



Ė„╬╗┼¾ėč┤¾╝ę║├Ż¼╬ę╩ŪŅÖ╚½Ż¼─┐Ū░Š═┬Üė┌HVRųąć°╣½╦Šō·╚╬┤¾ųą╚Aģ^╝╝ąg┐é▒Oę╗┬ÜĪŻĘŪ│ŻĖ▀┼dĮ±╠ņ─▄ē“ėąÖCĢ■║═┤¾╝ęū÷éĆĘųŽĒ║═Į╗┴„ĪŻ
Ž╚║åå╬ūį╬ęĮķĮBę╗Ž┬ĪŻ╬ę╩Ū98─Ļ«ģśIė┌ųąć°┐ŲīW╝╝ąg┤¾īWŻ¼īŻśI╩Ūėŗ╦ŃÖC┐ŲīWĪŻ«ģśI║¾Ž╚╚źAMDū÷┴╦2─ĻĄ─öĄō■Äņæ¬ė├ķ_░lŻ¼╚╗║¾ėųū÷┴╦2─ĻĄ─OracleERP╝╝ągŅÖå¢Ż¼2003─Ļ╬ę╝ė╚ļ┴╦Quest╣½╦ŠĪŻų„꬞ōž¤APM║═öĄō■ÄņīŹĢrÅ═ųŲ«aŲĘĪŻæ¬įō╦Ń╩Ūć°ā╚ūŅįńĮėė|▀@ĘN╗∙ė┌öĄō■Äņ╚šųŠĄ─Å═ųŲ╝╝ągĄ─ĪŻį┌Quest╣żū„Ą─10─Ļ└’ę▓ėH╩ųīŹ╩®┴╦┤¾┴┐Ą─ąąśIś╦ŚUĒŚ─┐ĪŻ
2013─Ļ╬ę╝ė╚ļ┴╦SAPŻ¼ų„꬞ōž¤Ą─▀Ć╩ŪöĄō■Äņ║═BI«aŲĘŻ¼░³└©ā╚┤µėŗ╦Ń╝╝ągŻ¼ŅA£yĘų╬÷╝╝ągĄ╚┤¾öĄō■ĮŌøQĘĮ░ĖĪŻ
Į±╠ņ╩Ū╬ęĄ┌ę╗┤╬ģó╝ė┤¾öĄō■ļsšäĄ─╗ŅäėŻ¼╝╚╚╗╬ęéā▀@╩ŪéĆ┤¾öĄō■╝╝ągų„Ņ}Ą─╚║Ż¼╬ęŽļ╬ęŠ═▀Ć╩ŪÅ─┤¾öĄō■šäŲĪŻ
┤¾öĄō■Ęų╬÷┼cé„ĮyBIĄ─ģ^äe

łD1 DTĢr┤·Ą─▒│Š░
▀@éĆŲ¼ūėĄ─ā╚╚▌Ż¼╬ęŽÓą┼┤¾╝ęæ¬įōČ╝▓╗─░╔·┴╦ĪŻ┤¾öĄō■Ą─4éĆV(öĄō■┴┐Ż¼öĄō■Å═ļsąįŻ¼öĄō■«a╔·╦┘Č╚║═ārųĄ)ūŅĮK─▄ē“¾w¼F×ķārųĄŻ¼▒Š┘|╔Žę▓╩ŪęįĘų╬÷×ķ║╦ą─Ą─Ż¼Ä═ų·Ų¾śI╠ß╔²śIäšČ┤▓ņ┴”Ż¼Å─Č°╠ßĖ▀ĮM┐Śā╚▓┐╔§ų┴ĮM┐Śų«ķgĄ─ģf═¼─▄┴”ĪŻ
┤¾öĄō■Ęų╬÷┼cé„ĮyBIĄ─ūŅ┤¾Ą─ģ^äeŻ¼╬ęĄ─└ĒĮŌėąŽ┬├µÄūéĆĘĮ├µŻ║
1.ŅA£yąįĪŻĖ„éĆ┤¾╣½╦Šį┌═Ų╦¹éāĄ─┤¾öĄō■ĮŌøQĘĮ░ĖĄ─Ģr║“Č╝į┌ÅŖš{╦¹éāĄ─ŅA£yĘų╬÷─▄┴”ĪŻ
2.ŠC║ŽąįĪŻé„ĮyBI═∙═∙╩Ūų„Ņ}Ęų╬÷Ż¼┤¾öĄō■Ęų╬÷═∙═∙╩ŪŠC║ŽąįŻ¼┐ńė“┐ńśI䚥─Ęų╬÷ĪŻ═∙═∙▒Ē¼Fį┌▓╗═¼öĄō■ų«ķg░l¼Fā╚║¼Ą─ŽÓĻPąįŻ¼Å─Č°┐éĮY╠ߤÆ│÷ą┬Ą─ų¬ūR║═ĘĮĘ©ĪŻ
3.īŹ¼FĖ³Ė▀īė┤╬Ą─┘Yį┤š¹║ŽŻ¼īŹ¼Fģf═¼ą¦æ¬ĪŻ
▀@└’╬ęųvéĆ└²ūė┐╔─▄Ģ■Ė³╝ė╚▌ęū└ĒĮŌĪŻ
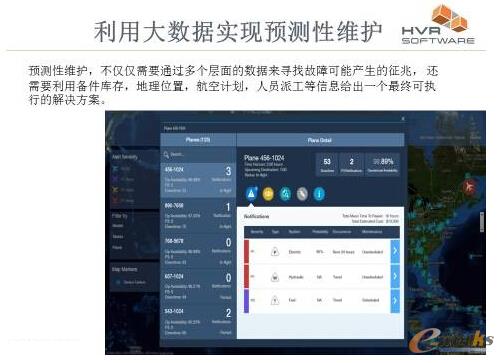
łD2 └¹ė├┤¾öĄō■īŹ¼FŅA£yąįŠSūo
╬ęéāęį║Į┐š«aśI×ķ└²ĪŻĖ∙ō■GEšfĘ©Ż¼įńį┌2013─Ļ╦¹éā╔·«aĄ─║Į┐š░läėÖC├┐╠ņŠ═Ģ■«a╔·│¼▀^1TBĄ─öĄō■Ż¼▀@╩ŪĄõą═Ą─╬’┬ōŠWöĄō■Ż¼ę▓Š═╩ŪÖCŲ„«a╔·öĄō■ĪŻ▀@ą®čb┼õį┌║Į┐š░läėÖC╔ŽĄ─Ė„ĘNé„ĖąŲ„¤oĢr¤o┐╠Ąž«a╔·║Ż┴┐Ą─öĄō■ĪŻ
═©▀^ī”▀@ą®öĄō■Ą─╩š╝»║═Ęų╬÷Ż¼╬ęéā┐╔ęįī”’wÖCĄ─“ĮĪ┐Ą”ĀŅørū÷│÷įu╣└ĪŻ▀@╩ŪīŹ¼FŅA£yąįŠSūoĄ─╗∙ĄAŻ¼ŽÓ▒╚ė┌ęÄČ©├┐’wąąČÓ╔┘ąĪĢr╗“└’│╠Š═▒žĒÜ▀Mąą╚½├µÖzą▐ę╗┤╬üĒšfŻ¼╬ęŽļ┤¾╝ę║▄╚▌ęū└ĒĮŌ▀@ĘNŅA£yąįŠSūo┤¾┤¾╠ßĖ▀ŠSūo╣żū„Ą─Š½£╩ąį═¼Ģrę▓┤¾Ę∙Č╚ĮĄĄ═┴╦ŠSūo│╔▒ŠĪŻ
╬ęéā¼Fį┌╝┘įOę╗╝▄’wÖCį┌▒▒Š®’w═∙╔Ž║ŻĄ─▀^│╠ųąŻ¼╬ęéāĄ─┤¾öĄō■Ęų╬÷Įo│÷Š»Ėµšfū¾é╚Ą─░läėÖCļm╚╗╚įį┌š²│Ż╣żū„Ż¼Ą½öĄō■▒Ē├„ėąØōį┌Ą─’LļUŻ¼▀@ėą┐╔─▄╩Ūė╔ė┌─│éĆ╗“─│ÄūéĆ┴Ń▓┐╝■└Ž╗»įņ│╔Ż¼─Ū├┤ĮėŽ┬üĒįōį§├┤▐k─žŻ┐┴ó┐╠’w═∙ą▐└ĒÅS▀Mąą╚½├µĄ─Öz▓ķ║═ŠSą▐├┤Ż┐╚ń╣¹▀@śėū÷Ą─įÆ┐╔─▄│╔▒Š▀Ć▓╗╚ńČ©Ų┌Özą▐üĒĄ─Ą═ĪŻ
└ĒŽļĄ─ū÷Ę©╩ŪĖ∙ō■’wÖCĄ─’wąąėŗäØ(Ž┬ę╗šŠ╩Ū╔Ž║ŻŻ¼ĮėŽ┬üĒ┐╔─▄╩Ū╔Ņ█┌…)Ż¼╔Ž║Ż╗“š▀╔Ņ█┌ĖĮĮ³╩ŪʱėąŽÓæ¬Ą─┴Ń▓┐╝■Äņ┤µęį╝░╝╝ąg╚╦åTą┼Žó(╝╝─▄Ż¼Ģrķg░▓┼┼)Ż¼╔§ų┴▀Ćę¬┐╝æ]╠ņÜŌ║═║Į┐š╣▄ųŲą┼Žóėŗ╦Ń’wÖC═Ē³cĄ─’LļUüĒ╔·│╔ę╗éĆÖzą▐ėŗäØ;╚╗║¾Ė∙ō■ėŗäØŽ“ŽÓĻP╣®æ¬╔╠Ż¼Ę■äš╔╠Ž┬▀_▓╔┘Åėåå╬ĪŻĘ■äš╔╠ĮėĄĮėåå╬║¾┴ó┐╠░▓┼┼╣żå╬┼╔│÷╝╝ąg╚╦åTĦų°┴Ń▓┐╝■į┌ųĖČ©ĢrķgĄĮųĖČ©Ąž³c╠ß╣®’wÖCĄ─Özą▐Ę■äšĪŻī”ė┌║Į┐š╣½╦ŠüĒšf╠ßĖ▀┴╦’wąąĄ─░▓╚½ąįĄ─═¼ĢrŻ¼ĮĄĄ═┴╦š¹¾wĄ─│╔▒ŠŻ¼╣╩šŽį┌ØōĘ³│§Ų┌▒╗░l¼F▓óĮŌøQ;ī”╣®æ¬╔╠║═Ę■äš╔╠╠ß╔²┐╔┐═æ¶ØMęŌČ╚ę▓ĮĄĄ═┴╦ūį╝║Ą─ŠSą▐│╔▒ŠĪŻ
▀@éĆ╣╩╩┬╩Ū▓╗╩Ū║▄░¶Ż┐╬ęšJ×ķ▀@īó╩ŪŲõųąę╗éĆ┤¾öĄō■Ą─╬┤üĒ░lš╣ĘĮŽ“Ż¼▀@└’╬ęéā┐╔ęį┐┤ĄĮŅA£yĘų╬÷╝╝ąg▒╗ČÓ┤╬▀\ė├Ż¼Ęų╬÷Ą─öĄō■ę▓│╩¼FČÓį¬╗»æBä▌Ż¼ėąą®╩Ūūį╝║Ą─śIäšöĄō■(║Į┐š╣½╦Šā╚▓┐ERPöĄō■Ż¼’wąąėŗäØöĄō■Ż¼║Į┐š░ÓĮM║═ĄžŪ┌╚╦åTą┼Žó)Ż¼ėąą®╩Ū═Ō▓┐öĄō■(╠ņÜŌą┼ŽóŻ¼║Į┐š╣▄ųŲą┼ŽóŻ¼▀\ĀI╔╠Äņ┤µ║═╝╝ągĘ■äš╚╦åTą┼Žó)Ż¼▀@ą®öĄō■ėąą®╩Ū╬’┬ōŠW«a╔·Ą─░ļĮYśŗ╗»╔§ų┴ĘŪĮYśŗ╗»öĄō■ĪŻ
═©▀^▀@śėę╗╠ū┤¾öĄō■æ¬ė├Ż¼’wÖCĪóÖCł÷Īó║Į┐š╣½╦Šęį╝░╣®æ¬╔╠Ę■äš╔╠▒╗ėąÖCĄ─š¹║ŽĄĮ┴╦ę╗ŲŻ¼īŹ¼F┴╦Ė³Ė▀īė├µĄ─ģf═¼ĪŻ
į┌öĄō■╝»│╔╔Ž├µ┼RĄ─╠¶æ
×ķ┴╦īŹ¼F╔Ž├µĄ──┐ś╦Ż¼Ė„éĆ╣½╦Šį┌öĄō■Ęų╬÷ĘĮ├µėąĖ„ĘNĖ„śėĄ─╝╝ągäōą┬╬ę▀@└’Š═▓╗ČÓšä┴╦Ż¼╬ęų„ꬎļÅ─öĄō■╝»│╔ĮŪČ╚üĒ┐┤┐┤╬ęéā«öŪ░▀Ć├µ┼Rų°──ą®╠¶æĪŻ
╩ūŽ╚Š═╩ŪöĄō■Ą─üĒį┤Ż¼▀@ą®öĄō■Ė∙ō■Ųõī┘ąį╬ęéā┐╔ęįĘų│╔ęįŽ┬4┤¾ŅÉŻ║
1.Ų¾śIā╚▓┐śI䚎ĄĮyöĄō■Ż¼▀@ą®öĄō■═∙═∙╩Ūė╔OLTPśI䚎ĄĮy«a╔·Ż¼╩Ū┤µĘ┼į┌é„ĮyĄ─öĄō■Äņā╚Ż¼ī┘ė┌ĮYśŗ╗»öĄō■;
2.╬’┬ōŠWöĄō■Ż¼ė╔ÖCŲ„«a╔·Ż¼═∙═∙╩ŪČ©Ģr╔·«aę╗ŽĄ┴ą╬─╝■Ą─ĘĮ╩ĮŻ¼└²╚ńĮ╗═©┐©┐┌Ą─özŽ±Ņ^┼─Ą─ššŲ¼Ż¼’wÖC╔Žé„ĖąŲ„▓╔╝»ĄĮĄ─▀\ąąą┼ŽóĄ╚ĪŻ▀@ą®öĄō■┤¾▓┐Ęų╩Ū░ļĮYśŗ╗»╔§ų┴╩ŪĘŪĮYśŗ╗»Ą─öĄō■;
3.╗ź┬ōŠWöĄō■Ż¼ŠWšŠŻ¼╬ó▓®Ż¼bbsĄ╚«a╔·Ą─öĄō■Ż¼ęį░ļĮYśŗ╗»║═ĘŪĮYśŗ╗»öĄō■×ķų„;
4.Ųõ╦³ĮM┐ŚĄ─öĄō■Ż¼░³└©╣®æ¬╔╠Ż¼┐═æ¶Ż¼ŽÓĻPš■Ė«▓┐ķTĄ╚Ą╚ĪŻ▀@ą®ęįĮYśŗ╗»öĄō■Äņ×ķų„ĪŻ
Ųõ┤╬╩ŪöĄō■Ą─Ęų╬÷ŲĮ┼_Ż¼¼Fį┌Ė„ĘNą┬╝╝ągīė│÷▓╗ĖFŻ¼Ė„┤¾ÅS╔╠Č╝Įo│÷ūį╝║Ą─┤¾öĄō■ĮŌøQĘĮ░ĖŻ¼└²╚ńęįHadoop×ķ║╦ą─Ą─Ż¼╗“š▀ā╚┤µėŗ╦Ń╝╝ąg×ķ║╦ą─(╚ńSAPĄ─HANA)ęį╝░MPP╝▄śŗöĄō■Äņ╝╝ąg(╚ńTeradataŻ¼Greenplum)ĪŻ
▀@ą®╝╝ągĖ„ėąŲõā×╚▒³cŻ¼įĮüĒįĮČÓĄ─┐═æ¶į┌śŗĮ©ūį╝║Ą─┤¾öĄō■ĮŌøQĘĮ░ĖĢr║“═∙═∙ę▓Ģ■ŠC║Ž▓╔ė├╔Ž╩÷ČÓĘNĮŌøQĘĮ░ĖŻ¼Č°▓╗╩ŪāHāHę└┘ćå╬ę╗Ą─╝╝ągĪŻ╬ęį┌▀@└’Š═▓╗š╣ķ_┴╦ĪŻ

łD3 öĄō■║■
Ą½╩ŪąĶę¬ūóęŌĄ─╩Ū▀@ą®┤¾öĄō■ŲĮ┼_▒Š╔Ē▓╗╩ŪöĄō■Ą─üĒį┤Ż¼Č°╩ŪöĄō■Ą─┤µā”║═╠Ä└ĒŲĮ┼_ĪŻļSų°▀@ą®╝╝ągĄ─░lš╣Ż¼┤¾öĄō■ŲĮ┼_Ą─═╠═┬─▄┴”įĮüĒįĮ┤¾Ż¼▀\╦Ńą¦┬╩įĮüĒįĮĖ▀Ż¼Ė„┤¾ÅS╔╠Č╝į┌ÅŖš{ūį╝║Ą─┤¾öĄō■īŹĢr╠Ä└Ē─▄┴”Ż¼Ą½╩Ū╚ń╣¹½@Ą├Ą─öĄō■▓╗╩ŪīŹĢrŻ¼─Ū├┤īŹĢr▀\╦Ńę▓Š═╩¦╚ź┴╦╦³Ą─ęŌ┴xĪŻ╦∙ęįū„×ķ┤¾öĄō■ŲĮ┼_Ą─Ą┌ę╗╣½└’Ż¼öĄō■╝»│╔╝╝ągę▓įĮüĒįĮ╩▄ĄĮśIĮńĄ─ųžęĢĪŻ
öĄō■╝»│╔ąĶę¬┐╝æ]Ą─ę“╦žį┌▀@śėę╗éĆŠC║ŽąįĄ─ŁhŠ│└’Ż¼öĄō■╝»│╔ąĶę¬┐╝æ]──ą®ĘĮ├µĄ─ę“╦ž─žŻ┐
1.öĄō■Ą─īŹĢr▓Č½@
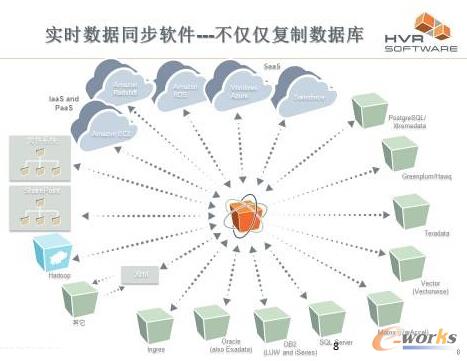
─┐Ū░╗∙ė┌╩┬äš╚šųŠĄ─öĄō■▓Č½@ęčĮøūāĄ├ĘŪ│Ż│╔╩ņŻ¼OracleėąOGGŻ¼DB2ėąCDCŻ¼SAPSybaseėąSRSŻ¼«ö╚╗ę▓░³└©╬ęéāūį╝║Ą─HVRĪŻ
▀@ĘN╝╝ągūŅ┤¾Ą─║├╠ÄŠ═╩Ūī”į┤öĄō■ÄņŽĄĮyė░Ēæ▌^Ą═Ż¼╩Ūę╗ĘNĘŪŪų╚ļ╩ĮĄ─öĄō■▓Č½@ĘĮ╩ĮĪŻ╗∙▒ŠįŁ└ĒŠ═╩Ū╦∙ėąĄ─ĻPŽĄą═öĄō■Äņ╗∙▒Š╔ŽČ╝Ģ■╠ß╣®╩┬äš╚šųŠŻ¼▓óŪę╩┬äš╚šųŠĢ■ėøõø╦∙ėąĄ─öĄō■ūā╗»ą┼ŽóŻ¼öĄō■ÄņĄ─╩┬äš╠ßĮ╗ę▓═∙═∙ęįīæ╚ļ╩┬äš╚šųŠ×ķś╦ųŠ(┤╦ĢröĄō■Äņ┐╔─▄ų╗═Ļ│╔┴╦bufferĄ─ą▐Ė─Ż¼öĄō■╬─╝■▀Ć╬┤═Ļ│╔īæ╚ļ)Ż¼═©▀^Ęų╬÷╚šųŠ╬ęéā┐═涽@Ą├╚½▓┐Ą─öĄō■ūā╗»ą┼ŽóŻ¼▓óŪę▀@ą®ą┼Žó╠ņ╚╗Š═╩Ūį÷┴┐Ą─Ż¼░┤Ģrķg┼┼ą“Ą─Ż¼▒ŻūCūxę╗ų┬ąį║═╩┬äšŪ░║¾Ēśą“Ą─ĪŻ
2.«ÉśŗŲĮ┼_ų¦│ų
łD4 īŹĢröĄō■═¼▓Į▄ø╝■
öĄō■Å═ųŲ▄ø╝■▓╗Ą½ę¬─▄ē“ų¦│ųé„ĮyĄ─ĻPŽĄą═öĄō■Äņ║═Ė„ĘN┤¾öĄō■ŲĮ┼_Ż¼▀Ć欫öų¦│ų╬─╝■ŽĄĮyÅ═ųŲŻ¼ų¦│ųįŲŁhŠ│Ą─▓┐╩ĪŻ╔Ž├µ▀@éĆłD╩Ū─┐Ū░╬ęéāĄ─HVR┐╔ęįų¦│ųĄ─ŲĮ┼_ĪŻ
3.öĄō■ē║┐s
öĄō■«a╔·Ą─į┤įĮüĒįĮÅ═ļsŻ¼Ų¾śI┐╔─▄ąĶę¬į┌▓╗═¼Ąž³cĄ─öĄō■ųąą─ų«ķgŻ¼╗“š▀į┌▒ŠĄžŽĄĮy║═įŲ╔ŽĄ─ŽĄĮyų«ķg▀MąąöĄō■Å═ųŲ;ėąą®öĄō■┐╔─▄ė╔▒ķ▓╝╚½ć°Ą─įOéõ«a╔·Ż¼└²╚ńęŲäė═©ėŹ╗∙šŠŻ¼▌öūāļŖįO╩®Ż¼╩»ė═Ń@Š«ŲĮ┼_Ą╚;╔§ų┴öĄō■«a╔·Ą─Ąž³cČ╝▓╗╩Ū╣╠Č©Ą─Ż¼└²╚ń╔Ž├µ└²ūė└’šfĄ─’wÖCŻ¼┤¼▓░;
öĄō■ē║┐s─▄┴”┐╔ęįÄ═ų·Ų¾śIśO┤¾Ą─╣Ø╝s▀\ĀI▀^│╠ųąĄ─ŠWĮj│╔▒ŠĪŻ─┐Ū░╬ęéāHVRĄ─ē║┐s╦ŃĘ©ī”ūųĘ¹ą═öĄō■┐╔ęįīŹ¼F│¼▀^95%▒Čęį╔ŽĄ─ē║┐s─▄┴”Ż¼ī”Ųõ╦³ĮYśŗ╗»öĄō■ŅÉą═ę▓┐╔ęį▀_ĄĮ50%ų┴80%Ą─ē║┐s┬╩ĪŻ
┤“éĆ▒╚ĘĮŻ¼ę╗éĆoracleöĄō■Äņ«a╔·1GBĄ─redologŻ¼ąĶę¬Å═ųŲĄ─ą┼ŽóūŅČÓ═©│Żį┌30%ū¾ėęŻ¼╬ęéā░┤šš90%Ą─ŠC║Žē║┐s┬╩üĒėŗ╦ŃŻ¼īŹļHąĶ꬚╝ė├ŠWĮjé„▌öĄ─öĄō■┴┐āHāHėą30MŻĪ
4.öĄō■╝ė├▄
▀h│╠öĄō■Å═ųŲł÷Š░ė╚Ųõ欫öųžęĢöĄō■Ą─░▓╚½ąįŻ¼Ę└ų╣öĄō■į┌é„▌ö▀^│╠▒╗Ė`╚ĪĪŻ
5.┐╔╣▄└Ēąį
▀@└’║Ł╔wĄ─ā╚╚▌Š═▒╚▌^ÅVĘ║┴╦ĪŻ
ę╗éĆĘĮ├µ╩Ū╝▄śŗ╔ŽŻ║─┐Ū░ŅÉ╦ŲĄ─▄ø╝■Į^┤¾ČÓČ╝▓╔ė├Ą─³cī”³c▓┐╩─Ż╩ĮĪŻę╗éĆĄõą═Ą─ł÷Š░┐╔─▄Ģ■╩ŪŅÉ╦ŲŽ┬├µĄ─▀@éĆ╝▄śŗłDĪŻ┤¾╝ę┐╔ęį┐┤ĄĮ▀@ĘNŠWšŠĄ─öĄō■Å═ųŲ─Ż╩Į▀ē▌ŗ╔ŽĘŪ│ŻÅ═ļsŻ¼ī”░▓čbŻ¼▓┐╩Ż¼╣▄└ĒČ╝ĦüĒ║▄┤¾Ą─ļyČ╚ĪŻ
łD5 ▄ø╝■╝▄śŗ
×ķ┴╦ĮŌøQ▀@éĆå¢Ņ}Ż¼HVR╠ß╣®ę╗éĆhub-spokenĄ─╝▄śŗŻ¼ŅÉ╦ŲŽ┬łDŻ║

łD6 hvr_integrate1
▀@śėĄ─╝▄śŗ╩╣Ą├▄ø╝■Ą─▓┐╩║═╣▄└ĒŠSūoĘŪ│Ż║åå╬Ż¼į┌├┐éĆöĄō■╣سc╔Žų╗ąĶę¬░▓čbåóäėhvr-listenerĘ■äš╝┤┐╔Ż¼╦∙ėąĄ─┼õų├Ż¼╣▄└Ē║═▒O┐ž╣żū„Č╝į┌hubĘ■äšŲ„╔Ž▀MąąŻ¼listenerĄ─╣żū„ąą×ķė╔hub╔ŽĄ─ū„śI▀M│╠š{Č╚║═╣▄└ĒĪŻ
┐╔╣▄└ĒąįĄ─┴Ē═Ōę╗éĆĘĮ├µŠ═╩Ū▒O┐ž║═Üv╩Ęł¾▒ĒĪŻ
═¼śėĄ├ęµė┌HVRŠ½¤ÆĄ─╝▄śŗįOėŗŻ¼HVR┐╔ęįĘĮ▒ŃĄž╠ß╣®žSĖ╗Ą─Üv╩ĘöĄō■ł¾▒ĒŻ¼└²╚ńÅ═ųŲĄ─čė▀tą┼ŽóŻ¼Å═ųŲĄ─öĄō■┴┐Ż¼į÷Ė─ähĄ─ėøõøöĄĄ╚ĪŻHVR▀Ć╠ß╣®┴╦═Ļ╔ŲĄ─▒O┐ž╣”─▄Ż¼«öėą╣╩šŽ░l╔·Ą─Ģr║“┐╔ęįūįäė░l╦═ĖµŠ»emailĄĮDBAĄ─Ó]Žõ╗“š▀═©▀^SNMPĘĮ╩Į░l╦═Ž¹ŽóĄĮ▒O┐žĖµŠ»ŲĮ┼_╔ŽĪŻ
6.öĄō■Ą─▐DōQ─▄┴”

łD7 é„ĮyĄ─öĄō■š¹¾wŻ©ETLŻ®┴„│╠
╔ŽłD╩Ūé„ĮyĄ─╔╠śIųŪ─▄ŅIė“═©│Ż╩╣ė├Ą─ETLĘĮĘ©ĪŻé„ĮyĄ─╔╠śIųŪ─▄ė╔ė┌ų„ę¬├µŽ“Ą─╩Ūęčų¬Ą─å¢Ņ}(ų„Ņ})Ż¼═©│Żį┌öĄō■é}ÄņĮ©įOļAČ╬ĘŪ│Żųžę¬Ą─Š═╩ŪöĄō■─Żą═įOėŗŻ¼Å─śI䚎ĄĮy╚ĪĄ├Ą─öĄō■ąĶę¬Įø▀^│ķ╚Ī(E)Ż¼▐DōQ(T)║═╝ė▌d(L)üĒ═Ļ│╔ĪŻė╔ė┌▐DōQĄ─╣żū„┴┐ėąĄ─Ģr║“ŽÓ«ö┤¾Ż¼▀ĆĢ■ąĶę¬ėąéĆīŻķTĄ─öĄō■ÄņüĒų¦ō╬Ż¼╦∙ęįėąĄ─ÅS╔╠╠ß│÷┴╦ELTĄ─ĮŌøQĘĮ░ĖĪŻ▓╗šō╩ŪETL▀Ć╩ŪELTŻ¼ę╗░ŃĄ─╣żū„╠ž³cČ╝╩ŪČ©Ģr│ķ╚ĪŻ¼┼·┴┐▐DōQ║═╝ė▌dĪŻöĄō■é}ÄņĄ├ĄĮĄ─öĄō■╩ŪĘŪīŹĢrĄ─ĪŻ
Č°┤¾öĄō■BIė╔ė┌═∙═∙├µī”Ą─╩Ū╬┤ų¬Ą─å¢Ņ}Ż¼ąĶę¬═©▀^Ė³╝ėÅVĘ║Ą─öĄō■╚ź╠Į╦„║═░l¼FŲõųąā╚║ŁĄ─ŽÓĻPąįŻ¼┤¾▓┐ĘųŪķørŽ┬ļyęįīŹ¼FŅAŽ╚Ą─öĄō■é}Äņ─Żą═Č©┴xĪŻ
Ą½ī”öĄō■ę└╚╗ąĶę¬ū÷ę╗ą®▐DōQ╣żū„ĪŻ
└²╚ń1Ż║öĄō■Ą─ąą╝ē▐DōQ

łD8 öĄō■▐DōQ
└²╚ń2Ż║öĄō■Ą─▄øäh│²║═Ģrķg┤┴▐DōQ

łD9 ▄øäh│²║═Ģrķg┤┴▐DōQ
┤¾öĄō■BIąĶꬥ─▓╗āHāHąĶꬥ─╩ŪśIäšöĄō■Ą─ĮY╣¹Ż¼śIäšöĄō■Ą─ūā╗»▀^│╠┐╔─▄Ė³ųžę¬ĪŻ
└²╚ńī”ė┌ęčĮøäh│²Ą─öĄō■Ż¼╔·«aŽĄĮy┐╔─▄▓╗į┌ąĶę¬▀@▓┐Ęųā╚╚▌Ż¼Ą½╩Ū┤¾öĄō■Ęų╬÷ę└╚╗ąĶ꬯¼Ą½╩Ūę¬═©▀^ś╦ėø┴ąüĒūRäeĪŻ╔§ų┴Ė³▀Mę╗▓ĮŻ¼ī”╦∙ėąĄ─į÷Ė─ähŻ¼┤¾öĄō■Ęų╬÷Č╝ąĶę¬▒Ż┴¶Ųõūā╗»Ą─├┐ę╗▓Į▀^│╠Ż¼▓ó═©▀^Ģrķg┤┴║═▓┘ū„ŅÉą═ĮoėĶ▒Ē╩ŠŻ¼«ö╚╗į┌┤╦╗∙ĄA╔Ž┐╔─▄▀ĆĢ■ąĶę¬▒Ż┴¶Ųõ╦³Ą─ŽÓĻPą┼ŽóŻ¼└²╚ńöĄō■üĒį┤Ż¼śIäš░lŲė├æ¶ą┼ŽóĄ╚Ą╚ĪŻ
▀@ĘNöĄō■▐DōQŲõīŹ▓╗āHāH┤¾öĄō■BIąĶ꬯¼é„ĮyĄ─╔╠śIųŪ─▄ę▓─▄Å─ųą╩▄ęµĪŻę╗ą®║åå╬Ą─ł÷Š░Ż¼öĄō■Ą─ąą╝ē▐DōQęčĮø┐╔ęįØMūŃśIäšę¬Ū¾ĪŻį┌ę╗ą®┤¾ą═Ą─BIĒŚ─┐ųąŻ¼Ģrķg┤┴▐DōQĮY║ŽETL╣żŠ▀Ą─ĘĮ░Ė┐╔ęįÄ═ų·Ų¾śI▒▄├ŌETL╣żŠ▀į┌öĄō■│ķ╚ĪĢrī”╔·«aįņ│╔Ą─ąį─▄ė░ĒæŻ¼ę▓▒▄├Ō┴╦ī”╔·«aŽĄĮy×ķ┴╦īŹ¼FöĄō■Ą─į÷┴┐│ķ╚ĪČ°▓╗Ą├▓╗▀MąąĄ─Ģrķg┤┴Ė─įņĪŻ
Q&A
Q1Ż║ī”ė┌«ÉĄžļp╗ŅöĄō■ųąą─ėą╩▓├┤║├Ą─Į©ūhå߯┐öĄō■īŹĢr╦┘Č╚ėąČÓ┐ņŻ┐
ŅÖ╚½Ż║Ž╚╗ž┤╔Ž├µ▀@ézéĆå¢Ņ}ĪŻš²│ŻŪķørŽ┬(ę▓Š═╩Ūø]ėą├„’@Ą─ŽĄĮyŲ┐Ņi)Ż¼öĄō■Ą─═¼▓Įčė▀tĢrķg╩Ūį┌├ļ╝ēŻ¼▀@┐╔─▄╩▄ĄĮŠWĮjčė▀tŻ¼╩┬䚥─┤¾ąĪŻ¼─┐ś╦öĄō■Äņąį─▄Ą─ė░ĒæĪŻī”ė┌ā╔Ąžļpųąą─Ż¼╬ęéāę▓ėą│╔╣”Ą─░Ė└²ĪŻĖ∙▒ŠĄ─įŁät╩Ū▒▄├Ōā╔ĄžśIäšöĄō■Ą─ø_═╗ĪŻ└²╚ńŻ¼ų„µIųĄĄ─ĘČć·äØĘųŻ¼╩╣Ą├š²│ŻŪķørŽ┬├┐éĆųąą─ų¦ō╬Ą─śIäš╩Ū▒╗Ęųģ^Ą─ĪŻ
Q2Ż║é„ĮyBI║═┤¾öĄō■┐ŽČ©╩Ū╬┤üĒŲ¾śI░lš╣Ą─ā╔ĘĮ├µŻ¼▓╗─▄öÓčįĄĮĄū┤¾öĄō■Ģ■▓╗Ģ■╠µ┤·é„ĮyBIĪŻ─Ū├┤å¢Ņ}į┌▀@└’Ż¼é„ĮyBI┐ŽČ©╩ŪŲ¾śIų°╩ųū÷┴╦║▄ķLĢrķgĄ─╣ż│╠┴╦Ż¼┼ÓBĄ─Ęų╬÷╚╦åTŻ¼öĄō■é}Äņķ_░låT▒ž╚╗ī”Ų¾śIĄ─ūįėąśIäš║▄Š½═©Ż¼─Ū├┤▀@ą®śIäš╚╦åT╩ŪʱĢ■ėą└^└m═∙┤¾öĄō■ĒŚ─┐╔Ž░lš╣Ą─┐╔─▄─žŻ¼▀Ć╩Ū╣½╦ŠĢ■┴ĒŲĖū╔įā╣½╦ŠüĒū÷┤¾öĄō■ĒŚ─┐Ż┐ā╔š▀Ą─▒╚└²Ż¼ę└─ŃĄ─Įø“×Ģ■ėąČÓ╔┘Ęų┼õŻ┐¼Fį┌Ą─┤¾öĄō■╩ął÷╣żŠ▀č█╗©┐ØüyŻ¼Ė„ėąŪ¦Ū’Ż¼┐ŽČ©▓╗╩Ū├┐éĆ╣żŠ▀Č╝─▄▀mæ¬╦∙ėąĄ─ĒŚ─┐╣ż│╠ĪŻ─Ū├┤╬ęéāį§├┤▀xō±▓┼─▄Ė³┐ņŪą╚ļ┤¾öĄō■ŅIė“ĪŻ╩Ūʱ┐╔ęį═Ų╦]ŽĄĮyĄ─Ģ°╗“š▀─·Ą─▓®┐═Ż┐
ŅÖ╚½Ż║▀@éĆå¢Ņ}ŲõīŹąU┤¾Ą─Ż¼╬ę▓╗šJ×ķ┤¾öĄō■BIĢ■═Ļ╚½╚Ī┤·é„ĮyBIĪŻé„ĮyBI║═┤¾öĄō■BIĢ■ėą▓╗═¼Ą─é╚ųž³cŻ¼ĮŌøQĄ─å¢Ņ}ę▓╩Ū▓╗═Ļ╚½ŽÓ═¼Ą─ĪŻĄ½╬ęŽÓą┼Ż¼┤¾öĄō■Ą──┐ś╦╩Ū╠ßĖ▀Ų¾śIĄ─śIäšČ┤▓ņ┴”Ż¼▀@éĆČ┤▓ņ┴”ūŅĮK╩Ūę¬┬õį┌Ų¾śIåT╣ż╔Ē╔ŽĄ─ĪŻ╦∙ęįśIäš╚╦åTĄ─┼ÓB╩ŪĘŪ│Żųžę¬Ą─ĪŻū╔įā╣½╦Šų„ę¬╩Ū░ńč▌ŅÖå¢Ą─ĮŪ╔½Ż¼į┌┤¾öĄō■ĒŚ─┐┬õĄžĄ─▀^│╠ųąŻ¼┐╔─▄Ė∙ō■Ų¾śIŠ▀¾wŪķørŻ¼ę└╚╗Ģ■ąĶꬎĄĮy╝»│╔╔╠Ż¼ĘĮ░Ė╣®æ¬╔╠Ż¼╔§ų┴▄ø╝■ķ_░l╔╠Ą╚ČÓĘN╗’░ķĄ─Ä═ų·ĪŻ
Q3Ż║╗∙ė┌ąąĄ─Å═ųŲŻ¼ī”┼·┴┐Ė³ą┬║═▒ĒĖ³ą┬▓┘ū„ėąų°╠ņ╚╗Ą─╚▒Ž▌ĪŻ─ŃéāĄ─«aŲĘ╚ń║╬ŠÅ║═┼·┴┐Ė³ą┬Ą─╚▒Ž▌Ż┐DDL▓┘ū„╩Ūʱ═Ė├„Ż┐
ŅÖ╚½Ż║▀@éĆ┼¾ėčšfĄ─║▄ī”ĪŻ▀@ĘNÅ═ųŲ╝╝ągæ¬įōšfų„ę¬├µī”Ą─╩Ūį┤Č╦OLTPŅÉą═Ą─śIäšĪŻĄ½╩Ū┼·╠Ä└Ē═∙═∙ę▓╩Ū▓╗┐╔▒▄├ŌĄ─ĪŻ«ö┼·╠Ä└ĒĄ─┴┐▌^┤¾Ą─Ģr║“Ż¼═∙═∙─┐ś╦Č╦öĄō■╚ļÄņ┐╔─▄Ģ■«a╔·ę╗Č©Ą─čė▀tŻ¼śIäšī”▀@éĆčė▀tĄ─╚╠╩▄Ūķør╩Ū▓╗═¼Ą─Ż¼öĄō■ęÄ─Żę▓▓Ņ«É║▄┤¾Ż¼ī”▓▀┐╔─▄ę▓Ģ■▓╗ę╗śėĪŻ▀@éĆąĶꬊ▀¾wå¢Ņ}Š▀¾wĘų╬÷┴╦ĪŻ
Q4Ż║╗∙ė┌öĄō■Äņ╚šųŠĄ─┤¾öĄō■▓╔╝»Ż¼Ė³ą┬║═äh│²═∙═∙į§├┤╠Ä└ĒŻ┐
ŅÖ╚½Ż║═©│ŻüĒšf┐╔ęį▓╔ė├╬ęč▌ųvųą╠ߥĮĄ─▐DōQ╩Š└²2Ż¼ę▓Š═╩Ū▄øäh│²╗“š▀Ģrķg┤┴▐DōQĄ─ĘĮ╩ĮüĒ╠Ä└ĒĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║öĄō■ÄņÅ═ųŲ╝╝ągį┌┤¾öĄō■BI╔ŽĄ─æ¬ė├
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839319670.html





















