔─▄╩Ū8KBŻ¼─Ū├┤╬ęĄ─öĄō■Š═╩Ūę╗éĆ┐╔ūāĄ─ķLČ╚Ż¼╚ń╣¹▀Ć▓╔ė├╬’└ĒĄžųĘ║═▀ē▌ŗĄžųĘę╗ę╗ī”æ¬Ą─ĘĮ╩Į╬ęŠ═▀_▓╗ĄĮ╣Ø╩Ī┐šķgĄ─ą¦╣¹┴╦ĪŻ╬ęīóę╗éĆ8KBĄ─ēKē║┐s│╔┴╦1KBŻ¼ĮY╣¹─Ń▀Ć╩ŪĮo╬ęĘų┼õ┴╦8KB╬’└Ē┐šķgüĒ┤µā”Ż¼▀@║åų▒Š═╩Ū▓╗║Ž▀mĪŻę“┤╦į┌ē║┐sĄ─īŹ¼F╔ŽŻ¼┤µā”ę╗░ŃČ╝▓╔ė├ROW╝▄śŗüĒīŹ¼FĪŻ
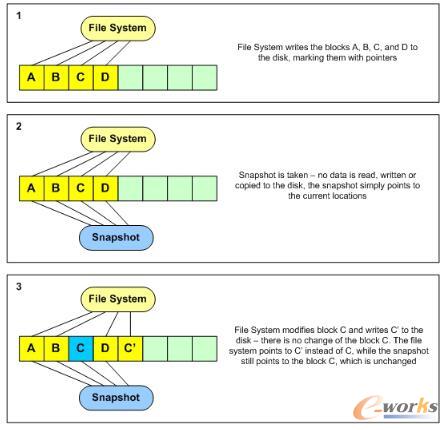
ROWĦüĒ┴╦─Ūą®ąį─▄Ž┬ĮĄ
1Īóė╔ė┌ROW╝▄śŗ├┐éĆēKČ╝ąĶę¬å╬¬Ü┤µā”ę╗┤╬ĄžųĘĄ─ė│╔õĻPŽĄŻ¼╦∙ęį╚▌┴┐įĮ┤¾Ż¼«a╔·Ą─į¬öĄō■┴┐ę▓įĮ┤¾Ż¼╦∙ęįROW╝▄śŗę╗░Ń╚▌┴┐įĮ┤¾Ż¼ąį─▄įĮ▓ŅĪŻ
×ķ┴╦Ė³║├Ą─╠Ä└ĒöĄō■Ż¼┐ŽČ©Žļį¬öĄō■╚½▓┐į┌ā╚┤µųąŠÅ┤µ╩Ūą¦┬╩ūŅ║├Ą─Ż¼╦∙ęįROW╝▄śŗ┤µā”ī”ā╚┤µĄ─įVŪ¾║▄┤¾ĪŻ
2Īóė╔ė┌ROW╝▄śŗ├┐┤╬īæ╚ļČ╝ąĶę¬ėøõøĄžųĘį¬öĄō■Ż¼╠Äė┌┐╔┐┐ąį┐╝æ]Ż¼╬ęéā┐ŽČ©ąĶę¬│ųŠ├╗»Ż¼├┐┤╬Č╝ę¬į¬öĄō■Ž┬▒PŻ¼▀@śėę╗┤╬īæ╚ļŠ═Ģ■«a╔·ā╔┤╬Ą─▓┘ū„Ż¼īæ╚ļį¬öĄō■Ż¼īæ╚ļöĄō■ĪŻ
3Īóė╔ė┌ROW╝▄śŗĄ─öĄō■īæ╚ļ▓╔ė├┴╦ą┬šęĄžųĘīæ╚ļŻ¼▀@śėįŁüĒ▀ē▌ŗ╔Ž▀B└mĄ─öĄō■Ģ■▒╗▓╗öÓĄ─ļx╔ó╗»Ż¼ūŅĮK▀B└mIOę▓Ģ■ūā│╔ļSÖCIOŻ¼ī”ąį─▄ė░Ēæ▌^┤¾
4ĪóROWĦüĒ┴╦┴Ēę╗éĆå¢Ņ}Ż¼ęį╔ŽłD×ķ└²Ż¼╬ęéā╚ń╣¹ø]ėą┐ņššŻ¼─Ū├┤C▀@éĆöĄō■ēKŠ═╩Ūę╗éƤoą¦Ą─öĄō■Ż¼Ą½╩Ū╬ęéā▓ó▓╗Ģ■į┌īæ╚ļĄ─Ģr║“┴ó╝┤Ą─äh│²▀@éĆöĄō■Ż¼ę“×ķĢ■ė░Ēæąį─▄ĪŻ╬ęéāŠ═ąĶę¬į┌ø]ėą▀B└m┐šķg╗“š▀śIäš┐šķeĄ─Ģr║“īŻķTüĒ╠Ä└Ē▀@ą®╩¦ą¦Ą─ēKĪŻ▀@éĆę▓Š═╩Ū╬ęéāĮø│Ż╦∙šfĄ─└¼╗°╗ž╩šŻ¼└¼╗°╗ž╩šī”ąį─▄ė░Ēæ║▄┤¾Ż¼║▄ČÓÅS╔╠Ė╔┤ÓŠ═▓╗╗ž╩šŻ¼Č°▓╔ė├ų▒Įė╠Ņ┐šīæ╚ļĄ─ĘĮ╩ĮĪŻ▓╗╣▄──ĘNĘĮ╩Įī”ė┌└¼╗°┐šķgĄ─ųžÅ═└¹ė├╩Ūī”ąį─▄ė░ĒæśO┤¾Ą─ę╗éĆ▓┘ū„ĪŻ
▀@ą®å¢Ņ}į┌é„Įyė▓▒Pł÷Š░ė░ĒæĖ³×ķ├„’@Ż¼▀@ę▓╩ŪęįŪ░Netappį┌HDDĢr┤·ąį─▄▒╗įŹ▓ĪĄ─ę╗éĆįŁę“ĪŻ
Č°SSD▒Pā╚▓┐Ą─öĄō■╠Ä└Ēę▓╩ŪŅÉ╦ŲŻ¼SSDųąķ_åó└¼╗°╗ž╩šī¦ų┬Ą─ąį─▄Ž┬ĮĄ▒╗ĘQų«×ķ“īææęč┬”
ē║┐s┐éĮYŻ║
ē║┐sī”ė┌┤µā”ąį─▄ĦüĒĄ─ø_ō¶Ż¼Ė∙▒Š▓╗╩ŪüĒūį┼cē║┐s▒Š╔ĒŻ¼Č°╩Ūė╔ė┌īŹ¼Fē║┐sĄ─╝▄śŗȰĦüĒĄ─ė░ĒæĪŻ
░┤šš«öŪ░śIĮńų„┴„┤µā”ÅS╔╠Ą─▄ø╝■╝▄śŗ║═ą¦┬╩üĒįu╣└Ż¼ę╗░ŃROW╝▄śŗĄ─┤µā”ŽÓī”ė┌COW╝▄śŗį┌ąį─▄╔Ž┤¾Ė┼ꬎ┬ĮĄ35%ū¾ėęŻ¼Č°ē║┐s▒Š╔ĒĦüĒĄ─ąį─▄ōp╩¦ę╗░Ńį┌5%ęįā╚Ż¼╦∙ęįī”ė┌š¹éĆ┤µā”ŽĄĮyüĒšfŻ¼ķ_åóē║┐sąį─▄Ž┬ĮĄĘ∙Č╚┤¾Ė┼į┌40%ū¾ėę
į┌ROW╝▄śŗ╔ŽīŹ¼Fųžäh▀Ćėąėą──ą®ø_ō¶─ž
ŽÓī”ė┌ē║┐sį┌ā╚┤µųąėŗ╦Ń═Ļ│╔║¾Š═ų▒Įėīæ╚ļŻ¼ųžähĄ─ė░ĒæĖ³┤¾Ż║
1ĪóąĶę¬ėąå╬¬ÜĄ─┐šķgüĒ┤µā”ųĖ╝yŻ©Ä¦üĒ┴╦ā╚┤µ┐╔ų¦│ų┤µā”┐šķgįĮüĒįĮąĪŻ®
2Īó├┐┤╬īæ╚ļČ╝ąĶę¬▀MąąųĖ╝y▒╚ī”Ż©ūxīæĢrčėį÷╝ėŻ®
3Īóī”ė┌ę╗éĆą┬öĄō■ēKĄ─īæ╚ļ«a╔·┴╦┤¾Ę∙Ą─Ę┼┤¾Ż©ųĖ╝yÄņėøõøę╗┤╬ĪóöĄō■ēKīæ╚ļę╗┤╬Īóį¬öĄō■ėøõøė│╔õę╗┤╬Ż®Ż¼╦∙ęį║▄ČÓĢr║“ųžähĦüĒĄ─ąį─▄ų„ę¬į┌ĢrčėĪŻ
śOČ╦ŪķørŻ║ę╗éĆĄõą═Ą─śOČ╦ŪķørŻ¼╚ń╣¹╩ŪHDD┤µā”ŁhŠ│Ż¼╬ęéā╝┘įO╬ęéāROWŽĄĮyĄ─Č©ķLēK┤¾ąĪ╩Ū8KBŻ¼╚ń╣¹╬ęīæ╚ļę╗éĆ128KBĄ─öĄō■Ż¼Ģ■▒╗ŪąŲ¼│╔16éĆöĄō■Ų¼Ż¼▀Mąą16*3┤╬öĄō■Ž┬▒P▓┘ū„Ż¼ūŅĮKĄ─Ģrčė┐╔ęį▀_ĄĮHDD▒Š╔ĒĄ─48▒ČŻ¼╝┘įOę╗éĆHDDĒææ¬╩Ū5msŻ¼─Ū├┤▀@éĆš¹éĆIOĄ─Ēææ¬Ģrčė▀_ĄĮ┴╦200msęį╔ŽŻ¼ī”ė┌SAN┤µā”üĒšf▀@Äū║§╩Ū▓╗┐╔Įė╩▄ĪŻ
╚ń║╬īŹ¼FĖ▀ą¦Ą─ųžähē║┐s
ųžähē║┐sī”ąį─▄Ą─ė░Ēæ┤¾╝ęČ╝ų¬Ą└Ż¼╚ń║╬ĮĄĄ═┤µā”ē║┐sĦüĒĄ─ąį─▄ė░ĒæŻ¼╬ęéāį┌Ž┬ę╗Ų¬╬─š┬üĒįö╝ÜĄ─ĮķĮBĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║£\šä┤µā”ųžähē║┐s╝╝ąg
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839624469.html






















