



ÖCŲ„īW┴ĢŻ©Machine LearningŻ¼MLŻ®╩Ūę╗ķTČÓŅIė“Į╗▓µīW┐ŲŻ¼╔µ╝░Ė┼┬╩šōĪóĮyėŗīWĪó▒ŲĮ³šōĪó═╣Ęų╬÷Īó╦ŃĘ©Å═ļsČ╚└ĒšōĄ╚ČÓķTīW┐ŲĪŻŲõīŻķT蹊┐ėŗ╦ŃÖC╩Ūį§śė─ŻöM╗“īŹ¼F╚╦ŅÉĄ─īW┴Ģąą×ķŻ¼ęį½@╚Īą┬Ą─ų¬ūR╗“╝╝─▄Ż¼ųžą┬ĮM┐ŚęčėąĄ─ų¬ūRĮYśŗŻ¼╩╣ų«▓╗öÓĖ─╔Ųūį╔ĒĄ─ąį─▄ĪŻ┤╦═ŌŻ¼öĄō■═┌Š“║═ÖCŲ„īW┴Ģėą║▄┤¾Ą─Į╗╝»ĪŻ▒Š╬─īóÅ─╝▄śŗ║═æ¬ė├ĮŪČ╚╚źĮŌūx▀@ā╔éĆŅIė“ĪŻ
ÖCŲ„īW┴Ģ║═öĄō■═┌Š“Ą─┬ōŽĄ┼cģ^äe
öĄō■═┌Š“╩ŪÅ─║Ż┴┐öĄō■ųą½@╚Īėąą¦Ą─Īóą┬ĘfĄ─ĪóØōį┌ėąė├Ą─ĪóūŅĮK┐╔└ĒĮŌĄ──Ż╩ĮĄ─ĘŪŲĮĘ▓▀^│╠ĪŻöĄō■═┌Š“ųąė├ĄĮ┴╦┤¾┴┐Ą─ÖCŲ„īW┴ĢĮń╠ß╣®Ą─öĄō■Ęų╬÷╝╝ąg║═öĄō■ÄņĮń╠ß╣®Ą─öĄō■╣▄└Ē╝╝ągĪŻÅ─öĄō■Ęų╬÷Ą─ĮŪČ╚üĒ┐┤Ż¼öĄō■═┌Š“┼cÖCŲ„īW┴Ģėą║▄ČÓŽÓ╦Ųų«╠ÄŻ¼Ą½▓╗═¼ų«╠Äę▓╩«Ęų├„’@Ż¼└²╚ńŻ¼öĄō■═┌Š“▓óø]ėąÖCŲ„īW┴Ģ╠Į╦„╚╦Ą─īW┴ĢÖCųŲ▀@ę╗┐ŲīW░l¼F╚╬䚯¼öĄō■═┌Š“ųąĄ─öĄō■Ęų╬÷╩Ūßśī”║Ż┴┐öĄō■▀MąąĄ─Ż¼Ą╚Ą╚ĪŻÅ──│ĘNęŌ┴x╔ŽšfŻ¼ÖCŲ„īW┴ĢĄ─┐ŲīW│╔ĘųĖ³ųžę╗ą®Ż¼Č°öĄō■═┌Š“Ą─╝╝ąg│╔ĘųĖ³ųžę╗ą®ĪŻ
īW┴Ģ─▄┴”╩ŪųŪ─▄ąą×ķĄ─ę╗éĆĘŪ│Żųžę¬Ą─╠žš„Ż¼▓╗Š▀ėąīW┴Ģ─▄┴”Ą─ŽĄĮy║▄ļyĘQų«×ķę╗éĆšµš²Ą─ųŪ─▄ŽĄĮyŻ¼Č°ÖCŲ„īW┴ĢätŽŻ═¹Ż©ėŗ╦ŃÖCŻ®ŽĄĮy─▄ē“└¹ė├Įø“×üĒĖ─╔Ųūį╔ĒĄ─ąį─▄Ż¼ę“┤╦įōŅIė“ę╗ų▒╩Ū╚╦╣żųŪ─▄Ą─║╦ą─蹊┐ŅIė“ų«ę╗ĪŻį┌ėŗ╦ŃÖCŽĄĮyųąŻ¼“Įø“×”═©│Ż╩ŪęįöĄō■Ą─ą╬╩Į┤µį┌Ą─Ż¼ę“┤╦Ż¼ÖCŲ„īW┴Ģ▓╗āH╔µ╝░ī”╚╦Ą─šJų¬īW┴Ģ▀^│╠Ą─╠Į╦„Ż¼▀Ć╔µ╝░ī”öĄō■Ą─Ęų╬÷╠Ä└ĒĪŻīŹļH╔ŽŻ¼ÖCŲ„īW┴ĢęčĮø│╔×ķėŗ╦ŃÖCöĄō■Ęų╬÷╝╝ągĄ─äōą┬į┤Ņ^ų«ę╗ĪŻė╔ė┌Äū║§╦∙ėąĄ─īW┐ŲČ╝ę¬├µī”öĄō■Ęų╬÷╚╬䚯¼ę“┤╦ÖCŲ„īW┴ĢęčĮøķ_╩╝ė░ĒæĄĮėŗ╦ŃÖC┐ŲīWĄ─▒ŖČÓŅIė“Ż¼╔§ų┴ė░ĒæĄĮėŗ╦ŃÖC┐ŲīWų«═ŌĄ─║▄ČÓīW┐ŲĪŻÖCŲ„īW┴Ģ╩ŪöĄō■═┌Š“ųąĄ─ę╗ĘNųžę¬╣żŠ▀ĪŻ╚╗Č°öĄō■═┌Š“▓╗āHāHę¬čąŠ┐Īó═žš╣Īóæ¬ė├ę╗ą®ÖCŲ„īW┴ĢĘĮĘ©Ż¼▀Ćę¬═©▀^įSČÓĘŪÖCŲ„īW┴Ģ╝╝ągĮŌøQöĄō■é}ā”Īó┤¾ęÄ─ŻöĄō■ĪóöĄō■įļ┬ĢĄ╚īŹ█`å¢Ņ}ĪŻÖCŲ„īW┴ĢĄ─╔µ╝░├µę▓║▄īÆŻ¼│Żė├į┌öĄō■═┌Š“╔ŽĄ─ĘĮĘ©═©│Żų╗╩Ū“Å─öĄō■īW┴Ģ”ĪŻ╚╗Č°ÖCŲ„īW┴Ģ▓╗āHāH┐╔ęįė├į┌öĄō■═┌Š“╔ŽŻ¼ę╗ą®ÖCŲ„īW┴ĢĄ─ūėŅIė“╔§ų┴┼cöĄō■═┌Š“ĻPŽĄ▓╗┤¾Ż¼╚ńį÷ÅŖīW┴Ģ┼cūįäė┐žųŲĄ╚ĪŻ╦∙ęį╣Pš▀šJ×ķŻ¼öĄō■═┌Š“╩ŪÅ──┐Ą─Č°čįĄ─Ż¼ÖCŲ„īW┴Ģ╩ŪÅ─ĘĮĘ©Č°čįĄ─Ż¼ā╔éĆŅIė“ėąŽÓ«ö┤¾Ą─Į╗╝»Ż¼Ą½▓╗─▄Ą╚═¼ĪŻ
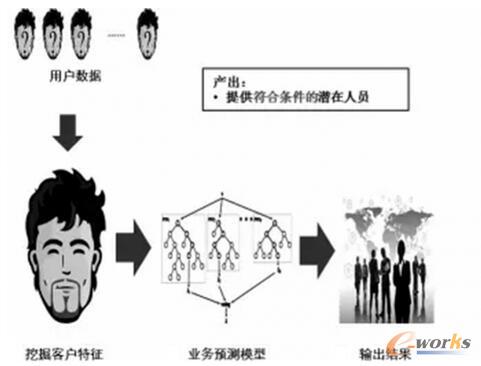
Ąõą═Ą─öĄō■═┌Š“║═ÖCŲ„īW┴Ģ▀^│╠
łD1╩Ūę╗éĆĄõą═Ą─═Ų╦]ŅÉæ¬ė├Ż¼ąĶ꬚ęĄĮ“Ę¹║ŽŚl╝■Ą─”Øōį┌╚╦åTĪŻę¬Å─ė├æ¶öĄō■ųąĄ├│÷▀@Åł┴ą▒ĒŻ¼╩ūŽ╚ąĶę¬═┌Š“│÷┐═æ¶╠žš„Ż¼╚╗║¾▀xō±ę╗éĆ║Ž▀mĄ──Żą═üĒ▀MąąŅA£yŻ¼ūŅ║¾Å─ė├æ¶öĄō■ųąĄ├│÷ĮY╣¹ĪŻ
łD1
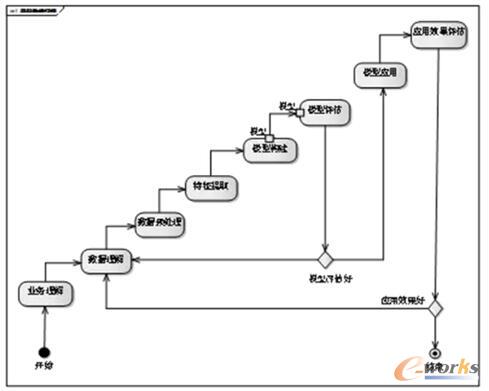
░č╔Ž╩÷└²ūėųąĄ─ė├æ¶┴ą▒Ē½@╚Ī▀^│╠▀Mąą╝ÜĘųŻ¼ėą╚ńŽ┬ÄūéĆ▓┐ĘųŻ©ęŖłD2Ż®ĪŻ
łD2
- śIäš└ĒĮŌŻ║└ĒĮŌśIäš▒Š╔ĒŻ¼Ųõ▒Š┘|╩Ū╩▓├┤Ż┐╩ŪĘųŅÉå¢Ņ}▀Ć╩Ū╗žÜwå¢Ņ}Ż┐öĄō■į§├┤½@╚ĪŻ┐æ¬ė├──ą®─Żą═▓┼─▄ĮŌøQŻ┐
- öĄō■└ĒĮŌŻ║½@╚ĪöĄō■ų«║¾Ż¼Ęų╬÷öĄō■└’├µėą╩▓├┤ā╚╚▌ĪóöĄō■╩Ūʱ£╩┤_Ż¼×ķŽ┬ę╗▓ĮĄ─ŅA╠Ä└Ēū÷£╩éõĪŻ
- öĄō■ŅA╠Ä└ĒŻ║įŁ╩╝öĄō■Ģ■ėąįļ┬ĢŻ¼Ė±╩Į╗»ę▓▓╗║├Ż¼╦∙ęį×ķ┴╦▒ŻūCŅA£yĄ─£╩┤_ąįŻ¼ąĶę¬▀MąąöĄō■Ą─ŅA╠Ä└ĒĪŻ
- ╠žš„╠ß╚ĪŻ║╠žš„╠ß╚Ī╩ŪÖCŲ„īW┴ĢūŅųžę¬ĪóūŅ║─ĢrĄ─ę╗éĆļAČ╬ĪŻ
- ─Żą═śŗĮ©Ż║╩╣ė├▀m«öĄ─╦ŃĘ©Ż¼½@╚ĪŅAŲ┌£╩┤_Ą─ųĄĪŻ
- ─Żą═įu╣└Ż║Ė∙ō■£yįć╝»üĒįu╣└─Żą═Ą─£╩┤_Č╚ĪŻ
- ─Żą═æ¬ė├Ż║īó─Żą═▓┐╩Īóæ¬ė├ĄĮīŹļH╔·«aŁhŠ│ųąĪŻ
- æ¬ė├ą¦╣¹įu╣└Ż║Ė∙ō■ūŅĮKĄ─śI䚯¼įu╣└ūŅĮKĄ─æ¬ė├ą¦╣¹ĪŻ
š¹éĆ▀^│╠Ģ■▓╗öÓĘ┤Å═Ż¼─Żą═ę▓Ģ■▓╗öÓš{š¹Ż¼ų▒ų┴▀_ĄĮ└ĒŽļą¦╣¹ĪŻ
ÖCŲ„īW┴ĢĖ┼ė[
ÖCŲ„īW┴ĢĄ─╦ŃĘ©ėą║▄ČÓŻ¼▀@└’Å─ā╔éĆĘĮ├µ▀MąąĮķĮBŻ║ę╗éĆ╩ŪīW┴ĢĘĮ╩ĮŻ¼┴Ēę╗éĆ╩Ū╦ŃĘ©ŅÉ╦ŲąįĪŻ
īW┴ĢĘĮ╩Į
Ė∙ō■öĄō■ŅÉą═Ą─▓╗═¼Ż¼ī”ę╗éĆå¢Ņ}Ą─Į©─Ż┐╔ęįėą▓╗═¼Ą─ĘĮ╩ĮĪŻį┌ÖCŲ„īW┴Ģ╗“╚╦╣żųŪ─▄ŅIė“Ż¼╚╦éā╩ūŽ╚Ģ■┐╝æ]╦ŃĘ©Ą─īW┴ĢĘĮ╩ĮĪŻį┌ÖCŲ„īW┴ĢŅIė“ėą╚ńŽ┬ÄūĘNų„ꬥ─īW┴ĢĘĮ╩ĮĪŻ
- ▒OČĮ╩ĮīW┴ĢŻ║į┌▒OČĮ╩ĮīW┴ĢŽ┬Ż¼▌ö╚ļöĄō■▒╗ĘQ×ķ“ė¢ŠÜöĄō■”Ż¼├┐ĮMė¢ŠÜöĄō■Č╝ėąę╗éĆ├„┤_Ą─ś╦ūR╗“ĮY╣¹Ż¼╚ńī”Ę└└¼╗°Ó]╝■ŽĄĮyųąĄ─“└¼╗°Ó]╝■”Īó“ĘŪ└¼╗°Ó]╝■”Ż¼ī”╩ųīæöĄūųūRäeųąĄ─“1”Īó“2”Īó“3”Īó“4”Ą╚ĪŻį┌Į©┴óŅA£y─Żą═Ą─Ģr║“Ż¼▒OČĮ╩ĮīW┴ĢĮ©┴óę╗éĆīW┴Ģ▀^│╠Ż¼īóŅA£yĮY╣¹┼c“ė¢ŠÜöĄō■”Ą─īŹļHĮY╣¹▀Mąą▒╚▌^Ż¼▓╗öÓĄžš{š¹ŅA£y─Żą═Ż¼ų▒ĄĮ─Żą═Ą─ŅA£yĮY╣¹▀_ĄĮę╗éĆŅAŲ┌Ą─£╩┤_┬╩ĪŻ▒OČĮ╩ĮīW┴ĢĄ─│ŻęŖæ¬ė├ł÷Š░░³└©ĘųŅÉå¢Ņ}║═╗žÜwå¢Ņ}ĪŻ│ŻęŖ╦ŃĘ©ėą▀ē▌ŗ╗žÜw║═Ę┤Ž“é„▀f╔±ĮøŠWĮjĪŻ
- ĘŪ▒OČĮ╩ĮīW┴ĢŻ║į┌ĘŪ▒OČĮ╩ĮīW┴ĢŽ┬Ż¼öĄō■▓ó▓╗▒╗╠žäeś╦ūRŻ¼īW┴Ģ─Żą═╩Ū×ķ┴╦═ŲöÓ│÷öĄō■Ą─ę╗ą®ā╚į┌ĮYśŗĪŻ│ŻęŖĄ─æ¬ė├ł÷Š░░³└©ĻP┬ōęÄätĄ─īW┴Ģ╝░Š█ŅÉĄ╚ĪŻ│ŻęŖ╦ŃĘ©░³└©Apriori╦ŃĘ©║═K-Means╦ŃĘ©ĪŻ
- ░ļ▒OČĮ╩ĮīW┴ĢŻ║į┌░ļ▒OČĮ╩ĮīW┴ĢŽ┬Ż¼▌ö╚ļöĄō■▓┐Ęų▒╗ś╦ūRŻ¼▓┐Ęųø]ėą▒╗ś╦ūRĪŻ▀@ĘNīW┴Ģ─Żą═┐╔ęįė├üĒ▀MąąŅA£yŻ¼Ą½╩Ū─Żą═╩ūŽ╚ąĶę¬īW┴ĢöĄō■Ą─ā╚į┌ĮYśŗŻ¼ęį▒Ń║Ž└ĒĄžĮM┐ŚöĄō■▀MąąŅA£yĪŻŲõæ¬ė├ł÷Š░░³└©ĘųŅÉ║═╗žÜwĪŻ│ŻęŖ╦ŃĘ©░³└©ę╗ą®ī”│Żė├▒OČĮ╩ĮīW┴Ģ╦ŃĘ©Ą─čė╔ņĪŻ▀@ą®╦ŃĘ©╩ūŽ╚įćłDī”╬┤ś╦ūRĄ─öĄō■▀MąąĮ©─ŻŻ¼╚╗║¾į┌┤╦╗∙ĄA╔Žī”ś╦ūRĄ─öĄō■▀MąąŅA£yŻ¼╚ńłDšō═Ų└Ē╦ŃĘ©╗“└ŁŲš└Ł╦╣ų¦│ųŽ“┴┐ÖCĄ╚ĪŻ
- ÅŖ╗»īW┴ĢŻ║į┌ÅŖ╗»īW┴ĢŽ┬Ż¼▌ö╚ļöĄō■ū„×ķī”─Żą═Ą─Ę┤üŻ¼▓╗Ž±▒OČĮ─Żą═─ŪśėŻ¼▌ö╚ļöĄō■āHāHū„×ķę╗ĘNÖz▓ķ─Żą═ī”ÕeĄ─ĘĮ╩ĮĪŻį┌ÅŖ╗»īW┴ĢŽ┬Ż¼▌ö╚ļöĄō■ų▒ĮėĘ┤üĄĮ─Żą═Ż¼─Żą═▒žĒÜī”┤╦┴ó┐╠ū÷│÷š{š¹ĪŻ│ŻęŖĄ─æ¬ė├ł÷Š░░³└©äėæBŽĄĮy╝░ÖCŲ„╚╦┐žųŲĄ╚ĪŻ│ŻęŖ╦ŃĘ©░³└©Q-Learning╝░Ģrķg▓ŅīW┴ĢŻ©Temporal Difference LearningŻ®Ą╚ĪŻ
į┌Ų¾śIöĄō■æ¬ė├Ą─ł÷Š░Ž┬Ż¼╚╦éāūŅ│Żė├Ą─┐╔─▄Š═╩Ū▒OČĮ╩ĮīW┴Ģ║═ĘŪ▒OČĮ╩ĮīW┴ĢĪŻį┌łDŽ±ūRäeĄ╚ŅIė“Ż¼ė╔ė┌┤µį┌┤¾┴┐Ą─ĘŪś╦ūRöĄō■║═╔┘┴┐Ą─┐╔ś╦ūRöĄō■Ż¼─┐Ū░░ļ▒OČĮ╩ĮīW┴Ģ╩Ūę╗éĆ║▄¤ßķTĄ─įÆŅ}ĪŻČ°ÅŖ╗»īW┴ĢĖ³ČÓĄžæ¬ė├į┌ÖCŲ„╚╦┐žųŲ╝░Ųõ╦¹ąĶę¬▀MąąŽĄĮy┐žųŲĄ─ŅIė“ĪŻ
╦ŃĘ©ŅÉ╦Ųąį
Ė∙ō■╦ŃĘ©Ą─╣”─▄║═ą╬╩ĮĄ─ŅÉ╦ŲąįŻ¼┐╔ęįī”╦ŃĘ©▀MąąĘųŅÉŻ¼╚ń╗∙ė┌śõĄ─╦ŃĘ©Īó╗∙ė┌╔±ĮøŠWĮjĄ─╦ŃĘ©Ą╚ĪŻ«ö╚╗Ż¼ÖCŲ„īW┴ĢĄ─ĘČć·ĘŪ│Ż²ŗ┤¾Ż¼ėąą®╦ŃĘ©║▄ļy├„┤_ÜwĄĮ─│ę╗ŅÉĪŻČ°ī”ė┌ėąą®ĘųŅÉüĒšfŻ¼═¼ę╗ĘųŅÉĄ─╦ŃĘ©┐╔ęįßśī”▓╗═¼ŅÉą═Ą─å¢Ņ}ĪŻ▀@└’Ż¼╬ęéā▒M┴┐░č│Żė├Ą─╦ŃĘ©░┤ššūŅ╚▌ęū└ĒĮŌĄ─ĘĮ╩Į▀MąąĘųŅÉĪŻ
- ╗žÜw╦ŃĘ©Ż║╗žÜw╦ŃĘ©╩ŪįćłD▓╔ė├ī”š`▓ŅĄ─║Ō┴┐üĒ╠Į╦„ūā┴┐ų«ķgĄ─ĻPŽĄĄ─ę╗ŅÉ╦ŃĘ©ĪŻ╗žÜw╦ŃĘ©╩ŪĮyėŗÖCŲ„īW┴ĢĄ─└¹Ų„ĪŻ│ŻęŖĄ─╗žÜw╦ŃĘ©░³└©ūŅąĪČ■│╦Ę©Īó▀ē▌ŗ╗žÜwĪóų▓Į╩Į╗žÜwĪóČÓį¬ūį▀mæ¬╗žÜwśėŚl╝░▒ŠĄž╔ó³cŲĮ╗¼╣└ėŗĄ╚ĪŻ
- ╗∙ė┌īŹ└²Ą─╦ŃĘ©Ż║╗∙ė┌īŹ└²Ą─╦ŃĘ©│Ż│Żė├üĒī”øQ▓▀å¢Ņ}Į©┴ó─Żą═Ż¼▀@śėĄ──Żą═│Ż│ŻŽ╚▀x╚Īę╗┼·śė▒ŠöĄō■Ż¼╚╗║¾Ė∙ō■─│ą®Į³╦Ųąį░čą┬öĄō■┼cśė▒ŠöĄō■▀Mąą▒╚▌^Ż¼Å─Č°šęĄĮūŅ╝čĄ─Ųź┼õĪŻę“┤╦Ż¼╗∙ė┌īŹ└²Ą─╦ŃĘ©│Ż│Ż▒╗ĘQ×ķ“┌A╝ę═©│įīW┴Ģ”╗“š▀“╗∙ė┌ėøæøĄ─īW┴Ģ”ĪŻ│ŻęŖĄ─╦ŃĘ©░³└©k-Nearest NeighborŻ©kNNŻ®ĪóīW┴Ģ╩Ė┴┐┴┐╗»Ż©Learning Vector QuantizationŻ¼LVQŻ®╝░ūįĮM┐Śė│╔õ╦ŃĘ©Ż©Self-Organizing MapŻ¼SOMŻ®Ą╚ĪŻ
- š²ät╗»╦ŃĘ©Ż║š²ät╗»╦ŃĘ©╩ŪŲõ╦¹╦ŃĘ©Ż©═©│Ż╩Ū╗žÜw╦ŃĘ©Ż®Ą─čė╔ņŻ¼Ė∙ō■╦ŃĘ©Ą─Å═ļsČ╚ī”╦ŃĘ©▀Mąąš{š¹ĪŻš²ät╗»╦ŃĘ©═©│Żī”║åå╬─Żą═ėĶęį¬ääŅŻ¼Č°ī”Å═ļs╦ŃĘ©ėĶęįæ═┴PĪŻ│ŻęŖĄ─╦ŃĘ©░³└©Ridge RegressionĪóLeast Absolute Shrinkage and Selection OperatorŻ©LASSOŻ®╝░ÅŚąįŠWĮjŻ©Elastic NetŻ®Ą╚ĪŻ
- øQ▓▀śõ╦ŃĘ©Ż║øQ▓▀śõ╦ŃĘ©Ė∙ō■öĄō■Ą─ī┘ąį▓╔ė├śõĀŅĮYśŗĮ©┴óøQ▓▀─Żą═Ż¼│Żė├üĒĮŌøQĘųŅÉ║═╗žÜwå¢Ņ}ĪŻ│ŻęŖ╦ŃĘ©░³└©ĘųŅÉ╝░╗žÜwśõŻ©Classification and Regression TreeŻ¼CARTŻ®ĪóID3Ż©Iterative Dichotomiser 3Ż®ĪóC4.5ĪóChi-squared Automatic Interaction DetectionŻ©CHAIDŻ®ĪóDecision StumpĪóļSÖC╔Ł┴ųŻ©Random ForestŻ®ĪóČÓį¬ūį▀mæ¬╗žÜwśėŚlŻ©MARSŻ®╝░╠▌Č╚═Ų▀MÖCŻ©GBMŻ®Ą╚ĪŻ
- žÉ╚~╦╣╦ŃĘ©Ż║žÉ╚~╦╣╦ŃĘ©╩Ū╗∙ė┌žÉ╚~╦╣Č©└ĒĄ─ę╗ŅÉ╦ŃĘ©Ż¼ų„ę¬ė├üĒĮŌøQĘųŅÉ║═╗žÜwå¢Ņ}ĪŻ│ŻęŖĄ─╦ŃĘ©░³└©śŃ╦žžÉ╚~╦╣╦ŃĘ©ĪóŲĮŠ∙å╬ę└┘ć╣└ėŗŻ©Averaged One-Dependence EstimatorsŻ¼AODEŻ®╝░Bayesian Belief NetworkŻ©BBNŻ®Ą╚ĪŻ
- ╗∙ė┌║╦Ą─╦ŃĘ©Ż║╗∙ė┌║╦Ą─╦ŃĘ©ųąūŅų°├¹Ą──¬▀^ė┌ų¦│ųŽ“┴┐ÖCŻ©SVMŻ®ĪŻ╗∙ė┌║╦Ą─╦ŃĘ©╩Ū░č▌ö╚ļöĄō■ė│╔õĄĮę╗éĆĖ▀ļAĄ─Ž“┴┐┐šķgŻ¼į┌▀@ą®Ė▀ļAŽ“┴┐┐šķg└’Ż¼ėąą®ĘųŅÉ╗“š▀╗žÜwå¢Ņ}─▄ē“Ė³╚▌ęūĄžĮŌøQĪŻ│ŻęŖĄ─╗∙ė┌║╦Ą─╦ŃĘ©░³└©ų¦│ųŽ“┴┐ÖCŻ©Support Vector MachineŻ¼SVMŻ®ĪóÅĮŽ“╗∙║»öĄŻ©Radial Basis FunctionŻ¼RBFŻ®╝░ŠĆąį┼ąäeĘų╬÷Ż©Linear Discriminate AnalysisŻ¼LDAŻ®Ą╚ĪŻ
- Š█ŅÉ╦ŃĘ©Ż║Š█ŅÉ╦ŃĘ©═©│Ż░┤ššųąą─³c╗“š▀ĘųīėĄ─ĘĮ╩Įī”▌ö╚ļöĄō■▀MąąÜw▓óĪŻ╦∙ėąĄ─Š█ŅÉ╦ŃĘ©Č╝įćłDšęĄĮöĄō■Ą─ā╚į┌ĮYśŗŻ¼ęį▒Ń░┤ššūŅ┤¾Ą─╣▓═¼³cīóöĄō■▀MąąÜwŅÉĪŻ│ŻęŖĄ─Š█ŅÉ╦ŃĘ©░³└©K-Means╦ŃĘ©╝░Ų┌═¹ūŅ┤¾╗»╦ŃĘ©Ż©EMŻ®Ą╚ĪŻ
- ĻP┬ōęÄätīW┴ĢŻ║ĻP┬ōęÄätīW┴Ģ═©▀^īżšęūŅ─▄ē“ĮŌßīöĄō■ūā┴┐ų«ķgĻPŽĄĄ─ęÄätŻ¼üĒšę│÷┤¾┴┐ČÓį¬öĄō■╝»ųąėąė├Ą─ĻP┬ōęÄätĪŻ│ŻęŖĄ─╦ŃĘ©░³└©Apriori╦ŃĘ©║═Eclat╦ŃĘ©Ą╚ĪŻ
- ╚╦╣ż╔±ĮøŠWĮj╦ŃĘ©Ż║╚╦╣ż╔±ĮøŠWĮj╦ŃĘ©─ŻöM╔·╬’╔±ĮøŠWĮjŻ¼╩Ūę╗ŅÉ─Ż╩ĮŲź┼õ╦ŃĘ©Ż¼═©│Żė├ė┌ĮŌøQĘųŅÉ║═╗žÜwå¢Ņ}ĪŻ╚╦╣ż╔±ĮøŠWĮj╩ŪÖCŲ„īW┴ĢĄ─ę╗éĆ²ŗ┤¾Ą─Ęųų¦Ż¼ėąÄū░┘ĘN▓╗═¼Ą─╦ŃĘ©Ż©╔ŅČ╚īW┴ĢŠ═╩ŪŲõųąĄ─ę╗ŅÉ╦ŃĘ©Ż®ĪŻ│ŻęŖĄ─╚╦╣ż╔±ĮøŠWĮj╦ŃĘ©░³└©Ėąų¬Ų„╔±ĮøŠWĮjĪóĘ┤Ž“é„▀fĪóHopfieldŠWĮjĪóūįĮM┐Śė│╔õ╝░īW┴Ģ╩Ė┴┐┴┐╗»Ą╚ĪŻ
- ╔ŅČ╚īW┴Ģ╦ŃĘ©Ż║╔ŅČ╚īW┴Ģ╦ŃĘ©╩Ūī”╚╦╣ż╔±ĮøŠWĮjĄ─░lš╣ĪŻį┌ėŗ╦Ń─▄┴”ūāĄ├╚šęµ┴«ārĄ─Į±╠ņŻ¼╔ŅČ╚īW┴Ģ╦ŃĘ©įćłDĮ©┴ó┤¾Ą├ČÓę▓Å═ļsĄ├ČÓĄ─╔±ĮøŠWĮjĪŻ║▄ČÓ╔ŅČ╚īW┴Ģ╦ŃĘ©╩Ū░ļ▒OČĮ╩ĮīW┴Ģ╦ŃĘ©Ż¼ė├üĒ╠Ä└Ē┤µį┌╔┘┴┐╬┤ś╦ūRöĄō■Ą─┤¾öĄō■╝»ĪŻ│ŻęŖĄ─╔ŅČ╚īW┴Ģ╦ŃĘ©░³└©╩▄Ž▐▓©Ā¢ŲØ┬³ÖCŻ©RBNŻ®ĪóDeep Belief NetworksŻ©DBNŻ®ĪóŠĒĘeŠWĮjŻ©Convolutional NetworkŻ®╝░Č茯╩ĮūįäėŠÄ┤aŲ„ Ż©Stacked Auto-encodersŻ®Ą╚ĪŻ
- ĮĄĄ═ŠSČ╚╦ŃĘ©Ż║┼cŠ█ŅÉ╦ŃĘ©ę╗śėŻ¼ĮĄĄ═ŠSČ╚╦ŃĘ©įćłDĘų╬÷öĄō■Ą─ā╚į┌ĮYśŗŻ¼▓╗▀^ĮĄĄ═ŠSČ╚╦ŃĘ©═©▀^ĘŪ▒OČĮ╩ĮīW┴ĢŻ¼įćłD└¹ė├▌^╔┘Ą─ą┼ŽóüĒÜw╝{╗“š▀ĮŌßīöĄō■ĪŻ▀@ŅÉ╦ŃĘ©┐╔ęįė├ė┌Ė▀ŠSöĄō■Ą─┐╔ęĢ╗»Ż¼╗“š▀ė├üĒ║å╗»öĄō■ęį▒Ń▒OČĮ╩ĮīW┴Ģ╩╣ė├ĪŻ│ŻęŖĄ─ĮĄĄ═ŠSČ╚╦ŃĘ©░³└©ų„│╔ĘųĘų╬÷Ż©Principle Component AnalysisŻ¼PCAŻ®ĪóŲ½ūŅąĪČ■│╦╗žÜwŻ©Partial Least Square RegressionŻ¼PLSRŻ®ĪóSammonė│╔õĪóČÓŠS│▀Č╚Ż©Multi-Dimensional ScalingŻ¼MDSŻ®╝░═Čė░ūĘ█ÖŻ©Projection PursuitŻ®Ą╚ĪŻ
- ╝»│╔╦ŃĘ©Ż║╝»│╔╦ŃĘ©ė├ę╗ą®ŽÓī”▌^╚§Ą─īW┴Ģ─Żą═¬Ü┴󥞊══¼śėĄ─śė▒Š▀Mąąė¢ŠÜŻ¼╚╗║¾░čĮY╣¹š¹║ŽŲüĒ▀Mąąš¹¾wŅA£yĪŻ╝»│╔╦ŃĘ©Ą─ų„ę¬ļy³cį┌ė┌Š┐Š╣╝»│╔──ą®¬Ü┴óĄ─Īó▌^╚§Ą─īW┴Ģ─Żą═Ż¼ęį╝░╚ń║╬░čīW┴ĢĮY╣¹š¹║ŽŲüĒĪŻ▀@╩Ūę╗ŅÉĘŪ│ŻÅŖ┤¾Ą─╦ŃĘ©Ż¼═¼Ģrę▓ĘŪ│Ż┴„ąąĪŻ│ŻęŖĄ─╝»│╔╦ŃĘ©░³└©BoostingĪóBootstrapped AggregationŻ©BaggingŻ®ĪóAdaBoostĪóČč»BĘ║╗»Ż©Stacked GeneralizationŻ¼BlendingŻ®Īó╠▌Č╚═Ų▀MÖCŻ©Gradient Boosting MachineŻ¼GBMŻ®╝░ļSÖC╔Ł┴ųŻ©Random ForestŻ®Ą╚ĪŻ
ÖCŲ„īW┴Ģ&öĄō■═┌Š“æ¬ė├░Ė└²
Ū░├µ┴╦ĮŌ┴╦ÖCŲ„īW┴Ģ║═öĄō■═┌Š“Ą─╗∙▒ŠĖ┼─ŅŻ¼Ž┬├µüĒ┐┤ę╗Ž┬śIĮń│╔╩ņĄ─░Ė└²Ż¼ī”ÖCŲ„īW┴Ģ║═öĄō■═┌Š“ėąę╗éĆų▒ė^Ą─└ĒĮŌĪŻ
─“▓╝║═ŲĪŠŲĄ─╣╩╩┬
Ž╚üĒ┐┤ę╗ätėąĻPöĄō■═┌Š“Ą─╣╩╩┬——“─“▓╝┼cŲĪŠŲ”ĪŻ
┐é▓┐╬╗ė┌├└ć°░ó┐Ž╔½ų▌Ą─╩└Įńų°├¹╔╠śI┴Ń╩█▀BµiŲ¾śI╬ųĀ¢¼öōĒėą╩└Įń╔ŽūŅ┤¾Ą─öĄō■é}ÄņŽĄĮyĪŻ×ķ┴╦─▄ē“£╩┤_┴╦ĮŌŅÖ┐═į┌ŲõķTĄĻĄ─┘Å┘I┴ĢæTŻ¼╬ųĀ¢¼öī”ŲõŅÖ┐═Ą─┘Å╬’ąą×ķ▀Mąą┘Å╬’╗@Ęų╬÷Ż¼Žļų¬Ą└ŅÖ┐═Įø│Żę╗Ų┘Å┘IĄ─╔╠ŲĘėą──ą®ĪŻ╬ųĀ¢¼ööĄō■é}Äņ└’╝»ųą┴╦ŲõĖ„ķTĄĻĄ─įö╝ÜįŁ╩╝Į╗ęūöĄō■Ż¼į┌▀@ą®įŁ╩╝Į╗ęūöĄō■Ą─╗∙ĄA╔ŽŻ¼╬ųĀ¢¼ö└¹ė├NCRöĄō■═┌Š“╣żŠ▀ī”▀@ą®öĄō■▀MąąĘų╬÷║══┌Š“ĪŻę╗éĆęŌ═ŌĄ─░l¼F╩ŪŻ║Ė·─“▓╝ę╗Ų┘Å┘IūŅČÓĄ─╔╠ŲĘŠ╣╚╗╩ŪŲĪŠŲŻĪ▀@╩ŪöĄō■═┌Š“╝╝ągī”Üv╩ĘöĄō■▀MąąĘų╬÷Ą─ĮY╣¹Ż¼Ę┤ė│┴╦öĄō■Ą─ā╚į┌ęÄ┬╔ĪŻ─Ū├┤Ż¼▀@éĆĮY╣¹Ę¹║Ž¼FīŹŪķørå߯┐╩Ūʱėą└¹ė├ārųĄŻ┐
ė┌╩ŪŻ¼╬ųĀ¢¼ö┼╔│÷╩ął÷š{▓ķ╚╦åT║═Ęų╬÷Ĥī”▀@ę╗öĄō■═┌Š“ĮY╣¹▀Mąąš{▓ķĘų╬÷Ż¼Å─Č°Įę╩Š│÷ļ[▓žį┌“─“▓╝┼cŲĪŠŲ”▒│║¾Ą─├└ć°╚╦Ą─ę╗ĘNąą×ķ─Ż╩ĮŻ║į┌├└ć°Ż¼ę╗ą®─Ļ▌pĄ─ĖĖėHŽ┬░Ó║¾Įø│Żę¬ĄĮ│¼╩ą╚ź┘Iŗļā║─“▓╝Ż¼Č°╦¹éāųąėą30%Ī½40%Ą─╚╦═¼Ģrę▓×ķūį╝║┘Ię╗ą®ŲĪŠŲĪŻ«a╔·▀@ę╗¼FŽ¾Ą─įŁę“╩ŪŻ║├└ć°Ą─╠½╠½éā│ŻČŻć┌╦²éāĄ─š╔Ę“Ž┬░Ó║¾×ķąĪ║ó┘I─“▓╝Ż¼Č°š╔Ę“éāį┌┘I═Ļ─“▓╝║¾ėųļS╩ųĦ╗ž┴╦╦¹éāŽ▓ÜgĄ─ŲĪŠŲĪŻ
╝╚╚╗─“▓╝┼cŲĪŠŲę╗Ų▒╗┘Å┘IĄ─ÖCĢ■║▄ČÓŻ¼ė┌╩Ū╬ųĀ¢¼öŠ═į┌ŲõĖ„╝ęķTĄĻīó─“▓╝┼cŲĪŠŲö[Ę┼į┌ę╗ŲŻ¼ĮY╣¹╩Ū─“▓╝┼cŲĪŠŲĄ─õN╩█┴┐ļpļpį÷ķLĪŻ
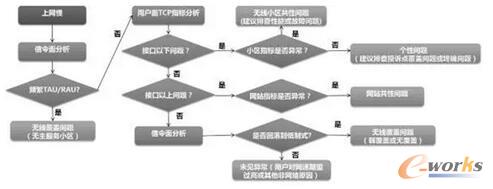
øQ▓▀śõė├ė┌ļŖą┼ŅIė“╣╩šŽ┐ņ╦┘Č©╬╗
ļŖą┼ŅIė“▒╚▌^│ŻęŖĄ─æ¬ė├ł÷Š░╩ŪøQ▓▀śõŻ¼└¹ė├øQ▓▀śõüĒ▀Mąą╣╩šŽČ©╬╗ĪŻ▒╚╚ńŻ¼ė├æ¶═ČįV╔ŽŠW┬²Ż¼ŲõųąŠ═ėą║▄ČÓĘNįŁę“Ż¼ėą┐╔─▄╩ŪŠWĮjĄ─å¢Ņ}Ż¼ę▓ėą┐╔─▄╩Ūė├æ¶╩ųÖCĄ─å¢Ņ}Ż¼▀Ćėą┐╔─▄╩Ūė├æ¶ūį╔ĒĖą╩▄Ą─å¢Ņ}ĪŻį§śė┐ņ╦┘Ęų╬÷║═Č©╬╗│÷å¢Ņ}Ż¼Įoė├æ¶ę╗éĆØMęŌĄ─┤Å═Ż┐▀@Š═ąĶę¬ė├ĄĮøQ▓▀śõĪŻ
łD3Š═╩Ūę╗éĆĄõą═Ą─ė├æ¶═ČįV╔ŽŠW┬²Ą─øQ▓▀śõĄ─śė└²ĪŻ
łD3
łDŽ±ūRäeŅIė“
- ąĪ├ū├µ┐ūŽÓāį
▀@ĒŚ╣”─▄Ą─├¹ūųĮą“├µ┐ūŽÓāį”Ż¼┐╔ęį└¹ė├łDŽ±Ęų╬÷╝╝ągŻ¼ūįäėĄžī”įŲŽÓāįššŲ¼ā╚╚▌░┤šš├µ┐ū▀MąąĘųŅÉš¹└ĒĪŻķ_åó“├µ┐ūŽÓāį”╣”─▄║¾Ż¼┐╔ęįūįäėūRäeĪóš¹└Ē║═ĘųŅÉįŲŽÓāįųąĄ─▓╗═¼├µ┐ūĪŻ
“├µ┐ūŽÓāį”▀Ćų¦│ų╩ųäėš{š¹ĘųĮMĪóęŲ│÷Õeš`├µ┐ūĪó═©▀^ŽĄĮy═Ų╦]┤_šJ├µ┐ūĄ╚╣”─▄Ż¼Å─Č°ÅøčaÖCŲ„ūRäeĄ─▓╗ūŃĪŻ
▀@ĒŚ╣”─▄Ą─▒│║¾ŲõīŹ╩╣ė├Ą─╩Ū╔ŅČ╚īW┴Ģ╝╝ągŻ¼ūįäėūRäełDŲ¼ųąĄ─╚╦─śŻ¼╚╗║¾▀MąąūįäėūRäe║═ĘųŅÉĪŻ
- ų¦ĖČīÜÆ▀─śų¦ĖČ
±RįŲį┌2015 CeBITš╣Ģ■ķ_─╗╩Į╔Ž╩ū┤╬š╣╩Š┴╦╬øŽüĮĘ■Ą─ūŅą┬ų¦ĖČ╝╝ąg“Smile to Pay”Ż©Æ▀─śų¦ĖČŻ®Ż¼¾@ŲG╚½ł÷ĪŻų¦ĖČīÜą¹ĘQŻ¼Face++ Financial╚╦─śūRäe╝╝ągį┌LFWć°ļH╣½ķ_£yįć╝»ųą▀_ĄĮ99.5%Ą─£╩┤_┬╩Ż¼═¼Ģr▀Ć─▄▀\ė├“Į╗╗ź╩ĮųĖ┴Ņ+▀B└mąį┼ąČ©+3D┼ąČ©”╝╝ągĪŻ╚╦─śūRäe╝╝ąg╗∙ė┌╔±ĮøŠWĮjŻ¼ūīėŗ╦ŃÖCīW┴Ģ╚╦Ą─┤¾─XŻ¼▓ó═©▀^“╔ŅČ╚īW┴Ģ╦ŃĘ©”┤¾┴┐ė¢ŠÜŻ¼ūī╦³ūāĄ├śO×ķ“┬ö├„”Ż¼─▄ē““šJ╚╦”ĪŻīŹ¼F╚╦─śūRäe▓╗ąĶę¬ė├æ¶ūįąą╠ßĮ╗ššŲ¼Ż¼ėą┘Y┘|Ą─ÖCśŗį┌ąĶę¬▀Mąą╚╦─śūRäeĢrŻ¼┐╔ęįŽ“╚½ć°╣½├±╔ĒĘ▌ūC╠¢┤a▓ķįāĘ■äšųąą─╠ß│÷╔ĻšłŻ¼īó▓╔╝»ĄĮĄ─ššŲ¼┼cįō▓┐ķTĄ─ÖÓ═■ššŲ¼Äņ▀Mąą▒╚ī”ĪŻ
ę▓Š═╩ŪšfŻ¼ė├æ¶į┌▀Mąą╚╦─śūRäeĢrŻ¼ų╗ąĶ┤“ķ_╩ųÖC╗“ļŖ─XĄ─özŽ±Ņ^Ż¼ī”ų°ūį╝║Ą─š²─ś▀Mąą┼─öz╝┤┐╔ĪŻį┌ųŪ─▄╩ųÖC╚½├µŲš╝░Ą─Į±╠ņŻ¼▀@éĆģó┼cķTÖæĄ═ĄĮ┐╔ęį║÷┬į▓╗ėŗĪŻ
ė├æ¶╚▌ęūō·ą─Ą─ļ[╦Įå¢Ņ}į┌╚╦─śūRäeŅIė“ę▓─▄ėąą¦▒▄├ŌŻ¼ę“×ķššŲ¼üĒį┤ÖÓ═■Ż¼═¼ĢrŻ¼ę╗ĘN╠žėąĄ─“├ō├¶”╝╝ąg┐╔ęįīóššŲ¼─Ż║²╠Ä└Ē│╔╚Ōč█¤oĘ©ūRäeČ°ų╗ėąėŗ╦ŃÖC▓┼─▄ūRäeĄ─łDŽ±ĪŻ
- łDŲ¼ā╚╚▌ūRäe
Ū░├µā╔éĆ░Ė└²ĮķĮBĄ─Č╝╩ŪłDŲ¼ūRäeŻ¼▒╚łDŲ¼ūRäeĖ³ļyĄ─╩ŪłDŲ¼šZ┴xĄ─└ĒĮŌ║═╠ß╚ĪŻ¼░┘Č╚║═GoogleČ╝į┌▀Mąą▀@ĘĮ├µĄ─蹊┐ĪŻ
░┘Č╚Ą─░┘Č╚ūRłD─▄ē“ėąą¦Ąž╠Ä└Ē╠žČ©╬’¾wĄ─Öz£yūRäeŻ©╚ń╚╦─śĪó╬─ūų╗“╔╠ŲĘŻ®Īó═©ė├łDŽ±Ą─ĘųŅÉś╦ūóŻ¼╚ńłD4╦∙╩ŠĪŻ

łD4
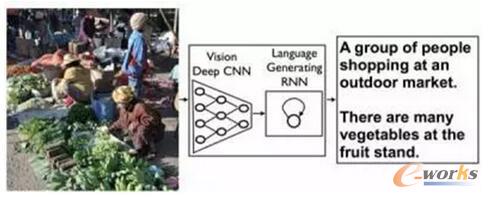
üĒūįGoogle蹊┐į║Ą─┐ŲīW╝ę░l▒Ē┴╦ę╗Ų¬▓®╬─Ż¼š╣╩Š┴╦Googleį┌łDą╬ūRäeŅIė“Ą─ūŅą┬蹊┐▀Mš╣ĪŻ╗“įS╬┤üĒGoogleĄ─łDą╬ūRäeę²Ūµ▓╗āH─▄ē“ūRäe│÷łDŲ¼ųąĄ─ī”Ž¾Ż¼▀Ć─▄ē“ī”š¹éĆł÷Š░▀Mąą║åČ╠Č°£╩┤_Ą─├Ķ╩÷Ż¼╚ńłD5╦∙╩ŠĪŻ▀@ĘN═╗ŲŲąįĄ─Ė┼─ŅüĒūįÖCŲ„šZčįĘŁūgĘĮ├µĄ─蹊┐│╔╣¹Ż║═©▀^ę╗ĘN▀fÜw╔±ĮøŠWĮjŻ©RNNŻ®īóę╗ĘNšZčįĄ─šZŠõ▐DōQ│╔Ž“┴┐▒Ē▀_Ż¼▓ó▓╔ė├Ą┌Č■ĘNRNNīóŽ“┴┐▒Ē▀_▐DōQ│╔─┐ś╦šZčįĄ─šZŠõĪŻ

łD5
Č°Googleīóęį╔Ž▀^│╠ųąĄ─Ą┌ę╗ĘNRNNė├╔ŅČ╚ŠĒĘe╔±ĮøŠWĮjCNN╠µ┤·Ż¼▀@ĘNŠWĮj┐╔ęįė├üĒūRäełDŽ±ųąĄ─╬’¾wĪŻ═©▀^▀@ĘNĘĮĘ©┐╔ęįīŹ¼FīółDŽ±ųąĄ─ī”Ž¾▐DōQ│╔šZŠõŻ¼ī”łDŽ±ł÷Š░▀Mąą├Ķ╩÷ĪŻĖ┼─Ņļm╚╗║åå╬Ż¼Ą½īŹ¼FŲüĒ╩«ĘųÅ═ļsŻ¼┐ŲīW╝ę▒Ē╩Š─┐Ū░īŹ“׫a╔·Ą─šZŠõ║Ž└Ēąį▓╗ÕeŻ¼Ą½ŠÓļx═Ļ├└╚įėą▓ŅŠÓŻ¼▀@ĒŚčąŠ┐─┐Ū░āH╠Äė┌įńŲ┌ļAČ╬ĪŻłD6š╣╩Š┴╦═©▀^┤╦ĘĮĘ©ūRäełDŽ±ī”Ž¾▓ó«a╔·├Ķ╩÷Ą─▀^│╠ĪŻ
łD6
ūį╚╗šZčįūRäe
ūį╚╗šZčįūRäeę╗ų▒╩Ūę╗éĆĘŪ│Ż¤ßķTĄ─ŅIė“Ż¼ūŅėą├¹Ą─╩Ū╠O╣¹Ą─SiriŻ¼ų¦│ų┘Yį┤▌ö╚ļŻ¼š{ė├╩ųÖCūįĦĄ─╠ņÜŌŅAł¾Īó╚š│Ż░▓┼┼Īó╦č╦„┘Y┴ŽĄ╚æ¬ė├Ż¼▀Ć─▄ē“▓╗öÓīW┴Ģą┬Ą─┬Ģę¶║═šZš{Ż¼╠ß╣®ī”įÆ╩ĮĄ─æ¬┤ĪŻ╬ó▄øĄ─Skype Translator┐╔ęįīŹ¼Fųąėó╬─ų«ķgĄ─īŹĢršZę¶ĘŁūg╣”─▄Ż¼īó╩╣Ą├ėó╬─║═ųą╬─Ųš═©įÆų«ķgĄ─īŹĢršZę¶ī”įÆ│╔×ķ¼FīŹĪŻ
Skype TranslatorĄ─▀\ū„ÖCųŲ╚ńłD7╦∙╩ŠĪŻ
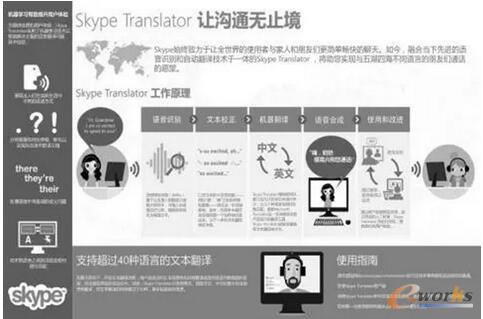
łD7
į┌£╩éõ║├Ą─öĄō■▒╗õø╚ļÖCŲ„īW┴ĢŽĄĮy║¾Ż¼ÖCŲ„īW┴Ģ▄ø╝■Ģ■į┌▀@ą®ī”įÆ║═ŁhŠ│╔µ╝░Ą─å╬į~ųą┤ŅĮ©ę╗éĆĮyėŗ─Żą═ĪŻ«öė├涚fįÆĢrŻ¼▄ø╝■Ģ■į┌įōĮyėŗ─Żą═ųąīżšęŽÓ╦ŲĄ─ā╚╚▌Ż¼╚╗║¾æ¬ė├ĄĮŅAŽ╚“īWĄĮ”Ą─▐DōQ│╠ą“ųąŻ¼īóę¶Ņl▐DōQ×ķ╬─▒ŠŻ¼į┘īó╬─▒Š▐DōQ│╔┴Ēę╗ĘNšZčįĪŻ
ļm╚╗šZę¶ūRäeę╗ų▒╩ŪĮ³Äū╩«─ĻüĒĄ─ųžę¬čąŠ┐šnŅ}Ż¼Ą½╩Ūįō╝╝ągĄ─░lš╣Ųš▒ķ╩▄ĄĮÕeš`┬╩Ė▀Īó¹£┐╦’L├¶ĖąČ╚▓Ņ«ÉĪóįļ┬ĢŁhŠ│Ą╚ę“╦žĄ─ūĶĄKĪŻīó╔Ņīė╔±ĮøŠWĮjŻ©DNNsŻ®╝╝ągę²╚ļšZę¶ūRäeŻ¼śO┤¾ĄžĮĄĄ═┴╦Õeš`┬╩Īó╠ßĖ▀┴╦┐╔┐┐ąįŻ¼ūŅĮK╩╣▀@ĒŚšZę¶ĘŁūg╝╝ągĄ├ęįÅVĘ║æ¬ė├ĪŻ
╔ŅČ╚īW┴Ģ
Artificial IntelligenceŻ©╚╦╣żųŪ─▄Ż®╩Ū╚╦ŅÉ├└║├Ą─įĖ═¹ų«ę╗ĪŻļm╚╗ėŗ╦ŃÖC╝╝ągęčĮø╚ĪĄ├┴╦ķLūŃĄ─▀M▓ĮŻ¼Ą½Įžų┴─┐Ū░Ż¼▀Ćø]ėąę╗┼_ėŗ╦ŃÖC─▄ē“«a╔·“ūį╬ꔥ─ęŌūRĪŻĄ─┤_Ż¼į┌╚╦ŅÉ║═┤¾┴┐¼FėąöĄō■Ą─Ä═ų·Ž┬Ż¼ėŗ╦ŃÖC┐╔ęį▒Ē¼FĄ├╩«ĘųÅŖ┤¾Ż¼Ą½╩Ūļxķ_┴╦▀@ā╔š▀Ż¼╦³╔§ų┴Č╝▓╗─▄Ęų▒µā╔ų╗ąĪäė╬’ĪŻ
╔ŅČ╚īW┴Ģ╦ŃĘ©ūįäė╠ß╚ĪĘųŅÉ╦∙ąĶĄ─Ą═īė┤╬╗“š▀Ė▀īė┤╬╠žš„ĪŻĖ▀īė┤╬╠žš„╩ŪųĖįō╠žš„┐╔ęįĘų╝ēŻ©īė┤╬Ż®Ąžę└┘ćŲõ╦¹╠žš„ĪŻ└²╚ńŻ¼ī”ė┌ÖCŲ„ęĢėXŻ¼╔ŅČ╚īW┴Ģ╦ŃĘ©Å─įŁ╩╝łDŽ±╚źīW┴ĢĄ├ĄĮ╦³Ą─ę╗éĆĄ═īė┤╬▒Ē▀_Ż¼╚ń▀ģŠēÖz£yŲ„ĪóąĪ▓©×V▓©Ų„Ą╚Ż¼╚╗║¾į┌▀@ą®Ą═īė┤╬▒Ē▀_Ą─╗∙ĄA╔Žį┘Į©┴ó▒Ē▀_Ż¼╚ń▀@ą®Ą═īė┤╬▒Ē▀_Ą─ŠĆąį╗“š▀ĘŪŠĆąįĮM║ŽŻ¼╚╗║¾ųžÅ═▀@éĆ▀^│╠Ż¼ūŅ║¾Ą├ĄĮę╗éĆĖ▀īė┤╬Ą─▒Ē▀_ĪŻ
╔ŅČ╚īW┴Ģ─▄ē“Ą├ĄĮĖ³║├Ąž▒Ē╩ŠöĄō■Ą─╠žš„Ż¼═¼Ģrė╔ė┌─Żą═Ą─īė┤╬ĪóģóöĄ║▄ČÓŻ¼╚▌┴┐ūŃē“Ż¼ę“┤╦Ż¼─Żą═ėą─▄┴”▒Ē╩Š┤¾ęÄ─ŻöĄō■ĪŻ╦∙ęįī”ė┌łDŽ±ĪóšZę¶▀@ĘN╠žš„▓╗├„’@Ż©ąĶę¬╩ų╣żįOėŗŪę║▄ČÓø]ėąų▒ė^Ą─╬’└Ē║¼┴xŻ®Ą─å¢Ņ}Ż¼─▄ē“į┌┤¾ęÄ─Żė¢ŠÜöĄō■╔Ž╚ĪĄ├Ė³║├Ą─ą¦╣¹ĪŻ┤╦═ŌŻ¼Å──Ż╩ĮūRäe╠žš„║═ĘųŅÉŲ„Ą─ĮŪČ╚üĒ┐┤Ż¼╔ŅČ╚īW┴Ģ┐“╝▄īó╠žš„║═ĘųŅÉŲ„ĮY║ŽĄĮę╗éĆ┐“╝▄ųąŻ¼ė├öĄō■╚źīW┴Ģ╠žš„Ż¼į┌╩╣ė├ųą£p╔┘┴╦╩ų╣żįOėŗ╠žš„Ą─Š▐┤¾╣żū„┴┐Ż¼ę“┤╦Ż¼▓╗āHą¦╣¹Ė³║├Ż¼Č°Ūę╩╣ė├ŲüĒę▓ėą║▄ČÓĘĮ▒Ńų«╠ÄĪŻ
«ö╚╗Ż¼╔ŅČ╚īW┴Ģ▒Š╔Ē▓ó▓╗╩Ū═Ļ├└Ą─Ż¼ę▓▓╗╩ŪĮŌøQ╚╬║╬ÖCŲ„īW┴Ģå¢Ņ}Ą─└¹Ų„Ż¼▓╗æ¬įō▒╗Ę┼┤¾ĄĮę╗éƤo╦∙▓╗─▄Ą─│╠Č╚ĪŻ
ąĪĮY
▒Š╬─ų„ę¬ĮķĮB┴╦ÖCŲ„īW┴ĢĪóöĄō■═┌Š“ęį╝░«öŪ░ūŅ¤ßķTĄ─╔ŅČ╚īW┴ĢĪŻ╔ŅČ╚īW┴Ģ┐╔ęįšfŽŲŲ┴╦╚╦╣żųŪ─▄Ą─ėųę╗┤╬¤ß│▒Ż¼Ą½╩Ū┤¾╝ęę¬ŪÕ│■ĄžšJūRĄĮŻ¼▀@ļxšµš²Ą─AIŻ©╚╦╣żųŪ─▄Ż®▀Ć▓ŅĄ├║▄▀hĪŻĄ½┐éĄ─üĒšfŻ¼╬ęéāļxļŖė░ųą├Ķ╩÷Ą─╬┤üĒ╩└ĮńĖ³Į³┴╦ę╗▓ĮŻ¼▓╗╩Ūå߯┐
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║┤¾öĄō■╝▄śŗįöĮŌŻ║Å─öĄō■½@╚ĪĄĮ╔ŅČ╚īW┴Ģ
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839721046.html






















