



«öŪ░Ż¼ųŲįņ▀^│╠ųą╦∙«a╔·Ą─öĄō■Ą─ęÄ─ŻĪóŅÉą═║═╦┘Č╚š²į┌│╩ųĖöĄ╝ēį÷ķLŻ¼Ä¦üĒ┴╦Š▐┤¾Ą─░lš╣ÖCė÷ĪŻ═©▀^šJšµĘų╬÷▀@ą®öĄō■Ż¼Ų¾śI┐╔½@Ą├ĖéĀÄā×ä▌Īó┐ņ╦┘Ēææ¬▓╗öÓūā╗»Ą─╩ął÷äėæBĪó’@ų°╠ßĖ▀ųŲįņ└¹ØÖĪó╔·«a┴”║═ą¦┬╩ĪŻ╣żÅS▄ćķgųąĄ─įOéõĢ■╔·│╔│╔Ū¦╔Ž╚fĘN▓╗═¼Ą─öĄō■ŅÉą═Ż¼└²╚ńČÓéĆ╝ēäeĄ─å╬╬╗╔·«aöĄō■ĪóįOéõ▀\ąąöĄō■Īó┴„│╠öĄō■Īó╚╦╣ż▓┘ū„åTöĄō■Ą╚ĪŻ▀@ą®öĄō■┐╔ęįį┌┤µā”║¾ė├ė┌öĄō■Ęų╬÷ĪŻ
▒M╣▄┤¾ą═ųŲįņ╔╠ČÓ─ĻüĒę╗ų▒į┌╩╣ė├Įyėŗ┴„│╠┐žųŲ║═ĮyėŗöĄō■Ęų╬÷üĒā×╗»╔·«aŻ¼Ą½«öĮ±öĄō■Ą─Å═ļsĮYśŗ│╔×ķ▓┐╩ą┬ĘĮ░ĖĪó╗∙ĄA╝▄śŗ║═╣żŠ▀ĦüĒ┴╦ųž┤¾ÖCė÷ĪŻĄ├ęµė┌Ė³ū┐įĮĄ─ėŗ╦Ńąį─▄Ą─ė┐¼FĪóķ_Ę┼ś╦£╩Ą─═Ų│÷║═ÅVĘ║┐╔ė├Ą─ąąśIīŻķLŻ¼ųŲįņśIęčĮø£╩éõ║├│õĘų└¹ė├┤¾öĄō■ĪŻ┤╦═ŌŻ¼į┌īWąg蹊┐Ą─═ŲäėŽ┬Ż¼╝╝─▄ŗ╣╩ņĄ─öĄō■┐ŲīW╝ęöĄ┴┐²ŗ┤¾Ż¼╦¹éāīó─▄ē“į┌╩╣ė├┤¾öĄō■ĘĮ├µ×ķųŲįņśI╠ß╣®Ė³│÷╔½Ą─ų¦│ųĪŻ
ĮĶų·╚½ą┬Ą─ųŲįņųŪ─▄╠žąįŻ¼ųŲįņ╔╠─▄ē“╠ßĖ▀┘|┴┐Ż¼į÷╝ė«a┴┐Ż¼Ė³£╩┤_Ąž┴╦ĮŌųŲįņå¢Ņ}Ą─Ė∙▒ŠįŁę“Ż¼ęį╝░£p╔┘ÖCŲ„╣╩šŽ║═Õ┤ÖCŪķørĪŻĮĶų·ą┬Ą─śIäšārųĄ║═╝╝ąg─▄┴”Ż¼ųŲįņ╔╠īó─▄ē“Ė─ūāśIäš─Ż╩Į║═īŹ█`Ż¼ęįā×╗»įOėŗŻ¼īŹ¼F│÷╔½Ą─┐╔ųŲįņąįŻ¼Å─Č°Ė─▀M╣®æ¬µ£╣▄└ĒŻ¼▓ó▓╔ė├Č©ųŲĄ─ųŲįņĘ■äš┐sČ╠īŻ×ķĖ„ĄžŽ¹┘Mš▀┴┐╔ĒČ©ųŲĄ─«aŲĘĄ─╔Ž╩ąĢrķgĪŻ
▒Š╬─Ė┼╩÷┴╦ėó╠žĀ¢ę╗╝ęųŲįņ╣żÅSĄ─╬’┬ōŠW(IoT)įć³cėŗäØŻ¼ęįšf├„īóöĄō■Ęų╬÷æ¬ė├ė┌╣żÅSįOéõ║═é„ĖąŲ„┐╔╚ń║╬╠ß╔²ųŲįņ┴„│╠Ą─▀\ĀIą¦┬╩▓ó╣Ø╝s╔·«a│╔▒ŠĪŻį┌īŹ╩®▀@ę╗╬’┬ōŠW┤¾öĄō■Ęų╬÷ĒŚ─┐Ą─▀^│╠ųąŻ¼ėó╠žĀ¢┼cClouderaĪó┤„Ā¢Īó╚²┴ŌļŖÖC║═Revolution Analytics▀Mąą┴╦Šo├▄Ą─ąąśIģfū„Ż¼ŅAėŗ├┐─Ļīó─▄ē“╣Ø╩ĪöĄ░┘╚f├└į¬Ż¼▓óĦüĒĖ³Ė▀Ą─═Č┘Y╗žł¾ĪŻ
╠¶æŻ║╚ń║╬Å─╦∙ėąĄ─ųŲįņöĄō■ųą╠ߤÆārųĄŻ┐
┤¾öĄō■īŹ┘|╔Ž╩Ū░³║¼Ė„ĘNöĄō■ŅÉą═Ą─²ŗ┤¾öĄō■╝»Ż¼┐╔ęįĘų×ķĮYśŗ╗»Īó░ļĮYśŗ╗»╗“ĘŪĮYśŗ╗»Ż¼╚ń▒Ē1╦∙╩ŠĪŻĮYśŗ╗»öĄō■▀m║ŽĘ┼į┌Ė±╩Įš¹²RĄ─▒ĒĖ±ųąŻ¼ę“┤╦ŽÓī”╚▌ęū╣▄└Ē║═╠Ä└ĒĪŻĮYśŗ╗»öĄō■Ą─ā×ä▌╩Ū▒Ńė┌▌ö╚ļĪó┤µā”Īó▓ķįā║═Ęų╬÷ĪŻŽÓĻP╩Š└²░³└©ĻPŽĄöĄō■Äņųą┤µā”Ą─ųŲįņöĄō■Ż¼ęį╝░üĒūįųŲįņł╠ąąŽĄĮy║═Ų¾śIŽĄĮyĄ─öĄō■ĪŻ┴Ēę╗ĘĮ├µŻ¼ĘŪĮYśŗ╗»öĄō■(└²╚ńłDŲ¼Īó╬─▒ŠĪóįOéõ╚šųŠ╬─╝■Īó╚╦╣ż▓┘ū„åT╔·│╔Ą─ųĄ░Ół¾Ėµ║═ųŲįņ╔ńĮ╗ģfū„ŲĮ┼_╬─▒ŠĄ╚)┐╔─▄×ķįŁ╩╝Ė±╩ĮŻ¼ąĶę¬Įø▀^ĮŌ┤a▓┼─▄╠ß╚ĪöĄō■ųĄĪŻ░ļĮYśŗ╗»öĄō■╩ŪĮYśŗ╗»öĄō■Ą─ę╗ĘNŻ¼ŲõĖ±╩Į▓╗Ę¹║ŽĻPŽĄöĄō■Äņ╗“Ųõ╦¹ą╬╩ĮĄ─öĄō■▒ĒĻP┬ōĄ─öĄō■─Żą═ś╦£╩ĮYśŗŻ¼Ą½░³║¼ė├ė┌ĘųĖ¶šZ┴xę¬╦žĄ─ś╦ėø╗“Ųõ╦¹ėø╠¢Ż¼▓óŪęöĄō■ųą├„┤_┴╦ėøõø║═ūųČ╬īė┤╬ĮYśŗĪŻį┌ųŲįņśIŻ¼ę¬Žļ░lō]┤¾öĄō■╝╝ągĄ─ÅŖ┤¾ū„ė├Ż¼ąĶę¬īó▀@ą®öĄō■╝»ŅÉą═▀Mąą║Ž▓ó┼cĻP┬ōŻ¼Å─ųą░l¼Fą┬Ą─Č┤ęŖŻ¼Å─Č°äōįņ│÷╔½Ą─śIäšārųĄĪŻ┤¾öĄō■╝╝ągĄ─┴Ēę╗éĆārųĄČ©╬╗Š═╩ŪŻ¼ų¦│ųųŲįņ╔╠ęįĮøØ·Ė▀ą¦Īó┐╔öUš╣Ą─ĘĮ╩ĮŠ█║Ž▓ó╝»ųąĖ„ŅÉöĄō■ĪŻ
▒Ē1 ųŲįņöĄō■╩Š└²
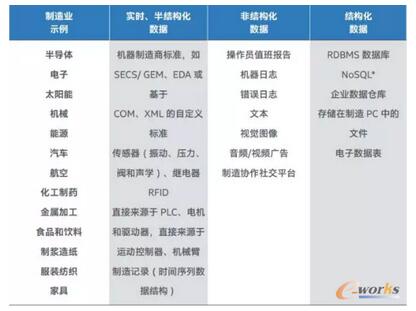
ĪĪĪĪ
ųŲįņ┴„│╠┤µį┌Ė„ĘNūā┴┐Ż¼╚ń▓─┴ŽĪó┴„│╠ĘĮ░Ė║═ĘĮĘ©ęį╝░įOéõ▓Ņ«ÉŻ¼▀@Š═ę¬Ū¾ųŲįņ╔╠▓╔ė├╗∙ė┌┐╔öUš╣ŲĮ┼_Ą─┤¾öĄō■ĮŌøQĘĮ░ĖŻ¼▀@ĘNŲĮ┼_─▄ē“ļSų°śIäšį÷ķL║═ųŲįņę¬Ū¾Ą─╠ßĖ▀Č°öUš╣ĪŻÖCŲ„öĄō■┼c«a┴┐║═┘|┴┐├▄ŪąŽÓĻPŻ¼ę“┤╦─▄ē“×ķų„äėÖz£yīóę¬╩¦╚ź┐žųŲĄ─┴„│╠╠ß╣®ųžę¬ą┼ŽóĪŻ╚╗Č°Ż¼ę╗ą®ŅÉą═Ą─ųŲįņ┴„│╠Ģ■«a╔·┤¾┴┐öĄō■╬─╝■(├┐éĆ╣żŠ▀ŅÉą═Äū╠ņŠ═┐╔«a╔·GB╝ēöĄō■Ż¼╚ń▒Ē2╦∙╩Š)Ż¼Ž▐ųŲ┴╦╩╣ė├é„ĮyĘĮĘ©Å─▀@ą®öĄō■ųąĘų╬÷Īó╠ß╚Ī║═┤µā”ėąė├ą┼ŽóĄ──▄┴”ĪŻ╚ń╣¹▓╗╩╣ė├┤¾öĄō■╝╝ągŻ¼ų▒ė^│╩¼FüĒį┤ÅVĘ║Ą─┤¾ą═öĄō■╝»ųąĄ─ą┼ŽóČ╝ĘŪ│Ż└¦ļyĪŻ
▒Ē2 öĄō■┤¾ąĪ╩Š└²
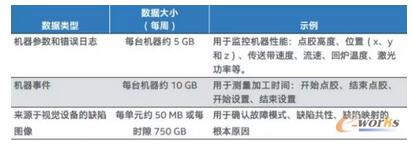
ĪĪĪĪ
æ¬ī”╠¶æŻ║ėó╠žĀ¢ųŲįņ▓┐ķT╩╣ė├┤¾öĄō■Ęų╬÷Ę■äšŲ„║═╬’┬ōŠWŠWĻPĄ─╬’┬ōŠWįć³cėŗäØ
łD1 ų¦│ų×ķÅ─╣żÅS▄ćķgĄĮöĄō■ųąą─Ą─š¹éĆ▀^│╠╠ß╣®ųŲįņųŪ─▄Ą─Č╦ĄĮČ╦╗∙ĄA╝▄śŗśŗĮ©─ŻēK
łD1╦∙╩Š×ķ├µŽ“┤¾ąĪą═öĄō■╝»Ą─Ė▀╝ē╬’┬ōŠWųŲįņ╝▄śŗŻ¼▀@ą®öĄō■╝»░³║¼üĒį┤ė┌ųŲįņ▄ćķg║═ųŲįņŠWĮjĪó┐╔╣®╩š╝»║═Š█║ŽĄ─Ė„ŅÉöĄō■ĪŻįō╝▄śŗ×ķ═©▀^öĄō■┐╔ęĢ╗»Īó▒O┐ž║══┌Š“äōĮ©ą┬ą═╔╠śIųŪ─▄╠ß╣®┴╦╚½ą┬┐╔─▄ĪŻ
┼e└²üĒšfŻ¼įō╝▄śŗ┐╔ęįŪÕ└ĒĪó╠ß╚Ī║═▐DōQüĒūį¼FėąöĄō■ÄņĄ─ĮYśŗ╗»öĄō■ĪóüĒūį╣żŠ▀é„ĖąŲ„Ą─ĘŪĮYśŗ╗»öĄō■ęį╝░üĒūįé„ĮyįOéõĄ─╚šųŠ╬─╝■Ż¼▓óīó╦³éāš¹║Žį┌ę╗éĆöĄō■┤µā”ŲĮ┼_(╝┤Hadoop)ųąĪŻ╚╗║¾Ż¼▀\ąąį┌ā╚▓┐Ę■äšŲ„(╝┤öĄō■┤µā”Ę■äšŲ„)╔Ž▓╗═¼╠ōöMÖCĄ─Ė▀╝ē╣żÅSæ¬ė├┐╔ī”öĄō■▀Mąą┐╔ęĢ╗»║═Ęų╬÷ĪŻ╗“š▀Ż¼ė├æ¶┐╔╩╣ė├ŠWĮj╔ŽĄ─Ųõ╦¹Ęų╬÷╗“▒O┐žæ¬ė├įLå¢▀@ą®öĄō■ĪŻŲõ╦¹į÷ÅŖ╣”─▄░³└©į┌Hadoop╗“Ųõ╦¹ŅÉą═╬─╝■ŽĄĮyųą▀MąąĘų╬÷╗“į┌ā╚┤µųą▀MąąĘų╬÷ęį╠ß╔²ąį─▄ĪŻĘų╬÷ĮY╣¹┐╔═©▀^ŠWĮj╔╠śIųŪ─▄īėųąĄ─ų▒ė^┐╔ęĢ╗»╣”─▄š╣╩ŠĮoė├æ¶ĪŻ
ĪĪĪĪėó╠žĀ¢ųŲįņ▓┐ķTįć³cėŗäØųąĄ─┤¾öĄō■Ęų╬÷╬’┬ōŠWĘ■äšŲ„įOų├
ĪĪĪĪ
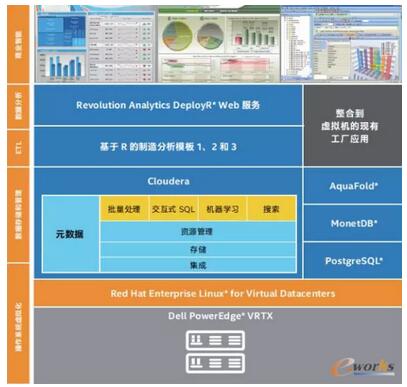
łD2 ┤¾öĄō■Ęų╬÷Ę■äšŲ„
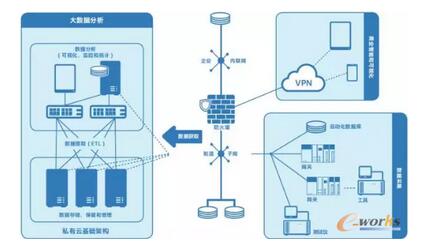
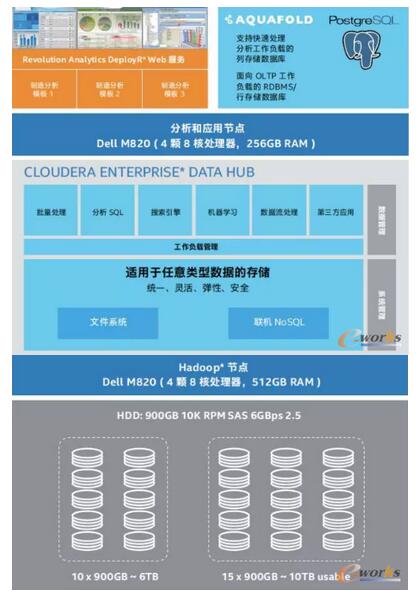
ėó╠žĀ¢ųŲįņ▓┐ķTį┌Ųõįć³c▓┐╩ųą╩╣ė├Ą─┤¾öĄō■Ęų╬÷Ę■äšŲ„╚ńłD2╦∙╩ŠĪŻ┤„Ā¢Ą─Šo£Éą═ŽĄĮy PowerEdge*VRTX2▒╗▀xū„ā╚▓┐Ę■äšŲ„Ż¼ęįį┌╦ĮėąįŲŁhŠ│ųą═ą╣▄┤¾öĄō■║═Ęų╬÷▄ø╝■ĪŻįōŽĄĮy░³║¼ę╗éĆDell PowerEdge VRTXÖCŽõŻ¼┼õéõ25ēK900GBė▓▒P║═2┼_Dell PowerEdgeM820ĄČŲ¼╩ĮĘ■äšŲ„Ż¼├┐ę╗┼_Ę■äšŲ„┼õéõE5-4600«aŲĘ╝ęūÕųąĄ─4Ņwėó╠žĀ¢Ż┐ų┴ÅŖŻ┐╠Ä└ĒŲ„ĪŻėó╠žĀ¢ų┴ÅŖ╠Ä└ĒŲ„E5-4600 «aŲĘ╝ęūÕ╠ß╣®┴╦ę╗┐Ņ│╔▒Š▀mę╦Ą─Šo£Éą═╦─┬Ę╠Ä└ĒŲ„ĮŌøQĘĮ░ĖŻ¼ūŅĖ▀ų¦│ų8éĆā╚║╦Īó20MB─®╝ēĖ▀╦┘(L3)ŠÅ┤µ║═1. 5TBā╚┤µ╚▌┴┐Ż¼═¼ĢrŠ▀éõ┐╔┐ņ╦┘▐DęŲöĄō■Ą─ą┼Ą└ĪŻ
ā╔┼_M820 Ę■äšŲ„┐╔═ą╣▄Ęų╬÷║═æ¬ė├▄ø╝■Ż¼ęį╝░į┌ČÓ┼_╠ōöMÖCųą▀\ąąĄ─ Hadoop╣سcĪŻRed Hat EntERPrise Linux* forVirtual Datacenters▓┘ū„ŽĄĮy×ķßśī”┐╔öUš╣Īó═Ļ╚½╠ōöM╗»öĄō■ųąą─Č°įOėŗĄ─Ę■äšŲ„╠ß╣®┴╦ę╗ĘN╚½├µĄ─╠ōöM╗»▄ø╝■ĮŌøQĘĮ░ĖĪŻ
Ęų╬÷║═æ¬ė├╣سc
ĪĪĪĪ
łD3 ┤¾öĄō■Ęų╬÷Ę■äšŲ„╔Ž▄ø╝■Ęų┼õų┴╠ōöMÖCĄ─Ūķør
łD3 ’@╩Š┴╦▄ø╝■▒╗╚ń║╬Ęų┼õų┴▓╗═¼╠ōöMÖC(VM)ĪŻįō╣سc═ą╣▄ų° 5 ┼_╠ōöMÖCŻ¼Ęųäe▀\ąąų°▓╗═¼Ą─Ęų╬÷║═æ¬ė├╣żū„žō▌dĪŻŠ▀¾w░³└©Ż║
·üĒūįRevolution AnalyticsĄ─Revolution REntERPrise* ╩Ūę╗┐Ņ╗∙ė┌ÅŖ┤¾Ą─ķ_į┤RĮyėŗšZčįĄ─Ęų╬÷▄ø╝■ĪŻįō▄ø╝■┐╔į┌Ęų╬÷ĮŌøQĘĮ░Ė║═Ų¾śI▄ø╝■ų«ķg╠ß╣®¤o┐pĪó░▓╚½Ą─öĄō■ś“Ż¼┐╔ĮŌøQ▓╔ė├╗∙ė┌RĄ─Ęų╬÷╣”─▄╝░¼FėąIT╗∙ĄA╝▄śŗĄ─Ų¾śI╦∙├µ┼RĄ─ĻPµI╝»│╔å¢Ņ}ĪŻ
· MonetDB*Ż║ę╗ĘN├µŽ“┴ąĄ─ķ_į┤öĄō■Äņ╣▄└ĒŽĄĮyŻ¼ų╝į┌Ä═ų·Ė▀ą¦═Ļ│╔ī”┤¾ą═öĄō■Äņ▀MąąĄ─Å═ļs▓ķįā╚╬䚯¼╚ńīó▒ĒĖ±┼cöĄ░┘éĆ┴ą║═öĄ░┘╚fąą▀MąąĮM║ŽĪŻMonetDBęč╩╣ė├į┌Ė„ĘNąĶę¬Ė▀ąį─▄Ą─æ¬ė├ųąŻ¼╚ńöĄō■═┌Š“Īóį┌ŠĆĘų╬÷╠Ä└Ē(OLAP)ĪóĄž└Ēą┼ŽóŽĄĮy║═┴„öĄō■╠Ä└ĒĄ╚ĪŻ
·PostgreSQL*Ż║ę╗┐ŅÅŖ┤¾Ą─ķ_į┤ī”Ž¾ĻPŽĄą═öĄō■ÄņŽĄĮyŻ¼ė├ė┌į┌ŠĆĮ╗ęū╠Ä└Ē(OLTP)ĪŻ
╬’┬ōŠW(IoT)ŠWĻP
╚²┴ŌļŖÖCMELSEC-QŽĄ┴ą* CšZčį┐žųŲŲ„╩Ūę╗┐Ņ╗∙ė┌ėó╠žĀ¢Ż┐┴ĶäėŻ┐╠Ä└ĒŲ„Ą─ŠWĻPŻ¼ė├ė┌Š█║Ž▓ó░▓╚½öz╚ļöĄō■ų┴┤¾öĄō■Ęų╬÷Ę■äšŲ„ĪŻöĄō■öz╚ļųĖ“×ūCĪó▀^×V║═ųžą┬Ė±╩Į╗»öĄō■Ż¼ęį▒Ń┤¾öĄō■Ęų╬÷▄ø╝■Ė³▌p╦╔Ąžī”Ųõ▀MąąĘų╬÷ĪŻ
╚²┴ŌļŖÖCMELSEC-QŽĄ┴ąCšZčį┐žųŲŲ„╩ŪŠ▀éõ▒ŖČÓųŪ─▄ŽĄĮy╣”─▄╠ž³cĄ─ŪČ╚ļ╩ĮĮŌøQĘĮ░ĖŻ¼░³└©╠Ä└ĒÅ─é„ĖąŲ„╗“═©▀^ŠWĮj╩š╝»Ą─┤¾┴┐öĄō■╦∙ąĶĄ─ĘĆČ©ŠWĮj▀BĮė║═ū┐įĮėŗ╦Ńąį─▄Ż¼═¼Ģrų¦│ųÅ═ļsĄ─ŽĄĮy┐žųŲ║═▓┘ū„ĪŻ▀@ę╗┐žųŲŲ„Ą─║╦ą─╩Ū▓╔ė├ėó╠žĀ¢Ż┐ ╝▄śŗ║═ Wind River VxWorks* īŹĢr▓┘ū„ŽĄĮyĄ─ė▓╝■ŲĮ┼_ĪŻ
╚²┴ŌļŖÖCķ_░l┴╦ MELSEC- QŽĄ┴ąCšZčį┐žųŲŲ„Ż¼ų╝į┌ØMūŃČÓĘN╣żÅSūįäė╗»ę¬Ū¾Ż¼Š▀éõū┐įĮĄ─┐╔┐┐ąįŻ¼┐╔▀mæ¬┐┴┐╠Ą─ŁhŠ│Ż¼ ŪęķLŲ┌┐╔ė├ĪŻ▀@ą®╠žąįų·╦³│╔×ķę╗┐Ņłį īŹ┐╔┐┐Ą─«aŲĘŻ¼Äū║§¤oąĶŠSūo╬’┬ōŠWųŲįņæ¬ė├ĪŻ
MELSEC-Q ŽĄ┴ąCšZčį┐žųŲŲ„╚Ī┤·┴╦é„Įy┐╔ŠÄ│╠┐žųŲŲ„ųą╩╣ė├Ą─╠▌ą╬▀ē▌ŗŻ¼╩╣ė├ć°ļHś╦£╩ C šZčį(C║═C++)╠ß╣®┴╦Ė³ņ`╗ŅĄ─ŠÄ│╠─▄┴”ĪŻ╦³─▄ē“ų¦│ųė├æ¶│õĘų└¹ė├¼FėąĄ─CšZčį▄ø╝■║═ķ_░l┘Yį┤ĪŻ
CIMSNIPER* ╩Ūę╗┐Ņ▀mė├ė┌╚²┴ŌļŖÖC MELSEC-Q ŽĄ┴ą C šZčį┐žųŲŲ„Ą─öĄō■½@╚Ī║═╠Ä└Ē▄ø╝■░³ĪŻ╦³─▄ē“╩š╝»┴„│╠öĄō■(░³└© SECS ą┼Žó)║═ųŲįņįOéõÕeš`Ż¼ Č°¤oąĶą▐Ė─¼FėąŽĄĮyĪŻ
┤¾öĄō■Ęų╬÷░Ė└²
į┌▀^╚źĄ─ā╔─ĻųąŻ¼ėó╠žĀ¢ķ_░l┴╦╩«ÄūéĆ┤¾öĄō■ĒŚ─┐Ż¼ņ¢╣╠┴╦▀\ĀIą¦┬╩║═╩š╚ļĪŻŽ┬ĘĮ┴ą│÷┴╦ÄūéĆ╩Š└²Ż║
┐sČ╠«aŲĘ£yįćĢrķg
ėó╠žĀ¢ųŲįņĄ─├┐ę╗├ČąŠŲ¼Č╝ę¬Įø▀^Åž ĄūĄ─┘|┴┐Öz▓ķŻ¼═©▀^ČÓĘNÅ═ļsĄ─£yįćĪŻ
ėó╠žĀ¢░l¼FŻ¼└¹ė├ųŲįņ▀^│╠ųą╩š╝»Ą─Üv╩Ęą┼Žó┐╔ęį£p╔┘£yįć╦∙ąĶĄ─«aŲĘöĄ┴┐Ż¼Å─Č°┐sČ╠£yįćĢrķgĪŻū„×ķĖ┼─Ņ“×ūCīŹ╩®Ą─▀@┐ŅĮŌøQĘĮ░Ėį┌ 2012 ─Ļ×ķėó╠žĀ¢Ż┐ ┐ßŅŻŻ┐ ŽĄ┴ą╠Ä└ĒŲ„╣Ø╝s┴╦ 300 ╚f├└į¬Ą─£yįć│╔▒ŠĪŻīó▀@┐ŅĮŌøQĘĮ░ĖöUš╣ĄĮĖ³ČÓ«aŲĘ║¾Ż¼ėó╠žĀ¢ ŅAėŗĢ■╣Ø╝s3Ż¼000 ╚f├└į¬Ą─│╔▒ŠĪŻ
Ė─╔ŲųŲįņ▒O┐ž
öĄō■├▄╝»ą═┴„│╠ę▓ė├ė┌Ä═ų·ėó╠žĀ¢į┌╔·«aŠĆ╔ŽÖz£y╣╩šŽŻ¼▀@╩Ūę╗éĆĖ▀Č╚ūįäė╗»Ą─ŁhŠ│ĪŻėó╠žĀ¢Å─š¹éĆ╣żÅSŠWĮjĄ─ųŲįņ╣żŠ▀║═£yįć╣żŠ▀ųą╠ß╚Ī╚šųŠ╬─╝■Ż¼├┐ąĪĢrČÓ▀_ 5 TBĪŻ═©▀^▓Č½@║═Ęų╬÷▀@ą®ą┼ŽóŻ¼ėó╠žĀ¢─▄ē“┤_Č©į┌ųŲįņ┴„│╠ųąĄ───éĆ▓Į¾Eķ_╩╝Ų½ļx│ŻęÄ╚▌▓ŅĪŻ
ßśī”┤╦╠ÄėæšōĄ─«öŪ░Č╦ĄĮČ╦ŲĮ┼_įć³c▓┐╩Ż¼ėó╠žĀ¢┼c╚²┴ŌļŖÖCĪóClouderaĪóRevolution Analytics ║═┤„Ā¢▀Mąą┴╦Šo├▄║Žū„Ż¼│╔╣”ķ_░l┴╦įSČÓū┐įĮ╣”─▄Ż¼į┌╩╣ė├öĄō■═┌Š“┐ŲīWĮŌøQīŹļHųŲįņå¢Ņ}ĘĮ├µ╚ĪĄ├┴╦Š▐┤¾▀Mš╣Ż¼▓ó═©▀^│╔▒Š╣Ø╩Ī║═øQ▓▀Ė─▀M×ķėó╠žĀ¢╣Ø╝s┴╦öĄ░┘╚f├└į¬ĪŻįōĒŚ─┐Ą─ų„ę¬─┐ś╦╩Ū░lŠ“öĄō■║═öĄō■Ęų╬÷Ą─ārųĄŻ¼═©▀^ŅA£yųŲįņ½@Ą├Ė³╔Ņ┐╠Ą─Č┤▓ņ┴”Ż¼▓óĮĄĄ═ųŲįņ│╔▒ŠŻ¼═¼Ģr▓╗ė░Ēæ╔·«a┴┐╗“┘|┴┐ĪŻ
Ž┬├µįö╩÷┴╦ėó╠žĀ¢═©▀^╝»│╔├µŽ“ųŲįņ╬’┬ōŠWĄ─┤¾öĄō■Ęų╬÷║═╝╝ąg½@Ą├┴╦ę╗ą®═╗ŲŲąį│╔Š═║═░l¼FĪŻ
įć³cėŗäØ│╔ą¦Ż║
╩╣ė├░Ė└² 1Ż║═©▀^▒O┐ž║═Ęų╬÷įOéõģóöĄųĄ▓óį┌▓┐╝■░l╔·╣╩šŽų«Ū░╝░ĢrĖ³ōQŻ¼£p╔┘▓╗▒žę¬Ą─«a─▄ōp╩¦ĪŻ
▒│Š░
ūįäė£yįćčbų├(ATE)╩ŪīŻķTė├ė┌į┌▓╗═¼įOéõ╔Žł╠ąą£yįćĄ─ÖCŲ„Ż¼▀@ą®įOéõ▒╗ĘQū„▒╗£yįOéõ(DUT)ĪŻATE ╩╣ė├┐žųŲŽĄĮy║═ūįäė╗»ą┼Žó╝╝ąg┐ņ╦┘ł╠ąą£yįćŻ¼£y┴┐▓óįu╣└▒╗£yįOéõĪŻ11 ATE ŽĄĮy▀BĮėĄĮĘQ×ķ╠Ä└Ē╣żŠ▀Ą─ūįäėĖ³ōQ╣żŠ▀╔ŽĪŻįō╣żŠ▀─▄ē“╬’└ĒĖ³ōQ£yįćĮė┐┌å╬į¬(TIU)╔ŽĄ─▒╗£yįOéõŻ¼ęį▒ŃĮė╩▄įōčbų├Ą─£yįćĪŻ
å¢Ņ}ĻÉ╩÷
ėą╚▒Ž▌Ą─£yįćĮė┐┌å╬į¬īóĢ■Õeš`Ąžīó┴╝ŲĘĘųŅÉ×ķ┤╬ŲĘŻ¼Ģ■ī”ėó╠žĀ¢ųŲįņ▀\ĀI│╔▒Šįņ│╔žō├µė░ĒæĪŻėą╚▒Ž▌Ą─£yįćĮė┐┌å╬į¬Ģ■ī¦ų┬ī”▒╗£yįOéõ▀MąąÕeš`ĘųŅÉŻ¼░³└©Š▄Į^┴╝ŲĘĪŻėó╠žĀ¢ųŲįņ▓┐ķTĄ──┐Ą─╩ŪÖz£yØōį┌Ą─ TIU ╚▒Ž▌Ż¼ęį▒Ń╝░Ģrą▐└Ē╗“Ė³ōQå╬į¬Ż¼Ę└ų╣╦³éā▒╗Õeš`ĘųŅÉĪŻ╚ń╣¹ėą╚▒Ž▌Ą─£yįćĮė┐┌å╬į¬īó┴╝ŲĘÕeš`ĘųŅÉ×ķ┤╬ŲĘŻ¼įōå╬į¬īóū„ÅUĪŻį┌Č©Ų┌ŅAĘ└ąįŠSūoŲ┌ķgŻ¼ę╗ą®╝┤▒Ń╚į╚╗▀\▐Dš²│ŻĄ─ĮM╝■ę▓Ģ■╩╣ė├éõ╝■Ė³ōQŻ¼ęį▒▄├Ō░l╔·┤╦ŅÉå¢Ņ}ĪŻ
│╔ą¦║═ā×ä▌
Ęų╬÷╣”─▄┐╔į┌¼Fėą╣żÅS┬ōÖC┴„│╠┐žųŲŽĄĮyė|░lų«Ū░Ż¼ŅA£y│÷Ė▀▀_ 90% Ą─Øōį┌£yįćĮė┐┌å╬į¬╣╩šŽĪŻį┌┤╦╠ÄĄ─ŪķørŽ┬Ż¼▀@┐╔Ä═ų·╝░ĢrĖ³┤µį┌╚▒Ž▌Ą─ TIU ęį├Ōįņ│╔▀^Č╚Š▄Į^┴╝ŲĘŻ¼īó«a─▄ōp╩¦ĮĄĄ═┴╦ 25%ĪŻ
┤╦═ŌŻ¼ėó╠žĀ¢▀Ć£p╔┘┴╦į┌ŅAĘ└ąįŠSūo▀^│╠ųą╠ßŪ░Ė³ōQ╔ą╬┤╣╩šŽĄ─éõ╝■Ą─ąĶŪ¾Ż¼Å─Č°ŅAėŗ┐╔ęįĮĄĄ═ 20% Ą─éõ╝■│╔▒ŠĪŻ
╩╣ė├░Ė└² 2Ż║═©▀^į┌║ĖŪ“║ĖĮėįOéõųąŽ¹│²║═£p╔┘Õeš`║ĖŪ“čb┼õŪķørĮĄĄ═«a─▄ōp╩¦
▒│Š░
║ĖŪ“║ĖĮė─ŻēK╩Ū×ķ╗∙Ų¼▒Ē├µ═┐─©║ĖĖÓĄ─▓┐╝■ĪŻ║ĖŪ“▒╗Ę┼ų├ĄĮ║ĖŪ“║ĖĮė▒Ē├µŻ¼╚╗║¾║ĖĖÓīóŲõ╣╠Č©į┌ŽÓæ¬╬╗ų├╔ŽĪŻš¹éĆĘŌčb═©▀^ę╗éĆ╗ž┴„║ĖĀtŻ¼īóį┌Ųõųą╚┌╗»╗∙Ų¼▒Ē├µ╔ŽĄ─║ĖĖÓ║═║ĖŪ“ĪŻ
║ĖŪ“▒╗šµ┐š╬³ĖĮĄĮ┘NčbŅ^Ą─ąĪ┐ū╔ŽĪŻŽĄĮyīóÖz▓ķįō┘NčbŅ^╔ŽĄ─║ĖŪ“╩Ūʱ▀^ČÓ╗“╚▒╩¦ĪŻ«ö┘NčbŅ^┼c╗∙Ų¼ī”²RĢrŻ¼║ĖŪ“▒╗Ę┼ų├į┌╗∙Ų¼Ą─║ĖĖÓ╔ŽĪŻßīĘ┼║ĖŪ“║¾Ż¼īóÖz▓ķ┘NčbŅ^╔Ž╩Ūʱܳ┴¶ėą╚╬║╬║ĖŪ“ĪŻūŅ║¾Ż¼özŽ±Ņ^│╔Ž±ŽĄĮyīóÖz▓ķ╗∙Ų¼╔Ž╩Ūʱ╚▒╩¦║ĖŪ“╗“║ĖŪ“╬╗ų├╩Ūʱ┤µį┌Ų½ęŲĪŻ
å¢Ņ}ĻÉ╩÷
╚▒╩¦║ĖŪ“Ą─å╬į¬×ķėą╚▒Ž▌Ą─▓─┴ŽŻ¼Ģ■įņ│╔«a─▄ōp╩¦ĪŻČÓĘNł÷Š░Ģ■ī¦ų┬å╬į¬╚▒╩¦║ĖŪ“Ż¼░³└©šµ┐šē║┴”▓╗ūŃĄ╚ĪŻ
│╔ą¦║═ā×ä▌
═©▀^┐╔ęĢ╗»╠Ä└Ēé„ĖąŲ„ūxöĄ▓óīóŲõ┼cĖ„ĘNÖCŲ„öĄō■║═ł╠ąąŽĄĮyöĄō■▀MąąĻP┬ōŻ¼ėó╠žĀ¢│╔╣”ĮĄĄ═┴╦«a─▄ōp╩¦Ż¼ā×╗»┴╦ŠSūo│╔▒ŠŻ¼▓ó▒▄├Ō┴╦įOéõ═╗╚╗Õ┤ÖCĪŻ▀@┐╔Ä═ų·╝╝ąg╚╦åTų„äėĮŌøQå¢Ņ}Ż¼│»ų°äōĮ©ŅA£yŠSūo╣”─▄Č°┼¼┴”ĪŻ
╩╣ė├░Ė└² 3Ż║╩╣ė├łDŽ±Ęų╬÷┤_Č©┴╝ŲĘ╗“┤╬ŲĘ
▒│Š░
ÖCŲ„ęĢėXįOéõ╩Ūę╗ĘN─ŻēKŻ¼┐╔║Y▀xå╬į¬▓óīóŲõĘųŅÉ×ķ┴╝ŲĘ║═▀ģļHå╬į¬ĪŻ┴╝ŲĘīóé„╦═ĄĮ╝ė╣ż┴„│╠Ż¼Č°▀ģļHå╬į¬īóĮė╩šųŲįņīŻåTĄ─Öz▓ķ▓ó┤_Č©Ųõā×┴ėĪŻįō╩ųäė┴„│╠▌^×ķ║─ĢrĪŻ
å¢Ņ}ĻÉ╩÷
╚╦╣żÖz▓ķ▓óĘųŅÉ▀ģļHå╬į¬Ą─┴„│╠ĘŪ│ŻĘ▒¼ŹŻ¼ėąĢrąĶę¬╝s8 ąĪĢr▓┼─▄│╔╣”īó▀ģļHå╬į¬┼cšµš²Ą─▓╗┴╝ŲĘĖ¶ļxĪŻ
▀@╩Ūę“×ķå╬į¬╦═▀_▓┘ū„åTĪó╚╗║¾é„╦═ĄĮĖ¶ļx─ŻēKĪóūŅ║¾▀MąąĖ¶ļx▒╚▌^┘MĢrĪŻłDŽ±Ęų╬÷┐╔Ä═ų·čĖ╦┘ūRäeÖz£y─ŻēKÖz£yĄĮĄ─▓╗┴╝ŲĘĪŻ
│╔ą¦║═ā×ä▌
ÖCŲ„ęĢėXįOéõ─ŻēKųąėøõøĄ─▀ģļHłDą╬Įø▀^ŅA╠Ä└ĒĪŻ├┐ę╗ÅłłDŽ±Č╝╩ŪĘŪĮYśŗ╗»öĄō■Ż¼ąĶꬹ▐Ė─│▀┤ńĪó╝¶▓├▓ó▐D╗»×ķ╗ęČ╚─Ż╩ĮŻ¼╚╗║¾īó├┐éĆŽ±╦ž▐D╗»×ķČ■▀MųŲĖ±╩ĮĪŻ┤╦┴„│╠Ą─Ž┬ę╗ļAČ╬╔µ╝░╠žš„▀xō±Ż¼ĘŪĮYśŗ╗»łDŽ±īóė╔ę╗ŽĄ┴ą▓╗═¼Ą─ųĄČ©┴xĪŻ╚╗║¾Ż¼īó▀@ą®ųĄ┘xėĶĖ„ĘNÖCŲ„īW┴Ģ╦ŃĘ©Ż¼ė├ė┌ģ^Ęųšµš²▓╗┴╝ŲĘ║═▀ģļH▓╗┴╝ŲĘĪŻ
łDŽ±Ęų╬÷┐sČ╠┴╦Å─┤¾┴┐▀ģļHå╬į¬ųąĘųļxšµš²▓╗┴╝ŲĘĄ─ĢrķgĪŻłDŽ±Ęų╬÷┤_šJ▓╗┴╝ŲĘĄ─╦┘Č╚┤¾╝s▒╚╚╦╣żĘĮĘ©┐ņ10▒ČĪŻ
öĄō■┴„
ĪĪĪĪ
łD4 Ė▀╝ēöĄō■┴„
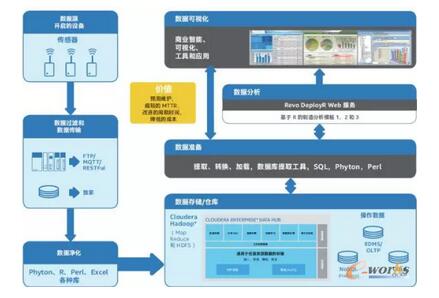
łD4’@╩Š┴╦╔Ž╩÷╩╣ė├░Ė└²ųąĄ─öĄō■╚ń║╬é„▌öĪŻ
╗∙ė┌ėó╠žĀ¢┴Ķäė╠Ä└ĒŲ„Ą─ŠWĻPīóīŹĢr½@╚ĪĄ─ÖCŲ„öĄō■║═é„ĖąŲ„öĄō■░l╦═ų┴┤¾öĄō■Ęų╬÷Ę■äšŲ„(BDAS)ĪŻ└²╚ńŻ¼║ĖŪ“║ĖĮė─ŻēKĄ─ÖCŲ„öĄō■═©▀^ÖCŲ„Įń├µČ╦┐┌╩š╝»Ż¼üĒūį─ŻöMé„ĖąŲ„Ą─ÖCŲ„öĄō■ęįöĄ├ļöĄ MB Ą─╦┘Č╚▀Mąą┴„é„▌öĪŻ
· ╩š╝»ĄĮĄ─╦∙ėą╣żÅSöĄō■Č╝┤µā”į┌ Hadoop* ųąĪŻęįŽ┬▓╗═Ļ╚½┴ą▒Ē’@╩Š┴╦╩╣ė├ Hadoop Ą─¼Fėą╣”─▄┐╔īŹ¼FĄ─┐╔─▄ąįŻ║
- HTTPŻ║┤¾öĄō■Ęų╬÷Ę■äšŲ„š╣╩Šę╗éĆų¦│ųī” HDFS ▀Mąą▓┘ū„Ą─Įø“×ūCĄ─ REST HTTP Č╦³cĪŻ
- Apache Sqoop* ╠ß╣®┴╦▀BĮė╣żŠ▀Ż¼ ė├ė┌īóĘŪ Hadoop öĄō■┤µā”(╚ńĻPŽĄöĄō■Äņ║═öĄō■é}Äņ)ųąĄ─öĄō■▀węŲų┴ HadoopĪŻ
- Flume* ─▄ē“Įė╩š│ų└mĄ─╚šųŠöĄō■ĪŻ
·▒Š▓┐Ęų╔Ž╩÷╩╣ė├░Ė└²ųąĄ─╠žČ©öĄō■Ė±╩Į×ķČ║╠¢ĘųĖ¶ųĄ(CSV) ╬─╝■╗“įŁ╩╝łDŽ±ĪŻ▒M╣▄ Hadoop ╔·æBŽĄĮy░³║¼ČÓĘNöĄō■öz╚ļ═ŠÅĮ(╚ń╔Ž╦∙╩÷)Ż¼Ą½ę╗ą®╣żÅSÖCŲ„Ą─ŠWĮjé„▌ö─▄┴”ėąŽ▐Ż¼ę¬Ū¾═©▀^Č©ųŲ╣ż│╠Ž“ HDFS ╠ßĮ╗öĄō■Ż║
- FTPŻ║╬’┬ōŠWŠWĻPōĒėąę╗éĆ FTP┐═æ¶Č╦Ż¼Č©Ų┌▀BĮėĄĮ┤¾öĄō■Ęų╬÷Ę■äšŲ„Ż¼▓óīóūŅą┬½@╚ĪĄ─öĄō■ų▒Įėé„▌öĄĮ HDFSĪŻę▓┐╔ęįĖ∙ō■īŹĢröĄō■┴„║═Ęų╬÷ę¬Ū¾╩╣ė├ MQTT ║═ REST Ą╚Ųõ╦¹öĄō■┴„ģfūhĪŻ
- CIFS ╣▓ŽĒ(Windows ╣▓ŽĒ)Ż║┤¾öĄō■Ęų╬÷Ę■äšŲ„╠ß╣®┴╦ę╗ĘN Windows/CIFS ╣▓ŽĒ─┐õøŻ¼ŠWĻP ┐╔īó╬─╝■Å═ųŲĄĮįō─┐õøųąĪŻ
·CSV ╬─╝■▒╗╩╣ė├ Pig ų▒Įėī¦╚ļHBase*Ż¼Č°įŁ╩╝łDŽ±Ģ■Ž╚╩╣ė├ėŗ╦ŃÖCęĢėX╝╝ąg║═ map-reduce ╚╬äš▀MąąŅA╠Ä└ĒŻ¼╔·│╔łDŽ±Ą─╬─▒ŠöĄō■▒Ē╩ŠĪŻ
·Ė∙ō■▓┘ū„ę¬Ū¾Ż¼öĄō■īóį┌╚²éĆöĄō■ ÄņųąĄ─ę╗éĆ▀Mąą┤µā”Ż║NoSQL (Hadoop)ĪóRDMS/SQL╗“ Coli/ OLAPĪŻ
·öĄō■Äņ┐╔╩╣ė├Ė„ĘN╣żŠ▀įLå¢║═╠Ä└ĒŻ¼ ░³└© AquaFoldĪóīŻķTł¾ĖµĪó╣żū„┴„š{Č╚ĪóETL ║═öĄō■Äņ╝»│╔ĪŻ═¼ĢrŻ¼ Cloudera Distribution for Hadoop ┐╔ī”öĄō■īŹ╩®Ė„ĘN▓┘ū„ĪŻ
·╠Ä└Ē▀^Ą─öĄō■╩╣ė├īŻ×ķ╣żÅSæ¬ė├įOėŗĄ─Revolution Analytics ╣żŠ▀▀Mąą▀Mę╗▓ĮĘų╬÷ĪŻ
·▀@ą®öĄō■į┌ęūė┌└ĒĮŌĄ─āx▒Ē▒PųąŽ“ė├涚╣╩ŠĪŻ
Įø“×┐éĮY║═ĮYšō
ėó╠žĀ¢╩╣ė├╬’┬ōŠWŠWĻPŻ¼ĮĶų·Å─ėó╠žĀ¢ūį╔ĒųŲįņŠWĮj║═įOéõ╝░é„ĖąŲ„╠ß╚ĪĄ─öĄō■Ż¼╝»│╔▓ó“×ūC┴╦┤¾öĄō■Ęų╬÷ā╚▓┐Ę■äšŲ„ĮŌøQĘĮ░ĖŻ¼Å─Č°ūCīŹ┴╦╬’┬ōŠWī”ė┌ųŲįņśIĄ─│÷╔½śIäšārųĄĪŻ▓╔ė├┴╦╚²┴ŌļŖÖC MELSEC-Q ŽĄ┴ą C šZčį┐žųŲŲ„ĪŻįć³cėŗäØĄ─īŹ╩®ėą┘ćė┌╣żÅS╣ż│╠ĤĪóIT ▓┐ķT║═üĒūį ClouderaĪó┤„Ā¢Īó╚²┴ŌļŖÖC║═ Revolution Analytics Ą─ąąśIīŻ╝ęĄ─═©┴”║Žū„ĪŻłFĻĀ╩ūŽ╚▓╔ė├¼FėąÖCŲ„ąį─▄║═▒O┐žöĄō■Ż¼╚╗║¾╩╣ė├┤¾öĄō■Ęų╬÷║═Į©─Ż╣”─▄½@╚Īė├ė┌ŅA£yØōį┌Ų½ęŲ║═╣╩šŽĄ─öĄō■ĪŻÖCŲ„ĮM╝■╣╩šŽŅA£y╣”─▄┐╔ų¦│ų╣ż│╠Ĥą▐Å═▓óĘ└ų╣Ų½ęŲŻ¼Å─Č°═©▀^▒▄├Ō└╦┘M╔·«a▓┐╝■Īó┐sČ╠ŠSą▐Ģrķg║═£p╔┘ÖCŲ„éõ╝■╩╣ė├┴┐╣Ø╝s┤¾┴┐┘YĮĪŻ
╩╣ė├┴╦┤¾öĄō■Ęų╬÷Ę■äšŲ„║═╬’┬ōŠWŠWĻP╔ŽĖ„ĘN▄ø╝■śŗĮ©─ŻēKĄ─╝»│╔╠ū╝■ĪŻ╔ą╬┤ķ_╩╝└¹ė├ųŲįņöĄō■ųą░³║¼Ą─ųŪ─▄ā×ä▌Ą─ųŲįņ╔╠Ż¼┐╔ęįæ¬ė├▓óīŹ╩®┤╦┐“╝▄ĪŻęčĮø╩╣ė├öĄō■╠ß╔²ą¦┬╩Ą─ųŲįņ╔╠┐╔ęį▀Mę╗▓Įį÷ÅŖ¼Fėą─▄┴”Ż¼ęį╠ßĖ▀öĄō■═┌Š“║═Ęų╬÷─▄┴”ĪŻ
ī”ė┌ėó╠žĀ¢Č°čįŻ¼┤╦įć³cėŗäØŅAėŗ├┐─Ļ┐╔╣Ø╝söĄ░┘╚f├└į¬Ż¼▓ó─▄ē“ĦüĒĖ³Ė▀Ą─═Č┘Y╗žł¾ĪŻā×ä▌░³└©čėķLįOéõĮM╝■š²│Ż▀\ąąĢrķgĪóūŅąĪ╗»┴╝ŲĘ║═┤╬ŲĘÕeš`ĘųŅÉ(Å─Č°╠ßĖ▀«a─▄║═╔·«a┴”)Ż¼ų¦│ųŅA£yŠSūoŻ¼═¼Ģr£p╔┘ĮM╝■╣╩šŽĪŻėó╠žĀ¢Ą─ųŲįņŁhŠ│║═įOéõųą▀ĆėąČÓĘNŲõ╦¹ŅÉą═Ą─ģóöĄĪóČ╚┴┐Ę©Īó«aŲĘ║═įOéõöĄō■(ĮYśŗ╗»║═ĘŪĮYśŗ╗»)Ż¼┐╔ęį═©▀^═┌Š“║═Ęų╬÷▀@ą®öĄō■½@╚Īą┬Ą─śIäšārųĄĪŻ═©▀^└¹ė├▀@ę╗ÖCĢ■Ż¼ėó╠žĀ¢īó─▄ē“▀Mę╗▓Į╠ßĖ▀╣żÅSĄ─ą¦┬╩║═╔·«a┴”Ż¼Į©┴ó│÷╔½ĖéĀÄā×ä▌ĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://www.guhuozai8.cn/
▒Š╬─ś╦Ņ}Ż║ųŪ─▄ųŲįņųą┤¾öĄō■Ęų╬÷║═╬’┬ōŠWĄ─Ąž╬╗
▒Š╬─ŠWųĘŻ║http://www.guhuozai8.cn/html/consultation/10839420747.html






















