




ĢrŽ┬öĄō■┐ŲīW╩Ūę╗éĆ¤ß³cįÆŅ}Ż¼Ė„éĆąąśI└’├µę▓ėąę╗ą®▒╚▌^│╔╩ņĄ─æ¬ė├Ż¼į┌▀@éĆ┤¾Ą─▒│Š░Ž┬Ż¼╬ęéāį┌┤¾╝sę╗─ĻŪ░Š═ķ_╩╝ėąęŌūRĄž░čöĄō■╝╝ągĪóöĄō■Ęų╬÷ĪóöĄō■═┌Š“▀@ą®╝╝ąg╚┌║ŽĄĮ▀\ŠSŅIė“Ą─æ¬ė├ĪŻį┌▀@éĆ▀^│╠ųąŻ¼╬ęéāū÷Ą─ĢrķgŲõīŹ▓╗║▄ķLŻ¼▒╚▌^Č╠Ż¼─┐Ū░ų╗╩Ūū÷┴╦ę╗ą®ŽÓī”üĒšf▌^×ķ║åå╬Ą─ę╗ą®╩┬ŪķŻ¼Ą½╚ĪĄ├Ą─│╔╣¹į┌╣½╦Šā╚▓┐ĖąėX▀Ć╩Ū▒╚▌^║├Ą─ĪŻĮ±╠ņ╬ęŠ═Ė·┤¾╝ęĘųŽĒę╗Ž┬╬ęéāį┌æ¬ė├ķ_░l▀^│╠ųąĄ─ę╗ą®░Ė└²Ż¼ę▓Š═╩ŪšfŻ¼╚ń║╬ūīöĄō■╝╝ągį┌▀\ŠSīŹ█`ųąĄ├ĄĮ│õĘųĄ─æ¬ė├Ż¼ŽŻ═¹ī”┤¾╝ęĄ─╣żū„ėąę╗ą®ģó┐╝ārųĄĪŻ
ĘųŽĒ─┐õøŻ║
1.öĄō■╠Ä└Ē╝╝ągæ¬ė├
2.öĄō■Ęų╬÷╝╝ągæ¬ė├
3.öĄō■═┌Š“╝╝ągæ¬ė├
4.æ¬ė├╔·æBĮ©įO╝░ęÄäØ
Ū░čį
į┌▀\ŠSųą╬ęéāĢ■┼÷ĄĮĖ„ĘNĖ„śėĄ─å¢Ņ}Ż¼Ą½ėąą®å¢Ņ}╬ęéāĮø│ŻųžÅ═ė÷ĄĮŻ¼▓óŪęą╬│╔┴╦ę╗ą®╠ßå¢ĘČ╩ĮŻ¼╚ńŻ║
- “ėąå¢Ņ}╗“╣╩šŽ░l╔·å߯┐”Ż¼▀@éĆ╠ßå¢▐DōQ│╔öĄīWå¢Ņ}Š═╩ŪĮ©┴ó“«É│ŻÖz£y”─Żą═Ż╗
- «ö╬ęéā┤_šJėąå¢Ņ}ĢrŻ¼╬ęéā▒Š─▄ĄžĢ■墓──└’│÷┴╦å¢Ņ}”Ż¼▀@▒Ń╩Ūę╗éĆ“Ė∙ę“Ęų╬÷”å¢Ņ}Ż╗
- ī”ė┌ę╗╝ęļŖ╔╠╣½╦ŠüĒšfŻ¼┤┘õNŪ░┐é╩Ūę¬ī”ŠĆ╔ŽŽĄĮy▀Mąą╚▌┴┐įu╣└║═öU╚▌Ż¼▀@└’▒Ńėąę╗éĆ“ŅA£y”─Żą═ąĶę¬▒╗Į©┴óŻ╗
- «ö╬ęéā├┐ū÷═Ļę╗éĆĒŚ─┐Ż¼ąĶę¬ī”ĒŚ─┐ąĶę¬▀_│╔Ą──┐ś╦▀MąąČ©┴┐Ą─įu╣└Ż¼▀@▒Ń╩Ūę╗éĆ“┐āą¦Ęų╬÷”Ą─å¢Ņ}ĪŻ
─┐Ū░Ė„ŅÉöĄīW─Żą═Ą─▌ö│÷į┌╬ęéāĄ─Š▀¾w╣żū„ųąų„ę¬▒╗ė├ū„▌oų·øQ▓▀üĒ╩╣ė├Ż¼ėąā╔éĆįŁę“╩╣╬ęéā▀Ć▓╗─▄ų▒Įė░čĮY╣¹ūįäėĄžė├ė┌øQ▓▀Ż║ę╗╩Ū╬ęéāī”öĄō■Ą─╩╣ė├─▄┴”▀Ć▓╗─▄ū÷ĄĮ├µ├µŠŃĄĮŻ¼║▄ČÓśIäšų¬ūR▀ƤoĘ©ė├╦ŃĘ©├Ķ╩÷Ż╗Č■╩Ū╦ŃĘ©Ą─▌ö│÷ĮY╣¹ę╗░ŃČ╝╩ŪėąĖ┼┬╩Ą─Ż¼į┌║▄ČÓąĶꬓĮ^ī”š²┤_”Ą─ł÷║Žų╗─▄ū„×ķģó┐╝ĪŻį┌īŹļH╣żū„ųąŻ¼╦ŃĘ©║═śIäšęÄätÄņČ╝Ģ■▀MąąĮ©įOŻ¼ė├üĒÄ═ų·▀\ŠS╚╦åTĖ³╚▌ęū║═š²┤_Ąžū÷│÷øQČ©ĪŻ
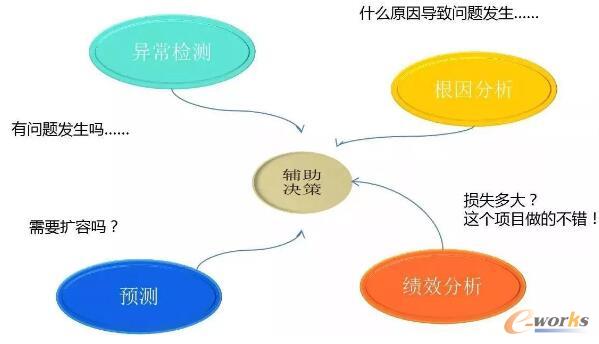
╗∙ė┌┤╦Ż¼Į±╠ņĮo┤¾╝ęųž³cĮķĮB“öĄō■╠Ä└Ē╝╝ąg”Īó“öĄō■Ęų╬÷╝╝ąg”Īó“öĄō■═┌Š“╝╝ąg”▀@╚²éĆĘĮ├µį┌╬©ŲĘĢ■Ą─æ¬ė├īŹ█`Ż¼ų„ę¬Ģ■ųvĄĮę╗ą®æ¬ė├ł÷Š░Ż¼ūŅ║¾šäŽ┬“öĄō■╝╝ąg”į┌╬©ŲĘĢ■▀\ŠSĄ─╔·æBĮ©įO║═ę╗ą®ęÄäØĪŻ
1.öĄō■╠Ä└Ē╝╝ągæ¬ė├
ī”ė┌öĄō■╠Ä└Ē╝╝ągüĒšfŻ¼╬ęéāų„ę¬╩ŪąĶę¬ĮŌøQęįŽ┬╬ÕéĆĘĮ├µĄ─å¢Ņ}Ż║
- öĄō■Ą─£╩┤_ąįĪó╝░Ģrąį
- ║Ż┴┐öĄō■Ą─īŹĢrėŗ╦Ń
- ČÓŠSöĄō■Ą─īŹĢr▒O┐ž
- ČÓŠSöĄō■Ą─š╣╩Š
- A/B£yįćīŹ¼FĘĮĘ©
▀@└’ėąą®å¢Ņ}į┌ąąśI└’ęčėą▒╚▌^│╔╩ņĄ─ĮŌøQĘĮ░ĖŻ¼ėąą®┐╔─▄Š═▓╗╩Ū├┐éĆ╣½╦ŠČ╝Ģ■┼÷ĄĮĪŻ
öĄō■▓╔╝»
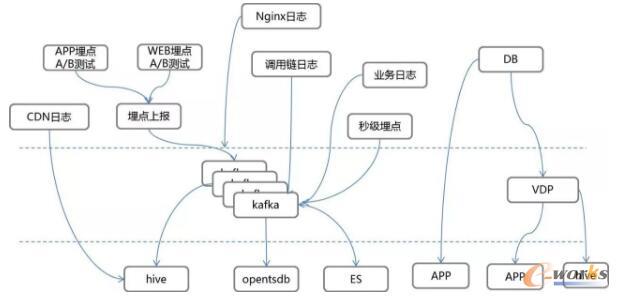
╩ūŽ╚╬ęéā┐┤öĄō■▓╔╝»Ż¼ī”╬©ŲĘĢ■üĒšfŻ¼╬ęéāų„ę¬╩Ūā╔ŅÉöĄō■Ż¼ę╗ŅÉ╩Ū╚šųŠöĄō■Ż¼ę╗ŅÉ╩ŪöĄō■ÄņöĄō■ĪŻ
ī”ė┌╚šųŠöĄō■üĒšfŻ¼╬ęéāėąā╔ŅÉ▓╔╝»Ż¼ę╗ŅÉ╩Ū┐═æ¶Č╦Ą─╚šųŠ▓╔╝»Ż¼ę╗ŅÉ╩ŪĘ■äšŲ„Č╦Ą─╚šųŠ▓╔╝»ĪŻī”ė┌Ę■äšŲ„Č╦Ą─╚šųŠ▓╔╝»Ż¼īŹļH╔Ž╩Ū▒╚▌^║åå╬Ą─Ż¼ę╗░ŃüĒšfŠ═╩Ū┬õĄĮ▒ŠĄž▒Pų«║¾Ż¼═©▀^Flumeé„╦═ĄĮ╣½╦ŠĄ─Kafka╝»╚║Ż¼╚╗║¾┤¾╝ęį┌╔Ž├µŽ¹┘MĪŻī”ė┌┐═æ¶Č╦ąą×ķĄ─▓╔╝»Ż¼Ęų│╔ā╔ĘNŻ¼ę╗ĘN╩ŪWebČ╦Ą─▓╔╝»Ż¼ę╗░ŃüĒšfŠ═╩Ū═©▀^«É▓ĮšłŪ¾į┌Nginx╔Ž┬õ╚šųŠŻ╗Ą┌Č■éĆ╩ŪAPPČ╦Ą─▓╔╝»Ż¼ę╗░Ń╩Ū═©▀^ę╗éĆĮė┐┌š{ė├Ą─ĘĮ╩ĮŻ¼░č▀@ą®öĄō■┬õĄĮĘ■äšČ╦Ż¼į┘ė╔Ę■äšČ╦░č▀@éĆöĄō■╩š╝»ŲüĒĪŻī”ė┌öĄō■ÄņĄ─▓╔╝»Ż¼īŹļH╔Ž╬ęéāę▓╩Ūėąā╔ĘNĘĮĘ©Ą─Ż¼ę╗ĘN╩Ūų▒Įėį┌Å─Äņ╔ŽüĒū÷▀@ĘNųĖś╦Ą─ėŗ╦ŃŻ¼▀Ćėąę╗ĘNŠ═╩Ūī”ė┌Å═ļsĄ─æ¬ė├Ż¼╬ęéāĢ■░čDBĄ─Binlogū÷ę╗ą®ĮŌ╬÷Ż¼ĮŌ╬÷═Ļ┴╦ų«║¾Ę┼ĄĮę╗éĆŽ¹Žó┐éŠĆ╔ŽŻ¼īŹļH╔ŽŠ═Ę┼ĄĮKafka╔ŽŻ¼╚╗║¾ūī┤¾╝ęüĒ▀Mąąę╗éĆŽ¹┘MŻ¼├┐éĆæ¬ė├Č╝╩ŪĖ∙ō■ūį╝║Ą─╠ž³cŻ¼ųžśŗūį╝║Ą─öĄō■ĮYśŗĪŻėąą®Ģ■▀ĆįŁöĄō■ÄņŻ¼ėąą®Š═ų▒Įėė├Ž¹ŽóüĒėŗ╦ŃųĖś╦Ż¼Š▀¾wę¬Ė∙ō■Ūķør▀MąąĘų╬÷ĪŻ
╔ŽłDų„ę¬├Ķ╩÷┴╦╬©ŲĘĢ■ė├ĄĮĄ─ę╗ą®ų„ę¬ķ_į┤«aŲĘŻ¼╗∙▒Š╔Ž╩Ū▀@śėĪŻ
öĄō■ėŗ╦Ń
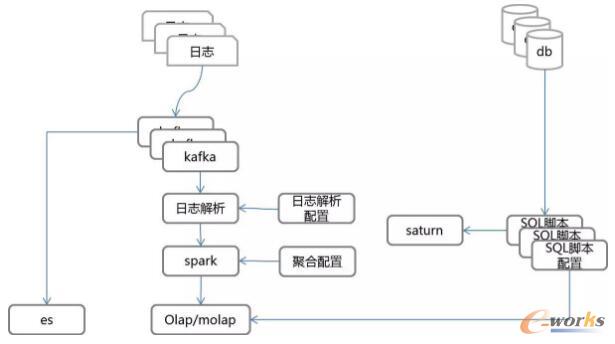
öĄō■ėŗ╦Ń╩Ū▒╚▌^ųžę¬Ą─ę╗ŁhŻ¼īŹļH╔Žę¬╝µŅÖąį─▄║═ņ`╗Ņąįā╔éĆĘĮ├µĪŻī”╚šųŠĄ─╠Ä└ĒŻ¼Ģ■ėąę╗éĆ╚šųŠĮŌ╬÷│╠ą“üĒŽ¹┘MKafkaĄ─Ž¹ŽóŻ¼“╚šųŠĮŌ╬÷”īŹ¼Fę╗éĆīŹĢrETLĄ─▀^│╠Ż¼╬ęéāĢ■Ė∙ō■┼õų├Ż©╗∙▒Š┼õų├ę▓Ė·ETL▓Ņ▓╗ČÓŻ®╚ź╔·│╔ŅAČ©┴xĄ─ś╦£╩Ė±╩ĮŻ¼║¾└mŠ═Į╗ĮoSparkū÷Š█║ŽĪŻ“╚šųŠĮŌ╬÷”ė╔ė┌╚šųŠų«ķgø]ėąŽÓĻPąįŻ¼┐╔ęįMapų«║¾▓óąąėŗ╦ŃŻ¼═╠═┬┴┐║═┘Yį┤Ą─═Č╚ļ╩Ū│╔š²▒╚Ą─Ż¼▀@śėą¦┬╩Š═ø]ėą╩▓├┤╠½ČÓĄ─å¢Ņ}ĪŻ
ī”ė┌SparkĄ─Š█║Ž┼õų├Ż¼ę╗░ŃüĒšf╬ęéāĢ■░č╚šųŠĮŌ╬÷═ĻĄ─öĄō■▀MąąČ©┴xŻ¼Č©┴xĖ„éĆūųČ╬╩ŪŠSČ╚╗“╩ŪųĖś╦Ż¼╚╗║¾Ģ■ū÷ę╗éĆ╚½ŠSČ╚Ą─Š█║ŽĪŻ▀@└’├µīŹļH╔Žę▓╩ŪėąéĆę¬Ū¾Ą─Ż¼╬ęéāę¬Ū¾╦∙ėąĄ─ųĖś╦į┌Ė„éĆŠSČ╚╔ŽČ╝Š▀ėą└█╝ėąįŻ¼╚ń╣¹▓╗Š▀éõ└█╝ėąįŻ©▒╚╚ń░┘Ęų▒╚▀@ĘNųĖś╦Ż®Ż¼╬ęéāį┌Spark└’╩Ū▓╗ū÷Š█║ŽĄ─Ż¼ų╗╩Ūį┌š╣¼FĄ─Ģr║“ųžą┬ėŗ╦ŃĪŻėŗ╦Ń║├Ą─öĄō■Ģ■Ę┼ĄĮę╗éĆOLAP║═MOLAPĄ─öĄō■Äņ└’ĪŻ
▀Ćėąę╗ĘNŪķørŻ¼╩Ū═©▀^─_▒Šį┌öĄō■ÄņÅ─Äņ╔Žų▒Įė▀MąąųĖś╦Ą─ėŗ╦ŃŻ¼ę╗░Ńė├ė┌ų╗ėąĢrķgŠSČ╚Ą─ųĖś╦ėŗ╦ŃŻ¼┼õų├║├Ą─ėŗ╦Ń─_▒ŠŻ¼╬ęéāĢ■ė├╣½╦Šķ_į┤Ą─ę╗éĆ«aŲĘSaturnüĒ▀Mąąę╗éĆĘų▓╝╩Įš{Č╚ĪŻSaturn▀@éĆ¢|╬„▀Ć╩Ū▓╗ÕeĄ─Ż¼═Ų╦]┤¾╝ę╚źćLįćę╗Ž┬ĪŻī”ė┌╚šųŠĄ─įö╝Ü▓ķįāŻ¼╬ęéā▀Ć╩ŪĘ┼ĄĮES└’Ż¼═©▀^╚½╬─Öz╦„Ą─ĘĮ╩ĮüĒ▓ķįāĪŻ
öĄō■š╣¼F
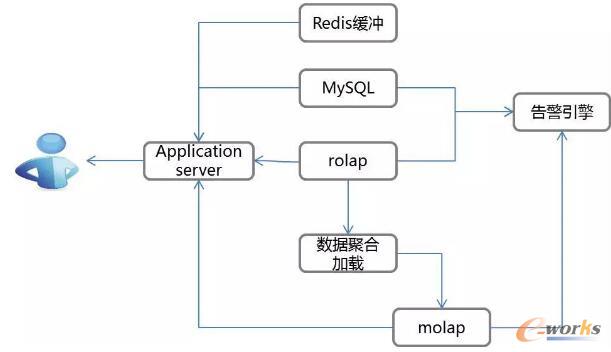
öĄō■š╣¼F╩ŪūŅĮKĄ─ĮY╣¹▌ö│÷Ż¼īŹļH╣żū„ųąŻ¼╬ęéāī”ĮY╣¹öĄō■Ą─▓ķįāą¦┬╩ę¬Ū¾▒╚▌^ć└┐┴ĪŻę“×ķ▀@ą®ĮY╣¹öĄō■▓╗āHė├ė┌Ū░Č╦Ż¼▀Ćė├ė┌ĖµŠ»▌ö│÷Ą╚Ė„éĆĘĮ├µĪŻī”ė┌ĖµŠ»Ą─öĄō■╬ęéāąĶę¬ū÷ĄĮ║┴├ļ╝ēĒææ¬Ż¼Ū░Č╦Įń├µę╗░Ńę¬Ū¾╩Ūį┌3├ļā╚õų╚Š═Ļ│╔ĪŻ×ķ┴╦═Ļ│╔▀@éĆę¬Ū¾Ż¼╬ęéāśŗĮ©┴╦ę╗éĆROLAPöĄō■ÄņŻ¼▀Ćėąę╗éĆMOLAPĄ─öĄō■ÄņŻ¼į┌ROLAPĄ─öĄō■Äņ└’Ż¼ę╗░Ńų╗┤µ«ö╠ņĄ─ČÓŠSöĄō■Ż¼Č°į┌MOLAPĄ─öĄō■Äņ└’Ż¼Ģ■┤µÜv╩ĘöĄō■ĪŻī”ė┌MOLAPöĄō■ÄņĄ─Öz╦„Ż¼ė╔ė┌æ¬ė├ų„ę¬╩ŪŪąŲ¼ĘĮ├µĄ─ąĶŪ¾Ż¼╗∙▒Š╔ŽČ╝╩ŪK-value─Ż╩ĮĄ─ę╗éĆÖz╦„Ż¼╦∙ęį╦³▒╚▌^┐ņĪŻMySQL└’ę╗░Ń╩Ū┤µĘ┼å╬ŠSČ╚ųĖś╦Ż¼æ¬įō▀@├┤ųvŻ¼╦³▓╗╩ŪČÓŠSöĄō■ĪŻRedisŠÅø_└’Ż¼ę╗░ŃĢ■┤µĘ┼╬ęéāĄ─├ļ╝ēöĄō■Ż¼▀Ćėąę╗ą®┼õų├ą┼ŽóĪŻ▀@éĆ╝▄śŗųąŻ¼ūŅ║¾═©▀^Application Server▀Mąąę╗éĆöĄō■Ą─š¹║ŽŻ¼üĒØMūŃŪ░Č╦öĄō■Ą─ę╗éĆš╣╩Šę¬Ū¾ĪŻ
- ČÓŠSĘų╬÷Įń├µ░Ė└²
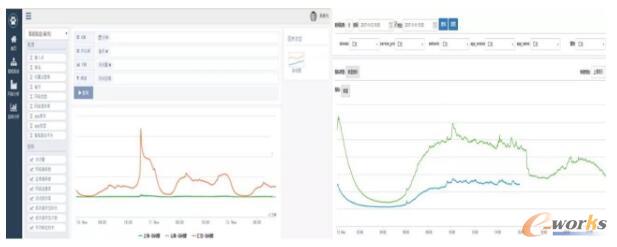
▀@╩Ūę╗éĆČÓŠSĘų╬÷░Ė└²Ą─Įń├µŻ¼ū¾▀ģ╩Ū╬ęéāĄ─Ęų╬÷ŲĮ┼_Ż¼ėę▀ģ╩Ū╬ęéāĄ─īŹĢr▒O┐žŲĮ┼_Ż¼Å─▀@╔Ž├µ┤¾╝ę─▄┐┤ĄĮŻ¼╬ęéāīŹļH╠ß╣®Ą─╣”─▄ų„ę¬╩Ūī”öĄō■ŪąŲ¼Ą──▄┴”Ż¼▀@éĆ─▄┴”╗∙▒Š┐╔ęįØMūŃ╬ęéā─┐Ū░╦∙ėąĄ─ąĶŪ¾ĪŻ
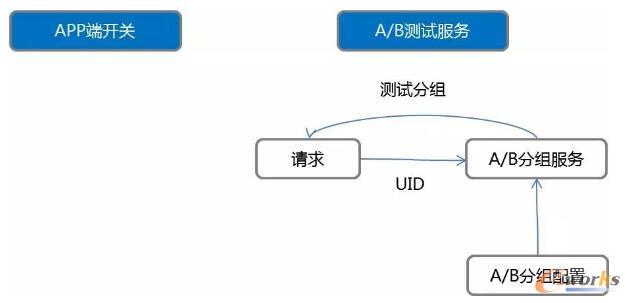
- A/B£yįćīŹ¼F
ī”ė┌öĄō■Ęų╬÷üĒšfŻ¼╗∙ė┌A/B£yįćĄ─ī”▒╚Ęų╬÷╩Ūę╗ĘNųžę¬Ą─ĘĮĘ©ĪŻę“×ķA/B£yįćī”▒╚Ą─ĮY╣¹╚▌ęū▒╗śIäš└ĒĮŌŻ¼╚ń╣¹ø]ėąA/B£yįćŻ¼─Ńšf╬ęū÷┴╦ę╗╝■╩┬ŪķŻ¼▀@╝■╩┬ŪķĦüĒ┴╦ę╗éĆ║├Ą─ą¦╣¹Ż¼▀Ć╩Ū║▄ļyĮøĄ├Ų╠¶æĄ─ĪŻį┌A/B£yįćųąŻ¼╦³ąĶę¬ę╗ą®╝╝ągüĒų¦ō╬Ą─Ż¼ę“×ķ╬ęéāį┌ŠĆ╔Ž═¼ĢrĢ■ėą║▄ČÓA/B£yįćĄ─░Ė└²═¼Ģrį┌┼▄Ż¼─Ńūį╝║Ą─A/B£yįć▓╗æ¬įō▒╗äe╚╦Ė╔ö_Ż¼į┌▀@ĘNŪķørŽ┬īŹļH╔Ž╩Ūę¬Ū¾Ė„éĆA/B£yįćų«ķgĄ─ė├æ¶Ęų▓╝Ą├Š▀ėąš²Į╗ąįŻ¼ę▓Š═╩Ūšfäe╚╦Ą─A/B£yįć╝»ė├æ¶æ¬įōŲĮŠ∙Ęų▓╝į┌─ŃĄ─A/B£yįć╝»╔ŽĪŻ
▀@ĘNīŹ¼F╬ęéā┤¾╝sėąā╔ĘNĘĮĘ©Ż¼ę╗ĘN╩ŪĢ■į┌APPČ╦įOų├ķ_ĻPŻ¼├┐éĆķ_ĻP╣▄└Ēę╗éĆA/B£yįćĄ─īŹ“×ĪŻĖ³ČÓĄ─A/B£yįćŻ¼╩ŪĮyę╗šłŪ¾║¾Č╦Ą─A/B£yįćĘųĮMĘ■䚯¼▀@éĆĘ■äš═©▀^╦ŃĘ©üĒ▒ŻūCĖ„éĆįć“×ų«ķgŽÓ╗ź¬Ü┴óĪŻę╗░ŃüĒšfŻ¼«ö┐═æ¶Č╦░lŲA/B£yįćł÷Š░Ą─Ģr║“Ż¼Š═Ģ■Ž“A/B£yįćĘųĮMĘ■äš░léĆšłŪ¾Ż¼╚╗║¾A/BĘųĮMĘ■äšĢ■ĘĄ╗ž▀@éĆė├æ¶╩Ūī┘ė┌AĮM▀Ć╩ŪBĮMŻ¼ę╗░Ń╩Ū▀@śėĄ─ĪŻ
2.öĄō■Ęų╬÷╝╝ągæ¬ė├
▀@▓┐ĘųĢ■║åå╬ĮķĮBŠ▀¾wĄ─Ęų╬÷ĘĮĘ©Ż¼▓óų„꬚fŽ┬æ¬ė├ł÷Š░║═░Ė└²ĪŻ┐éĄ─üĒšfŻ¼╬ęéāĄ─▀\ŠSöĄō■Ęų╬÷╝╝ągų„ę¬╩Ūė├ė┌ĮŌøQā╔ĘĮ├µĄ─å¢Ņ}Ż¼ę╗ĘĮ├µ╩Ū“┐āą¦Ęų╬÷”Ż¼ę╗ĘĮ├µ╩Ū“Ė∙ę“Ęų╬÷”ĪŻ
┐āą¦Ęų╬÷
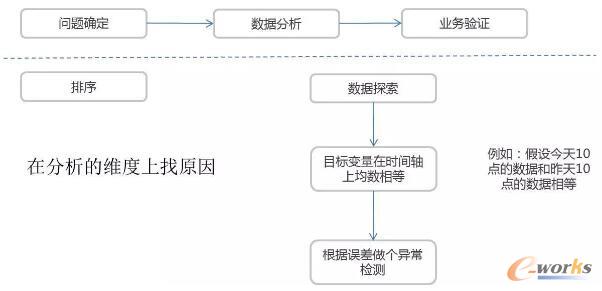
ęįŪ░╬ęéāū÷┴╦═”ČÓĄ─ĒŚ─┐Ż¼▀@ą®ĒŚ─┐ę╗░ŃüĒšfWBSĘųĮŌų«║¾Ż¼╬ęéāĢ■ī”ĒŚ─┐Ą─ĮY╣¹ū÷ę╗éĆ║åå╬Ą─Ė·█ÖŻ¼ų╗╩Ūšfū÷═Ļ┴╦Ż¼▀Ć╩Ūø]ū÷═ĻŻ¼ę╗░Ńę▓▓╗Ģ■ī”╦³ū÷ę╗ą®Č©┴┐Ą─Ęų╬÷╗“š▀šfī”▀@éĆ┘|┴┐ėąę╗éĆ┐┤Ę©ĪŻ▀@ĘNŪķørį┌╬ęéāĄ─ĒŚ─┐ųąĘŪ│Ż│ŻęŖŻ¼▀@ĘNĒŚ─┐ę╗░ŃüĒšf▒╚▌^ąĪŻ¼Č╝╩Ū┐┐éĆ╚╦╝╝ąg─▄┴”Š═─▄┐žųŲūĪĪŻ
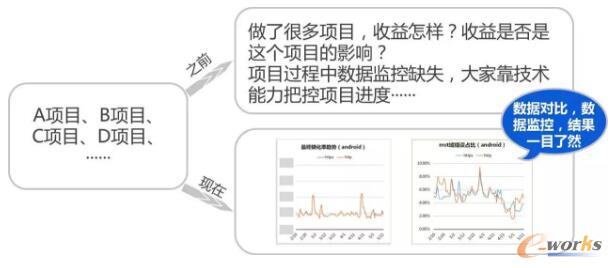
Ą½į┌┤¾ą═ĒŚ─┐ųą▀@ĘNū÷Ę©Š═║▄└¦ļyŻ¼╦³Ģ■├µ┼RĖ³ČÓĄ─ę╗éĆ╠¶æŻ¼ė╚Ųõ╩Ū┐ń▓┐ķT║Žū„Ą╚ŪķørŻ¼ę“×ķ┤¾╝ęĄ─£Ž═©╩ųĘ©▓╗āHāH╩Ū╝╝ągĄ─Ż¼┐╔─▄▀Ćėąę╗ą®╣▄└Ē╔ŽĄ─Ż¼▀@ĢrŠ═ąĶę¬┤¾╝ęė├öĄō■į┌Ė„éĆ▓┐ķTų«ķgū„×ķę╗éĆ£Ž═©Ą─ś“┴║ĪŻ
- ┐āą¦Ęų╬÷-╚½šŠHTTPSĒŚ─┐░Ė└²
ė┌╩ŪöĄō■Ęų╬÷╚╦åTŠ═ęčĮøķ_╩╝Įķ╚ļüĒ▀MąąĘų╬÷¾wŽĄĄ─įOėŗŻ¼ų„ę¬░³└©Ż║Ęų╬÷ųĖś╦Ą─įOėŗ║═Ęų╬÷ŠSČ╚Ą─įOėŗŻ¼═¼Ģr║═čą░l┤_šJöĄō■▓╔╝»ĘĮ░ĖĪóA/B£yįćĘĮ░ĖĪóĮyėŗ┐┌ÅĮĄ╚ĪŻ
ųĖś╦ų„ę¬╩ŪĖ∙ō■ĒŚ─┐ųąĖ„ĒŚ╣żū„Č╝ĻPūó╩▓├┤å¢Ņ}üĒįOėŗŻ¼Č°ŠSČ╚Ą─įOėŗ╩ŪÅ─«öųĖś╦▓╗ØMęŌĢrŻ¼┐╔ęįį┌──ą®ĘĮ├µų°╩ųĖ─▀MüĒ▀MąąĪŻ
į┌▀@éĆĒŚ─┐ųą┐╔ŅAęŖĄ─╩ŪŻ¼ė╔ė┌ūCĢ°╬š╩ųĄ─įŁę“Ż¼TCP▀BĮėĢrķgĢ■ūāķLŻ¼┐╔─▄Ģ■ė░Ēæė├涾w“ׯ¼═¼Ģrę▓Ģ■£p╔┘Į┘│ųÅ─┐é¾w╔Ž╠ßĖ▀ė├涾w“ׯ¼╦∙ęįĒŚ─┐Ą──┐ś╦įOų├×ķ▐D╗»┬╩ų┴╔┘▓╗Ž┬ĮĄŻ¼ūŅ║├─▄ėą╔Ž╔²ĪŻ
╬ęéāīŹļH╔Ž╩Ūū÷┴╦ę╗éĆHTTPSĄ─╚½šŠĒŚ─┐Ż¼į┌ĒŚ─┐ķ_╩╝ų«│§Ż¼╬ęéāŠ═ėąęŌūRĄž░čöĄō■Ęų╬÷łFĻĀ║═╝╝ąg╚╦åTš¹║ŽĄĮę╗ŲĖ·▀MĒŚ─┐Ż¼╚ĪĄ├┴╦▓╗ÕeĄ─ĮY╣¹ĪŻöĄō■Ęų╬÷╚╦åTį┌ĒŚ─┐Ą─│§Ų┌Š═ęčĮøķ_╩╝Įķ╚ļŻ¼üĒ▀MąąĘų╬÷¾wŽĄĄ─įOėŗŻ¼ų„ę¬░³└©Ż║Ęų╬÷ųĖś╦Ą─įOėŗ║═Ęų╬÷ŠSČ╚Ą─įOėŗŻ¼═¼Ģr║═čą░l┤_šJöĄō■▓╔╝»ĘĮ░ĖŻ¼A/B£yįćĘĮ░ĖŻ¼Įyėŗ┐┌ÅĮĄ╚ĪŻ
Ęų╬÷╚╦åTĢ■░č▀@ą®╣żū„ū÷║├Ż¼┐╔╦¹éāį§├┤üĒįOėŗ▀@éĆĒŚ─┐Ą─ę╗ą®ųĖś╦─žŻ┐ę╗░ŃüĒšfŻ¼į┌WBSĘųĮŌų«║¾Ż¼╬ęéāĻPūó╩▓├┤å¢Ņ}Ż¼Š═Ģ■░č▀@éĆå¢Ņ}ūāōQ│╔ę╗éĆų„ꬥ─▒O┐žųĖś╦ĪŻ─Ū╚ń║╬╚źįOČ©▀@ą®ŠSČ╚─žŻ┐
Ė─╔ŲĄ─ĄžĘĮĪŻ
╩ūŽ╚HTTPSĒŚ─┐Ż¼▓╗ų¬Ą└┤¾╝ęėąø]ėą┴╦ĮŌŻ¼╚ń╣¹┴╦ĮŌ┐╔─▄ų¬Ą└HTTPSĒŚ─┐Ż¼ę“×ķTCP╬š╩ųĢrķgĢ■čėķLŻ¼▀@ę╗³c╔Ž┐╔─▄Ģ■ōp╩¦ę╗▓┐ĘųĄ─ė├涾w“ׯ¼Ą½į┌Ę└Į┘│ųĄ╚ĘĮ├µŻ¼ėųĢ■╝ėÅŖš¹¾wĄ─ė├涾w“ׯ¼į┌▀@ĘNŪķørŽ┬Ż¼╬ęéāĒŚ─┐įO┴ó┴╦ę╗éĆūŅĮKĄ─ų„ę¬─┐ś╦Ż¼ę▓Š═╩Ū▒ŻūC▐D╗»┬╩Ż¼▀@éĆ▐D╗»┬╩▓╗─▄Ž┬ĮĄŻ¼ūŅ║├▀Ćėąę╗³c³c╠ß╔²Ż¼į┌▀@éĆų„ę¬─┐ś╦╔ŽŻ¼╬ęéāŠ═┐žųŲ▀@éĆų„ę¬─┐ś╦Ż¼▓╗═ŻĄž╗ęČ╚Ę┼┴┐Ż¼▓╗═ŻĄžš{š¹Ż¼▀@éĆą¦╣¹╩Ū▒╚▌^║├Ą─Ż¼ę“×ķį┌▀@éĆ▀^│╠ųą╬ęéā░l¼F┴╦║▄ČÓĄ─å¢Ņ}Ż¼═¼Ģr▀@éĆĒŚ─┐│ų└m┴╦┤¾╝s8éĆį┬Ż¼į┌8éĆį┬ųą╬ęéāø]ėą░l╔·▀^╚╬║╬ųž┤¾Ą─╣╩šŽĪŻ

▀@éĆ░Ė└²╩Ūī”Õeš`┬╩Ą─Ęų╬÷║═▒O┐žŻ¼ėąę╗┤╬░l¼F╬ęéāĄ─Õeš`┤a╩ŪHTTPSĄ─ūCĢ°šJūC▀^▓╗╚źŻ¼▀@ĘNŪķørį┌─│éĆ╩Ī─│éĆ▀\ĀI╔╠┤¾ęÄ─ŻĄž░l╔·Ż¼╬ęéāÅ─Ęų╬÷Ą─ĮŪČ╚┐┤▀@ą®╣سcIP╩Ū▓╗╩Ū╬ęéāūį╝║Ą─IPŻ¼▀@śė╬ęéāŠ═ų¬Ą└į┌▀@éĆĄžĘĮ░l╔·┴╦┤¾ęÄ─ŻĄ─DNSĮ┘│ųå¢Ņ}Ż¼ė┌╩ŪŠ═╚źģfš{«öĄžĄ─▀\ĀI╔╠░č▀@éĆ╩┬ŪķĖŃČ©ĪŻöĄō■Ęų╬÷ę▓Ģ■░l¼Fę╗ą®┤·┤aųąĄ─å¢Ņ}Ż¼╬ęéāū÷HTTPSĒŚ─┐Ż¼┐╔─▄ę¬ī”┤·┤a▀Mąąę╗ą®ą▐Ė─Ż¼▒╚╚ńšfį┌š¹éĆHTML└’╩Ū▓╗─▄┤µį┌HTTPģfūhĄ─ė▓ŠÄ┤aŻ¼Ą½ė╔ė┌Üv╩ĘįŁę“Ż¼▀@ĘNĄžĘĮ▀Ć╩Ū▒╚▌^ČÓĄ─Ż¼ķ_░l╚╦åT║▄ļy┼┼▓ķ═ĻŻ¼īŹļH╔ŽąĶę¬Ęų╬÷╚╦åT═©▀^öĄō■Ęų╬÷╩ųČ╬╚ź▓ķŻ¼░č▀@ą®ø]ėąĖ─▀^Ą─┤·┤ašę│÷üĒĪŻ
▀Ćėąę╗ą®łDŲ¼Ą─å¢Ņ}Ż¼╬ęéā░l¼Fę╗ą®łDŲ¼Ą─Ų┤ĮėÕeš`Ż¼«ö╚╗╩Ūł¾┴╦404Ż¼ł¾┴╦404ų«║¾Ż¼╬ęéāī”▀@éĆÕeš`┤aĘų╬÷Ż¼░l¼F═╗╚╗ČÓ┴╦Ż¼░čł¾ÕeĄ─URLū÷ę╗éĆ┼┼ą“║¾░l¼Fę╗ą®╩ŪŲ┤ĮėĄ─Õeš`Ż¼▀Ćėąę╗ą®╩Ūė╔ė┌╠ž╩ŌūųĘ¹ę²ŲČ°ī¦ų┬┴╦¤oĘ©╔·│╔š²┤_Ą─šłŪ¾ĪŻ╬ęéāī”TCPĄ─╬š╩ųĢrķLę▓Ģ■▀MąąĖ·█ÖŻ¼į┌ū÷╗ęČ╚▀xą═ļAČ╬Ż¼╬ęéāį┌▓╗═¼Ą─╚ļ┐┌▓╔ė├┴╦▓╗═¼Ą─╝╝ągŅÉą═Ż¼═©▀^Ęų╬÷Ė„éĆ╚ļ┐┌Ą─╬š╩ųĢrķLüĒ▌oų·▀\ŠS╚╦åT▀Mąąę╗éĆ╝ė╦┘┐©Ą─▀xą═Ż¼▀Ćėąę╗ą®ģóöĄš{š¹Ą╚╣żū„ĪŻ
- ┐āą¦Ęų╬÷-Ųõ╦³░Ė└²ł÷Š░
▀@éĆĒŚ─┐▀Mąą═Ļ│╔ų«║¾Ż¼╬ęéā┐éĮY┴╦║▄ČÓĮø“ׯ¼┬²┬²Ąžį┌Ųõ╦³Ą─ĒŚ─┐ųąę▓ųØuėąęŌūRĄž▀\ė├öĄō■Ęų╬÷╝╝ągŻ¼░čöĄō■Ęų╬÷╚╦åT║═╝╝ąg╚╦åTėąą¦ĄžĮY║Žį┌ę╗ŲĪŻ
▀@└’├µę▓ėąÄūéĆ░Ė└²Ż¼▒╚╚ńšfCDNÅS╔╠ŪąōQĢrŻ¼╬ęéāę¬Ė·█ÖÕeš`┬╩ĪóĒææ¬Ģrķg▀@śėĄ─ę╗ą®ųĖś╦Ż¼üĒøQČ©ŪąōQ╩ŪʱąĶę¬╗žØLŻ╗┤┘õNŪ░Ą─ę╗ą®┴„┴┐š{Č╚Ż¼╬ęéāę▓ę¬Ęų╬÷š{Č╚▓▀┬įĄ─ŅAŲ┌ĮY╣¹Ż¼▒╚╚ńšfĖ„éĆ╚ļ┐┌Ą─┴„┴┐╩Ū▓╗╩Ū░┤╬ęéāĄ─ėŗäØ░č▀@éĆ┴„┴┐š{Č╚ĄĮ╬╗┴╦Ż╗├┐┤╬APP░µ▒ŠĄ─Ė³ą┬Ż¼╬ęéāę▓ąĶę¬▓╗═ŻĄžüĒĖ·█Ö╦³Ą─įLå¢▀B═©┬╩ĪóŠWĮj▀B═©┬╩Ą╚ę╗ą®ĻPµIųĖś╦ĪŻ

Ė∙ę“Ęų╬÷
į┌öĄō■Ą─╗∙ĄA╔ŽŻ¼╬ęéāę▓┐╔ęįū÷ę╗ą®įŁę“Ą─▓ķšęŻ¼═©▀^öĄō■Ęų╬÷▀MąąĄ─įŁę“▓ķšęėąĢr┐╔ęįų▒ĮėÄ═╬ęéāČ©╬╗ĄĮå¢Ņ}Ż¼į┌Ė³ČÓĄ─Ģr║“┐╔ęįėąą¦ĄžÄ═╬ęéā┐sąĪå¢Ņ}Ą─ĘČć·ĪŻ═©▀^öĄō■üĒ▓ķšęįŁę“Ż¼▀@ŲõīŹ╩Ūėąę╗Č©ŠųŽ▐ąįĄ─Ż¼ŠųŽ▐ąįŠ═į┌ė┌öĄō■Ą─ŠSČ╚Ż¼ę“×ķ╬ęéāų╗─▄į┌Ęų╬÷Ą─ŠSČ╚╔ŽüĒ▀Mąą▓ķšęŻ¼╚ń╣¹╣╩šŽĄ─įŁę“ø]ėąį┌╬ęéāęčų¬ŠSČ╚╔ŽŻ¼īŹļH╔Ž╩Ūšę▓╗│÷üĒĄ─Ż¼Ą½┤¾▓┐ĘųĢr║“▀Ć╩Ū─▄ŲĄĮ▒╚▌^ĻPµIĄ─ū„ė├ĪŻ

ī”ė┌ų▒Įė└¹ė├ČÓŠSöĄō■▀Mąąå¢Ņ}Ą─Ęų╬÷Ż¼╬ęéā┤¾╝sėą╚²éĆ▓Į¾EŻ¼Ą┌ę╗éĆ▓Į¾EŠ═╩Ūę¬┤_Č©å¢Ņ}Ż¼┤_Č©å¢Ņ}ų«║¾Ż¼Š═┤_Č©┴╦╩Ū──éĆųĖś╦ėąå¢Ņ}Ż¼Ą┌Č■▓Į╩Ūū÷ę╗ą®öĄō■╔ŽĄ─Ęų╬÷Ż¼ūŅ║¾šęĄĮå¢Ņ}ų«║¾Ż¼╬ęéāę¬ū÷öĄō■║═śIäš╔ŽĄ─ę╗ą®“×ūCŻ¼ų„ꬥ─ĘĮĘ©ėąā╔ĘNŻ║
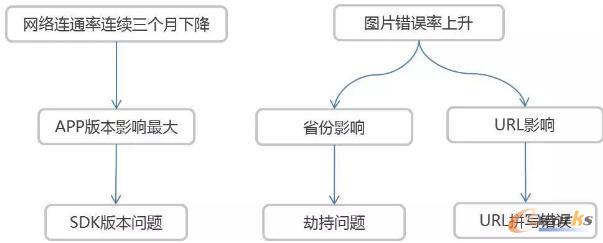
Ą┌ę╗ĘN╩Ū┼┼ą“▒ĒŻ¼▀@éĆūŅ║åå╬┴╦Ż¼Š═╩Ū╚╦č█┐┤Ż¼═©▀^┼┼ą“╬ęéā┐╔ęįĮŌøQ70-80%Ą─å¢Ņ}ĪŻĄ┌Č■ĘNŠ═ėą³cūįäė╗»Ą─ęŌ╦╝┴╦Ż¼╬ęéāĮąöĄō■╠Į╦„Ż¼╦³ėąę╗éĆįŁ└ĒŻ¼īŹļH╔Ž▓ó▓╗╩Ū╦∙ėąĄ─öĄō■Č╝─▄▀Mąą╠Į╦„Ż¼╬ęéā─┐Ū░Š═╩Ū╝┘įO▀@éĆöĄō■į┌╚╬ęŌŪąŲ¼╔ŽŻ¼į┌ĢrķgŠSČ╚╔Ž╦³╩Ūī┘ė┌Š∙ä“Ęų▓╝Ą─Ż¼į┌▀@ĘNŪķørŽ┬╬ęéāšJ×ķ▀@éĆš`▓ŅųĄ╩ŪĘ¹║Žš²æBĘų▓╝Ą─Ż¼Š═┐╔ęį▒╚▌^╚▌ęūĄžū÷ę╗éĆ«É│ŻĄ─Öz£yüĒ┐┤├┐éĆöĄō■ŪąŲ¼╔Ž╩Ūʱėąå¢Ņ}Ż¼«ö╦∙ėąĄ─öĄō■▒╗╠Į╦„═Ļų«║¾Ż¼å¢Ņ}Ą─įŁę“ę▓╗∙▒Š─▄šęĄĮĪŻ
- Ė∙ę“Ęų╬÷-░Ė└²
▀@╩ŪĘŪīŹĢrĖ∙ę“Ęų╬÷Ą─ę╗ą®░Ė└²Ż║
╬ęéāėąę╗┤╬ŠWĮj▀B═©┬╩▀B└m╚²éĆį┬Ž┬ĮĄŻ¼╬ęéāĘų╬÷ĄĮūŅ║¾Ż¼░l¼F▀@éĆAPPĄ─░µ▒Šėąą®å¢Ņ}Ż¼─│╠ņų«║¾╦∙ėąą┬░l▓╝Ą─APP░µ▒Š▀B═©┬╩Ž┬ĮĄČ╝▒╚▌^┤¾Ż¼Ė·čą░lĘ┤üų«║¾Ż¼╦¹éāŠ═į┌SDKū÷┴╦ę╗ą®š{š¹Ż¼īŹļH╔Žšµš²Õeį┌──Ż¼╬ęéā▓ó▓╗ų¬Ą└Ż¼╬ęéāų╗─▄ų¬Ą└▀@éĆ░µ▒Šėąå¢Ņ}Ż¼Ė³ČÓĄž╚źÄ═ų·╝╝ąg╚╦åT┐sąĪ▀@éĆĘČć·ĪŻį┘Š═╩ŪłDŲ¼Õeš`┬╩╔Ž╔²Ż¼äé▓┼ęčĮøĮķĮB▀^┴╦ĪŻ
į┘Š═╩ŪīŹĢrĄ─Ė∙ę“Ęų╬÷Ż¼äé▓┼ųvĄ─ŲõīŹČ╝╩Ūę╗ą®ŲĮĢrĄ─░Ė└²Ż¼Č°īŹļH╔Ž╬ęéāę▓ū÷īŹĢrĄ─ŽĄĮyŻ¼▀@ą®īŹĢrĄ─ŽĄĮyŠ═╩ŪŽŻ═¹└¹ė├ČÓŠSöĄō■Ż¼į┌ŽĄĮyĖµŠ»║“Ż¼─▄ē“Ä═ų·┤¾╝ęĖ³┐ņČ©╬╗ę╗ą®å¢Ņ}ĪŻ▀@└’ę▓ėąā╔éĆ└²ūėŻ║

ę╗éĆŠ═╩Ū▀B═©┬╩Ž┬ĮĄų«║¾Ż¼╬ęéāĢ■░l¼F─│ŅÉÕeš`┤a╩Ūė░ĒæĄ─ę╗éĆų„ę¬ę“╦žŻ¼ėąßśī”ąįĄžĮŌøQå¢Ņ}║¾Ż¼░l¼F▀B═©┬╩╗ųÅ═┴╦Ż¼▀@śė╗∙▒Š╔Ž┐╔ęįČ©╬╗╣╩šŽĪŻ
į┘ėąŠ═╩Ū─│ę╗éĆæ¬ė├Ą─Õeš`┬╩ėą╔Ž╔²Ż¼╬ęéāĢ■┐┤ĄĮėąą®╩ĪĘ▌ė░Ēæ▒╚▌^┤¾Ż¼Š▀¾w┐┤╩Ūę╗ą®CDN╣سcĄ─╣╩šŽŻ¼ŪąōQ║¾Ż¼╣╩šŽĄ├ĄĮ╗ųÅ═ĪŻ┐é¾w┐┤Ż¼īŹĢrĘų╬÷▀Ć╩Ū─▄ē“▒╚▌^┐ņĄžÄ═ų·▀\ŠS╚╦åTČ©╬╗å¢Ņ}ĪŻ
3.öĄō■═┌Š“╝╝ągæ¬ė├
ī”ė┌öĄō■═┌Š“üĒšfŻ¼╬ęéā─┐Ū░╦∙æ¬ė├Ą─ł÷Š░Ż¼╗“š▀šf─▄Ä═╬ęéāĮŌøQĄ─å¢Ņ}ų„ę¬ėą╚²ŅÉŻ║ę╗ŅÉ╩ŪŅA£yŻ¼ę╗ŅÉ╩Ū«É│ŻÖz£yŻ¼«É│ŻÖz£yų„ę¬╩Ūė├üĒū÷ĖµŠ»ķōųĄūįäėĄ─įOų├ĪŻĄ┌╚²ŅÉ╩Ūū÷ę╗ą®Ė∙ę“Ą─Ęų╬÷Ż¼╦³Ą──┐Ą─║═äé▓┼ųvĄ─╗∙ė┌öĄō■Ęų╬÷Ą─Ė∙ę“Ęų╬÷╩Ūę╗śėĄ─Ż¼Ą½į┌īŹ¼F╔Ž╦ŃĘ©ėąą®▓╗═¼ĪŻ
ŅA£y
╬ęéā¼Fį┌Ą─ŅA£yŻ¼ų„ę¬╩Ūū÷┴╦ę╗ą®śIäšųĖś╦Ą─ŅA£yŻ¼▒╚╚ńŽ±PVĪóUVĪóėåå╬Īó┘Å╬’▄ć▀@śėĄ─ę╗ą®śIäšųĖś╦Ż¼Ž┬├µ╬ęųvę╗Ž┬ėåå╬Ą─ŅA£yĪŻ
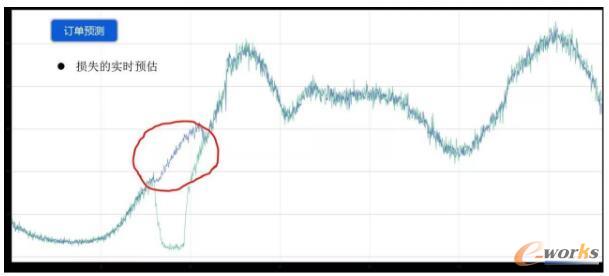
▀@╩Ū╬ęéāĄ─ėåå╬ŅA£yłDĪŻ«öĢrū÷▀@éĆŅA£yŻ¼īŹļH╩Ūėąæ¬ė├Ą─ł÷Š░Ż¼«ö╣╩šŽ░l╔·ĢrŻ¼ąĶę¬īŹĢrĖ·█ÖŅAėŗĄ─ōp╩¦Ż¼ęį▒Ńė┌╬ęéā┤_Č©╣╩šŽĄ─Ą╚╝ēŻ¼▀ĆėąŠ═╩Ūš{Č╚ĮŌøQ╣╩šŽąĶꬥ─┘Yį┤┴┐ĪŻ┤¾╝ę┐╔ęį┐┤ĄĮŻ¼▀@ĘNŅA╣└╬ęéā▀Ć╩Ū▒╚▌^╚▌ęū┐╔ęį╦Ń│÷üĒĄ─Ż¼į┌╩▓├┤Ģr║“▀@éĆ╣╩šŽęčĮø║├┴╦Ż¼╩▓├┤Ģr║“╦³Ą─ōp╩¦▀_ĄĮ╩▓├┤│╠Č╚Ż¼╬ęéāĄ─╣╩šŽ╩Ū▓╗╩ŪąĶę¬╔²╝ēĪŻ
▀@└’├µėąę╗éĆ╝╝ąg³cąĶę¬ĮŌøQŻ¼Š═╩Ūšf╬ęéāį┌╣╩šŽĄ─Ģr║“Ż¼īŹļHųĄęčĮøĄ¶Ž┬╚ź┴╦Ż¼Č°╬ęéāĄ─ŅA£y╦ŃĘ©ąĶę¬Ū░ę╗ĘųńŖ║═Ū░ÄūĘųńŖĄ─öĄō■Ż¼×ķ┴╦▓╗░č╣╩šŽĄ─öĄō■ę²╚ļĄĮ╦ŃĘ©ųąŻ¼į┌╣╩šŽĄ─Ģr║“Ż¼╩Ūė├ŅA£yųĄ┤·╠µšµīŹųĄĪŻŠ▀¾wüĒšfŻ¼Š═╩Ūė├╔Žę╗ų▄Ą─öĄō■ū÷ę╗ą®ŲĮŠ∙Ą─╝ė│╔üĒ╠µōQŻ¼╚╗║¾į┘ū÷Ž┬ę╗┤╬Ą─ŅA£yĪŻ
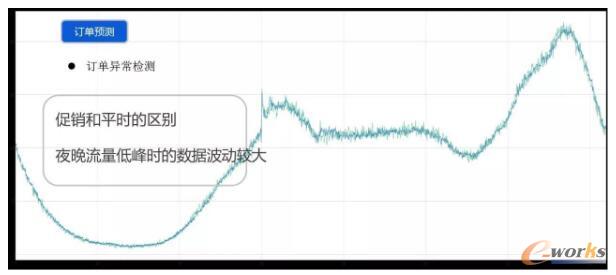
ī”ė┌ŅA£y╦ŃĘ©Ż¼╬ęéāķ_╩╝▓╔ė├Ą─╩ŪĢrķgą“┴ąųąĄ─holt-winters╦ŃĘ©Ż¼ę“×ķ╬ęéā╣½╦ŠĄ─öĄō■ų▄Ų┌ąį▒╚▌^├„’@Ż¼╬ęéāį┌Ģrķgą“┴ą╔Žū÷öM║ŽĢr▀Ć╩Ū▒╚▌^£╩┤_Ą─Ż¼æ¬įōüĒšfą¦╣¹▀Ć▒╚▌^║├ĪŻĄ½▀@éĆ╦ŃĘ©ĄĮ┴╦ę╗Č©Ģr║“Ż¼╬ęéāŠ═┼÷ĄĮ┴╦ę╗ą®å¢Ņ}Ż¼ę╗éĆŠ═╩Ū┤┘õN║═ŲĮĢr▓╗╠½ę╗śėŻ¼ę▓Š═╩Ūšf┤┘õNĄ─öĄō■Ż¼╬ęéā╩ŪöM║Ž▓╗╔ŽĄ─ĪŻĄ┌Č■éĆŠ═╩Ūį┌ĖµŠ»║═ę╗ą®ę╣═Ē┴„┴┐Ą═ĘÕĢrŻ¼▀@éĆöĄō■▓©äė▀Ć╩Ū▒╚▌^┤¾Ą─Ż¼ĖµŠ»Ą─£╩┤_┬╩ę▓▓╗╩Ū║▄Ė▀Ż¼╬ęéāį§├┤üĒĮŌøQ▀@éĆå¢Ņ}─žŻ┐
Ž╚┐┤┤┘õNĪŻī”ėåå╬┴┐üĒšfŻ¼ėåå╬▀_ĄĮĖ▀ĘÕų«Ū░Ż¼╬ęéāĄ─PVĪóUV░³└©╩š▓žöĄĄ╚śIäšųĖś╦ęčĮøķ_╩╝åóäė┴╦Ż¼╬ęéāŠ═Ģ■░č▀@ą®śIäšųĖś╦ę²╚ļ╬ęéāĄ─Ęų╬÷─Żą═Ż¼ę▓Š═╩Ū╬ęéāĢ■░čPVĪóUVĪó╩š▓žöĄŻ¼░³└©╔Žų▄═¼Ų┌Ą─▀@ą®öĄō■Ż¼║═╔Žų▄╬ęéāę¬ŅA£y─ŪéĆĢrķg³cĄ─ėåå╬öĄ╚½▓┐Č╝ę²▀MüĒŻ¼╚╗║¾ė├ę╗éĆÖCŲ„īW┴ĢĄ─▐kĘ©Ż¼╗∙▒Š╔ŽŠ═┐╔ęįĮŌøQ▀@éĆå¢Ņ}ĪŻį┌ļp11┤┘õN║¾ė^▓ņ┴╦ę╗Ž┬ŅA£yĄ─ŪķørŻ¼¼Fį┌┤┘õNŅA£yĄ─öĄųĄ▀Ć╩Ū▒╚▌^£╩Ą─ĪŻ
«ö╗∙ė┌ŅA£y▀MąąĖµŠ»ĢrŻ¼┼÷ĄĮų„ę¬å¢Ņ}╩Ūę╣═ĒĄ═ĘÕĢröĄō■▓©äė▌^┤¾Ż¼╚ń╣¹░┤├┐éĆĢrķg³cĄ─ųĖś╦ų▒Įė▀MąąĖµŠ»ĘŪ│Ż╚▌ęūš`ł¾ĪŻ╬ęéā▓╔ė├Ą─▐kĘ©╩ŪŅA╣└ōp╩¦└█ėŗĄ─ł¾Š»ĘĮĘ©Ż¼«ö└█ėŗŅA╣└ōp╩¦▀_ĄĮ100å╬ĢrŠ═▀MąąĖµŠ»Ż¼▀@śėš{š¹║¾Ż¼╬ęéāÅ─╔ŽŠĆĄĮ¼Fį┌╗∙▒ŠęčĮøø]ėą┴╦š`ĖµĪŻ▀@éĆ100å╬Ą─įOų├Ż¼Ė·╬ęéā╣½╦ŠĄ─ųŲČ╚ėąĻPŻ¼ę“×ķ╬ęéā╣½╦Š▀_ĄĮ┴╦200å╬Īó300å╬Ż¼─ŪŠ═╩Ūųž┤¾╣╩šŽ┴╦Ż¼╬ęéāį┌100å╬Ą─Ģr║“Ż¼Š═░č▀@éĆŠ»ł¾Įo└ŁŲüĒŻ¼╩Ū┐╔ęįĘ└ų╣ųž┤¾╣╩šŽ░l╔·Ą─ĪŻ
Ė∙ę“Ęų╬÷
ūŅ║¾į┌öĄō■═┌Š“▀@▓┐ĘųĄ─æ¬ė├Ż¼Įo┤¾╝ęĮķĮBę╗Ž┬Ė∙ę“Ęų╬÷ĪŻ
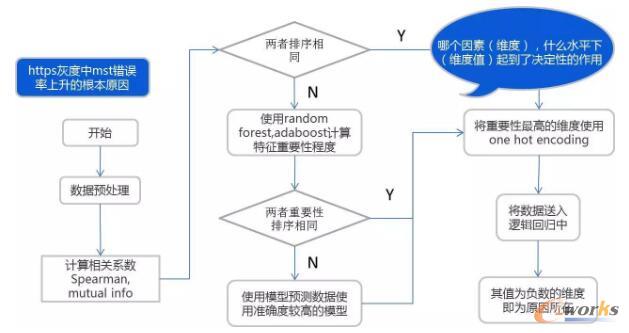
╬ęéā▀@╠ū╦ŃĘ©Įø▀^ÄūéĆ░Ė└²Ą─ćLįćŻ¼╗∙▒Š╔ŽČ╝─▄šę│÷įŁę“Ż¼╩ūŽ╚Š═╩Ū╦³Ė·ČÓŠSĘų╬÷Ą─“Ė∙ę“Ęų╬÷”▓╗╠½ę╗śėŻ¼ČÓŠSĘų╬÷Ą─“Ė∙ę“Ęų╬÷”╩ŪĮ©┴óį┌ęčĮøėŗ╦Ń║├Ą─ČÓŠSöĄō■╗∙ĄA╔ŽŻ¼Č°▀@éĆ╦ŃĘ©īŹļH╔Ž╩ŪÅ─įŁ╩╝öĄō■üĒ│ķśėĄ─ĪŻ▒╚╚ńšfŻ¼Ž±Õeš`┬╩╔Ž╔²Ą─ę╗éĆĖ∙ę“Ęų╬÷Ż¼╬ęéā╩ūŽ╚Ģ■│ķę╗ą®öĄō■Ż¼░čÕeĄ─║═š²┤_Ą─╚šųŠĖ„│ķ50%Ż¼ī”ĘŪöĄō■┴ą▀MąąŅAŠÄ┤aĪŻŅA╠Ä└Ēų«║¾Ż¼╬ęéāĢ■ė├Spearman║═Mutual Information▀@ā╔ĘN╦ŃĘ©üĒėŗ╦ŃĖ„éĆŠSČ╚║═ĮY╣¹ų«ķgĄ─ŽÓĻPąį│╠Č╚Ż¼╚ń╣¹▀@ā╔ĘNĘĮĘ©ĮY╣¹ę╗ų┬Ż¼ätų▒Įė░┤ŽÓĻPąįųĄ┤¾ąĪ▀Mąą┼┼ą“Ż¼╚╗║¾Ģ■ė├One hot encodingū÷ę╗éĆ▐D┤aŻ¼▐D┤aų«║¾Ę┼╚ļ▀ē▌ŗ╗žÜw─Żą═ųąŻ¼▀xō±L1Ą─æ═┴PĒŚŻ¼╚ń╣¹╦³Ą─ŽĄöĄ╦Ń│÷üĒ╩ŪžōųĄŻ¼▀@éĆžōųĄ╦∙┤·▒ĒĄ─ŠSČ╚Š═╩ŪįŁę“╦∙į┌ĪŻ╚ń╣¹╔Ž╩÷ĘĮĘ©ā╔éĆĮY╣¹▓╗ę╗ų┬Ż¼▓╔ė├random forest║═adaboostĄ─ĘĮĘ©śŗĮ©śõ─Żą═Ż¼▓ķ┐┤─Żą═Įo│÷Ą─ŠSČ╚ųžę¬ąįŻ¼▀@└’╬ęęčĮø«ŗĄ├║▄ŪÕ│■┴╦Ż¼╚ń╣¹ā╔éĆ─Żą═Ą─ųžę¬ąį┼┼ą“ę╗ų┬Ż¼Š═ū▀╔Ž┤╬─ŪéĆ▓Į¾EŻ¼╚ń╣¹▓╗═¼Ż¼ätė├įō─Żą═ī”öĄō■▀MąąŅA£yŻ¼▀xō±ŅA£yĮY╣¹▌^Ė▀Ą─ŽÓĻPąį┼┼ą“ĪŻ
4.æ¬ė├╔·æBĮ©įO╝░ęÄäØ
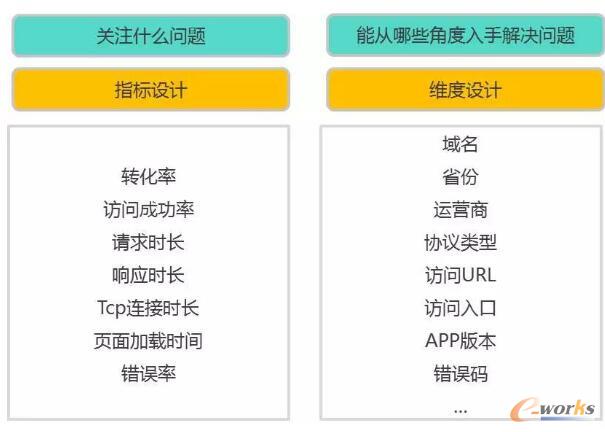
ūŅ║¾Ė·┤¾╝ęę╗Ųėæšōę╗Ž┬Ż¼╚ń║╬ūīöĄō■│╔×ķ▀\ŠSĄ─┤¾─XĪŻĖ∙ō■╬ęéāĄ─Įø“ׯ¼╩ūŽ╚Å─ĮM┐ŚĮYśŗ╔ŽüĒšfŻ¼╬ęéāąĶę¬ę╗éƬÜ┴óĄ─Ęų╬÷łFĻĀĪŻę“×ķį┌▀@éĆĘų╬÷łFĻĀ│╔┴óų«Ū░Ż¼╣½╦ŠĄ─▀\ŠS¾wŽĄīŹļH╔Žę▓į┌╩╣ė├öĄō■Ż¼╩╣ė├öĄō■Ą─ĘĮĘ©║═Ęų╬÷łFĻĀ║¾üĒ╩╣ė├Ęų╬÷öĄō■Ą─ĘĮĘ©ę▓╩Ū┤¾═¼ąĪ«ÉŻ¼Ą½ę“×ķ╦³▒Š╔Ē╩Ūę╗éĆūį░lĄ─Ż¼ø]ėąę╗ą®ÅŖųŲąįĄ─ę¬Ū¾ĪŻį┌░čöĄō■Ęų╬÷╚┌╚ļĄĮ╣żū„┴„│╠ų«║¾Ż¼╬ęéā░l¼Fą¦┬╩Ģ■Ą├ĄĮę╗éĆ▒╚▌^┤¾Ą─╠ß╔²Ż¼═¼Ģrų¬ūRĄ─é„│ąŻ¼░³└©Įyėŗ┐┌ÅĮĄ╚▀@ą®▒╚▌^┴Ņ╚╦└¦╗¾Ą─å¢Ņ}ę▓Č╝┐╔ęįĄ├ĄĮę╗éĆ▒╚▌^║├Ą─╣▄└Ē║═ĮŌøQĪŻ
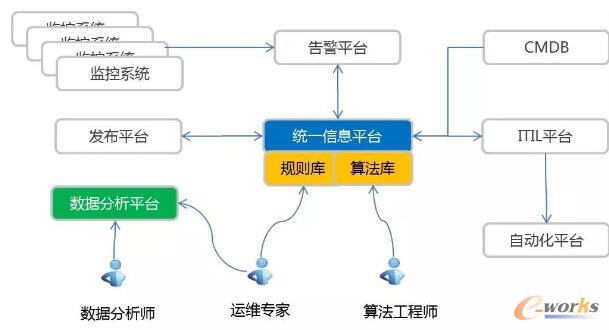
▀@śėĄ─ĮM┐Ś╝▄śŗį┌╬ęéāĄ─īŹ█`ųąŻ¼ĖąėX┐╔ęįĖ³║├ĄžÄ═ų·▀\ŠSīŻ╝ęüĒĮŌøQå¢Ņ}ĪŻ
Å─ŲĮ┼_Į©įO╔ŽüĒšfŻ¼æ¬įō╩Ūšf¼Fį┌ęčĮøķ_╩╝┴╦Ż¼ų°┴”┤“įņĄ─ŲõīŹ╩Ūā╔éĆŲĮ┼_Ż¼ę╗éĆ╩ŪöĄō■Ęų╬÷Ą─ŲĮ┼_Ż¼öĄō■Ęų╬÷ŲĮ┼_šfĄĮĄūŠ═╩Ū▀\ŠSĄ─öĄō■é}ÄņŻ¼╦³╩╣ė├¼Fį┌┤¾öĄō■Ą─ę╗ą®é„Įy╝╝ągüĒū÷▀@╝■╩┬ŪķŻ¼Ą┌Č■éĆ╩ŪĮyę╗ą┼ŽóĄ─ŲĮ┼_ĪŻ“Įyę╗ą┼ŽóŲĮ┼_”ų„ę¬┐╝æ]ĄĮį┌╗ź┬ōŠW╣½╦ŠŻ¼▓╗╣▄╩Ū▓╗╩Ūį┌ę░ąU│╔ķLļAČ╬Ż¼┤²▀^Ą─╚╦Č╝Ģ■ų¬Ą└Ż¼ŽĄĮy╠žäeČÓŻ¼ą┼Žóę▓╩Ū╠žäeĘų╔óŻ¼╬ęéā▀Ć╩ŪŽļ░č▀@ą®Ęų╔óĄ─ĻPµIą┼Žó┐┤į§├┤╩š╝»ŲüĒŻ¼╚╗║¾┐┤─▄▓╗─▄ū÷ę╗ą®╩┬ŪķĪŻ─┐Ū░╬ęéāĢ■░č░l▓╝ŲĮ┼_Ą─ę╗ą®░l▓╝ą┼ŽóŻ¼▀ĆėąITILŲĮ┼_Ą─ę╗ą®╩┬╝■ą┼ŽóĪóūāĖ³ą┼ŽóŻ¼CMDBĄ─ę╗ą®╗∙ĄA╝▄śŗą┼ŽóŻ¼į┘ėąŠ═╩ŪĖ„ĘNĖ„śėĄ─▒O┐žŽĄĮyĄ─ųĄ░Ó▒Ēą┼Žó║═ĖµŠ»ą┼ŽóŻ©▀@ĘN▒O┐žŽĄĮy╬ęéāėą║├Äū╩«╠ūŻ®Ż¼╬ęéāČ╝Ģ■░č╦³éāĘ┼ĄĮą┼ŽóÄņ└’├µĪŻį┌ą┼ŽóÄņĮ©įOų«║¾Ż¼╬ęéā╦ŃĘ©ļm╚╗┐╔ęįīŹļHėąą¦ĄžĮŌøQ³c╔ŽĄ─å¢Ņ}Ż¼Ą½▀Ćø]─▄║▄║├ĄžĮŌøQĻP┬ōąį╔ŽĄ─å¢Ņ}Ż¼▀@ēK▀Ć╩Ū═”└¦ļyĄ─ĪŻų╗─▄╩Ūšf«öŪ░╩Ūę╗╝■╩┬Ūķę╗╝■╩┬Ūķ╚źĮŌøQŻ¼─Ū▀@ĘNÅ═ļsĄ─ĻP┬ōąį╬ęéā┐┐╩▓├┤─žŻ┐
┐┐Ą─╩ŪęÄätÄņŻ¼ė├śIäšų¬ūRča│õ«öŪ░ļAČ╬╦ŃĘ©╔ŽĄ─ę╗ą®▓╗ūŃĪŻę▓Š═╩Ūšfį┌š¹éĆŽĄĮyĮ©įOųąŻ¼īŹļH╔Ž╦ŃĘ©Äņ║═ęÄätÄņČ╝╩Ūę╗ŲĮ©įOĄ─Ż¼▓╗Ģ■šfŻ¼Š═ė├╦ŃĘ©Š═▓╗ę¬ęÄät┴╦Ż¼╗“ų╗ėąęÄätŻ¼╦ŃĘ©ę▓ø]╩▓├┤ė├Ż¼╦³╩Ūę╗¾wĮ©įOĄ─Ż¼Č°Ūę╦³éā─▄ĮŌøQĄ─å¢Ņ}▓╗ę╗śėŻ¼╦ŃĘ©╬ęéā╩ŪĮŌøQ³c╔ŽĄ─å¢Ņ}Ż¼ęÄät╬ęéā╩Ūė├üĒĮŌøQ▀@ĘNĻP┬ōąįĄ─å¢Ņ}Ż¼ė╚ŲõÅ═ļsśIäšĻP┬ōĄ─å¢Ņ}Ż¼Č╝┐┐ęÄätüĒ┼õų├Ą─ĪŻ
š¹éĆ▀@╠ūŲĮ┼_Ą─Į©įO╦³ų„ę¬ėąā╔éĆ─┐ś╦Ż¼Č╠Ų┌─┐ś╦Š═╩Ūšfī”ĖµŠ»▀Mąąėąą¦Ą─ę╗éĆē║ųŲĪó╣▄└ĒĪó║Ž▓óŻ¼Ą┌Č■éĆ─┐ś╦Š═╩ŪŽļ─▄ē“ĮŌøQūįäė╣╩šŽČ©╬╗Ą─å¢Ņ}ĪŻ─┐Ū░╩Ūėąę╗Č©Ą─│╔ą¦Ż¼Ą½£╩┤_┬╩▀Ćø]ėą─Ū├┤Ė▀Ż¼ęį║¾─▄ū÷Ą├║├Ą─Ģr║“Ż¼╬ęéāĢ■Žļ═©▀^ITILŲĮ┼_üĒ“īäėūįäė╗»ŲĮ┼_ī”¼FŠWĄ─╣╩šŽ▀Mąąūįäė╗»Ą─╠Ä└ĒŻ¼▒╚╚ńšfŽ±ųžåóĪóĮĄ╝ēŻ¼Ž▐┴„Ż¼┤┼▒P┐šķg╣▄└ĒŻ¼┴„┴┐š{Č╚Ą╚╣żū„ĪŻæ¬įō╩Ūšf×ķ┴╦ūįäė╗»▀\ŠSĪóĮŌøQ╣╩šŽę╗Ų┼¼┴”░╔ŻĪ
ęį╔ŽŠ═╩Ū╬ęéāī”öĄō■æ¬ė├į┌╬┤üĒę╗éĆĢrŲ┌ā╚Ą─Č©┴xŻ¼ę▓╩ŪŽļį┌╬┤üĒ┤¾╝s░ļ─ĻĄĮę╗─Ļ─▄ē“┐┤ĄĮĖ³ČÓ│╔╣¹Ą─ę╗éĆīŹ█`ĪŻĮ±╠ņĘųŽĒŠ═ĄĮ▀@└’Ż¼ųxųx┤¾╝ęŻĪ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║╬©ŲĘĢ■▀\ŠSöĄō■╝╝ągīŹ█`Ą─╚²ųžŠ│Įń
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839324474.html






















